前几天在网上搜索PyTorch的相关内容,找到了莫烦制作的一系列PyTorch教程,感觉说的非常好,简单易懂,每个视频都不超过半个小时。 莫烦系列教程地址是这里,PyTorch教程是这里。里面的内容非常丰富,制作这些东西需要花费相当多的精力,确实很佩服。 所以这篇博客主要就是针对PyTorch教程进行一些笔记记录,会记一些我觉得比较重要的或不会的东西。想完整系统的学可以看那个教程。
1.Numpy和PyTorch数据互转
主要介绍矩阵数据的相互转换,转换也很简单,Numpy矩阵转PyTorch的Tensor函数是torch.from_numpy(),从Tensor转成Numpy的Array是直接调用Tensor对象的成员函数numpy()。
除此之外,从Numpy的Array转到PyTorch的Tensor还可以用torch.FloatTensor()函数。这个函数就是将一个Array转换成float类型的tensor变量,和torch.from_numpy()有一点点区别。
当然区别从名字就能看出来,FloatTensor函数不管原来Array的数据类型是什么,全部转成Float类型,而From函数则是保持与Array的数据类型统一,Array的数据类型是int,Tensor的数据类型也是int。
使用PyTorch需要引入torch包。
示例代码如下。
import torch
import numpy as np
np_data = np.ones([3, 2], np.float)
print("type", type(np_data), "\n", np_data)
# Numpy array -> PyTorch tensor
torch_data = torch.from_numpy(np_data)
print("type", type(torch_data), "\n", torch_data)
# PyTorch tensor -> Numpy array
cvt_data = torch_data.numpy()
print("type", type(cvt_data), "\n", cvt_data)
运行上述代码,输出结果如下。
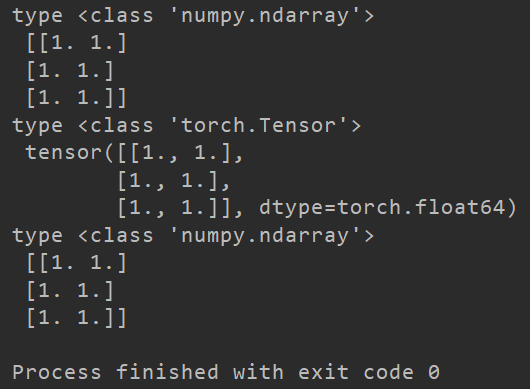 除此之外,Numpy和PyTorch的很多运算也是相同的,如
除此之外,Numpy和PyTorch的很多运算也是相同的,如abs()、cos()、mean()等函数。也有一些不同的函数,如矩阵乘法,Numpy:np.matmul(),PyTorch:torch.mm()。
更详细的运算函数可以参考官方文档API。
2.变量Variable
这个概念与TensorFlow中的类似,在实际网络中可以用来存储各神经元节点的系数。可以通过反向传播不断修改。
Tensor和Variable的区别就在于后者可以反向传播,前者不能反向传播。再简单点说就是Variable的值在计算过程中是可变的,所以叫变量,而Tensor的值一旦赋值,在运行过程中就不能改变了。
这就是为什么我们神经网络节点的系数需要用Variable表示而不是Tensor。
使用Variable需要从torch.autograd模块中导入Variable。在PyTorch中新建一个变量比较简单,如下。
import torch
import numpy as np
from torch.autograd import Variable
data = np.ones([2, 3], np.float)
data_t = torch.from_numpy(data)
# requires_grad参数表示是否求梯度,参与误差反向传播过程
# 同时传入的数据需要是Tensor类型,不能是numpy的类型
v = Variable(data_t, requires_grad=True)
print(v)
对于一个变量Variable有grad属性,存储的是梯度信息,有data属性,存储的是数值信息(tensor格式,可以调用.numpy()函数转换成Array)。反向传播示例代码如下。
import torch
import numpy as np
from torch.autograd import Variable
# 注意对于需要反向传播的variable而言,其数据类型要是float,不能是int
data = np.array([[1., 2.], [3., 4.]])
data_t = torch.from_numpy(data)
v = Variable(data_t, requires_grad=True)
print(v)
# fn的导数可以表示成fn' => 1/4 * v^2 => 1/4 * 2v => 1/2 * v
fn = torch.mean(v * v)
# 误差反向传播
fn.backward()
print(v.grad)
# 注意data是tensor,需要转换才能被Numpy识别
print(v.data.numpy())
输出结果如下。
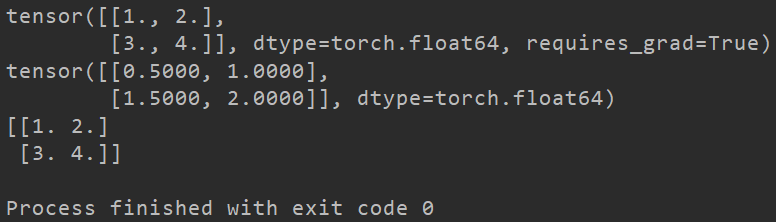 误差反向传播求梯度其实就是个求导的过程,调整各神经元的参数使得最终误差最小。这在之前TensorFlow的笔记中也有提到过。
误差反向传播求梯度其实就是个求导的过程,调整各神经元的参数使得最终误差最小。这在之前TensorFlow的笔记中也有提到过。
3.激励函数
激励函数并不是某一个具体的函数,而是指具备一些特征的一类函数。
简单来说就是线性函数无论再怎么线性组合,最后结果还是线性的。而并不是所有的问题都线性可分,所以需要某些非线性函数让输出结果非线性化。
那么这些非线性函数就是激励函数,当然除了非线性还需要满足其它一些条件。
关于什么是激活函数,可以参考之前的这篇博客。
在PyTorch中使用激励函数需要先导入torch.nn.functional模块,简单示例代码如下。
import torch
from torch.autograd import Variable
import torch.nn.functional as F
from matplotlib import pyplot as plt
# -3到3采样100个点
x = torch.linspace(-3, 3, 100)
x = Variable(x)
# 调用各种激励函数
# 注意sigmoid和tanh比较特殊,在新版本PyTorch中,直接放在了torch模块下
y_relu = F.relu(x)
y_softplus = F.softplus(x)
y_sigmoid = torch.sigmoid(x)
y_tanh = torch.tanh(x)
# 将数据全部转换为Numpy Array格式用于画图
x_numpy = x.numpy()
y_relu_numpy = y_relu.numpy()
y_sigmoid_numpy = y_sigmoid.numpy()
y_softplus_numpy = y_softplus.numpy()
y_tanh_numpy = y_tanh.numpy()
# 绘图
plt.figure(1, figsize=(8, 6))
plt.subplot(221)
plt.plot(x_numpy, y_relu_numpy, c='red', label='relu')
plt.legend(loc='best')
plt.subplot(222)
plt.plot(x_numpy, y_sigmoid_numpy, c='red', label='sigmoid')
plt.legend(loc='best')
plt.subplot(223)
plt.plot(x_numpy, y_tanh_numpy, c='red', label='tanh')
plt.legend(loc='best')
plt.subplot(224)
plt.plot(x_numpy, y_softplus_numpy, c='red', label='softplus')
plt.legend(loc='best')
plt.show()
绘图效果如下。
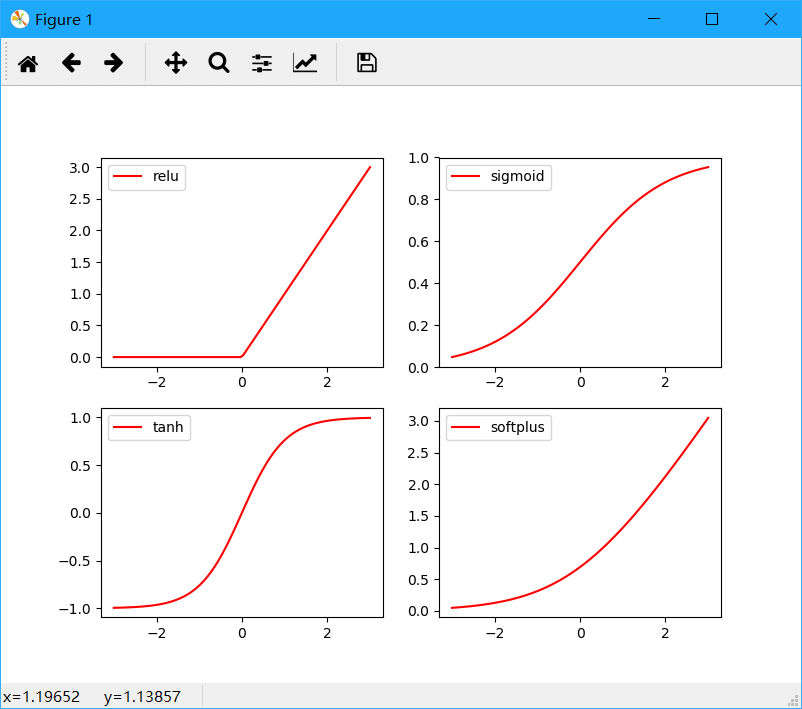
以上便是PyTorch一些基础知识,一些概念性的问题可以参考之前写的TensorFlow笔记。
本文作者原创,未经许可不得转载,谢谢配合
