一、坐标系简介
1.世界坐标系
三维世界中真实的坐标系,用(Xw, Yw, Zw)表示其坐标值。
2.相机坐标系
以相机的光心为坐标原点,习惯让Z轴指向相机前方,X轴向右,Y轴向左,满足右手定则。
3.图像坐标系
以相机光心在图像平面上的投影点为坐标原点,X轴和Y轴方向与相机坐标系相同,用( x , y )表示其坐标值。图像坐标系是用物理单位(例如毫米)表示像素在图像中的位置。
4.像素坐标系
以图像平面的左上角顶点为原点,u轴(X轴)向右与x轴平行,v轴(Y轴)向下与y轴平行。像素坐标系与图像坐标系之间差了一个缩放和原点的平移。
二、相机坐标系与像素坐标系
如下图所示,O-x-y-z为相机坐标系,O’-x’-y’-z’为图像坐标系。点P是空间中一点,在成像平面上的投影点是P’。
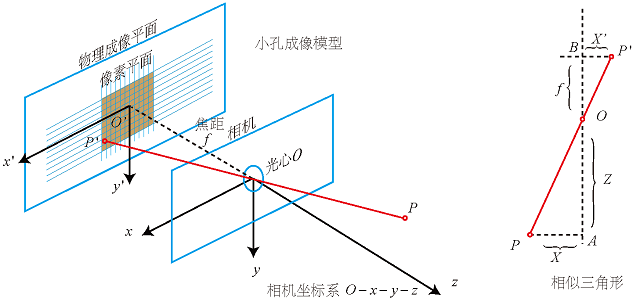 设P在相机坐标系下的坐标是
\([X,Y,Z]^{T}\),P’在图像坐标系的坐标是
\([X^{'},Y^{'},Z^{'}]^{T}\),在像素坐标系下的坐标是
\((u,v)\)。且成像平面到光心的焦距f已知。以此推导相机坐标系与像素坐标系之间的关系。
设P在相机坐标系下的坐标是
\([X,Y,Z]^{T}\),P’在图像坐标系的坐标是
\([X^{'},Y^{'},Z^{'}]^{T}\),在像素坐标系下的坐标是
\((u,v)\)。且成像平面到光心的焦距f已知。以此推导相机坐标系与像素坐标系之间的关系。
首先由三角形相似原理可以得到各坐标的绝对值之间有如下等式。
\[\frac{X^{'}}{X}=\frac{Y^{'}}{Y}=\frac{f}{Z}\]然后整理如下
\[\left\{\begin{matrix} X^{'}=\frac{f}{Z}X\\ Y^{'}=\frac{f}{Z}Y \end{matrix}\right.\]这便是相机坐标系与图像坐标系之间的关系。之前说了,像素坐标系与图像坐标系之间差了一个缩放和平移,因此假设其在u轴(X轴)上缩放了α倍,平移了cx;v(Y轴)上缩放了β倍,平移了cy。因此可以自然的写出下面的公式。
\[\left\{\begin{matrix} u = \alpha X^{'}+c_{x}\\ v = \beta Y^{'}+c_{y} \end{matrix}\right.\]再将上面的两个公式合并,得到如下结果。即P点相机坐标与像素坐标的关系。
\[\left\{\begin{matrix} u = \alpha \frac{f}{Z}X+c_{x}\\ v = \beta \frac{f}{Z}Y+c_{y} \end{matrix}\right.\]这里可以取
\[\left\{\begin{matrix} f_{x}=\alpha f\\ f_{y} = \beta f \end{matrix}\right.\]再次带入可得
\[\left\{\begin{matrix} u = \frac{X}{Z}f_{x}+c_{x}\\ v = \frac{Y}{Z}f_{y}+c_{y} \end{matrix}\right.\]可以将这个式子写成矩阵的形式,看起来会更简洁。
\[\begin{pmatrix} u\\ v\\ 1 \end{pmatrix}=\frac{1}{Z}\begin{pmatrix} f_{x} & 0 & c_{x}\\ 0 & f_{y} & c_{y}\\ 0 & 0 & 1 \end{pmatrix}\begin{pmatrix} X\\ Y\\ Z \end{pmatrix}\]这里的变换用到了齐次坐标,多了一个1=1的恒等式,能看懂就行。中间的3×3矩阵便是相机的内参矩阵K。所以更简单的形式如下。
\[\begin{pmatrix} u\\ v\\ 1 \end{pmatrix}=\frac{1}{Z}K\begin{pmatrix} X\\ Y\\ Z \end{pmatrix}\]更多时候我们可能已知的是相机内参和像素坐标求解该点在相机坐标系下的坐标,因此稍作变换即可。
\[\begin{pmatrix} X\\ Y\\ Z \end{pmatrix}=K^{-1}Z\begin{pmatrix} u\\ v\\ 1 \end{pmatrix}\]这里还有最后一个问题,就是Z我是不知道的,但是在等式右边出现了,因此需要移到左边来,左右两边同时乘以1/Z。
\[\begin{pmatrix} \frac{X}{Z}\\ \frac{Y}{Z}\\ 1 \end{pmatrix}=K^{-1}\begin{pmatrix} u\\ v\\ 1 \end{pmatrix}\]这样便可以计算了。只是需要注意的是,这里的Z被归一化了,同时X、Y坐标也不再是真实的坐标了,和真实坐标相比都差了Z倍。但是它们彼此的比例关系还是没变的。
三、对极几何
两个摄像机的光心C0、C1,三维空间中一点P,在两幅图像中的位置为p0、p1。如下图所示。
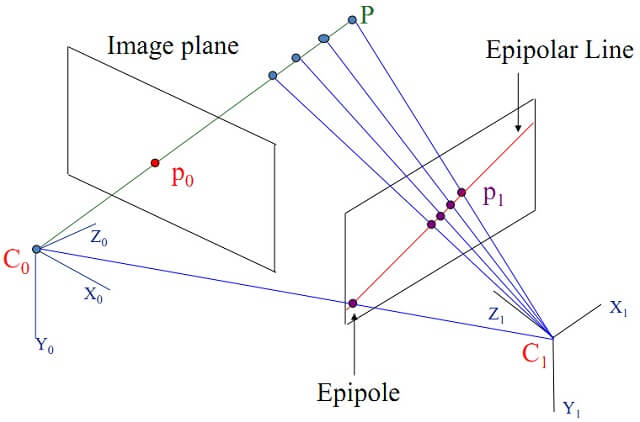 由于C0、C1、P三点共面,所以C0、C1、p0、p1四点共面。由向量共面可以有如下等式成立。
由于C0、C1、P三点共面,所以C0、C1、p0、p1四点共面。由向量共面可以有如下等式成立。
因为两个向量叉乘得到的向量垂直于这个面。而如果两个非零向量垂直,则其点乘为0。
p0在归一化相机坐标系C0以及p1在归一化相机坐标系C1中的表示为:
\[p_{0}=\begin{pmatrix} x_{0}\\ y_{0}\\ 1 \end{pmatrix}_{C_{0}},p_{1}=\begin{pmatrix} x_{1}\\ y_{1}\\ 1 \end{pmatrix}_{C_{1}}\]改写上式变成
\[\overrightarrow{p_{0}}\cdot (\overrightarrow{t}\times R\overrightarrow{p_{1}})=0\]在C0坐标系中,向量C0p0可以表示成p0,在C1坐标系中向量C1p1可以表示成p1。t是两个摄像机光心的平移量。R是从坐标系C1到C0的旋转变换。左乘旋转矩阵R的目的是把向量C1p1在C1坐标系下的表示旋转到C0坐标系下。
一个向量a叉乘一个向量b可以表示为一个反对称矩阵乘以向量b的形式。这时由向量a表示的反对称矩阵(skew symmetric matrix)如下:
\[[a]_{X}=\begin{pmatrix} 0 & -a_{3} & a_{2}\\ a_{3} & 0 & -a_{1}\\ -a_{2} & a_{1} & 0 \end{pmatrix}\]所以上式可以写成
\[p_{0}^{T}[t]_{X}Rp_{1}=0\]这里全部写成了矩阵的形式。我们定义
\[E=[t]_{X}R\]这是一个3×3的矩阵。所以有
\[p_{0}^{T}Ep_{1}=0\]也即
\[\begin{pmatrix} x_{0} & y_{0} & 1 \end{pmatrix}\begin{pmatrix} E_{11} & E_{12} & E_{13}\\ E_{21} & E_{22} & E_{23}\\ E_{31} & E_{32} & E_{33} \end{pmatrix}\begin{pmatrix} x_{1}\\ y_{1}\\ 1 \end{pmatrix}=0\]由于9个E是待求量,因此将这个式子拆开重新组合,写成Ax=0的形式。
\[\begin{pmatrix} x_{0}x_{1} & x_{0}y_{1} & x_{0} & y_{0}x_{1} & y_{0}y_{1} & y_{0} & x_{1} & y_{1} & 1 \end{pmatrix}\begin{pmatrix} E_{11}\\ E_{12}\\ \vdots \\ E_{33} \end{pmatrix}=0\]由于这个方程为0且左边只有乘法,所以对左边进行任意缩放都不会影响方程的解。
\[\begin{pmatrix} x_{0}x_{1} & x_{0}y_{1} & x_{0} & y_{0}x_{1} & y_{0}y_{1} & y_{0} & x_{1} & y_{1} & 1 \end{pmatrix}E_{33}\begin{pmatrix} E_{11}/E_{33}\\ E_{12}/E_{33}\\ \vdots \\ 1 \end{pmatrix}=0\]因此虽然E有9个未知数,但是有一个变量E33是缩放因子,因此实际只有8个未知数,这就是尺度Scale的由来。
Ax=0,x有8个未知量,因此需要A的秩为8,所以至少需要8对匹配点,这便是8点法。如果多于8对点,则变为求解最小二乘问题了。这个方程的解就是对系数矩阵A进行SVD分解以后,V矩阵最右边那一列的值。
上面使用8点法计算E的过程使用的约束是
\[p_{0}^{T}Ep_{1}=0\]这便是对极约束。在求得E之后,就可以通过E求得旋转和平移了。一个3x3的矩阵是本征矩阵的充要条件是对它奇异值分解后,它有两个相等的奇异值,并且第三个奇异值为0。然而在实际计算过程中,匹配点坐标存在误差,这会使得计算出的E可能不会满足之前提到的那条性质,所以我们需要把计算出的E投影到真正的本征矩阵空间,也就是使得它的三个奇异值中两个相等,一个为0。投影的方法如下,实际就是强制改变这个矩阵的奇异值。在应用的时候,考虑到E矩阵反正已经是缩放了的,所以更多的是直接令奇异值为(1,1,0)。
\[[U,\Sigma,V]=svd(E), E'=Udiag([1,1,0])V'\]即先对由方程求解出来的E进行svd分解,然后替换奇异值重新生成一个新的E’,便可以用它做后续计算了。
由本质矩阵E恢复t,R的公式如下。
\[R = UR_{Z}^{T}(\pm \frac{\pi}{2})V^{T},\widehat{t}=UR_{Z}(\pm \frac{\pi}{2})\Sigma U^{T}\]这里Rz表示绕Z轴正负旋转90度的矩阵。
\[R_{Z}(\theta )=\begin{pmatrix} cos\theta & sin\theta & 0\\ -sin\theta & cos\theta & 0\\ 0 & 0 & 1 \end{pmatrix}\] \[R_{Z}(\frac{\pi}{2})=\begin{pmatrix} 0 & 1 & 0\\ -1 & 0 & 0\\ 0 & 0 & 1 \end{pmatrix},R_{Z}(-\frac{\pi}{2})=\begin{pmatrix} 0 & -1 & 0\\ 1 & 0 & 0\\ 0 & 0 & 1 \end{pmatrix}\]而U、V、Σ都是对E进行SVD分解以后的各个部分。最后还需要注意的是这里求出的t并不是平移向量,而是t的反对称矩阵。因此还需要按照前面的转换公式,依次转成t。
由于Rz有正负,因此计算出来的t、R就有4种不同组合方式。由于一组R,T就决定了摄像机光心坐标系C的位姿,所以选择正确R、T的方式就是,把所有特征点的深度计算出来,看深度值是不是都大于0,深度都大于0的那组R,T就是正确的。
最后重新看一下尺度问题。从R,T的计算公式中,可以发现平移向量t和E的奇异值Σ有关。再回顾一下之前求E时候的方程以及提到的伸缩,这里s是缩放倍数。
\[AE = A(U\Sigma V) =0,AsE = A(Us\Sigma V) = 0\]所以,之前推导过程中所有对E进行的尺度伸缩实际上都是作用在奇异值Σ上。也就是说这个尺度scale实际作用的是两个相机之间的平移。
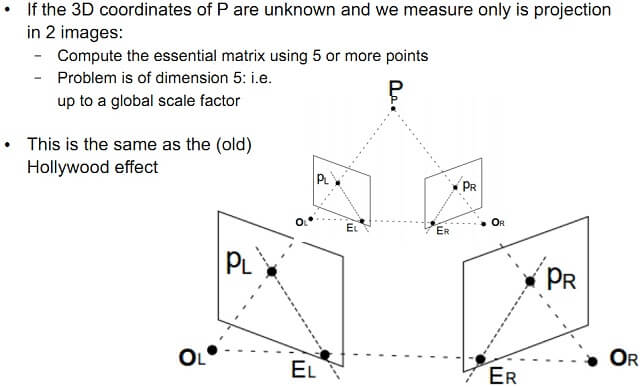 从图中也可以看出,由于尺度scale的关系,不同的t,决定了以后计算点P的深度也是不同的,所以恢复的物体深度也是跟尺度scale有关的,也就是说只是恢复了物体的结构框架,而不是实际意义的物体尺寸。并且要十分注意,每两对图像计算E并恢复R,T时,他们的尺度都不是一样的,本来是同一点,在不同尺寸下,深度不一样了,所以这个尺度需要统一。
从图中也可以看出,由于尺度scale的关系,不同的t,决定了以后计算点P的深度也是不同的,所以恢复的物体深度也是跟尺度scale有关的,也就是说只是恢复了物体的结构框架,而不是实际意义的物体尺寸。并且要十分注意,每两对图像计算E并恢复R,T时,他们的尺度都不是一样的,本来是同一点,在不同尺寸下,深度不一样了,所以这个尺度需要统一。
如果你一直采用这种2d-2d匹配计算位姿的方式,那每次计算的t都是在不同尺度下的,Davide Scaramuzza的论文《Visual odometry I》的computing the relative scale那部分讲了一种方法使得相邻位姿间的不同的尺度s经过缩放进行统一。我们已经知道出现尺度不一致是由于每次都是用这种计算本征矩阵的方式,而尺度就是在计算E时产生的。所以尺度统一的另一种思路就是后续的位姿估计我不用这种2d-2d计算本征E的方式了,也就说你通过最开始的两帧图像计算E恢复了R,T,并通过三角法计算出了深度,那我就有了场景点的3D坐标,后续的视频序列就可以通过3Dto2d(opencv里的solvePnp)来进行位姿估计,这样后续的视频序列就不用计算本征矩阵从而绕过了尺度,所以后续的视频序列的位姿和最开始的两帧的尺度是一样的了。
四、参考博客
- https://blog.csdn.net/heyijia0327/article/details/50758944
- https://blog.csdn.net/zsq306650083/article/details/8773996
本文作者原创,未经许可不得转载,谢谢配合
