1.背景
十月金秋,北方的秋天总是来的那么浓烈。你开心地走在长安街上,感受着天安门广场上国庆庆典的余热。巨大的祝福祖国花篮摆放在天安门广场中央,五星红旗在蓝色天空的背景下迎风飘扬,一片秋高气爽的景象,让你忍不住想拍照留念。于是你掏出手机,来来回回,精挑细选,黄金分割线、天空留画面的1/3、近景远景结合…,无数摄影概念在你脑海中奔涌而过。终于你找到了一个很棒的构图,兴冲冲告诉同行的小伙伴从这个角度拍,帮你记录下这美好的瞬间。摆好姿势,露出笑容,3,2,1,一切都很OK。你的小伙伴也认真负责,咔嚓咔嚓帮你连续拍了好多张。你觉得很完美,以挑好的角度拍了那么多张,你觉得总会有一张可以用。你想象中的照片会是这个样子。
 满心欢喜拿回手机,你惊呆了,你的小伙伴把你拍成了下面的样子。
满心欢喜拿回手机,你惊呆了,你的小伙伴把你拍成了下面的样子。
 仿佛天旋地转一般(小伙伴说:啊,我没注意,拍歪了,没关系,后面还有几张好的)。于是你又往后翻了一张,是这样:
仿佛天旋地转一般(小伙伴说:啊,我没注意,拍歪了,没关系,后面还有几张好的)。于是你又往后翻了一张,是这样:
 好不容易人正了,可是重要背景天安门被“砍掉了一半”,而且你跑到了边边。(小伙伴说:我觉得挺好的啊,人和天安门都拍到了)。你只好默默地再翻一张,期待下一次会出现奇迹。
好不容易人正了,可是重要背景天安门被“砍掉了一半”,而且你跑到了边边。(小伙伴说:我觉得挺好的啊,人和天安门都拍到了)。你只好默默地再翻一张,期待下一次会出现奇迹。
 终于人正了,天安门也拍全了,可是人就只剩了个头,没了下半身。(小伙伴说:这张很棒啊,把天安门拍的很气派)。无奈,你只能再往后滑,却发现已没照片。噔噔咚,于是你瞬间血压飙升。可回想小伙伴尽力拍照的样子和渴望夸奖的眼神,你便不再多说什么 - 只能面带微笑地说着违心的话,“可以,可以,我觉得还行”。最终,只能带着“奇形怪状”的照片离开了人潮汹涌的金水桥。人的悲欢并不相通,你只觉得他们吵闹,只希望下次旅行和会拍照的小伙伴同行。(PS:以上照片都是为了节目效果手动合成的,并非帮我拍照的小伙伴拍的照片。小伙伴的拍照技术很棒,第一张就是拍的原图。)
终于人正了,天安门也拍全了,可是人就只剩了个头,没了下半身。(小伙伴说:这张很棒啊,把天安门拍的很气派)。无奈,你只能再往后滑,却发现已没照片。噔噔咚,于是你瞬间血压飙升。可回想小伙伴尽力拍照的样子和渴望夸奖的眼神,你便不再多说什么 - 只能面带微笑地说着违心的话,“可以,可以,我觉得还行”。最终,只能带着“奇形怪状”的照片离开了人潮汹涌的金水桥。人的悲欢并不相通,你只觉得他们吵闹,只希望下次旅行和会拍照的小伙伴同行。(PS:以上照片都是为了节目效果手动合成的,并非帮我拍照的小伙伴拍的照片。小伙伴的拍照技术很棒,第一张就是拍的原图。)
这个情况相信很多人都有遇到过。让别人帮自己拍照,奈何对方技术不太行,总是拍的不好,可碍于情面又不好意思让对方一直帮自己拍。这便是很多人在旅游拍照时的“痛点”。有些人求人不如求己,带着自拍杆自拍,有些人则心灰意冷,彻底不拍了。导致这个现象的核心问题是,拍照的人本身可能并没有很专业的构图知识,或者不会拍照。解决这个问题其实也很简单,那就是给他一个参考,让他照葫芦画瓢地拍。也许他画的瓢没有那么完美,但至少比起没有任何参考的情况(像上面这种),要好得多,后期稍微调调还能看。那么有没有什么手段呢?答案是有的。这也是本篇博客主要解决的问题。
2.解决方案
那么如何在拍照的时候给出参考呢?其实也很简单。与小时候照字帖练字类似,我们可以设计这样一个流程:首先,会拍照的人根据自己的知识挑选好一个满意的视角,先拍摄一张照片,以此作为参考。然后,我们将这张照片叠加到当前相机的预览界面上,不会拍照的人拿着手机不断移动,尽可能让实时预览界面和参考照片重合。当重合度最高的时候,可以认为当前相机的视角就是参考视角了。最后,点击拍照按钮,完成拍照。
可以看到,这里最核心的就是将参考影像和相机实时预览界面进行叠加。如何叠加呢?也非常简单,那就是设置透明度。比如将参考影像和预览界面都设置成0.5的透明度,就可以实现内容的叠加,而且各自的内容也都能看得到。所以下面话不多说,直接上代码实现。
3.方案实现
目前使用Python进行了原理层面的实现,之后有时间再在Android手机上实现一个可用的App。
3.1简单版本
一个按照上面介绍实现的简单版本代码如下。
# coding=utf-8
import cv2
import time
# 按钮回调事件
def reactionEvent(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
# shot按钮
if start_x < x < start_x + 70 and start_y < y < start_y + 30:
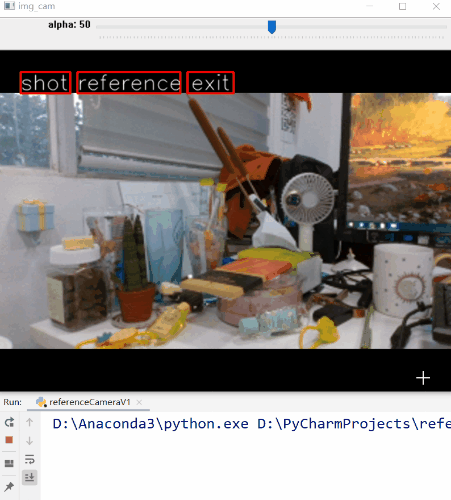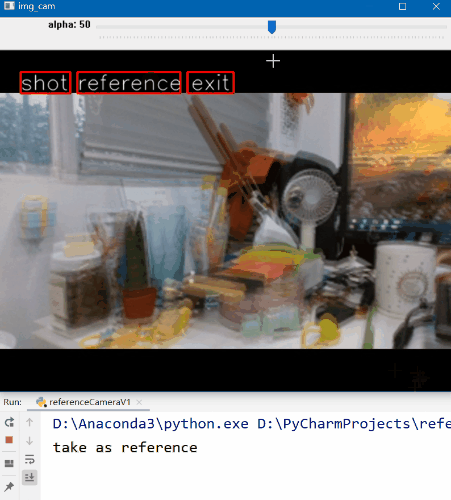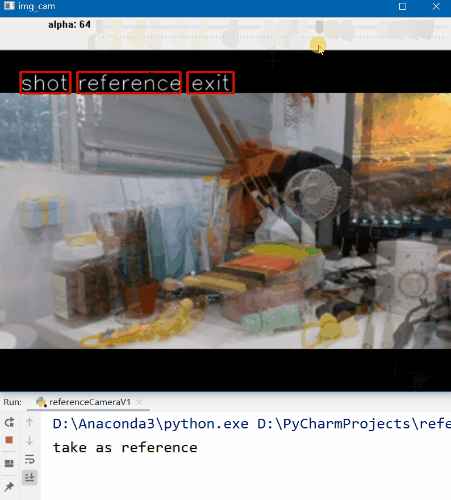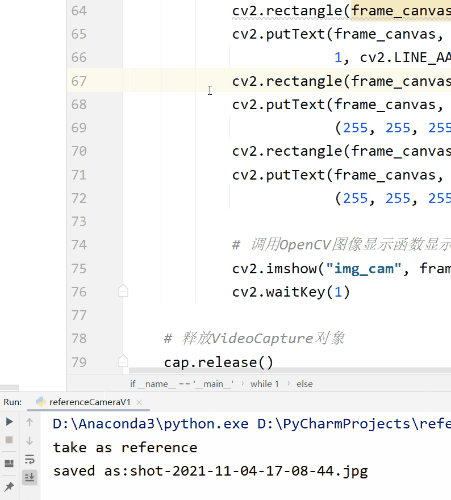
cv2.imwrite(time.strftime("shot-%Y-%m-%d-%H-%M-%S", time.localtime()) + ".jpg", frame)
print("saved as:" + time.strftime("shot-%Y-%m-%d-%H-%M-%S", time.localtime()) + ".jpg")
# reference按钮
elif start_x + 80 < x < start_x + 225 and start_y < y < start_y + 30:
cv2.imwrite("reference.jpg", frame)
print("take as reference")
global ref_frame, flag_ref
ref_frame = cv2.imread("reference.jpg")
flag_ref = 1
# exit按钮
elif start_x + 235 < x < start_x + 300 and start_y < y < start_y + 30:
cv2.destroyAllWindows()
exit()
def nothing(x):
pass
global ref_frame
# 脚本实现拍摄某张影像作为参考,再拍摄其它照片的功能
if __name__ == '__main__':
flag_ref = 0
start_x = 30
start_y = 30
# 新建一个VideoCapture对象,指定第0个相机进行视频捕获
cap = cv2.VideoCapture(0)
cv2.namedWindow("img_cam")
cv2.setMouseCallback("img_cam", reactionEvent)
cv2.createTrackbar('alpha', "img_cam", 50, 100, nothing)
# 一直循环捕获,直到手动退出
while 1:
# 返回两个值,ret表示读取是否成功,frame为读取的帧内容
ret, frame = cap.read()
# 判断传入的帧是否为空,为空则退出
if frame is None:
break
else:
if flag_ref != 1:
# 如果没有参考影像,就拷贝当前帧影像
frame_canvas = frame.copy()
elif flag_ref == 1:
# 如果有参考影像,就根据滑动条的位置获取比例,对当前帧和参考帧进行混合并输出
alpha_value = cv2.getTrackbarPos('alpha', "img_cam")
alpha_value = alpha_value / 100
img_mix = cv2.addWeighted(ref_frame, alpha_value, frame, 1 - alpha_value, 0)
frame_canvas = img_mix.copy()
# 按钮绘制
cv2.rectangle(frame_canvas, (start_x, start_y), (start_x + 70, start_y + 30), (0, 0, 255), 2)
cv2.putText(frame_canvas, "shot", (start_x, start_y + 25), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255),
1, cv2.LINE_AA)
cv2.rectangle(frame_canvas, (start_x + 80, start_y), (start_x + 225, start_y + 30), (0, 0, 255), 2)
cv2.putText(frame_canvas, "reference", (start_x + 80, start_y + 25), cv2.FONT_HERSHEY_SIMPLEX, 1,
(255, 255, 255), 1, cv2.LINE_AA)
cv2.rectangle(frame_canvas, (start_x + 235, start_y), (start_x + 300, start_y + 30), (0, 0, 255), 2)
cv2.putText(frame_canvas, "exit", (start_x + 240, start_y + 25), cv2.FONT_HERSHEY_SIMPLEX, 1,
(255, 255, 255), 1, cv2.LINE_AA)
# 调用OpenCV图像显示函数显示每一帧
cv2.imshow("img_cam", frame_canvas)
cv2.waitKey(1)
# 释放VideoCapture对象
cap.release()
最核心的代码就是参考帧和当前帧混合,调用了addWeighted()函数。之所以看起来有些复杂是因为写了一些按钮和回调函数。当然另一个需要注意的是这里可视化的影像和输出的影像并非是同一个(因为可视化影像上面绘制了按钮等内容)。运行效果如下。GIF动图的可视效果可能不太好,感兴趣可以下载源码运行,体验丝滑流畅。
 首先我们找到个合适的角度,然后点击“Reference”按钮,这时程序就记录下了参考帧的内容。移动相机就可以看到叠加在预览界面的参考帧了,我们以此为标准,移动相机尽可能使预览界面与参考帧重合。当你觉得OK的时候,点击“Shot”按钮进行拍照即可完成。
看起来还不错,基本实现了我们上面设计的流程。参考影像和实际拍摄的影像如下。
首先我们找到个合适的角度,然后点击“Reference”按钮,这时程序就记录下了参考帧的内容。移动相机就可以看到叠加在预览界面的参考帧了,我们以此为标准,移动相机尽可能使预览界面与参考帧重合。当你觉得OK的时候,点击“Shot”按钮进行拍照即可完成。
看起来还不错,基本实现了我们上面设计的流程。参考影像和实际拍摄的影像如下。
 可以看到,影像内容和视角基本是一致的。
可以看到,影像内容和视角基本是一致的。
3.2高级版本
那能不能更好一点呢?当然是可以的。比如我们可以根据参考帧和当前帧内容之间的位置差异,自动给拍摄者提示,应该朝哪个方向移动手机,让程序更“智能”一些。这样即使再不会拍照的人,只要按照提示移动手机,也基本能拍出还不错的照片了。话不多说,直接放代码。
# coding=utf-8
import cv2
import time
import math
def reactionEvent(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
if start_x < x < start_x + 70 and start_y < y < start_y + 30:
cv2.imwrite(time.strftime("shot-%Y-%m-%d-%H-%M-%S", time.localtime()) + ".jpg", frame)
print("saved as:" + time.strftime("shot-%Y-%m-%d-%H-%M-%S", time.localtime()) + ".jpg")
elif start_x + 80 < x < start_x + 225 and start_y < y < start_y + 30:
cv2.imwrite("reference.jpg", frame)
print("take as reference")
global ref_frame, flag_ref
ref_frame = cv2.imread("reference.jpg")
global ref_kps, ref_des
ref_kps, ref_des = getOrbKps(ref_frame)
flag_ref = 1
elif start_x + 235 < x < start_x + 300 and start_y < y < start_y + 30:
cv2.destroyAllWindows()
exit()
def nothing(x):
pass
def getOrbKps(img, numKps=2000):
"""
获取ORB特征点和描述子
:param img: 读取的输入影像
:param numKps: 期望提取的特征点个数,默认2000
:return: 特征点和对应的描述子
"""
orb = cv2.ORB_create(nfeatures=numKps)
kp, des = orb.detectAndCompute(img, None)
return kp, des
def cvtCvKeypointToNormal(keypoints):
"""
将OpenCV中KeyPoint类型的特征点转换成(x,y)格式的普通数值
:param keypoints: KeyPoint类型的特征点列表
:return: 转换后的普通特征点列表
"""
cvt_kps = []
for i in range(keypoints.__len__()):
cvt_kps.append((keypoints[i].pt[0], keypoints[i].pt[1]))
return cvt_kps
def bfMatch(kp1, des1, kp2, des2, disTh=15.0):
"""
基于BF算法的匹配
:param kp1: 特征点列表1
:param des1: 特征点描述列表1
:param kp2: 特征点列表2
:param des2: 特征点描述列表2
:return: 匹配的特征点对
"""
good_kps1 = []
good_kps2 = []
# create BFMatcher object
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
# Match descriptors.
matches = bf.match(des1, des2)
if matches.__len__() == 0:
return good_kps1, good_kps2
else:
min_dis = 10000
for item in matches:
dis = item.distance
if dis < min_dis:
min_dis = dis
g_matches = []
for match in matches:
if match.distance <= max(1.1 * min_dis, disTh):
g_matches.append(match)
# print("matches:" + g_matches.__len__().__str__())
cvt_kp1 = []
cvt_kp2 = []
if type(kp1[0]) is cv2.KeyPoint:
cvt_kp1 = cvtCvKeypointToNormal(kp1)
else:
cvt_kp1 = kp1
if type(kp2[0]) is cv2.KeyPoint:
cvt_kp2 = cvtCvKeypointToNormal(kp2)
else:
cvt_kp2 = kp2
for i in range(g_matches.__len__()):
good_kps1.append([cvt_kp1[g_matches[i].queryIdx][0], cvt_kp1[g_matches[i].queryIdx][1]])
good_kps2.append([cvt_kp2[g_matches[i].trainIdx][0], cvt_kp2[g_matches[i].trainIdx][1]])
return good_kps1, good_kps2
global ref_frame
global ref_kps
global ref_des
# 脚本实现拍摄某张影像作为参考,再拍摄其它照片的功能
# 相比于V1,增加了运动提示显示
if __name__ == '__main__':
flag_ref = 0
start_x = 30
start_y = 30
# 新建一个VideoCapture对象,指定第0个相机进行视频捕获
cap = cv2.VideoCapture(0)
cv2.namedWindow("img_cam")
cv2.setMouseCallback("img_cam", reactionEvent)
cv2.createTrackbar('alpha', 'img_cam', 50, 100, nothing)
# 一直循环捕获,直到手动退出
while 1:
# 返回两个值,ret表示读取是否成功,frame为读取的帧内容
ret, frame = cap.read()
# 判断传入的帧是否为空,为空则退出
if frame is None:
break
else:
if flag_ref != 1:
# 如果没有参考影像,就拷贝当前帧影像
frame_canvas = frame.copy()
elif flag_ref == 1:
# 提取当前帧ORB特征并和参考帧ORB匹配
frame_kps, frame_des = getOrbKps(frame)
g_kp1, g_kp2 = bfMatch(ref_kps, ref_des, frame_kps, frame_des)
# 如果有参考影像,就根据滑动条的位置获取比例,对当前帧和参考帧进行混合并输出
alpha_value = cv2.getTrackbarPos('alpha', "img_cam")
alpha_value = alpha_value / 100
img_mix = cv2.addWeighted(ref_frame, alpha_value, frame, 1 - alpha_value, 0)
frame_canvas = img_mix.copy()
frame_width = frame_canvas.shape[1]
frame_height = frame_canvas.shape[0]
# 计算参考帧和当前帧之间的位置差异
diff_xs = []
diff_ys = []
for i in range(len(g_kp1)):
kp1_x = int(g_kp1[i][0])
kp1_y = int(g_kp1[i][1])
kp1 = (kp1_x, kp1_y)
kp2_x = int(g_kp2[i][0])
kp2_y = int(g_kp2[i][1])
diff_xs.append(kp2_x - kp1_x)
diff_ys.append(kp2_y - kp1_y)
diff_xs.sort()
diff_ys.sort()
median_diff_x = diff_xs[int((len(diff_xs) - 1) / 2)]
median_diff_y = diff_ys[int((len(diff_ys) - 1) / 2)]
diff_d = math.sqrt(median_diff_x ** 2 + median_diff_y ** 2)
# 根据不同的距离设置不同颜色
color = (0, 0, 255)
if diff_d < 5:
color = (0, 255, 0)
elif diff_d > 5 and diff_d < 20:
color = (0, 255, 255)
else:
color = (0, 0, 255)
# 绘制匹配点对
for i in range(len(g_kp1)):
kp1_x = int(g_kp1[i][0])
kp1_y = int(g_kp1[i][1])
kp1 = (kp1_x, kp1_y)
kp2_x = int(g_kp2[i][0])
kp2_y = int(g_kp2[i][1])
kp2 = (kp2_x, kp2_y)
cv2.circle(frame_canvas, kp1, 1, color)
cv2.circle(frame_canvas, kp2, 1, color)
cv2.line(frame_canvas, kp1, kp2, color, 1)
# 根据不同差异绘制运动提示箭头
if median_diff_y > 5:
# 向上
cv2.arrowedLine(frame_canvas, (int(frame_width / 2), int(frame_height / 2) - 100),
(int(frame_width / 2), int(frame_height / 2) + 100),
(32, 183, 255), 4)
elif median_diff_y < -5:
# 向下
cv2.arrowedLine(frame_canvas, (int(frame_width / 2), int(frame_height / 2) + 100),
(int(frame_width / 2), int(frame_height / 2) - 100),
(32, 183, 255), 4)
if median_diff_x > 5:
# 向左
cv2.arrowedLine(frame_canvas, (int(frame_width / 2) - 100, int(frame_height / 2)),
(int(frame_width / 2) + 100, int(frame_height / 2)),
(32, 183, 255), 4)
elif median_diff_x < -5:
# 向右
cv2.arrowedLine(frame_canvas, (int(frame_width / 2) + 100, int(frame_height / 2)),
(int(frame_width / 2) - 100, int(frame_height / 2)),
(32, 183, 255), 4)
# 绘制按钮
cv2.rectangle(frame_canvas, (start_x, start_y), (start_x + 70, start_y + 30), (0, 0, 255), 2)
cv2.putText(frame_canvas, "shot", (start_x, start_y + 25), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255),
1, cv2.LINE_AA)
cv2.rectangle(frame_canvas, (start_x + 80, start_y), (start_x + 225, start_y + 30), (0, 0, 255), 2)
cv2.putText(frame_canvas, "reference", (start_x + 80, start_y + 25), cv2.FONT_HERSHEY_SIMPLEX, 1,
(255, 255, 255), 1, cv2.LINE_AA)
cv2.rectangle(frame_canvas, (start_x + 235, start_y), (start_x + 300, start_y + 30), (0, 0, 255), 2)
cv2.putText(frame_canvas, "exit", (start_x + 240, start_y + 25), cv2.FONT_HERSHEY_SIMPLEX, 1,
(255, 255, 255), 1, cv2.LINE_AA)
# 调用OpenCV图像显示函数显示每一帧
cv2.imshow("img_cam", frame_canvas)
cv2.waitKey(1)
# 释放VideoCapture对象
cap.release()
与上面的版本相比多了一些东西。首先是参考帧和当前帧相对位置的确定。我们通过分别在参考帧和拍摄帧上分别提取ORB特征点,然后进行匹配。计算匹配的同名点之间的坐标差异,最后统计所有同名点坐标差异的中值,以此作为判断标准,从而给出提示。关于特征提取与匹配的内容,感兴趣可以参考这篇博客。实现的效果如下。GIF动图的可视效果可能不太好,感兴趣可以下载源码运行,体验丝滑流畅。
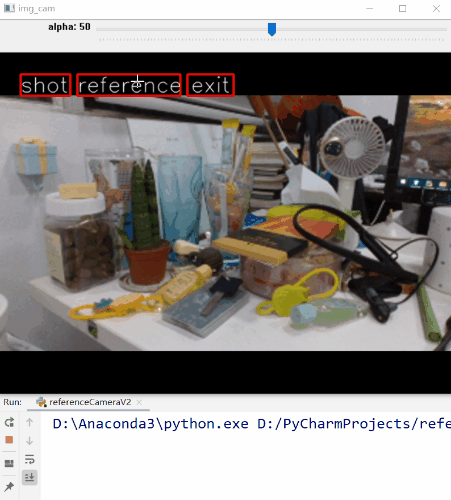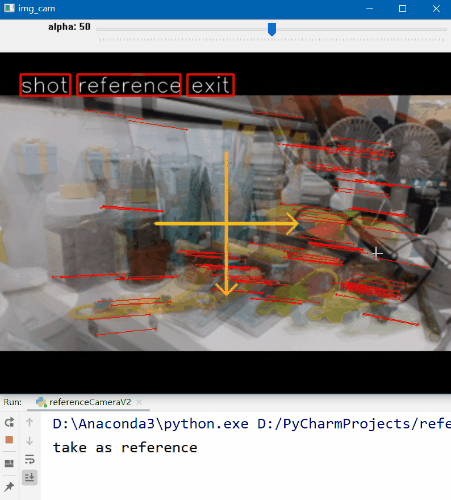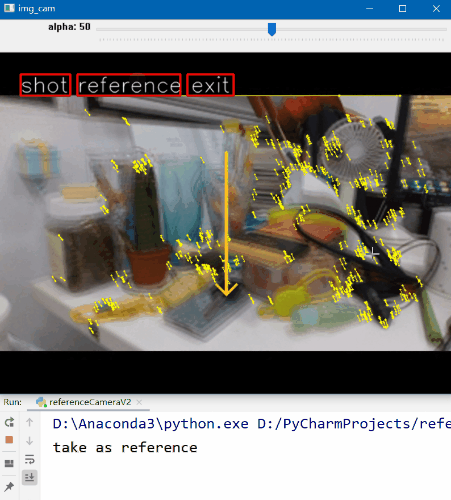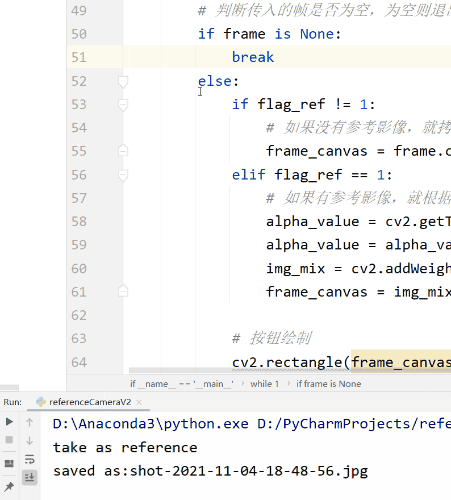 首先我们找到个合适的角度,然后点击“Reference”按钮,这时程序就记录下了参考帧的内容。移动相机就可以看到叠加在预览界面的参考帧了。可以看到相比于上面的版本,这个版本多了参考帧和当前帧的对应关系(图中很短的线段)。不同颜色代表参考帧和当前帧的差异,最好状态是绿色,次一点是黄色,最后是红色。同时我们也可以看到预览界面多了两个橙色的箭头。这是用于指导拍摄者该如何移动相机的。当箭头向右指的时候,则表示向右移动相机。这样,我们以参考帧为标准,根据提示移动相机,使预览界面尽可能与参考帧重合。当你觉得OK的时候,点击“Shot”按钮进行拍照即可完成。
参考帧影像和拍摄帧影像对比如下。
首先我们找到个合适的角度,然后点击“Reference”按钮,这时程序就记录下了参考帧的内容。移动相机就可以看到叠加在预览界面的参考帧了。可以看到相比于上面的版本,这个版本多了参考帧和当前帧的对应关系(图中很短的线段)。不同颜色代表参考帧和当前帧的差异,最好状态是绿色,次一点是黄色,最后是红色。同时我们也可以看到预览界面多了两个橙色的箭头。这是用于指导拍摄者该如何移动相机的。当箭头向右指的时候,则表示向右移动相机。这样,我们以参考帧为标准,根据提示移动相机,使预览界面尽可能与参考帧重合。当你觉得OK的时候,点击“Shot”按钮进行拍照即可完成。
参考帧影像和拍摄帧影像对比如下。
 可以看到,视角和内容同样是基本一致的。至此,我们便圆满完成了博客开始时候提出的需求。相关代码也上传到了Github,点击查看,感兴趣可以Fork或Star。
可以看到,视角和内容同样是基本一致的。至此,我们便圆满完成了博客开始时候提出的需求。相关代码也上传到了Github,点击查看,感兴趣可以Fork或Star。
4.结论与展望
本篇博客提出的想法其实是很简单的,但对于一些应用场景确实有很有效。除了拍照,另外一些潜在的应用场景是,比如我们可以在一些景点让专业摄影师挑选一系列好的角度,预置好各种姿态。当游客到达指定地点的时候,只要按照提示移动手机到预置姿态就可以拍出视角、构图还不错的照片。或者开发一些和摄影有关的教育App,可以让使用者的感受更深。
本文作者原创,未经许可不得转载,谢谢配合
