批量下载脚本
本脚本针对网上一些有序的按数字排列的图片的下载,如01.jpg、02.jpg等等。 整个程序基于之前这篇博客中的瓦片批量下载脚本精简而来。 整个脚本也比较简单,直接放代码。
# coding=utf-8
import urllib2 as ulb
import numpy as np
import PIL.ImageFile as ImageFile
import cv2
# 获取图片函数
def getImage(url):
"""
获取网络图片函数
:param url: 网络图片的url地址
:return: 返回值是图片的内容,包含RGB 3通道的图片矩阵
"""
# 按照最大尝试次数连接
for tries in range(5):
try:
# 用urllib2库链接网络图像
response = ulb.Request(url)
# 打开网络图像文件句柄
fp = ulb.urlopen(response)
# 定义图像IO
p = ImageFile.Parser()
# 开始图像读取
while 1:
s = fp.read(1024)
if not s:
break
p.feed(s)
# 得到图像
im = p.close()
# 将图像转换成numpy矩阵
arr = np.array(im)
# 将通道顺序变成BGR,以便OpenCV可以正确保存
arr = arr[:, :, ::-1]
return arr
# 抛出异常
except ulb.HTTPError, e:
# 持续尝试
if tries < (5 - 1):
# 404错误直接退出
if e.code == 404:
print '***404 Not Found***'
arr = np.zeros((256, 256, 3), np.uint8)
break
return arr
def downloadIMGS(base, start, end, appendix, format, savepath):
"""
批量下载图片函数
:param base: 图片url中相同的部分
:param start: 图片的起始索引
:param end: 图片的结束索引
:param appendix: 图片索引后的url内容
:param format: 图片索引的格式
:param savepath: 图片的保存文件夹路径
:return: 返回值为空
"""
urls = []
for i in range(end - start + 1):
urls.append(base + (i + start).__str__().zfill(format) + appendix)
for i in range(urls.__len__()):
img = getImage(urls[i])
cv2.imwrite(savepath + "\\" + (i + start).__str__().zfill(format) + ".jpg", img)
print (i + start).__str__().zfill(format) + ".jpg saved", ((i + 1.0) / urls.__len__()) * 100, "% finished."
downloadIMGS(
"cover",
1,
30,
".jpg",
2,
"E:\\a"
)
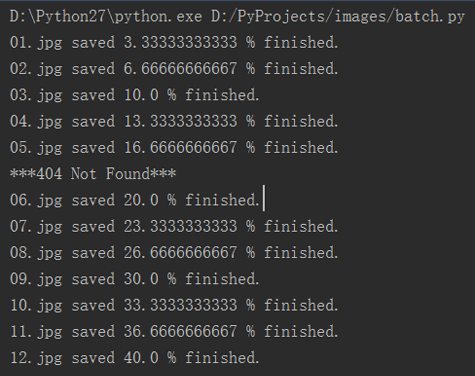
直接运行代码测试如下。
 可以看到06图像获取失败了,所以是黑色的图片。事实上是因为06是png,而这里都是jpg,所以程序找不到正确的url所以下载失败。
在运行结果中也可以看到,显示06.jpg是404错误的。
可以看到06图像获取失败了,所以是黑色的图片。事实上是因为06是png,而这里都是jpg,所以程序找不到正确的url所以下载失败。
在运行结果中也可以看到,显示06.jpg是404错误的。
 最后需要注意的是,保存图片的文件夹路径中最好不要有中文和其它特殊字符,否则会出现找不到保存的文件的情况。
最后需要注意的是,保存图片的文件夹路径中最好不要有中文和其它特殊字符,否则会出现找不到保存的文件的情况。
本文作者原创,未经许可不得转载,谢谢配合
