一、优化批量下载程序
在上篇博客中,实现了区域瓦片批量下载功能,得到了一堆瓦片。 首先值得肯定的是,利用增加Header、使用代理IP、以及请求延时的方法,在测试下载了2000多张瓦片后, 没有出现一次403情况。这和之前连续下载几百张就被封掉相比有很大的进步。而且这只是用了6个免费代理IP。 如果可以找到更多更好的IP,效果应该会更好。 但还需要对批量下载程序进行优化,主要有以下问题:
1.黑色瓦片
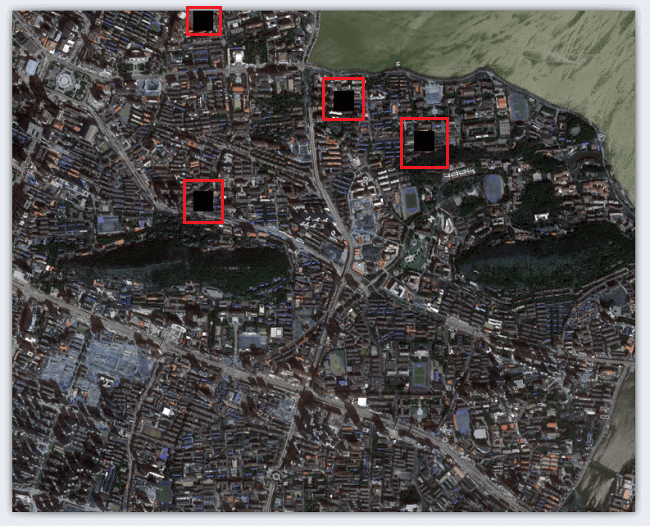
如图所示,是利用之前程序下载的某区域影像。由于之前对每个瓦片只请求一次,所以很容易出现请求失败的情况。
而对于请求失败的瓦片以黑色代替,所以会出现较多黑色瓦片(图中红色框出部分)。比较影响观感。
2.异常捕获
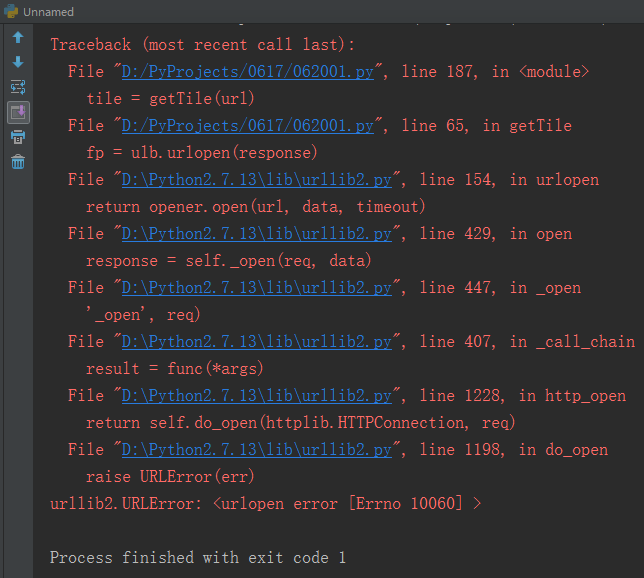
由于之前代码主要是实现功能,所以并没有做什么异常捕获。导致下载可能因错误中断,如下图所示。
3.色彩通道异常、
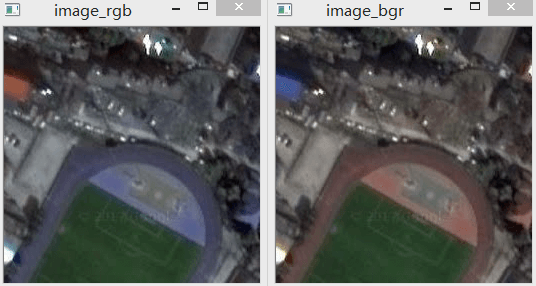
如下是两张同一地区的瓦片,可以看到下载下来的颜色有问题。
在第一幅影像中,塑胶跑道原本应该是橙色的,而这里却变成了蓝色。
相反地,原本是蓝色的屋顶却变成了橙色。在影像中橙色和蓝色颜色反了,原因在于B、G、R通道的顺序不对。
由于OpenCV采用的是BGR顺序,而一般获取到的是RGB顺序,在保存时没有调整,所以导致这种情况出现。
因此需要在获取瓦片时将通道调成OpenCV识别的BGR顺序,再利用OpenCV进行保存。
3.批量下载程序2.0
针对以上问题,在以下几个方面重新优化了代码。
- 1.增加了多次连接请求同一瓦片的功能
- 2.对于失败瓦片,重新尝试下载
- 3.增加了异常捕获,即使出现异常也不致下载中断
- 4.修复瓦片颜色不正确的问题
- 5.新增代理IP地址
- 6.输出下载失败瓦片对应url
改进后的代码如下:
# coding=utf-8
import urllib2 as ulb
import numpy as np
import PIL.ImageFile as ImageFile
import cv2
import math
import random
import time
# 免费代理IP不能保证永久有效,如果不能用可以更新
# https://www.goubanjia.com/
proxy_list = [
'61.191.41.130:80',
'117.143.109.142:80',
'183.95.80.102:8080',
'123.160.31.71:8080',
'166.111.77.32:80',
'218.201.98.196:3128',
'210.38.1.144:8080',
'111.13.141.99:80',
'210.35.171.4:8080',
'222.84.189.38:80',
'61.176.215.34:8080',
]
# 收集到的常用Header
my_headers = [
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
]
# 用于存放获取失败瓦片的url、path
err_urls = []
err_paths = []
# 获取瓦片函数
def getTile(url):
# 每次执行前先暂停t秒
time.sleep(t)
# 随机选择IP、Header
proxy = random.choice(proxy_list)
header = random.choice(my_headers)
print proxy, 'sleep:', t, header
# 基于选择的IP构建连接
urlhandle = ulb.ProxyHandler({'http': proxy})
opener = ulb.build_opener(urlhandle)
ulb.install_opener(opener)
# 按照最大尝试次数连接
for tries in range(maxTryNum):
try:
# 用urllib2库链接网络图像
response = ulb.Request(url)
# 增加Header伪装成浏览器
response.add_header('User-Agent', header)
# 打开网络图像文件句柄
fp = ulb.urlopen(response)
# 定义图像IO
p = ImageFile.Parser()
# 开始图像读取
while 1:
s = fp.read(1024)
if not s:
break
p.feed(s)
# 得到图像
im = p.close()
# 将图像转换成numpy矩阵
arr = np.array(im)
# 将通道顺序变成BGR,以便OpenCV可以正确保存
arr = arr[:, :, ::-1]
return arr
# 抛出异常
except ulb.HTTPError, e:
# 持续尝试
if tries < (maxTryNum - 1):
# 404错误直接退出
if e.code == 404:
print '404 Not Found'
arr = np.zeros((256, 256, 3), np.uint8)
# 将该url、path记录到list中
err_urls.append(url)
err_paths.append(path)
break
# 403错误直接退出
elif e.code == 403:
print '403 Forbidden'
arr = np.zeros((256, 256, 3), np.uint8)
err_urls.append(url)
err_paths.append(path)
break
# 打印尝试次数
print (tries + 1), "time(s) to access", url
continue
else:
# 输出失败信息
print "Has tried", maxTryNum, "times to access", url, ", all failed!"
arr = np.zeros((256, 256, 3), np.uint8)
err_urls.append(url)
err_paths.append(path)
# 统一返回arr
return arr
# 记录经过尝试仍然失败的瓦片
err_final_url = []
# 用于对失败的瓦片重新获取
def errTile(url):
# 每次执行前先暂停t秒
time.sleep(t)
# 随机选择IP、Header
proxy = random.choice(proxy_list)
header = random.choice(my_headers)
print proxy, 'sleep:', t, header
# 基于选择的IP构建连接
urlhandle = ulb.ProxyHandler({'http': proxy})
opener = ulb.build_opener(urlhandle)
ulb.install_opener(opener)
# 按照最大尝试次数连接
for tries in range(maxTryNum):
try:
# 用urllib2库链接网络图像
response = ulb.Request(url)
# 增加Header伪装成浏览器
response.add_header('User-Agent', header)
# 打开网络图像文件句柄
fp = ulb.urlopen(response)
# 定义图像IO
p = ImageFile.Parser()
# 开始图像读取
while 1:
s = fp.read(1024)
if not s:
break
p.feed(s)
# 得到图像
im = p.close()
# 将图像转换成numpy矩阵
arr = np.array(im)
# 将通道顺序变成BGR,以便OpenCV可以正确保存
arr = arr[:, :, ::-1]
return arr
# 抛出异常
except ulb.HTTPError, e:
# 持续尝试
if tries < (maxTryNum - 1):
# 404错误直接退出
if e.code == 404:
print '404 Not Found'
arr = np.zeros((256, 256, 3), np.uint8)
err_final_url.append(url)
break
# 403错误直接退出
elif e.code == 403:
print '403 Forbidden'
arr = np.zeros((256, 256, 3), np.uint8)
err_final_url.append(url)
break
# 打印尝试次数
print (tries + 1), "time(s) to access", url
continue
else:
# 输出失败信息
print "Has tried", maxTryNum, "times to access", url, ", all failed!"
arr = np.zeros((256, 256, 3), np.uint8)
err_final_url.append(url)
# 统一返回arr
# 将通道顺序变成BGR,以便OpenCV可以正确保存
arr = arr[:, :, ::-1]
return arr
# 由x、y、z计算瓦片行列号
def calcXY(lat, lon, z):
x = math.floor(math.pow(2, int(z) - 1) * ((lon / 180.0) + 1))
tan = math.tan(lat * math.pi / 180.0)
sec = 1.0 / math.cos(lat * math.pi / 180.0)
log = math.log(tan + sec)
y = math.floor(math.pow(2, int(z) - 1) * (1 - log / math.pi))
return int(x), int(y)
# 字符串度分秒转度
def cvtStr2Deg(deg, min, sec):
result = int(deg) + int(min) / 60.0 + float(sec) / 3600.0
return result
# 获取经纬度
def getNum(str):
split = str.split(',')
du = split[0].split('°')[0]
fen = split[0].split('°')[1].split('\'')[0]
miao = split[0].split('°')[1].split('\'')[1].split('"')[0]
split1 = cvtStr2Deg(du, fen, miao)
du = split[1].split('°')[0]
fen = split[1].split('°')[1].split('\'')[0]
miao = split[1].split('°')[1].split('\'')[1].split('"')[0]
split2 = cvtStr2Deg(du, fen, miao)
return split1, split2
# 获取经纬度
def getNum2(str):
split = str.split(',')
split1 = float(split[0].split('N')[0])
split2 = float(split[1].split('E')[0])
return split1, split2
# 用户输入更新后的IP文件,如果没有则用代码中的默认IP
ip_path = raw_input("Input the path of IP list file(input \'no\' means use default IPs):\n")
# 判断是否输入IP文件
if ip_path != 'no':
proxy_list = []
file = open(ip_path)
lines = file.readlines()
for line in lines:
proxy_list.append(line.strip('\n'))
print proxy_list.__len__(), 'IPs are loaded.'
# 输入两次请求间的暂停时间
t = 0.1
t = input("Input the interval time(second) of requests(e.g. 0.1):\n")
# 输入最大尝试连接次数
maxTryNum = 5
maxTryNum = input("Input max number of try connection(e.g. 5):\n")
# 输入影像层数
z = 18
z = raw_input("Input image level(0-18):\n")
# 输入左上角点经纬度并计算行列号
lt_raw = raw_input("Input lat & lon at left top(e.g. 30.52N,114.36E):\n")
lt_lat, lt_lon = getNum2(lt_raw)
lt_X, lt_Y = calcXY(lt_lat, lt_lon, z)
# 输入右下角点经纬度并计算行列号
rb_raw = raw_input("Input lat & lon at right bottom(e.g. 30.51N,114.37E):\n")
rb_lat, rb_lon = getNum2(rb_raw)
rb_X, rb_Y = calcXY(rb_lat, rb_lon, z)
# 计算行列号差值及瓦片数
cols = rb_X - lt_X
rows = rb_Y - lt_Y
tiles = cols * rows
count = 0
# 判断结果是否合理
if tiles <= 0:
print 'Please check your input.'
exit()
print tiles.__str__() + ' tiles will be downloaded.'
# 输入保存路径
base = raw_input("Input save path:\n")
print 'Now start...'
# 循环遍历,下载瓦片
for i in range(rows):
for j in range(cols):
# 拼接url
url = 'https://mt2.google.cn/vt/lyrs=s&hl=zh-CN&gl=CN&x=' + (j + lt_X).__str__() + '&y=' + (
i + lt_Y).__str__() + '&z=' + z.__str__()
# 拼接输出路径
path = base + '\\' + z.__str__() + '_' + (j + lt_X).__str__() + '_' + (i + lt_Y).__str__() + '.jpg'
# 获取瓦片
tile = getTile(url)
# 保存瓦片
cv2.imwrite(path, tile)
# 计数变量增加
count = count + 1
# 输出进度信息
print (round((float(count) / float(tiles)) * 100, 2)).__str__() + " % finished"
# 输出下载完成信息
print rows * cols, 'in total,', (rows * cols - err_urls.__len__()), 'successful,', (err_urls.__len__()), 'unsuccessful.'
# 如果不成功瓦片列表不为0,再次尝试
if err_urls.__len__() != 0:
print 'Trying for unsuccessful tiles again...'
for k in range(err_urls.__len__()):
# 获取瓦片
tile = errTile(err_urls[k])
# 保存瓦片
cv2.imwrite(err_paths[k], tile)
# 如果最终不成功瓦片列表不为0,输出最终不成功瓦片url
if err_final_url.__len__() != 0:
# 创建文件
output = open(base + "\err_output.txt", 'w')
output.write('Delete this file before join tiles together!\n')
# 依次输出无法获取瓦片的url
for i in range(err_final_url.__len__()):
output.write(err_final_url[i] + '\n')
print err_final_url[i]
output.close()
首先对连接异常进行捕获,如果是403、404错误,直接退出返回黑色瓦片。因为这不是多次尝试可以解决的问题。 如果不是这些错误,那么尝试以用户输入的maxTryNum为尝试次数进行尝试,成功则返回数据,不成功返回黑色瓦片。 在加入了异常捕获后,可以大大减少“黑色瓦片”的出现。但还有可能有些瓦片因为403、404错误而无法下载, 在程序的最后针对这些瓦片通过随机更换IP和Header进行重新下载。这样基本可以解决403、404错误。 经过测试在1200幅瓦片中实现了0黑色瓦片的效果。而且用户可以指定最大连接次数,从而更好控制下载过程。
4.测试
如下图所示,依次输入相关参数。
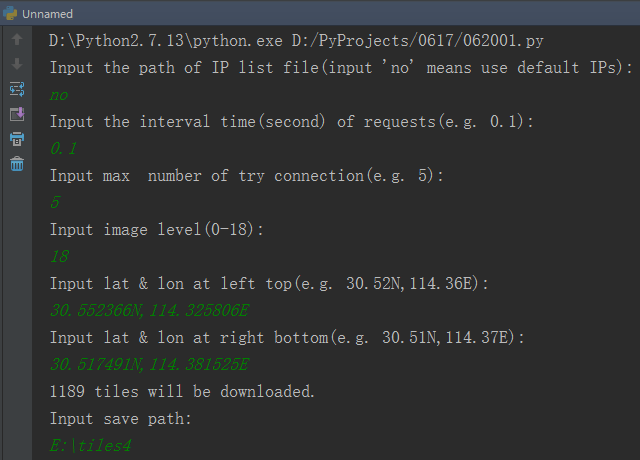 这里使用默认的代理IP、请求暂停是0.1秒,最大尝试连接数是5。
我们要获取的是30.552366N,114.325806E - 30.517491N,114.381525E范围内的18级影像。
至于经纬度如何获取,可以在中国版谷歌地图上长按,就会显示出该点的经纬度,复制修改成指定格式即可。如下所示。
这里使用默认的代理IP、请求暂停是0.1秒,最大尝试连接数是5。
我们要获取的是30.552366N,114.325806E - 30.517491N,114.381525E范围内的18级影像。
至于经纬度如何获取,可以在中国版谷歌地图上长按,就会显示出该点的经纬度,复制修改成指定格式即可。如下所示。
 程序计算出一共有1189张瓦片。最后输入保存瓦片的路径,按回车程序开始下载。完成后如下图所示。
程序计算出一共有1189张瓦片。最后输入保存瓦片的路径,按回车程序开始下载。完成后如下图所示。
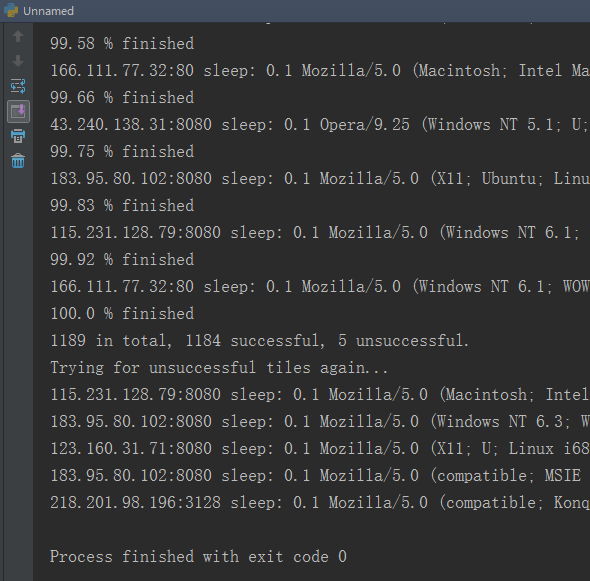 可以看到一共成功下载了1184张瓦片,有5张瓦片下载失败。在最后重新尝试下载,全部下载成功。
下载好的瓦片如下所示,经过检查没有黑块:
可以看到一共成功下载了1184张瓦片,有5张瓦片下载失败。在最后重新尝试下载,全部下载成功。
下载好的瓦片如下所示,经过检查没有黑块:
 打包好的exe点击这里下载,密码:1shx。
以后可能还会继续完善,如下载不同类型、级别的瓦片等等,这些只需要修改请求url中对应的参数即可。
打包好的exe点击这里下载,密码:1shx。
以后可能还会继续完善,如下载不同类型、级别的瓦片等等,这些只需要修改请求url中对应的参数即可。
二、瓦片拼接程序
1.原理与代码
使用上面的批量下载程序会得到很多瓦片。但这并不是想要的最终结果。
我们想要的是一张大图,而不是一个个瓦片。所以需要对瓦片进行拼接,拼成一张图。主要思路和原理很简单,
由于文件名是按照”layer_x_y”的格式保存,因此遍历瓦片获得layer、x、y,
然后直接矩阵操作,利用Numpy的vstack()和hstack()便可完成。代码如下:
# coding=utf-8
import cv2
import numpy as np
import os.path
import math
# 计算经纬度
def calcLatLon(x, y, z, m, n):
lon = (math.pow(2, 1 - z) * (x + m / 256.0) - 1) * 180.0
lat = (360 * math.atan(math.pow(math.e, (1 - math.pow(2, 1 - z) * (y + n / 256.0)) * math.pi))) / math.pi - 90
return lat, lon
path = []
layer = 0
x = 0
y = 0
# 记录x、y、layer
layers = []
xs = []
ys = []
imgs = []
# 用户输入存放影像的文件夹目录,如E:\L0
rootdir = raw_input("Input the parent path of images:\n") + "\\"
for parent, dirname, filenames in os.walk(rootdir):
for filename in filenames:
name = parent + filename
# 读取瓦片
img = cv2.imread(name)
# 附加到list
imgs.append(img)
path.append(name)
# 提取x、y、layer并保存在list中
filename = filename.split('.')
str = filename[0].split('_')
layer = int(str[0])
x = int(str[1])
y = int(str[2])
layers.append(layer)
xs.append(x)
ys.append(y)
print 'Images are loaded.'
# 去除list中的重复元素
layers = list(set(layers))
xs = list(set(xs))
ys = list(set(ys))
# 用于存放每一列的拼图
v_lines = []
# 先按照竖直方向拼成条带
for i in range(0, imgs.__len__(), ys.__len__()):
v_line = tuple(imgs[i:i + ys.__len__()])
v_tuple = np.vstack(v_line)
v_lines.append(v_tuple)
print 'Join images', round((i * 1.0 / imgs.__len__()) * 100, 2), '% finished'
v_tuple = tuple(v_lines)
# 再按水平方向拼接
final = np.hstack(v_tuple)
# 输出拼接后的图像
cv2.imwrite(parent + "output.jpg", final)
# 输出相关信息
output = open(parent + "output.txt", 'w')
output.write('north-west point (x,y):' + (xs[0], ys[0]).__str__() + "\n")
output.write('north-west point (lat,lon):' + calcLatLon(xs[0], ys[0], layers[0], 0, 0).__str__() + "\n")
output.write('south-east point (x,y):' + (xs[-1], ys[-1]).__str__() + "\n")
output.write('south-east point (lat,lon):' + calcLatLon(xs[-1], ys[-1], layers[0], 255, 255).__str__() + "\n")
output.write('rows:' + xs.__len__().__str__() + "\n")
output.write('columns:' + ys.__len__().__str__() + "\n")
output.write('Output image size:' + final.shape[1].__str__() + ' * ' + final.shape[0].__str__())
output.close()
# 控制台中打印相关信息
print 'north-west point (x,y):', (xs[0], ys[0]).__str__()
print 'north-west point (lat,lon):', calcLatLon(xs[0], ys[0], layers[0], 0, 0)
print 'south-east point (x,y):', (xs[-1], ys[-1]).__str__()
print 'south-east point (lat,lon):', calcLatLon(xs[-1], ys[-1], layers[0], 255, 255)
print 'rows:', xs.__len__()
print 'columns:', ys.__len__()
print 'Output image size:', final.shape[1].__str__(), '*', final.shape[0].__str__()
print "------------------------"
print "Output files info:"
print parent + "output.jpg"
print parent + "output.txt"
print "------------------------"
# 显示图像
cv2.imshow("final", final)
cv2.waitKey(0)
2.测试
程序只需要用户输入瓦片存放路径就可以,如下图所示。程序会自动统计有多少瓦片以及行列。
需要注意的是文件夹中不能有其它非瓦片文件,否则会报错。
 按回车之后程序开始运行,首先获取所有瓦片信息,然后进行拼接,控制台中输出进度。
按回车之后程序开始运行,首先获取所有瓦片信息,然后进行拼接,控制台中输出进度。
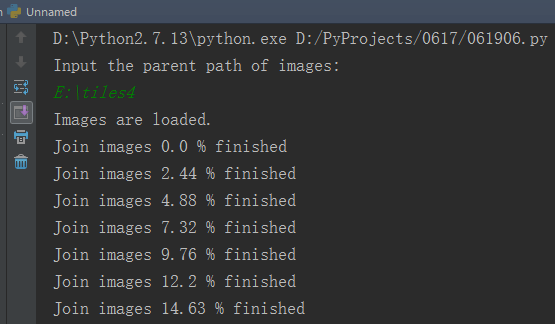 完成后会输出相关信息,如拼接后的影像大小等等。
完成后会输出相关信息,如拼接后的影像大小等等。
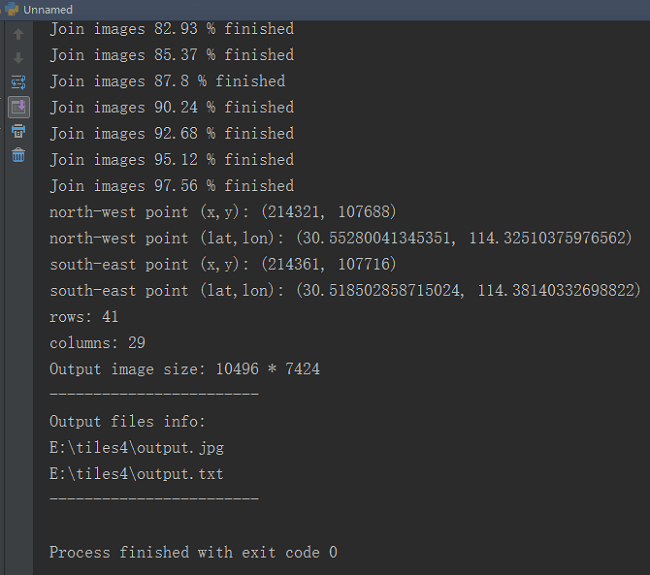 在文件管理器中可以看到输出了两个文件,一个是20多MB的”output.jpg”,一个是”output.txt”。
在文件管理器中可以看到输出了两个文件,一个是20多MB的”output.jpg”,一个是”output.txt”。
 其中jpg是输出影像,如下图所示。
其中jpg是输出影像,如下图所示。
 txt为输出的对应影像信息,基于此可以计算影像上任意一点的经纬度坐标。
txt为输出的对应影像信息,基于此可以计算影像上任意一点的经纬度坐标。
 下面是影像局部细节图。下图是武汉大学信息学部影像。
下面是影像局部细节图。下图是武汉大学信息学部影像。
 下图是武大正门牌坊附近影像。
下图是武大正门牌坊附近影像。
 下图是洪山广场影像。
下图是洪山广场影像。
 可以看到影像的地表分辨率非常高,在第三幅图中路上行驶的大小汽车清晰可见。
exe链接:https://pan.baidu.com/s/1qYbizcK 密码:5iqf。
输出程序的测试界面如下所示。
可以看到影像的地表分辨率非常高,在第三幅图中路上行驶的大小汽车清晰可见。
exe链接:https://pan.baidu.com/s/1qYbizcK 密码:5iqf。
输出程序的测试界面如下所示。
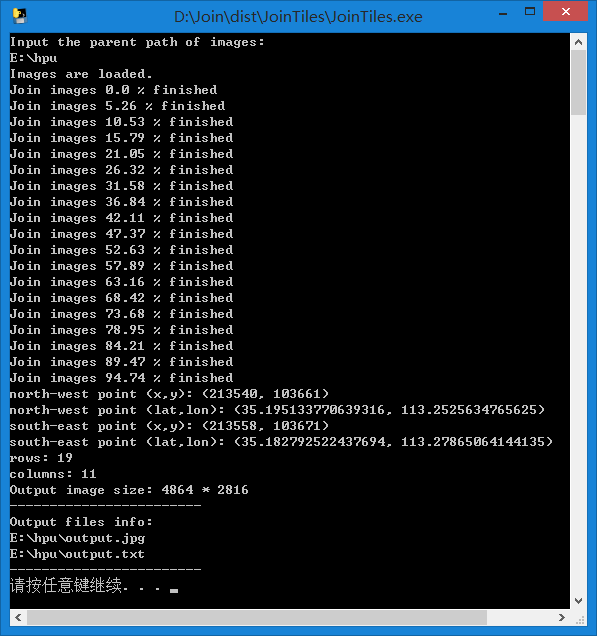 程序正常运行,拼接完成后输出影像如下,下图是河南理工大学的卫星影像。
程序正常运行,拼接完成后输出影像如下,下图是河南理工大学的卫星影像。

三、小结
至此批量下载区域瓦片以及对瓦片进行拼接整个流程对应的程序就写完了。在编写过程中遇到、解决了很多新的问题, 很有收获。
本文作者原创,未经许可不得转载,谢谢配合
