之前在处理视频的时候就有过这样一个想法,只是没时间去实现。今天简单写了个脚本,实现了这个小功能。 即视频的剧情连拍功能。这样不用打开视频文件也知道视频里大致都有些什么内容,十分方便。 在处理卫星视频的时候,很多都是4K视频,打开播放很容易卡,所以这个功能就更显得重要了。
当然目前现有的视频播放软件都可以实现这个功能。但为什么还要再自己写一个呢? 原因很简单。因为现有软件的这个功能并不能实现批量化。例如一个文件夹中有很多个视频,如果利用现有软件剧情连拍,必须一个个打开,然后生成。 对于有很多个视频文件而言,显然是不能忍受的。
所以写了两个脚本文件,一个是内容预览生成程序,一个是批量调用程序。项目传到了Github上,点击查看。 代码不多,在这里也贴一下。分别写了python2和python3两个版本,这里仅贴pyhon2版本的,python3版本的可以去github看。
内容预览生成程序 preivewer.py
# coding=utf-8
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import time
import sys
# 批量保存关键帧,这里没用到
def saveImages(images, indices, out_path):
for i in range(images.__len__()):
cv2.imwrite(out_path + "\\" + "%05d" % (indices[i]) + ".jpg", images[i])
# 批量给关键帧添加时间戳
def txtImages(images, frames_save, frames, fps):
for i in range(images.__len__()):
txt = (frames_save[i] * 1.0 / frames) * (frames * 1.0 / fps)
m, s = divmod(txt, 60)
h, m = divmod(m, 60)
cv2.putText(images[i],
"%02d:%02d:%02d" % (h, m, s),
(10, 25),
cv2.FONT_HERSHEY_SIMPLEX,
0.6,
(255, 255, 255),
2,
cv2.LINE_AA)
max_width = 400
num_sample = 16
cols = 4
rows = 4
interval = 20
margin = 20
top = 100
bottom = 30
out_path = "content.jpg"
# 程序启动逻辑
# 如果启动时没有参数,则启动后手动输入参数
# 如果启动时有一个参数,默认缩略图大小为400
# 如果启动时有两个参数,输出文件名为默认
# 如果启动时有三个参数,则按照指定参数运行
# 否则,报错退出,并给出运行提示
if sys.argv.__len__() == 1:
# 输入需要处理的视频文件
video_path = raw_input("Input path of video:\n")
# 输入视频每一帧的缩略图大小,默认为400
input_width = raw_input("Input width for frame thumbnail(press 'd' use 400 as default):")
if input_width == "d":
max_width = 400
else:
max_width = int(input_width)
out_path = raw_input("Input the name of output jpg file(press 'd' use 'content.jpg' as default):")
if out_path == "d":
out_path = 'content.jpg'
elif sys.argv.__len__() == 2:
video_path = sys.argv[1]
max_width = 400
elif sys.argv.__len__() == 3:
video_path = sys.argv[1]
max_width = int(sys.argv[2])
elif sys.argv.__len__() == 4:
video_path = sys.argv[1]
max_width = int(sys.argv[2])
out_path = sys.argv[3]
else:
print "Wrong params."
print "You can run the script directly with no params and input them manually later.\n" \
"Or you can give params to script before running using these following formats:\n" \
"[1]python script.py video_path\n" \
"[2]python script.py video_path thumbnail_width\n" \
"[3]python script.py video_path thumbnail_width out_filename" \
"If you don't give the param 'thumbnail_width' , it will be 400 as default." \
"If you don't give the param 'out_filename', it will be 'content.jpg' as default."
exit()
cap = cv2.VideoCapture(video_path)
frames = int(cap.get(7))
fps = int(cap.get(5))
video_width = int(cap.get(3))
video_height = int(cap.get(4))
print frames, 'frames in total.'
ratio = max_width * 1.0 / video_width
delta_frame = int(frames / num_sample)
frames_save = []
images = []
t1 = time.time()
for i in range(num_sample):
i = i * delta_frame
frames_save.append(i)
for item in frames_save:
cap.set(cv2.CAP_PROP_POS_FRAMES, item)
ret, frame = cap.read()
if frame is None:
break
else:
images.append(cv2.resize(frame, None, fx=ratio, fy=ratio, interpolation=cv2.INTER_LINEAR))
print "processing...", round((item * 1.0 / frames) * 100, 2), " %"
# 释放对象
cap.release()
txtImages(images, frames_save, frames, fps)
max_height = images[0].shape[0]
width = max_width * cols + interval * (cols - 1) + margin * 2
height = max_height * rows + interval * (rows - 1) + margin * 2 + bottom
result = np.zeros((height, width, 3), np.uint8) + 255
# 输出文件相关信息
info = Image.fromarray(np.zeros((top, width, 3), np.uint8) + 230)
draw = ImageDraw.Draw(info)
font = ImageFont.truetype('hwxh.ttf', 24)
if sys.argv.__len__() == 1:
draw.text((1 * margin, 20), u'文件名:' + unicode(video_path.split("\\")[-1], 'utf-8'), (0, 0, 0), font=font)
else:
draw.text((1 * margin, 20), u'文件名:' + unicode(video_path.split("\\")[-1], 'gbk'), (0, 0, 0), font=font)
draw.text((1 * margin, 50), u'分辨率:' + video_width.__str__() + u" × " + video_height.__str__(), (0, 0, 0), font=font)
draw.text((1 * margin + 1 * max_width, 50), u'时长:' + round(frames * 1.0 / fps, 3).__str__() + " s", (0, 0, 0),
font=font)
draw.text((3 * margin + 2 * max_width, 50), u'帧率:' + fps.__str__(), (0, 0, 0), font=font)
draw.text((4 * margin + 3 * max_width, 50), u'帧计数:' + frames.__str__(), (0, 0, 0), font=font)
for i in range(rows):
for j in range(cols):
result[margin + i * interval + i * max_height:margin + i * interval + i * max_height + max_height,
margin + j * interval + j * max_width:margin + j * interval + j * max_width + max_width] = \
images[i * 4 + j * 1]
if width - 500 <= 0:
loc_x = 0
else:
loc_x = width - 500
cv2.putText(result,
"Created by video previewer written by Zhao Xuhui.",
(loc_x, height - 20),
cv2.FONT_HERSHEY_SIMPLEX,
0.6,
(0, 0, 0),
1,
cv2.LINE_AA)
res = np.vstack([info, result])
cv2.imwrite(out_path, res)
t2 = time.time()
print "process...finished."
print "Total time cost:", round(t2 - t1, 2), "s"
批量调用程序 bash.py
# coding=utf-8
import os
# 读取目录下所有图片的路径,返回一个list
def findAllVideos(root_dir):
paths = []
# 遍历
for parent, dirname, filenames in os.walk(root_dir):
for filename in filenames:
# 这里只选择了两种最常用的视频格式
if filename.endswith(".mp4") or filename.endswith(".avi") or filename.endswith(".MP4") or filename.endswith(".AVI"):
paths.append(parent + "\\" + filename)
return paths
# 用户指定目录
root_dir = raw_input("Input the parent path of videos:\n")
paths = findAllVideos(root_dir)
for i in range(paths.__len__()):
print "Video", (i + 1), "/", paths.__len__().__str__()
os.system("python preview_py2.py " + '"' + paths[i] + '"' + " 400 " + (i + 1).__str__() + ".jpg")
print "\n"
在写程序的过程中,也学到了一些新的东西,这里简单地做一记录。
0.总体思路
总体思路其实比较简单,就是利用OpenCV打开一个视频文件,然后获取总帧数。 再根据采样数(如取16张影像),计算出每次采样的采样间隔。从而计算出待采样的16张影像的帧号。 利用OpenCV的VideoCapture类依次获取这些帧。 然后对帧画面进行缩放、并加上其对应的时间。 最后利用Numpy生成一个大的图像,将采样的这些影像放到指定位置,完成任务。
1.脚本启动参数
在python中也支持带参数启动。第一个参数为脚本路径,从第二个参数开始可以随意输入,不同参数用空格隔开。 在这个脚本中,采用了一种更为“健全”的启动方式,既可以支持带参启动,也可以不带参启动。 程序的启动逻辑是通过判断脚本启动时的参数个数,是否为1。为1表示没有输入参数,则在脚本启动后由用户手动输入参数。 如果程序有启动参数,则按照相应的启动参数启动。 如果启动参数错误,则会退出,并输出脚本启动相关提示。 在实际测试中发现如果文件路径中包含有空格,则程序不能正确识别。因为不同参数程序就是按照空格分开的。 解决这个问题也很简单,那就是在路径的首尾端都加上双引号,这样程序就会把这个路径当作一个整体而不会被分开了。
带参启动这个模式便于批量调用脚本,从用户交互角度而言可能并不是很友好。 而用户交互输入这个模式对用户很友好,但是不利于程序批量调用。 因此为了让程序更加完善,考虑同时支持这两种不同模式。 最后经过测试,发现效果很不错,达到了预期。
2.参数化编程
在写代码的过程中,考虑到代码对于不同视频尺寸的适用性,将所有与尺寸相关的计算都抽象成了参数。 这样只需要修改参数的数值,结果自然就会变了,“一改全改”,十分方便。
3.字符编码
字符编码这个问题真的是个令人头大的问题。不得不说Python2.7对于中文路径和文件名的支持确实很糟糕。 看网上说Python3以后支持好了一些。在写代码的过程中,至少有40%的时间花在了测试不同编码上。 真正实现功能其实并没有化很多时间。当然如果说不考虑中文,那程序写起来会轻松很多。
4.OpenCV读取视频指定帧内容
OpenCV的VIdeoCapture类是有个set()函数的,可以指定从第几帧开始读取以及读取指定帧内容,十分方便。
而之前不知道有这个函数,所以在这篇博客中实现视频截取的时候,是从第一帧开始读到指定帧,然后再从指定帧开始进行处理。
显然这个方法就显得比较笨了。而且当视频很长的时候,会非常耗时。
最后对脚本进行测试。
首先是单个视频的测试。
下图是对一个4K、60fps的视频进行内容提取的测试。依次输入相关参数。
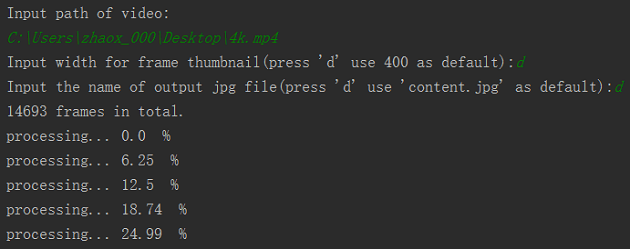 然后生成的视频内容缩略图如下所示(点击右键可查看原图)。
然后生成的视频内容缩略图如下所示(点击右键可查看原图)。
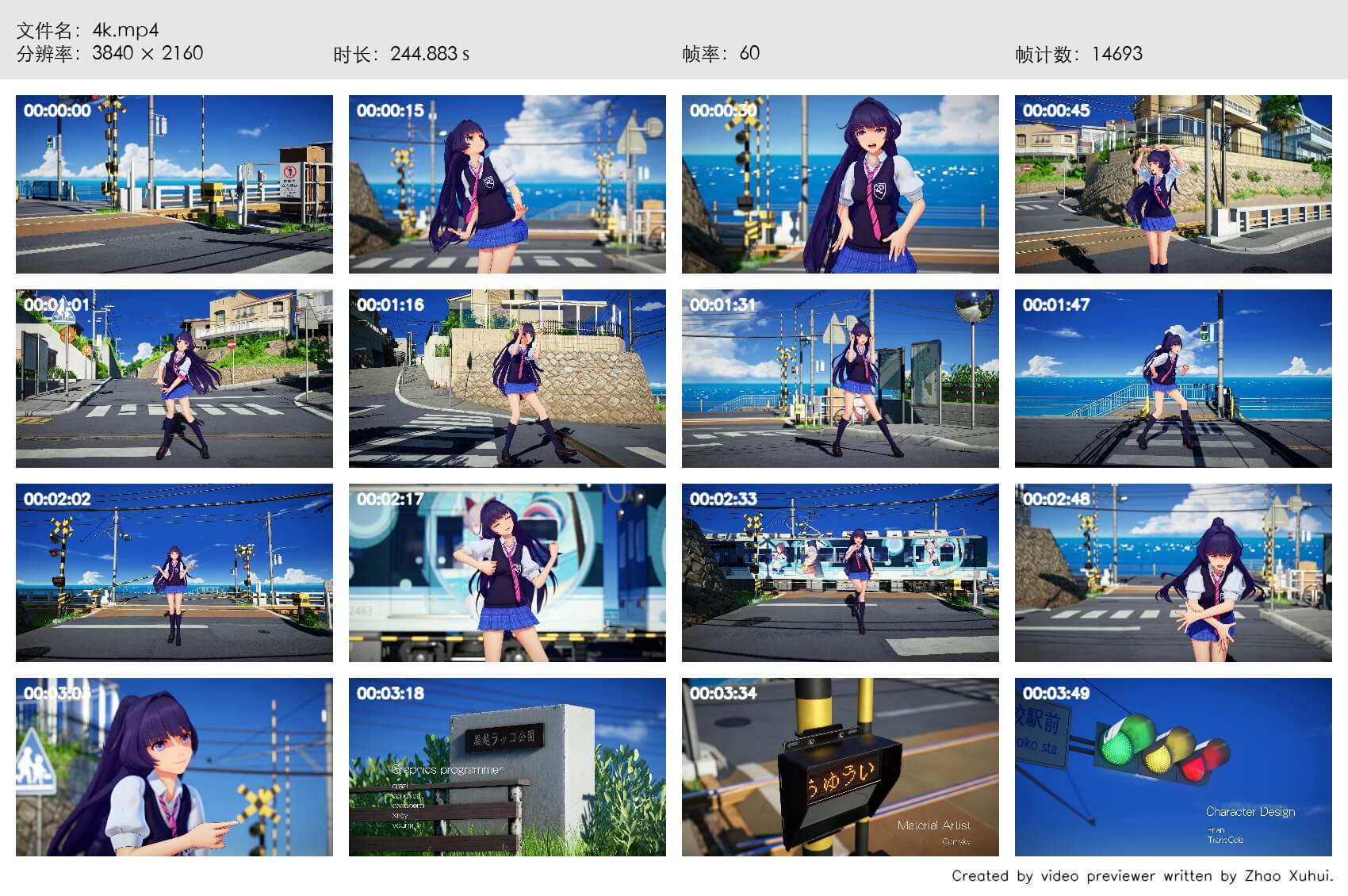 可以看到,输出了视频相关的基本信息以及内容缩略图。
可以看到,输出了视频相关的基本信息以及内容缩略图。
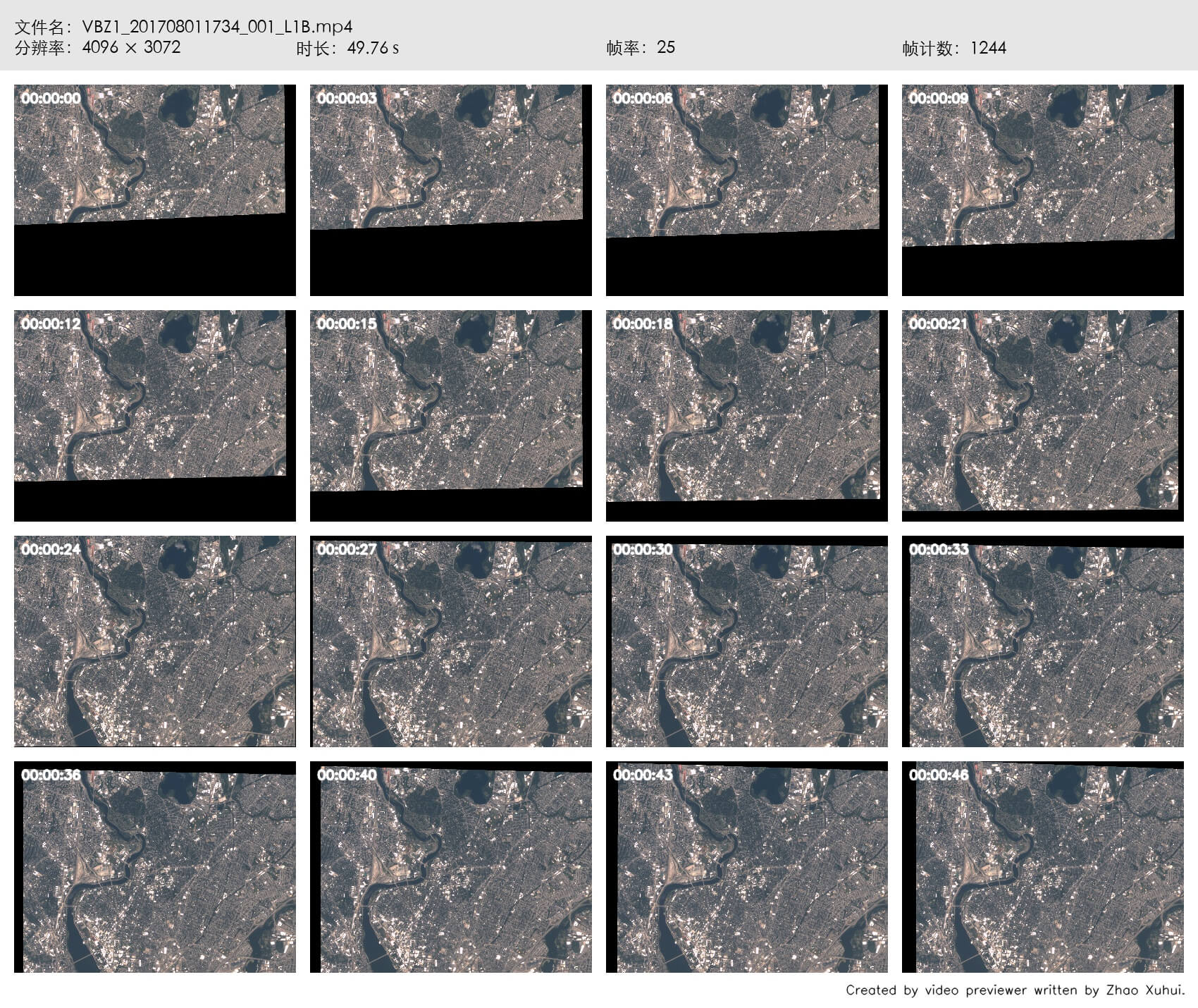
又选取了一段卫星视频进行测试,大小也为4K,但是码率没有那么高,是25。测试结果如下(点击右键可查看原图)。
下面对一个较长的视频进行测试,这里选取《南极料理人》测试。输出的结果如下(点击右键可查看原图)。
 视频有1.5GB,全长2个小时,用脚本处理生成缩略图的时间是7.21s,还算是比较快的。
这里也用QQ影音生成了一个剧情缩略图如下。
视频有1.5GB,全长2个小时,用脚本处理生成缩略图的时间是7.21s,还算是比较快的。
这里也用QQ影音生成了一个剧情缩略图如下。
 和QQ影音相比,脚本生成的信息更加丰富一些,同时还可以进行更丰富的自定义。
因为这个脚本主要考虑还是为了后续的视频处理服务的。
而且和QQ影音相比,用脚本生成快了很多,免去了打开视频等一系列操作。
尤其是像我这种老电脑,一打开这种大视频都会卡个好几秒。
和QQ影音相比,脚本生成的信息更加丰富一些,同时还可以进行更丰富的自定义。
因为这个脚本主要考虑还是为了后续的视频处理服务的。
而且和QQ影音相比,用脚本生成快了很多,免去了打开视频等一系列操作。
尤其是像我这种老电脑,一打开这种大视频都会卡个好几秒。
下面是对批量视频进行测试。在文件夹中有多个视频如下。
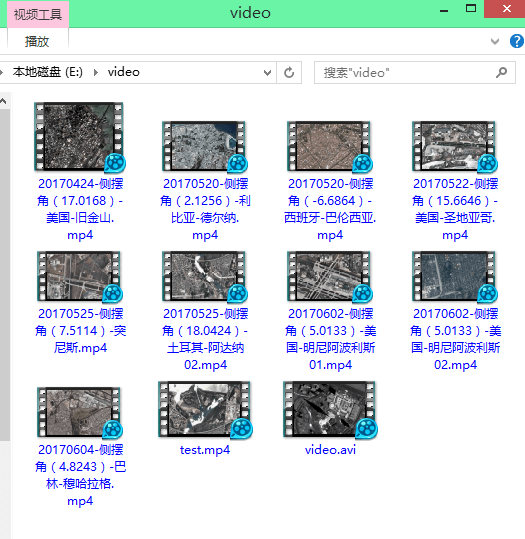 运行批量脚本,输入视频所在文件夹。执行脚本。
运行批量脚本,输入视频所在文件夹。执行脚本。
 完成之后生成的内容缩略图如下。
完成之后生成的内容缩略图如下。

至此便比较完整地实现了想要的功能。当一个文件夹中有很多视频,但仅凭文件名又不知道其内容(如文件名为一堆数字)的时候,快速知道视频内容是十分必要的。 只需要跑一遍批量脚本,就能生成每个视频的内容缩略图,从而能帮助更好地整理视频提升效率。
本文作者原创,未经许可不得转载,谢谢配合
