对应《GPU高性能编程CUDA实战中文版》第4章笔记。
矢量求和函数
CPU实现
#include<stdlib.h>
#include<iostream>
//定义常量N表示数组大小
#define N 10
//定义add函数用于相加,注意这里是数组名做参数
void add(int *a, int *b, int *c)
{
//假设这是第0个CPU,因此索引从0开始
int tid = 0;
while (tid < N)
{
c[tid] = a[tid] + b[tid];
//由于只有1个CPU,因此每次加1
tid += 1;
}
}
void main()
{
int a[N], b[N], c[N];
//先对a、b进行赋值初始化
for (int i = 0; i < N; i++){
a[i] = i*i;
b[i] = i + 2;
}
//调用add函数
add(a, b, c);
//输出结果
for (int i = 0; i < N; i++){
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
//系统暂停
system("pause");
}
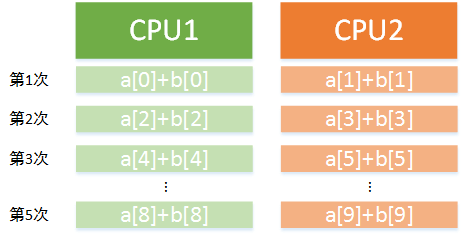
对于上述代码看起来觉得怪怪的是因为循环完全可以用for,而且
循环变量不是i而是tid。这样做的目的是使代码能够在多个
或多核CPU上运行。例如在双核处理器上可将每次递增大小改为2。
这样其中一个核从tid=0开始循环,另一核从tid=1开始循环,第一个核
将偶数索引相加,第二个核则将奇数索引相加。而这也就是并行编程
的思想,同时执行两次,可以理解为步长为2。其执行流程可以用下图表示:
GPU实现
#define N 10
__global__ void add(int *a, int *b, int *c)
{
int tid = blockIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
void main()
{
int a[N], b[N], c[N];
int * dev_a, *dev_b, *dev_c;
for (int i = 0; i < N; i++)
{
a[i] = i*i;
b[i] = i + 2;
}
cudaMalloc((void **)&dev_a, N*sizeof(int));
cudaMalloc((void **)&dev_b, N*sizeof(int));
cudaMalloc((void **)&dev_c, N*sizeof(int));
cudaMemcpy(dev_a, a, N*sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N*sizeof(int), cudaMemcpyHostToDevice);
add <<<1, 1 >>>(dev_a, dev_b, dev_c);
cudaMemcpy(c, dev_c, N*sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < N; i++){
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
system("pause");
}
在这里,可以看出CUDA编程的一些通用模式:
- 调用
cudaMalloc()函数在设备上为三个数组分配内存, 其中两个数组(dev_a、dev_b)包含输入值,dev_c包含计算结果。 - 通过
cudaMemcpy()函数在设备和主机之间进行数据交换,通过 参数指定拷贝的方向。 - 通过尖括号语法,在主机代码
main()中执行add()中的设备代码。 - 为避免内存泄露,在使用完GPU内存后通过
cudaFree()释放它们。 在代码中,是在CPU中对数组进行的赋值。但其实若在GPU中实现 会更快。之所以这样的原因是,我们只把这个加法算法当成某个程序 的一个步骤,数据是由其它程序已经生成好的,我们需要做的就是把 它们放到GPU里进行加法运算。
调用核函数的尖括号里两个参数的含义分别是:第一个参数表示
设备在执行核函数时使用的并行线程块的数量。在本示例中为N。
如果指定的是kernel<<<2,1>>>(),那么可以认为运行时将创建
核函数的两个副本,并以并行的方式来运行它们。每个并行执行环境都
称为一个线程块(Block)。而变量blockIDx.x变量用于判断当前
正在运行的是哪个线程块。该变量是一个内置变量,其包含的值
也就是当前执行设备代码的线程块的索引。
而bolckIdx变量其实包含了x、y、z三个变量。这是因为CUDA支持
多维的线程块数组。对于二维空间的计算问题,如矩阵运算或图像处理,
使用二维索引往往很方便,因为可避免将矩形索引转换为线性索引。
当启动核函数时,我们指定线程块的数量为N。这个线程块的集合称为
一个线程格(Grid)。也即这是个一维的线程格,其中包含N个线程块。
每个线程块的blockIdx.x都是不同的。第一个为0,最后一个为N-1。
在并行执行时,运行时将用相应的线程块索引来替换blockIdx.x。
在CPU的示例中,有for函数用于遍历求和,而在GPU中并没有遍历,
因为将计算任务分配到了各个线程块上,每个线程块其实只执行一次代码。
需要注意的是,在启动线程块数组时,数组每一维的最大数量都不能超过65535。
这是一种硬件限制,如果超过,那么程序会运行失败。
Julia集部分知识点
1.多维索引
类型dim3并不是标准C定义的类型。在CUDA头文件中定义了一些辅助
数据类型来封装多维数组。dim3表示一个三维数组,可以用于指定
启动的线程块的数量。CUDA运行时希望得到一个三维的dim3值,虽然
当前仅是二维图像,这样CUDA运行时自动将最后一维大小设为1。在
代码中,我们完全可以将一个dim3类型的变量放在尖括号中:
dim3 grid(DIM,DIM);
kernel<<<grid,1>>>();
其中DIM表示图像的大小。在第一行代码中,调用grid()的初始化函数,
便建立了一个DIM×DIM大小的二维线程格(第三维为1)。然后将这个
线程格设置到kernel()函数中。这样的结果是运行时会创建DIM×DIM个
线程块,这些线程块分别对应图像中的每一个像素。每个线程块中
包含一个线程。简单理解是例如一个200×200的图像,便指定了开启
40000个线程块同时运行,每个线程块对应一个像素。我们不需要通过
嵌套的for循环来生成像素索引。与矢量相加一样,CUDA运行时将在
变量blockIdx中包含这些索引。在声明线程格的时候,线程的每一维
的大小与图像每一维的大小是相等的,因此在(0,0)和(DIM-1,DIM-1)
之间的每个像素点(x,y)都能获得一个线程块。
2.将二维索引转换为一维索引
利用CUDA内置变量gridDim可以实现。对所有线程块来说,gridDim是
一个常数,用来保存线程格每一维的大小。因此将行索引乘以线程格的宽度,
再加上列索引,就可以得到唯一的一维索引,其范围为(0,DIM*DIM-1)。
int index = x + y * gridDim.x;
3.标识符
__device__表示代码将在GPU而不是主机上运行,只能从
其它__device__函数或者__global__函数中调用它们。
与此类似的还有__host__标识,表示只能在主机上运行,
但一般都省略不写了。
总结
GPU上启动的线程块的集合称为一个线程格。线程格既可以是一维的
线程块集合,也可以是二维的线程块集合。核函数的每个副本都可以
通过内置变量blockIdx来判断哪个线程块正在执行它。同样,我们
还可以通过内置变量gridDim来获取线程格的大小。这两个内置变量
在核函数中是非常有用的,可以用来计算每个线程块需要的数据索引。
其它零碎知识点
1.CUDA错误信息获取与分析
可以利用CUDA内置类型cudaError_t来获取代码执行状态,
取值为int型,返回错误代码。可以根据不同的错误代码发现错误。
虽然我们可以通过查阅相关API找到错误代码的具体含义,但是
也可以直接判断。cudaGetErrorName()、cudaGetErrorString()
便是两个与错误描述相关的函数。其定义为:
__host__ __device__ const char* cudaGetErrorName ( cudaError_t error )
__host__ __device__ const char* cudaGetErrorString ( cudaError_t error )
所以我们可以直接在参数中填入出错的cudaError_t类型变量,即可
获得对应的错误名称和描述。检测某个函数是否执行成功以及返回错误信息的代码如下:
int num;
cudaError_t cudaStatus = cudaGetDeviceCount(&num);
if (cudaStatus != cudaSuccess)
{
printf("Failed!\n");
printf("Error Name: %s\n", cudaGetErrorName(cudaStatus));
printf("Description: %s\n", cudaGetErrorString(cudaStatus));
}else
{
printf("%d Device(s)\n",num);
}
在代码中获取设备的个数,如果不成功,则返回错误信息,否则输出设备个数。 其实更一般的,我们可以把是否执行成功这个操作写成一个宏或工具函数,这样 以后直接调用即可。例如写成判断函数如下:
void checkError(cudaError_t a)
{
if (a != cudaSuccess)
{
printf("Failed!\n");
printf("Error Name: %s\n", cudaGetErrorName(a));
printf("Description: %s\n", cudaGetErrorString(a));
}
}
这样我们只需要在调用API时,加上checkError即可。
int num;
checkError(cudaGetDeviceCount(&num));
2.选择合适的设备
有时一台主机上可能有多个支持CUDA的设备,这时就需要我们根据
情况选择使用哪个设备。我们可以首先利用cudaGetDeviceCount()获取到
当前设备总数,然后遍历,利用cudaGetDeviceProperties()函数获取属性
信息并进行筛选,最终得到符合我们要求的设备的索引。最后利用cudaSetDevice()
函数使用设备设置为那个索引即可。
3.线程、线程块、线程格
CUDA有线程块的概念,将一组线程组织到一起,共同分配一部分资源,然后内部调度执行。 线程块与线程块之间毫无瓜葛。这有利于做更粗粒度的并行。 线程并行是细粒度并行,调度效率高;块并行是粗粒度并行, 每次调度都要重新分配资源,有时资源只有一份,那么所有线程块都只能排成一队,串行执行。 我们的任务有时可以采用分治法,将一个大问题分解为几个小规模问题, 将这些小规模问题分别用一个线程块实现,线程块内可以采用细粒度的线程并行, 而块之间为粗粒度并行,这样可以充分利用硬件资源,降低线程并行的计算复杂度。 适当分解,降低规模,在一些矩阵乘法、向量内积计算应用中可以得到充分的展示。 实际应用中,常常是二者的结合。多个线程块组织成了一个Grid,称为线程格。
4.CUDA修饰符前缀
一个.cu文件内既包含CPU程序(称为主机程序),也包含GPU程序(称为设备程序)。
如何区分主机程序和设备程序?根据声明,凡是挂有__global__或者__device__前缀的函数,
都是在GPU上运行的设备程序,不同的是__global__设备程序可被主机程序调用,
而__device__设备程序则只能被设备程序调用。
没有挂任何前缀的函数,都是主机程序。主机程序显示声明可以用__host__前缀。
5.流并行
我们知道线程并行为细粒度的并行,而块并行为粗粒度的并行,同时也知道了CUDA的线程组织情况,
即Grid-Block-Thread结构。一组线程(Thread)并行处理可以组织为一个block,而一组block并行处理可以组织为一个Grid,
很自然地想到,Grid只是一个网格,我们是否可以利用多个网格来完成并行处理呢?答案就是利用流。
流可以实现在一个设备上运行多个核函数。前面的块并行也好,线程并行也好,
运行的核函数都是相同的(代码一样,传递参数也一样)。
而流并行,可以执行不同的核函数,也可以实现对同一个核函数传递不同的参数,实现任务级别的并行。
核函数代码仍然和块并行的版本一样,只是在调用时做了改变,«<»>中的参数多了两个,
其中前两个和块并行、线程并行中的意义相同,仍然是线程块数、每个线程块中线程数。
第三个表示每个block用到的共享内存大小;第四个为流对象,表示当前核函数在哪个流上运行。
假设我们创建了5个流,每个流上都装载了一个核函数,同时传递参数有些不同,
也就是每个核函数作用的对象也不同。
这样就实现了任务级别的并行,当我们有几个互不相关的任务时,可以写多个核函数,
资源允许的情况下,我们将这些核函数装载到不同流上,然后执行,这样可以实现更粗粒度的并行。
6.线程通信
前面介绍了三种利用GPU并行的方式:线程并行、块并行和流并行。但各个线程所进行的处理是互不相关的, 即两个线程不会产生交集,每个线程都只关注自己。 线程通信在CUDA中有三种实现方式:
- 共享存储器
- 线程同步
- 原子操作
一般采用前两种实现。通常情况是这样:当线程A需要线程B计算的结果作为输入时,需要确保线程B已经将结果写入共享内存中,
然后线程A再从共享内存中读出。同步必不可少,否则,线程A可能读到的是无效的结果,造成计算错误。
同步机制可以用CUDA内置函数:__syncthreads();当某个线程执行到该函数时,进入等待状态,
直到同一线程块(Block)中所有线程都执行到这个函数为止,
即一个__syncthreads()相当于一个线程同步点,确保一个Block中所有线程都达到同步,然后线程进入运行状态。
注意的是,位于同一个Block中的线程才能实现通信,不同Block中的线程不能通过共享内存、同步进行通信,而应采用原子操作或主机介入。
题外话:关于函数参数的问题
数组名就是数组的首地址。 因此在数组名作函数参数时所进行的传送只是地址的传送, 也就是说把实参数组的首地址赋予形参数组名, 形参数组名取得首地址之后,也就等于有了实在的数组。 实际上是形参数组和实参数组为同一数组,共同拥有一段内存空间。 因此我们在定义函数的时候,参数可以写成数组的形式,也可以写成指针形式。
void add(int a[],int b[],int c[]){}
void add(int *a,int *b,int *c){}
而对于一般变量而言,默认采用的是值传递。若要让函数可以修改 传递进来的参数,可以采用两种办法,一种是用指针,另一种是引用。 这两种办法都可以将变量的内存地址传递到函数中,系统不进行变量的拷贝, 而是直接对原始地址进行操作。
void add(int a,int b,int *c){}
void add(int a,int b,int &c){}
本文作者原创,未经许可不得转载,谢谢配合
