一、需求与分析
行政区域边界对于遥感影像裁剪有着很重要的意义。然而很多时候想要找到一个比较好的行政区划边界形文件不得不费一番周折,还有可能一无所获。 因此决定自己动手写个小程序来实现这个功能。其实在移动测绘平台里已经利用百度地图API实现了行政区划边界的获取。 这里采用高德地图的Web API实现行政区划获取,使用GDAL将获取的坐标点转换成形文件。 因此需求是明确的:一是方便获取想要的行政区划边界,二是将结果输出成形文件以便于用ArcGIS等打开从而进行影像的裁切。 所以整个程序设计分为两种模式。一种是将本地已有的经纬度坐标文件转换成坐标文件,另一种是在线获得坐标信息,保存为形文件。
二、代码
# coding=utf-8
try:
from osgeo import gdal
from osgeo import ogr
import urllib2 as ulb
import json
except ImportError:
import gdal
import ogr
# 调用高德地图API获取边界信息
def GetBoundary(keyword):
# API的KEY
key = "bb4c4785c81b07d286fc561879c6037b"
# 拼接请求url
url = "https://restapi.amap.com/v3/config/district?key=" + key + "&keywords=" + keyword + "&subdistrict=0&extensions=all"
# 接收返回的结果
response = ulb.urlopen(url)
response = response.read()
s = json.loads(response)
polyline = s['districts'][0]['polyline']
# 第一次拆分,将多段线拆分开
first_separate = polyline.split("|")
polylines = []
str_polylines = []
# 第二次拆分,将各多段线内的坐标拆开
for item in first_separate:
line = item.split(";")
polylines.append(line)
# 依次遍历每一条多段线,拼接对应格式的字符串
for line in polylines:
list_lat = []
list_lon = []
for item in line:
res = item.split(",")
list_lon.append(res[0])
list_lat.append(res[1])
result_str = ""
print list_lat.__len__(), "points are read."
for i in range(list_lat.__len__()):
result_str += list_lon[i] + " " + list_lat[i] + ","
result_str = "POLYGON ((" + result_str[:-1] + "))"
str_polylines.append(result_str)
return str_polylines
# 写形文件
def WriteVectorFile(filename, content):
# 为了支持中文路径,添加下面这句代码
gdal.SetConfigOption("GDAL_FILENAME_IS_UTF8", "NO")
# 为了使属性表字段支持中文,添加下面这句
gdal.SetConfigOption("SHAPE_ENCODING", "")
# 注册所有的驱动
ogr.RegisterAll()
# 创建数据
strDriverName = "ESRI Shapefile"
oDriver = ogr.GetDriverByName(strDriverName)
if oDriver is None:
print strDriverName, "驱动不可用"
return
# 创建数据源
oDS = oDriver.CreateDataSource(filename)
if oDS == None:
print filename, "创建文件失败!"
return
# 创建图层,创建一个多边形图层,这里没有指定空间参考,如果需要的话,需要在这里进行指定
papszLCO = []
oLayer = oDS.CreateLayer("Polygon", None, ogr.wkbPolygon, papszLCO)
if oLayer == None:
print("图层创建失败!\n")
return
# 下面创建属性表
# 先创建一个叫FieldID的整型属性
oFieldID = ogr.FieldDefn("FieldID", ogr.OFTInteger)
oLayer.CreateField(oFieldID, 1)
# 再创建一个叫FeatureName的字符型属性,字符长度为50
oFieldName = ogr.FieldDefn("FieldName", ogr.OFTString)
oFieldName.SetWidth(100)
oLayer.CreateField(oFieldName, 1)
oDefn = oLayer.GetLayerDefn()
for item in content:
# 创建要素
oFeature = ogr.Feature(oDefn)
oFeature.SetField(0, 0)
oFeature.SetField(1, "Border")
geom = ogr.CreateGeometryFromWkt(item)
oFeature.SetGeometry(geom)
oLayer.CreateFeature(oFeature)
oDS.Destroy()
print("形文件创建完成!\n")
# path为文本文件路径
# spl_str为坐标分隔符,如空格、逗号、制表符等
# format为坐标样式,int类型变量
# 1:latitude longitude
# 2:longitude latitude
def ReadContent(path, spl_str, format):
str_polylines = []
list_lat = []
list_lon = []
# 判断坐标顺序
if format == 1:
for line in open(path):
res = line.split(spl_str)
list_lat.append(res[0])
list_lon.append(res[1].replace("\n", ""))
elif format == 2:
for line in open(path):
res = line.split(spl_str)
list_lon.append(res[0])
list_lat.append(res[1].replace("\n", ""))
result_str = ""
print list_lat.__len__(), "points are read."
for i in range(list_lat.__len__()):
result_str += list_lon[i] + " " + list_lat[i] + ","
result_str = "POLYGON ((" + result_str[:-1] + "))"
str_polylines.append(result_str)
return str_polylines
mode = input("Select mode:\n1:Load points from file.\n2:Get points from Internet.\n")
if mode == 1:
filename = raw_input("Input file path(e.g. E:\input.txt):\n")
separator = raw_input("Input separator of text(for \"\\t\" input \"t\"):\n")
if separator == "t":
separator = "\t"
format = input("Select format of text:\n1:latitude longitude\n2:longitude latitude\n")
str_points = ReadContent(filename, separator, format)
out = raw_input("Input output filename(e.g. F:\out.shp):\n")
WriteVectorFile(out, str_points)
elif mode == 2:
keyword = raw_input("Input name of strict:\n")
str_points = GetBoundary(keyword)
out = raw_input("Input output filename(e.g. F:\out.shp):\n")
WriteVectorFile(out, str_points)
代码中用的比较多的是字符串的拆分与拼接。GDAL用来生成形文件,高德Web API用来获取边界信息。敬告:代码中的KEY是我个人申请的,本着开放共享、方便他人测试的理念进行了公开。但如发现代码中的KEY被大量盗用,我可能会在控制台中删除此KEY,导致其他人均无法使用。如果您需要大量使用请自行前往高德开放平台申请。所以请遵守基本的行为道德规范,营造良好的氛围,不盗用、不乱用KEY,谢谢配合。
[2020-09-13更新]
我向来是不以最坏的恶意来揣测他人的,但是总有些人素质太差。一直在调用我的“搜索服务-关键字查询”。
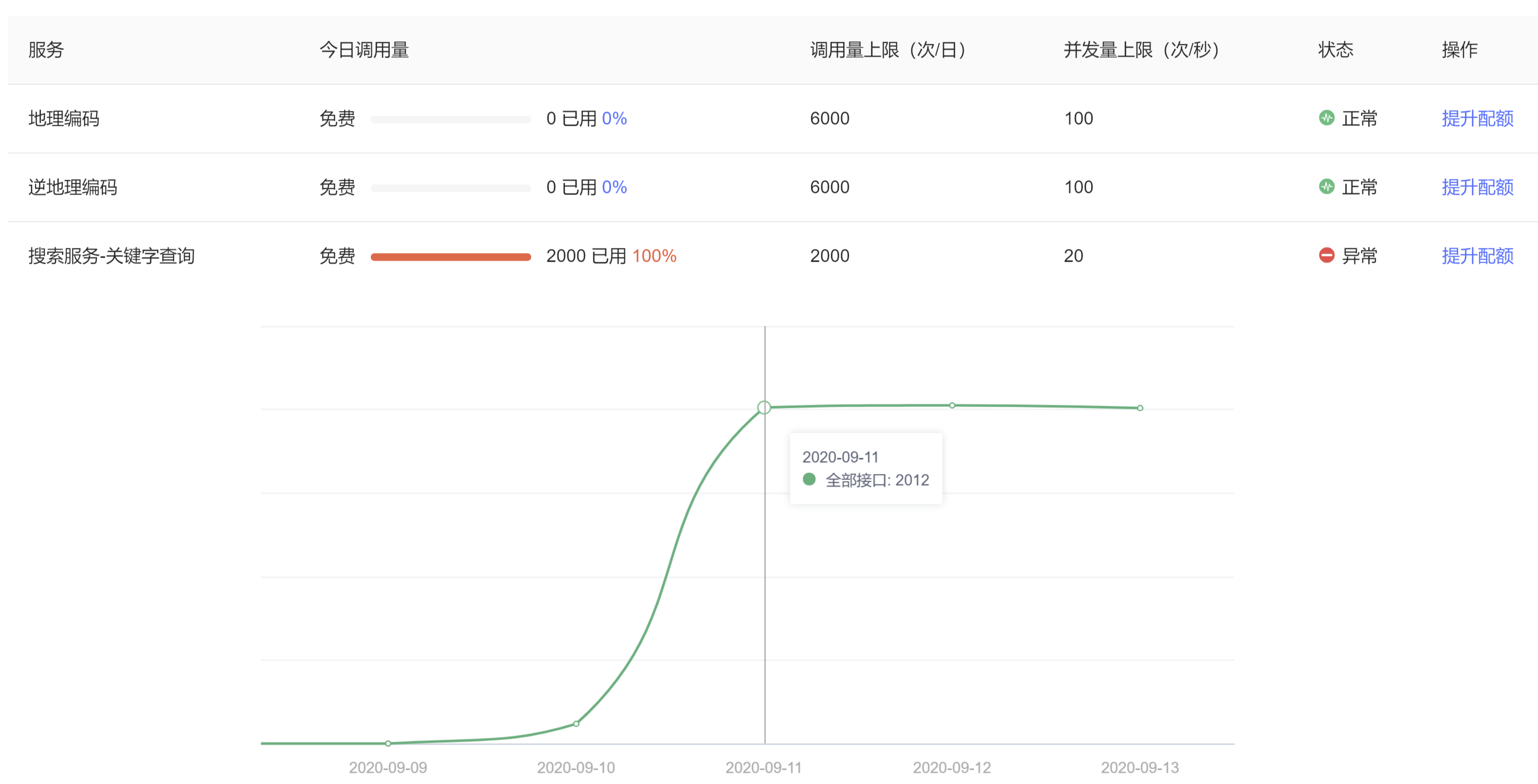 如上图所示,连续好多天连续使用我的KEY,使得高德天天凌晨给我发邮件说配额已满。
如上图所示,连续好多天连续使用我的KEY,使得高德天天凌晨给我发邮件说配额已满。
 既然这样的话,我也没办法。我已经删除了上面代码中的KEY,无法使用了。需要的话你可以自己申请。最后再说一句,好的环境需要大家一起维护,这样自私的行为只会害人害己。
既然这样的话,我也没办法。我已经删除了上面代码中的KEY,无法使用了。需要的话你可以自己申请。最后再说一句,好的环境需要大家一起维护,这样自私的行为只会害人害己。
[2020-09-13更新完毕]
三、测试
1.模式一
如图,首先在移动测绘平台中利用“边界与地址检索”功能搜索“武汉”,即可得到武汉的边界。
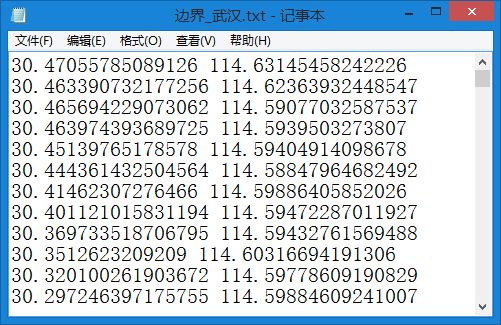
 下图是输出的txt坐标信息。
下图是输出的txt坐标信息。
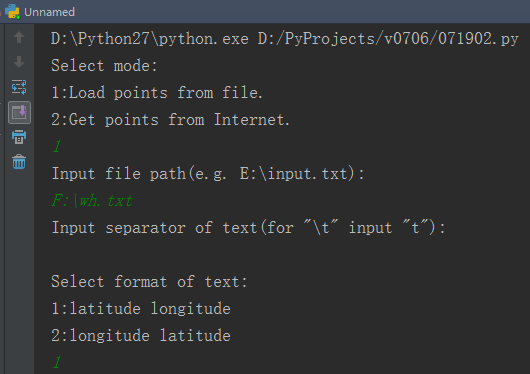
 然后打开程序,选择模式1。然后依次输入文件路径、坐标分隔符(如这里是空格)、坐标格式(这里是纬度-经度)。
然后打开程序,选择模式1。然后依次输入文件路径、坐标分隔符(如这里是空格)、坐标格式(这里是纬度-经度)。
 点击回车,会显示读取的点数。输入输出形文件路径,即可完成。
点击回车,会显示读取的点数。输入输出形文件路径,即可完成。
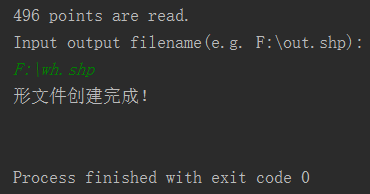 在ArcGIS中打开如下。
在ArcGIS中打开如下。
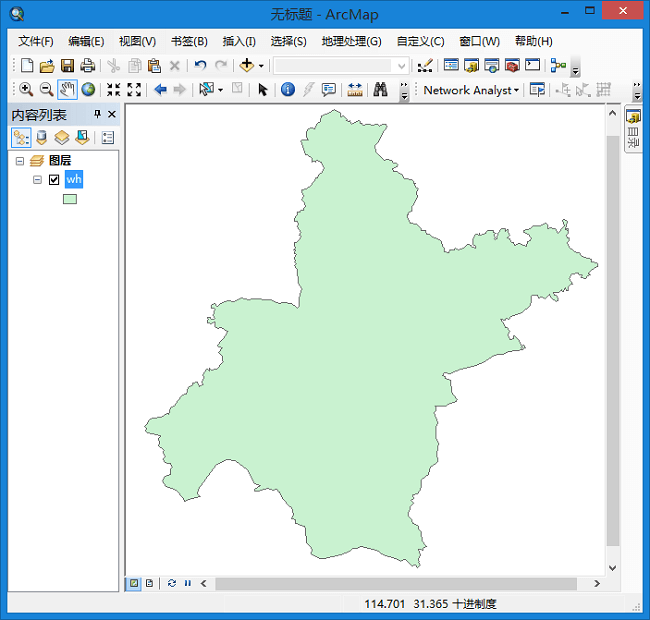
2.模式二
首先选择模式二,然后输入想要查找的边界,如“安徽”。
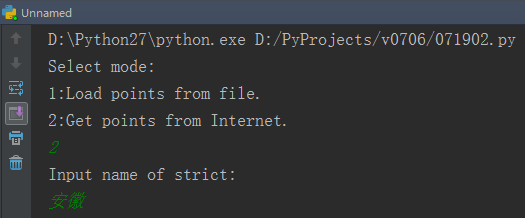 由于不止有一段多段线,所以读取了多段。这时再输入保存路径,回车即可完成。
由于不止有一段多段线,所以读取了多段。这时再输入保存路径,回车即可完成。
 在ArcGIS中打开如下。
在ArcGIS中打开如下。
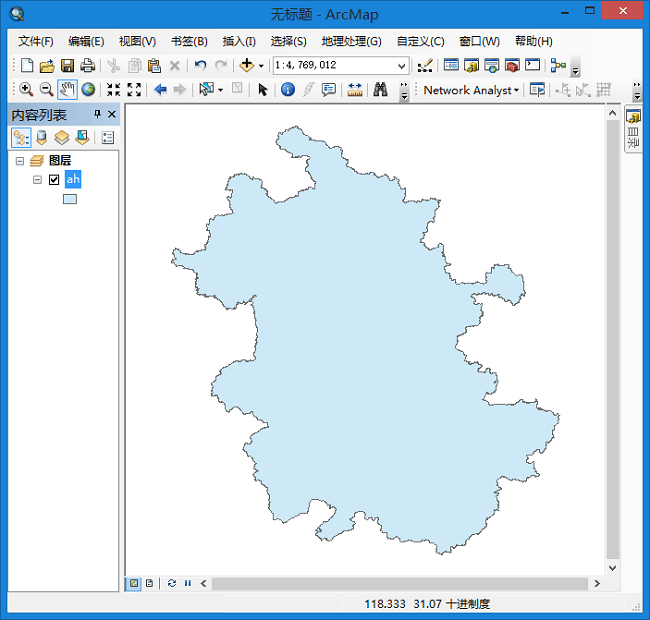
通过两次测试,程序的功能是可以正常使用的。
四、题外话
由于移动测绘平台使用的是百度地图API,这次使用的是高德地图API。
在使用过程中发现,高德地图获取的边界信息更加丰富。
如图是高德和百度数据的对比图。
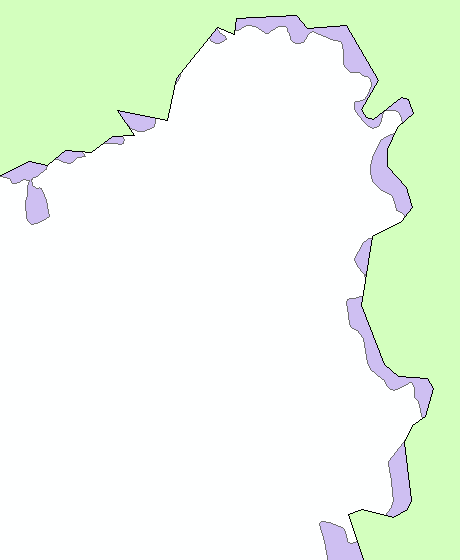 绿色是百度地图数据绘制的轮廓,紫色是高德地图数据绘制的轮廓。可以很明显的看出,高德地图的轮廓信息更加丰富。
从边界点的数量上也可以看出来,百度地图获取到1857个点,而高德地图获取到16783个点。
虽然点的数量并不一定完全能反映精细程度(如同一条线段上只有两个端点是有用的,其它所有点再多,依然不会增加精度),但巨大的差异也能反映出精度的不同。
绿色是百度地图数据绘制的轮廓,紫色是高德地图数据绘制的轮廓。可以很明显的看出,高德地图的轮廓信息更加丰富。
从边界点的数量上也可以看出来,百度地图获取到1857个点,而高德地图获取到16783个点。
虽然点的数量并不一定完全能反映精细程度(如同一条线段上只有两个端点是有用的,其它所有点再多,依然不会增加精度),但巨大的差异也能反映出精度的不同。
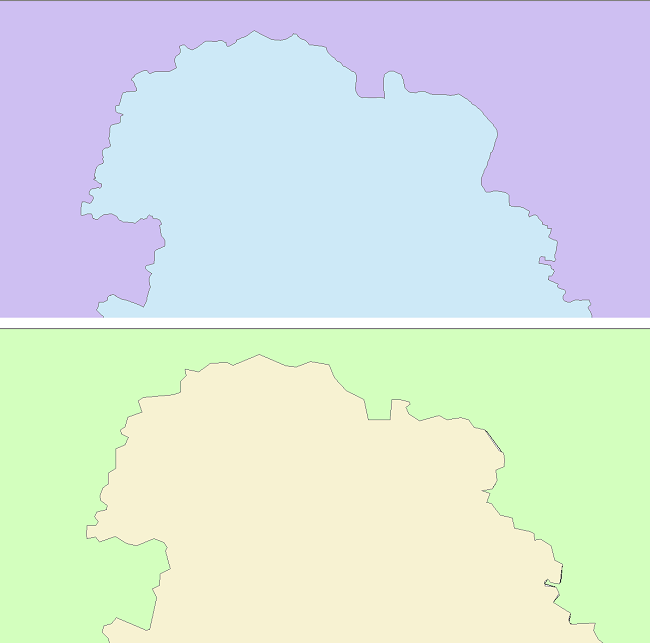 上图是安徽、河南两省交界处。下面是百度数据,上面是高德数据。
最后附上漂亮的全国行政区划图。
上图是安徽、河南两省交界处。下面是百度数据,上面是高德数据。
最后附上漂亮的全国行政区划图。
本文作者原创,未经许可不得转载,谢谢配合
