一、视频生成
巧妇难为无米之炊,在研究之前应该要先有研究的视频。然而在电脑以及网上找了一段时间后发现没有合适的。 而正巧电脑中有一帧帧的卫星影像。所以就想自己将这些帧拼起来构成一小段视频,用于后续处理。
1.代码
同样感谢Python和OpenCV,使得组成视频的核心代码十分简洁,一共不超过30行。代码如下:
# coding=utf-8
import cv2
import os.path
# 用户输入存放影像的文件夹目录,如E:\L0
rootdir = raw_input("Input the parent path of images:\n") + "\\"
# 输出视频路径
output = raw_input("Input output video path:\n")
# 考虑到适用性,增加了影像文件类型的选择,如tif、jpg、png等
type = raw_input("Input file type of images:\n")
# 考虑原始影像可能非常大,如4096*3072,直接拼接成视频可能不方便观看
# 因此设置了缩放因子,这样可以指定输出视频的大小
scale = input("Input scale of video(0-1):\n")
# 用于控制输出视频帧率
fps = input("Input fps of video:\n")
print "OK...Processing...\n"
# list,用于存放遍历得到的用户指定类型的影像文件
paths = []
# 遍历
for parent, dirname, filenames in os.walk(rootdir):
for filename in filenames:
# 判断,如果是用户指定的类型则添加到list,否则什么也不做
# 这里用endswith更好一些,因为如果用contains,有可能有些文件是".tif.xml"
# 这样即使不是tif,但是还是会被加进来,但用endswith就不会了
if filename.endswith(type):
paths.append(parent + '\\' + filename)
if paths.__len__() is not 0:
for path in paths:
print path
print paths.__len__(), "frames were found."
# 读取第一张影像,获取其大小,然后计算输出视频的大小
tem = cv2.imread(paths[0])
width = int(scale * tem.shape[1])
height = int(scale * tem.shape[0])
# 指定输出视频的编码器以及相关参数
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter(output, fourcc, fps, (width, height))
# 用于统计进度的循环变量
count = 0
# 循环处理每一帧,组成视频
for items in paths:
frame = cv2.imread(items)
frame = cv2.resize(frame, (width, height), interpolation=cv2.INTER_AREA)
out.write(frame)
count += 1
print items + " " + ((count * 1.0 / paths.__len__()) * 100).__str__() + " %"
# 释放VideoWriter对象
out.release()
print "--------------------------------"
print "Output Video Information:"
print "Output path:" + output
print "Width:" + width.__str__()
print "Height:" + height.__str__()
print "FPS:" + fps.__str__()
print "Frames:" + paths.__len__().__str__()
print "Time:" + (paths.__len__() * 1.0 / fps * 1.0).__str__() + " s"
print "--------------------------------"
用户在打开程序后,依次输入输入影像目录、输入影像类型、输出视频大小、输出视频帧率, 程序便会自动将每帧影像组成视频。后续对程序进行了更新,增加了视频输出路径的设置。百度云程序已经更新。
2.测试
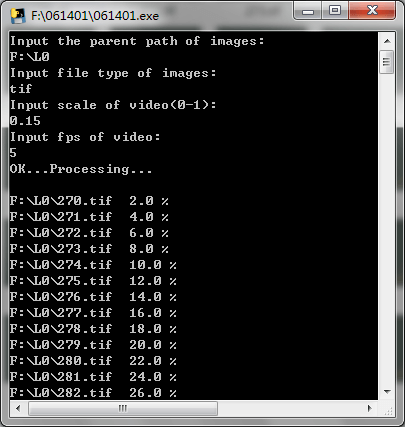
如下是电脑中的影像,一共有50帧。
 打开程序,按照提示依次输入如下:
打开程序,按照提示依次输入如下:
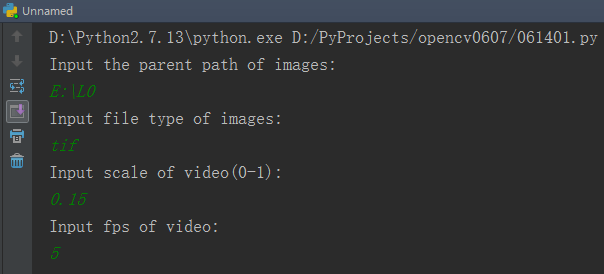 由于原始的tif影像宽有4000多像素,因此将其设置小一些,缩放因子设置为0.15,
这样输出视频的宽为615,比较容易读取和处理。
同时这里为了让视频时间长一些,将帧率设置成了5,这样视频时长一共有10秒。
如果设置成20或25,就只有2秒左右,太短了。
输入完成后按回车,程序便会开始运行,如下。
由于原始的tif影像宽有4000多像素,因此将其设置小一些,缩放因子设置为0.15,
这样输出视频的宽为615,比较容易读取和处理。
同时这里为了让视频时间长一些,将帧率设置成了5,这样视频时长一共有10秒。
如果设置成20或25,就只有2秒左右,太短了。
输入完成后按回车,程序便会开始运行,如下。
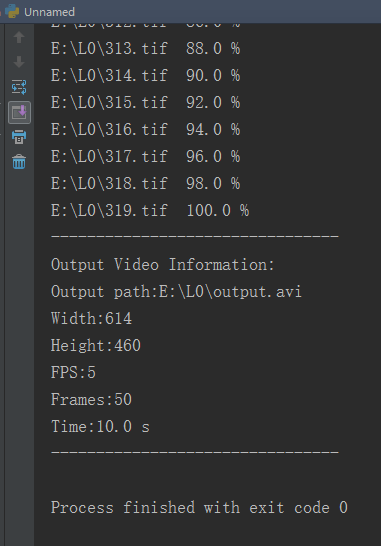
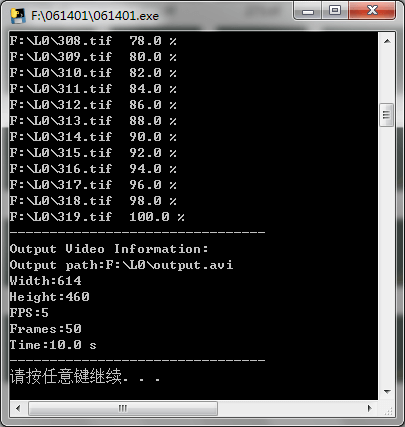
 完成之后会输出导出视频的相关信息,如下:
完成之后会输出导出视频的相关信息,如下:
 在输出目录中找到视频文件打开,可以看到是可以正常播放的,说明输出成功。
在输出目录中找到视频文件打开,可以看到是可以正常播放的,说明输出成功。
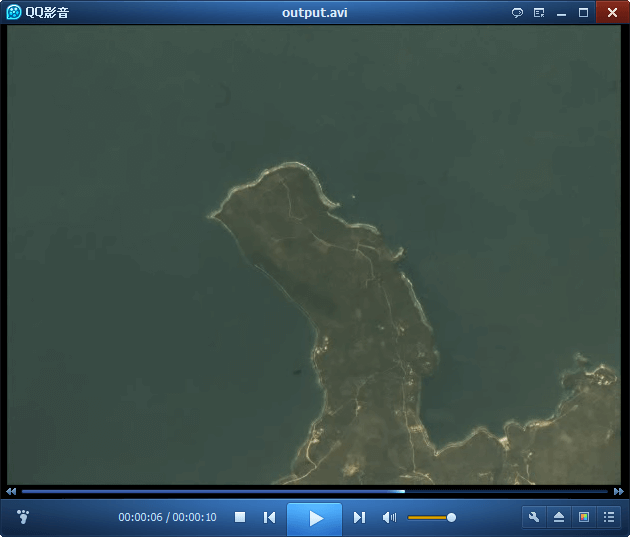 这样我们便有了“煮饭的米”,基于此视频,可以继续下一步的研究了。
这样我们便有了“煮饭的米”,基于此视频,可以继续下一步的研究了。
此外,在测试中发现,有时会出现生成的视频中某一帧是黑色或者只有一半等异常情况,如下图所示。
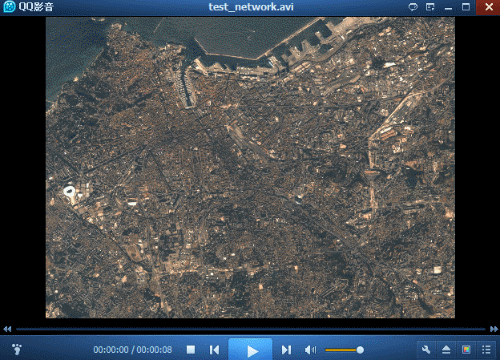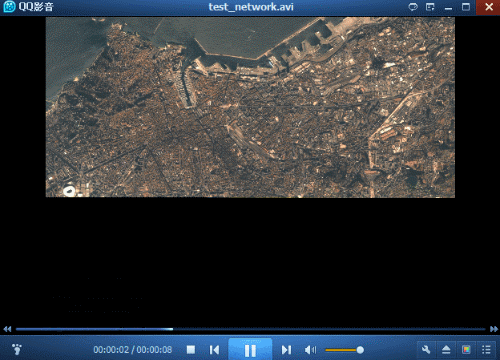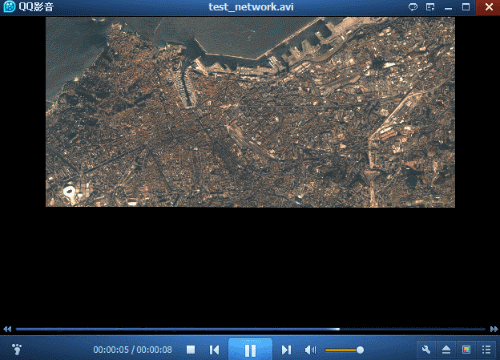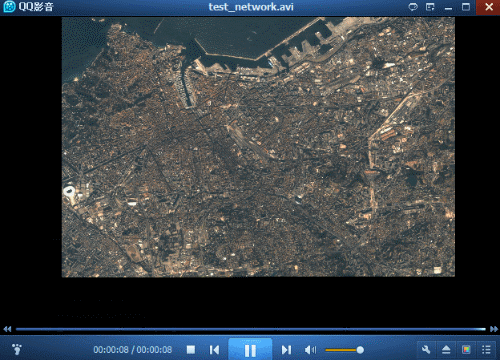 经过查找原因,和代码关系不大,主要与磁盘有关。如果传输速率过低就很容易出现这种情况。
例如一帧影像是30MB的tif文件,但是传输速率只有10MB/s。这样需要3s才能读取完一张影像。
因此生成很大的视频时最好考虑在配置较好的电脑上进行。当然如果每一帧都不大,那么在普通电脑上运行就可以了。
经过查找原因,和代码关系不大,主要与磁盘有关。如果传输速率过低就很容易出现这种情况。
例如一帧影像是30MB的tif文件,但是传输速率只有10MB/s。这样需要3s才能读取完一张影像。
因此生成很大的视频时最好考虑在配置较好的电脑上进行。当然如果每一帧都不大,那么在普通电脑上运行就可以了。
3.输出程序
在本机上成功运行后,利用Pyinstaller将脚本打包成exe文件,这样在没有Python环境的电脑上同样可以运行。
如下是在机房的Win7电脑上运行的效果,电脑上没有Python、OpenCV。
 还是依次输入相关参数,按回车开始处理。完成后会显示输出信息。
注意:如果发现无法在控制台中复制粘贴内容,不要着急,不是控制台坏了。
而是需要设置一下。点击窗口左上角图标,选择“属性”,然后打开“快速编辑模式”,即可通过鼠标右键复制粘贴了。
更多详细步骤可以看这篇博客。
还是依次输入相关参数,按回车开始处理。完成后会显示输出信息。
注意:如果发现无法在控制台中复制粘贴内容,不要着急,不是控制台坏了。
而是需要设置一下。点击窗口左上角图标,选择“属性”,然后打开“快速编辑模式”,即可通过鼠标右键复制粘贴了。
更多详细步骤可以看这篇博客。
 但问题来了。打开输出文件目录发现输出的”output.avi”文件大小是0KB。这立即让我想到了之前在本机上测试时遇到的问题:
没有视频编码器。如果在Python中也出现这种情况,没有报错,但是输出文件为0K的情况。基本都是因为没有编码器。
针对这个问题在这篇博客中已经给出了解决办法,
只需要将两个dll拷贝到Python安装目录下即可。因此对于这个问题,同理,将两个dll拷贝到生成的exe所在的目录下。
但问题来了。打开输出文件目录发现输出的”output.avi”文件大小是0KB。这立即让我想到了之前在本机上测试时遇到的问题:
没有视频编码器。如果在Python中也出现这种情况,没有报错,但是输出文件为0K的情况。基本都是因为没有编码器。
针对这个问题在这篇博客中已经给出了解决办法,
只需要将两个dll拷贝到Python安装目录下即可。因此对于这个问题,同理,将两个dll拷贝到生成的exe所在的目录下。
 再次测试,果然问题解决了。视频成功输出,并且可以被播放器播放了。
再次测试,果然问题解决了。视频成功输出,并且可以被播放器播放了。
 已将生成视频的程序传至百度云,可点击这里下载,密码:5013。
已将生成视频的程序传至百度云,可点击这里下载,密码:5013。
二、模板匹配目标检测
在前面学习了模板匹配,也说了它的特点。那就是待匹配的目标必须要和模板一模一样,包括大小等等。
不同的缩放都会造成匹配错误。根据这个特点,模板匹配可能并不适合在日常的视频中使用,
因为普通视频中某个物体可能存在着各种变形,再加上大小的缩放,让模板匹配很难发挥作用。
但是在卫星视频中,却没有这样的情况。卫星视频总体是比较稳定的。卫星视频有如下特点,
一是视频经过稳像后,图像十分稳定。而是视频中的运动物体运动速度相对稳定、匀速。
因为在视频中能看到运动的一般是道路上的车、飞机等等稍大的目标。
同时因为卫星拍摄时不会出现调焦、剧烈晃动等情况,所以物体大小(尺度)、角度相对固定。
以上这几点恰恰为模板匹配在卫星视频目标检测与识别带来了可能。通过逐帧对影像进行模板匹配,
可以起到连续追踪物体的效果。
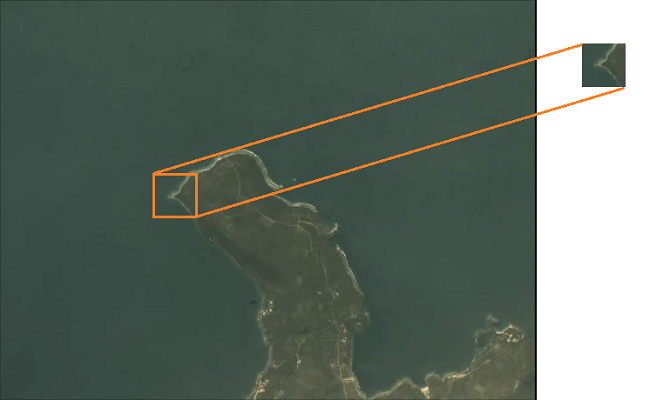
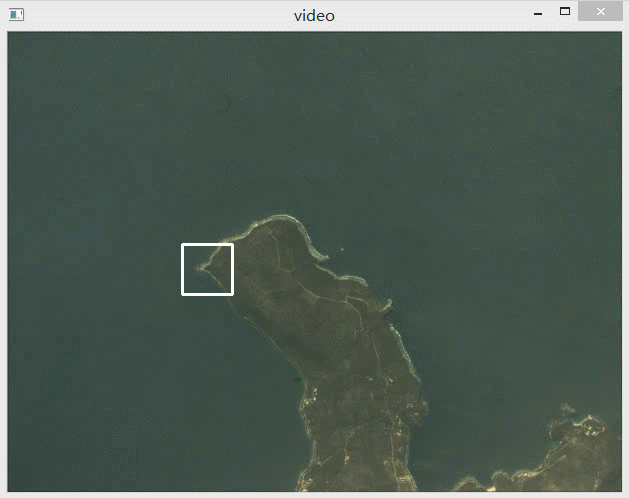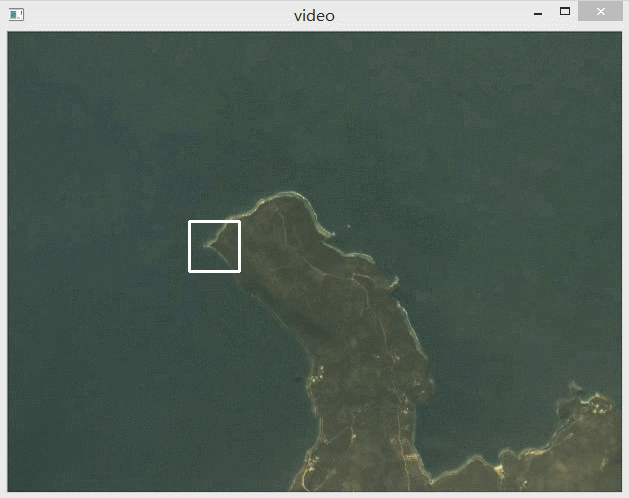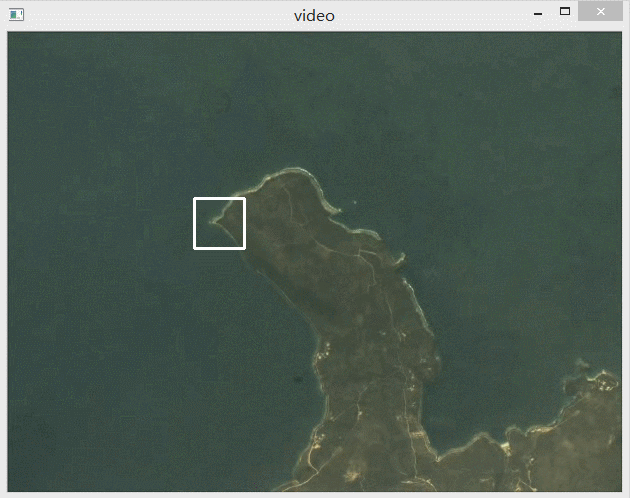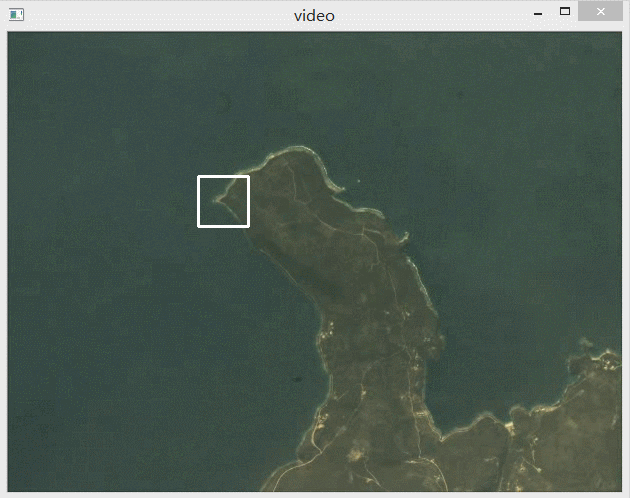
首先在视频中选择一块区域作为模板截图保存,如图是选择的模板区域。
 代码如下:
代码如下:
# coding=utf-8
import cv2
# 打开待识别的视频
cap = cv2.VideoCapture("E:\\output.avi")
# 加载预先选好的模板
template = cv2.imread("E:\\template.png")
# 获取模板的宽高
h = template.shape[0]
w = template.shape[1]
# 根据视频信息计算每一帧的等待时间
waitTime = 1
if cap.get(5) != 0:
waitTime = int(1000.0 / cap.get(5))
while cap.isOpened():
ret, frame = cap.read()
# 判断帧内容是否为空,不为空继续
if frame is None:
break
else:
# 逐帧进行模板匹配
res = cv2.matchTemplate(frame, template, cv2.TM_CCOEFF)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
# 绘制目标区域
cv2.rectangle(frame, top_left, bottom_right, (255, 255, 255), 2)
# 显示结果
cv2.imshow("video", frame)
k = cv2.waitKey(waitTime) & 0xFF
if k == 27:
break
cap.release()
下面动图展示了识别效果,可以看到有效识别出了选中的这一块区域。
第二幅图是R值的动态变化图像,可以看到最亮的那一点就是我们识别出来的目标点。
 此外,更进一步,在模板匹配部分嵌入计时代码,研究了模板匹配中同一算法标准化和非标准化的耗时,绘制出了如下折线图。
此外,更进一步,在模板匹配部分嵌入计时代码,研究了模板匹配中同一算法标准化和非标准化的耗时,绘制出了如下折线图。
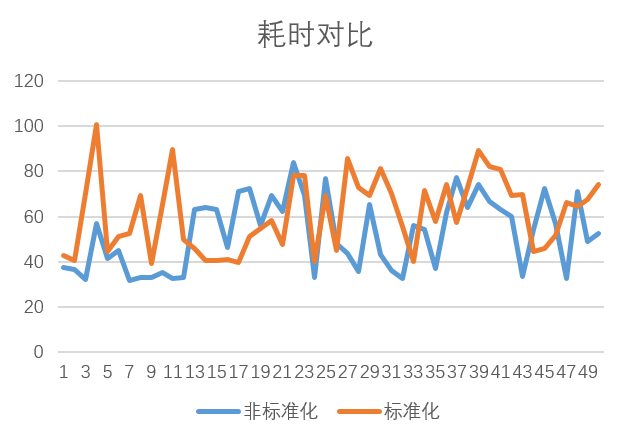 由于计算机硬件配置等因素,因此不用在意绝对时间,观察两条折线的走势可以发现,非标准化曲线基本是在标准化下面的。
以上代码便实现了基于模板匹配的目标识别。
由于计算机硬件配置等因素,因此不用在意绝对时间,观察两条折线的走势可以发现,非标准化曲线基本是在标准化下面的。
以上代码便实现了基于模板匹配的目标识别。
三、追踪与轨迹提取
基于上面的代码,更进一步,可以基于帧间像素坐标的差值,提取出目标的运动轨迹。
# coding=utf-8
import cv2
import numpy as np
# 打开待识别的视频
cap = cv2.VideoCapture("E:\\output.avi")
# 加载预先选好的模板
template = cv2.imread("E:\\template.png")
# 获取模板的宽高
h = template.shape[0]
w = template.shape[1]
# 获取视频图像大小
video_h = int(cap.get(4))
video_w = int(cap.get(3))
# 新建一张与视频等大的影像用于绘制轨迹
track = np.zeros((video_h, video_w, 3), np.uint8)
# 新建一个列表用于接收轨迹点坐标
trackPoints = []
# 根据视频信息计算每一帧的等待时间
waitTime = 1
if cap.get(5) != 0:
waitTime = int(1000.0 / cap.get(5))
while cap.isOpened():
# 读取每帧内容
ret, frame = cap.read()
# 判断帧内容是否为空,不为空继续
if frame is None:
break
else:
# 逐帧进行模板匹配
res = cv2.matchTemplate(frame, template, cv2.TM_CCOEFF)
# 坐标相关计算
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
center_point = ((top_left[0] + bottom_right[0]) / 2, (top_left[1] + bottom_right[1]) / 2)
trackPoints.append(center_point)
# 绘制运动轨迹
# 判断如果轨迹点列表里只有一个点,画点,否则直线连接列表里的倒数第一和第二个点
if trackPoints.__len__() == 1:
cv2.circle(track, center_point, 1, (255, 255, 255), -1)
else:
cv2.line(track, trackPoints[-2], trackPoints[-1], (255, 255, 255), 1)
# 绘制目标识别框
cv2.rectangle(frame, top_left, bottom_right, (255, 255, 255), 2)
# 显示结果
cv2.imshow("track", track)
cv2.imshow("video", frame)
# 退出控制
k = cv2.waitKey(waitTime) & 0xFF
if k == 27:
break
# 输出轨迹坐标
print trackPoints
# 释放VideoCapture对象
cap.release()
实现的效果如下:
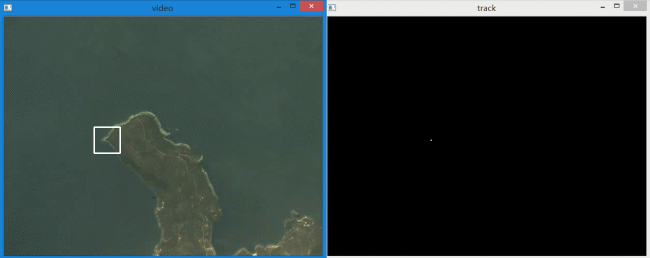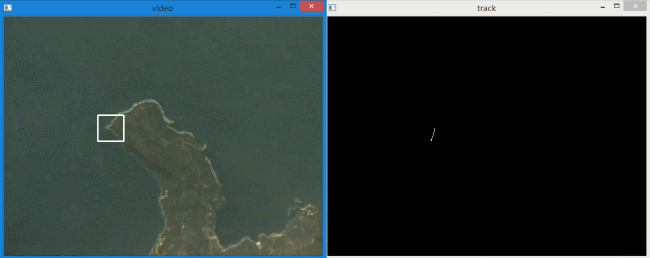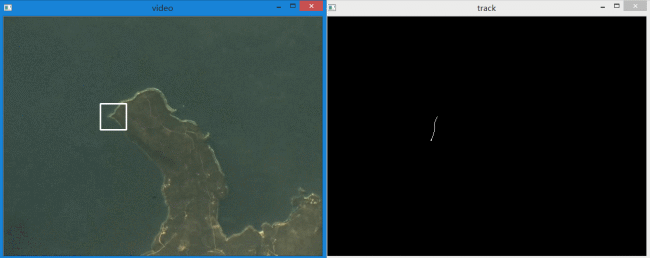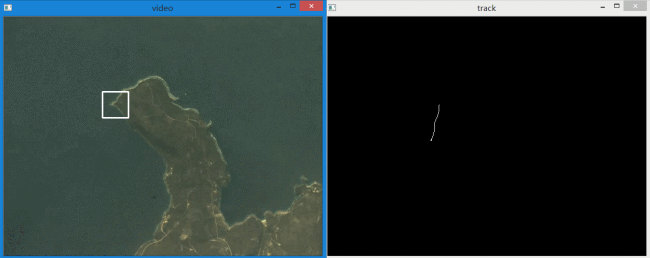 左边是识别出的目标,右边是目标运动轨迹。下面是单独的轨迹放大动图。
左边是识别出的目标,右边是目标运动轨迹。下面是单独的轨迹放大动图。

四、算法优化
上面的算法中,在模板匹配这一步,传入的是整帧图像。但是其实并没有必要传入整幅图像。 原因在于,在一开始就分析了在卫星视频中物体运动基本是匀速而且缓慢(从图像上来看)的。 因此上一帧和下一帧的差别(像素差)其实并不会太大(会在下面论证到底是什么范围)。 在这种情况下每次还是全图匹配,自然会多很多的计算量。 因此可以根据目标的运动动态地进行搜索范围优化。这样整个算法流程就变为了:
- 1.首先传入第一帧影像,全图搜索进行匹配,找到最佳匹配点坐标并记录下来
- 2.对于第二帧影像,根据上一帧匹配的坐标,向外拓展一定范围,形成新的图像
- 3.在新的图像上进行匹配,记录下最佳匹配坐标
- 4.重复2、3步操作,直到所有帧处理完成
1.实现代码
代码如下:
# coding=utf-8
import cv2
import numpy as np
# 输入待识别视频的路径
video_path = raw_input("Input the path of video:\n")
# 打开待识别的视频
cap = cv2.VideoCapture(video_path)
# 输入已选择模板图像的路径
template_path = raw_input("Input the path of template:\n")
# 加载预先选好的模板
template = cv2.imread(template_path)
# 获取模板的宽高
h = template.shape[0]
w = template.shape[1]
# 获取视频图像大小
video_h = int(cap.get(4))
video_w = int(cap.get(3))
# 设置新窗口的大小
d = max(h, w)
# 新建列表用于存放各种类型的坐标点
# tlp用于存放待选窗口的左上角点
# rbp用于存放待选窗口的右下角点
# bottom_right_points用于存放目标区域的右下角点
# center_points用于存放目标区域的中心点
# trackPoints用于存放目标区域的左上角点
tlp = [(0, 0)]
rbp = [(video_w, video_h)]
bottom_right_points = []
center_points = []
trackPoints = []
# 新建循环变量
count = 0
# 新建一张与视频等大的影像用于绘制轨迹
track = np.zeros((video_h, video_w, 3), np.uint8)
# 根据视频信息计算每一帧的等待时间
waitTime = 1
if cap.get(5) != 0:
waitTime = int(1000.0 / cap.get(5))
while cap.isOpened():
# 读取每帧内容
ret, frame = cap.read()
# 判断帧内容是否为空,不为空继续
if frame is None:
break
else:
# 判断是否第一次
if count == 0:
res = cv2.matchTemplate(frame, template, cv2.TM_CCOEFF)
else:
# 如果不是第一次,则在上一次指定的小窗口内寻找
res = cv2.matchTemplate(frame[tlp[count][0]:rbp[count][0], tlp[count][1]:rbp[count][1]], template,
cv2.TM_CCOEFF)
# 坐标相关计算
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# 目标区域在原图中的左上角点坐标
top_left = (max_loc[0] + tlp[count][1], max_loc[1] + tlp[count][0])
# 计算待选窗口左上角点坐标
tlx = top_left[0] - d
tly = top_left[1] - d
# 判断是否越界,越界则设置为0
if tlx < 0:
tlx = 0
if tly < 0:
tly = 0
range_tl = (tlx, tly)
# 计算待选窗口右下角点坐标
rbx = top_left[0] + w + d
rby = top_left[1] + h + d
# 判断是否越界,越界设置为视频长宽最大值
if rbx > video_w:
rbx = video_w
if rby > video_h:
rby = video_h
range_rb = (rbx, rby)
# 将待选窗口左上角点坐标和右下角点坐标依次添加到列表中
tlp.append(range_tl)
rbp.append(range_rb)
# 根据目标区域的左上角点坐标计算右下角点坐标、中心点坐标
bottom_right = (top_left[0] + w, top_left[1] + h)
center_point = ((top_left[0] + bottom_right[0]) / 2, (top_left[1] + bottom_right[1]) / 2)
# 将目标区域的左上角点、中心点、右下角点坐标依次加入列表
trackPoints.append(top_left)
bottom_right_points.append(bottom_right)
center_points.append(center_point)
# 绘制运动轨迹
# 判断如果轨迹点列表里只有一个点,画点,否则直线连接列表里的倒数第一和第二个点
if trackPoints.__len__() == 1:
cv2.circle(track, top_left, 1, (255, 255, 255), -1)
cv2.circle(track, bottom_right, 1, (255, 255, 255), -1)
cv2.circle(track, center_point, 1, (0, 0, 255), -1)
else:
cv2.line(track, trackPoints[-2], trackPoints[-1], (255, 255, 255), 1)
cv2.line(track, bottom_right_points[-2], bottom_right_points[-1], (255, 255, 255), 1)
cv2.line(track, center_points[-2], center_points[-1], (0, 0, 255), 1)
# 循环变量赋值
count += 1
# 显示结果
# 绘制目标识别框
cv2.rectangle(frame, top_left, bottom_right, (255, 255, 255), 2)
cv2.imshow("track", track)
cv2.imshow("video", frame)
# 退出控制
k = cv2.waitKey(waitTime) & 0xFF
if k == 27:
break
# 输出轨迹坐标(目标区域左上角点坐标)
print trackPoints
# 释放VideoCapture对象
cap.release()
为了程序的使用方便,在之前的代码基础上,将视频路径和模板路径由固定值变成用户输入。
并且利用Pyinstaller输出成了可执行文件,这样在没有Python、OpenCV的电脑上同样可以运行。
依次输入视频路径”E:\output.avi”,模板路径”E:\template.png”,回车即开始识别。
实现效果如下:
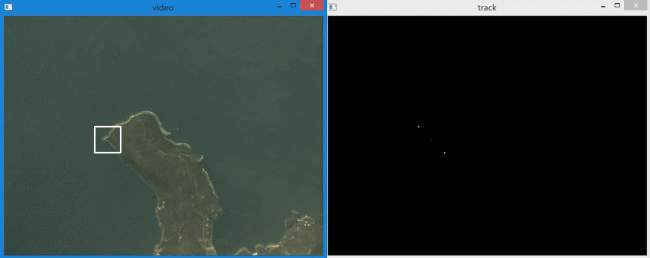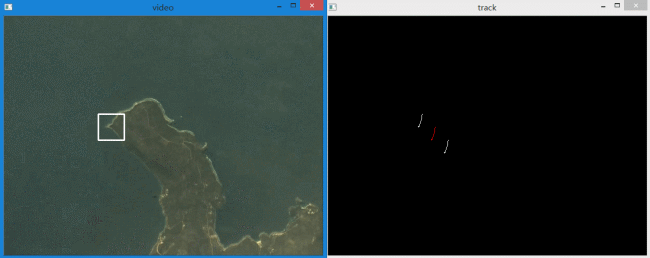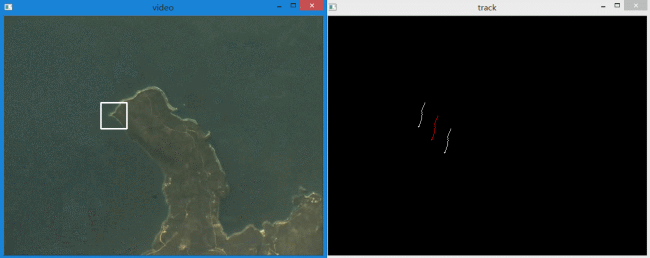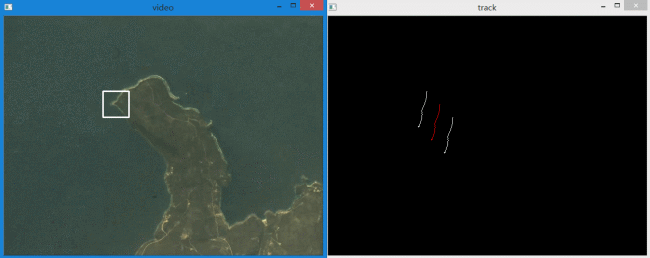 白色的轨迹分别代表左上和右下角点,红色的轨迹表示目标区域中心点。
虽然从结果上看和之前没有任何区别,但其计算效率却得到了很大提升。
在这里设置了搜索窗口的大小为3倍的目标区域,形成一个3×3的九宫格,如下。
白色的轨迹分别代表左上和右下角点,红色的轨迹表示目标区域中心点。
虽然从结果上看和之前没有任何区别,但其计算效率却得到了很大提升。
在这里设置了搜索窗口的大小为3倍的目标区域,形成一个3×3的九宫格,如下。
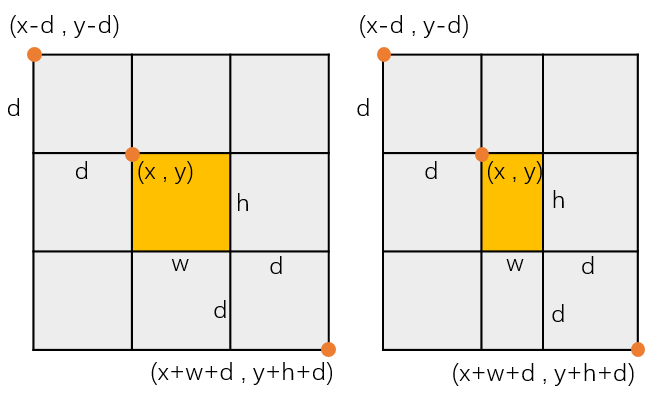 d为模板长宽中的最大值,各坐标关系也在图中标出来了。
经过优化,可以统计得到如下图表:
d为模板长宽中的最大值,各坐标关系也在图中标出来了。
经过优化,可以统计得到如下图表:
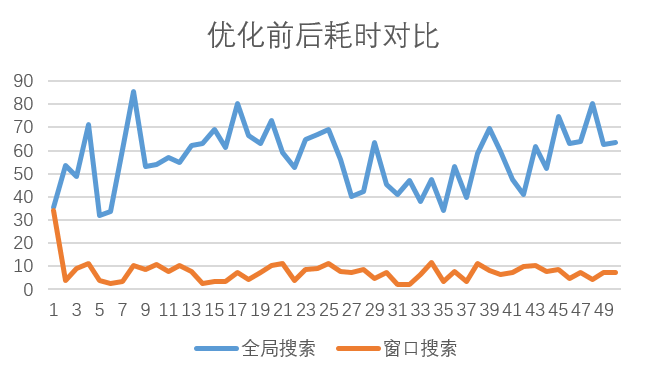 可以看到,每帧处理耗时相较于以前有大幅降低,提升效果十分明显。
从代码中可以看到,第一帧是采用的全图匹配的方式,所以和之前的方法耗时相同。
从第二帧开始就采用了搜索窗口的办法,耗时明显减少。就本机而言,优化前平均耗时是56.78ms,
优化后算上第一帧全局搜索的时间平均值是7.57ms。平均效率提升了8倍左右。
而且优化后的计算量是与待匹配图像大小无关的,只与模板大小有关。在模板大小固定的情况下,
无论是在1000×1000的图像还是在10000×10000的图像中搜索,计算量是相同的。
程序已分享至百度云,可点击这里下载,密码:19pc。
可以看到,每帧处理耗时相较于以前有大幅降低,提升效果十分明显。
从代码中可以看到,第一帧是采用的全图匹配的方式,所以和之前的方法耗时相同。
从第二帧开始就采用了搜索窗口的办法,耗时明显减少。就本机而言,优化前平均耗时是56.78ms,
优化后算上第一帧全局搜索的时间平均值是7.57ms。平均效率提升了8倍左右。
而且优化后的计算量是与待匹配图像大小无关的,只与模板大小有关。在模板大小固定的情况下,
无论是在1000×1000的图像还是在10000×10000的图像中搜索,计算量是相同的。
程序已分享至百度云,可点击这里下载,密码:19pc。
2.窗口大小选择
上面说了优化后的算法只与窗口大小有关。因此如果能尽可能减少窗口的大小,也会降低算法的计算量。
考虑卫星视频中能识别的运动物体基本为汽车、飞机等,而且基本是匀速运动。基于这个前提,
推导出每一帧影像之间,物体所能移动的最大像素。假设某卫星视频的帧率为\(f\),单位为frames/s;分辨率为\(r\),
单位为m/pixel;视频中某物体的运动速度为\(v\),单位为km/h。则公式推导过程如下:
首先由已知速度\(v\)可以计算得到每秒移动的米数,单位为m/s:
而视频每秒有\(f\)帧,所以每秒移动的次数为\(f-1\)。所以每一次移动的距离如下,单位为m:
\[d = \frac{v^{'}}{f-1}=\frac{5v}{18(f-1)}\]卫星的分辨率为\(r\),即表示每一个像素代表地面\(r\)米,所以在影像像素上反映出来的移动距离为pixel,单位为像素:
\[pixel = ceil[\frac{d}{r}]=ceil[\frac{5v}{18r(f-1)}]\]因此最终帧间最大运动估计公式如下:
\[pixel_{max} =ceil\left [ \frac{5v}{18r(f-1)} \right ]\]在公示中ceil[]表示对结果向上取整。如1.3像素取整为2像素。 从式子中可以看出,最大移动距离和速度成正比,和分辨率、帧率成反比。 这也符合我们的认识。 输入相关参数,利用这个公式则可以估计出每一帧目标的运动范围。 即以上一帧物体所在的位置为圆心,以\(pixel_{max}\)为半径的圆形范围。 这对于缩小目标的搜索范围有一定帮助。 例如速度是60km/h的汽车,在分辨率为2m、帧率为24fps的视频中,每一帧最大移动0.36个像素,取整就是1个像素。
而且从这个式子还可以估计出某类物体的最大运动范围。例如对普通人而言,目前最快的移动方式应该是飞机。
飞机的普通运行速度是800km/h,也是目前能达到的最高速(这里不算战斗机等超音速飞机)。
按照视频卫星的分辨率在1.5m,帧率按照20fps计算。
那么可以得出在这个条件下,人类最快的运动反映在卫星视频上,最大不会超过8个像素。
因此,在进行搜索范围的确定时,在这个像素范围以外的所有图像都没有必要考虑了。
因为按照目前人类最快的速度只能在个像素范围内,不可能超出这个范围。
因此根据这个公式可以得到如下常见物体的移动范围表。
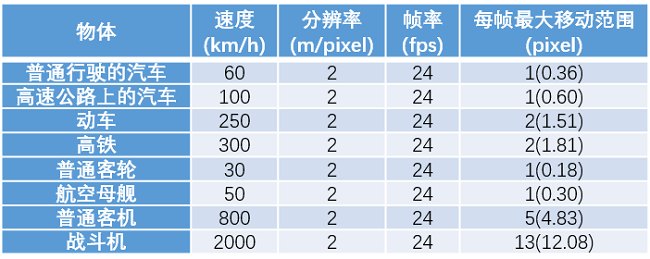 表中的速度取的是物体在正常匀速运行情况下的平均值。这个表格可能会给卫星视频目标识别中搜索范围的选择带来一些参考。
这里没有尝试将这个公式应用到上面的例子中,如果有时间会试试看。
表中的速度取的是物体在正常匀速运行情况下的平均值。这个表格可能会给卫星视频目标识别中搜索范围的选择带来一些参考。
这里没有尝试将这个公式应用到上面的例子中,如果有时间会试试看。
五、小结
本篇博客首先研究了由一帧帧图像生成视频的方法与代码,然后研究了基于模板匹配方法的视频目标提取和轨迹追踪。 基于此又对算法进行了改进,优化了搜索范围,提升了代码的运行效率。最后给出了关于物体帧间最大运动的估计公式。
可以看到基于模板匹配的目标识别还是有一些局限性,例如模板与待识别物体必须大小一致、颜色一致(尽可能)、角度不变(尽可能)。
这些很苛刻的条件在普通视频中几乎无法满足。但在很多卫星视频中却能较好满足,因此取得了不错的效果。但有时也会出现问题。
如当飞机的航向发生改变时,其角度就会改变,产生旋转,这样就会对模板匹配带来影响。
模板匹配有一定的识别方向变化的能力,且与模板和待识别物体大小有关。
当模板和待识别物体比较小时,旋转对其轨迹的影响不大。如下所示,箭头代表飞机,测试了旋转对于检测结果的影响。

 此外模版匹配对于背景的改变有一定的容错能力,当背景改变时任然可以识别出物体。
但是在运动目标颜色与背景相近时容易识别错误,这些问题还需要解决。
因此模板匹配适用于相对简单的动目标提取场景。
对于更复杂的场景,还需要其它更好的能够适应物体方向、大小、颜色变化的算法或改进算法来进行目标检测。
此外模版匹配对于背景的改变有一定的容错能力,当背景改变时任然可以识别出物体。
但是在运动目标颜色与背景相近时容易识别错误,这些问题还需要解决。
因此模板匹配适用于相对简单的动目标提取场景。
对于更复杂的场景,还需要其它更好的能够适应物体方向、大小、颜色变化的算法或改进算法来进行目标检测。
本文作者原创,未经许可不得转载,谢谢配合
