在前段时间接触到了一个需求,就是需要将文件保存成压缩二进制文件以节省空间。所以稍微学习了下Python的二进制文件读写。这里简单记录一下。
需要说明的是本博客是基于zlib实现的二进制文件读写。常规Python二进制文件读写非常简单,直接在open()和write()函数中传入rb、wb即可。
但这样保存的二进制文件大小其实没多少压缩,所以需要用到zlib这个压缩库对文件进行压缩存储。常规读写可参考这篇博客。
简单介绍zlib,其官网是这个。这是一个专门设计用来处理各种压缩文件的库,常见的压缩格式都支持读写。想了解更多请自行百度。 本篇博客也是利用zlib的压缩,只不过是用它来压缩二进制文件。
1.代码
由于没有什么理论知识,所以直接放代码。需要注意的一些地方在注释里已经写了。
# coding=utf-8
import zlib
def saveData(content, save_path):
f = open(save_path, 'wb')
for i in range(len(content)):
f.write(content[i])
f.close()
def saveAndCompressData(content, save_path, level=9):
f = open(save_path, 'wb') # 打开文件用于写入
compress = zlib.compressobj(level) # 根据压缩等级构造对象
for i in range(len(content)):
f.write(compress.compress(content[i]))
f.write(compress.flush())
f.close()
def readAndDecompressData(file_path):
parts = []
infile = open(file_path, 'rb')
decompress = zlib.decompressobj()
data = infile.read(1024) # 每次读取1024个字节
# 简单解释下这里为什么读1024个字节
# 这里的1024其实写成其它数字都ok
# 由于在保存的时候是按行保存的因此读完之后根据换行符进行分割即可
while data:
res = decompress.decompress(data)
parts.append(res)
data = infile.read(1024)
tmp_str = ""
for i in range(len(parts)):
tmp_str += parts[i] # 把读取的每一段都拼起来
lines = tmp_str.split("\n")[:-1] # 根据换行符进行分割
return lines
if __name__ == '__main__':
content = []
for i in range(10000):
content.append("zhaoxuhui " + i.__str__().zfill(5) + "\n")
saveData(content, "test.txt")
saveAndCompressData(content, "test.zxh")
lines = readAndDecompressData("test.zxh")
print lines
2.测试
在代码中构造了10000行的字符串,分别保存成普通txt和自定义格式的二进制文件,保存后的文件大小如下所示。
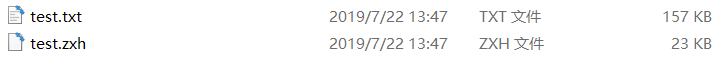 可以明显发现,同样的内容,在保存成压缩二进制文件后,文件大小小了约85%,压缩效果还是相当好的。
可以明显发现,同样的内容,在保存成压缩二进制文件后,文件大小小了约85%,压缩效果还是相当好的。
本文作者原创,未经许可不得转载,谢谢配合
