- 1.自动驾驶常用传感器
- 2.小鹏与特斯拉的传感器比较
- 3.自动驾驶应用场景
- 4.自动驾驶中的一些概念与缩写
- 5.自动驾驶中的高精地图
- 6.深度学习在自动驾驶中的应用
- 7.自动驾驶中的多传感器融合
- 8.参考资料
本篇博客是一些微信公众号推送的笔记,由于是多篇,内容相对零散,各部分之间没有很强的逻辑性。所以你可以根据目录直接跳转到感兴趣部分,一般不会存在读不懂的情况。同时网络资料纷杂,可能会出现来源不明、相互借鉴的情况,我尽可能把用到的资料列在了参考资料部分,感兴趣可以查看。
1.自动驾驶常用传感器
当前自动驾驶主要使用的传感器可以分为超声波传感器、毫米波雷达、激光雷达和视觉摄像头四类,下面分别简单介绍。
1.1 超声波传感器
这是目前最普遍用于泊车的传感器,车上一般装配8-12个。它的作用是用于检测周围是否有障碍物。事实上这种传感器其实我们并不陌生,之前在树莓派小车上就用过这种传感器,点击查看,当时主要是用于测距,判断前方是否有障碍物。而这里说的超声波传感器其实是一样的。这种传感器比较传统,成本也较低(十几元一个),如下图所示(就是汽车头部或者尾部一些圆圈状的东西)。

1.2 毫米波雷达
顾名思义就是工作在毫米波段(波长1mm到10mm)的探测雷达。探测距离可达200m左右,可靠性高、不受光线、尘埃影响,相比摄像头在距离150米以上的目标检测效果更好。如下图所示,为Bosch公司的毫米波雷达以及它的拆解图。图中白色的有很多点点的就是雷达的天线阵列。毫米波雷达通常体积较小,安装在汽车保险杠后面。

 目前市场主流使用的车载毫米波雷达按照其频率的不同,主要可分为两种:24GHz毫米波雷达(严格来讲不是毫米波,因为它的波长在1cm左右,所以有时也叫厘米波)和77GHz毫米波雷达。通常24GHz雷达检测范围为中短距离,用作实现盲区监控、变道辅助等功能,而77GHz中长程雷达用作实现自适应巡航系统、自动紧急刹车等。和24GHz相比,77GHz体积较小,检测精度较高。在自动驾驶领域,毫米波雷达最常见的三个用途是:
目前市场主流使用的车载毫米波雷达按照其频率的不同,主要可分为两种:24GHz毫米波雷达(严格来讲不是毫米波,因为它的波长在1cm左右,所以有时也叫厘米波)和77GHz毫米波雷达。通常24GHz雷达检测范围为中短距离,用作实现盲区监控、变道辅助等功能,而77GHz中长程雷达用作实现自适应巡航系统、自动紧急刹车等。和24GHz相比,77GHz体积较小,检测精度较高。在自动驾驶领域,毫米波雷达最常见的三个用途是:
- 自适应巡航(ACC)
- 盲点检测和变道辅助(BSD&LCA)
- 自动紧急制动(AEB)
那么相比于激光雷达,毫米波雷达的优势在哪呢?首先是天气。激光的波长远小于毫米波雷达(nm vs mm),所以雾霾容易导致激光雷达失效。同样的原因,毫米波雷达的探测距离可以轻松超过200米,而激光雷达目前的性能一般不超过150米,所以对于高速公路这样的场景,毫米波雷达能够做的更好。其次,毫米波雷达更便宜。作为成熟产品,毫米波雷达目前价格大约在1500左右,而激光雷达的价格目前仍然是以万作为单位。并且由于激光雷达获取的数据量远超毫米波雷达,所以需要更高性能的处理器处理数据,更高性能的处理器同时也意味着更高的价格。所以对于工程师而言,在简单场景中,毫米波雷达仍然是最优选择。
对毫米波雷达的探测原理感兴趣,可进一步参考这个网页,说的比较详细。
1.3 激光雷达
这是我们比较熟悉的,其测量精度较高、且受环境影响较小,是目前自动驾驶中比较流行的传感器之一。目前的缺点就是成本比较高,而且数据量大,对算力的要求较高。

1.4 视觉摄像头
自动驾驶必备的传感器之一。虽然视觉信息在某些极端情况下不如激光雷达可靠,但毕竟视觉包含信息的丰富程度是激光雷达点云无法比拟的。基于视觉信息再结合各种计算机视觉算法,可以实现丰富的功能,如行人检测、障碍物识别等。而且在实际应用中,车辆都会配备多个摄像头以覆盖各种视角,可以简单分为以下三种。
1.4.1 环视摄像头
一般采用鱼眼摄像头,安装在车的前后左右四个方向。这样通过对四个方向的鱼眼影像合成,就能得到360°无死角的环视影像。
1.4.2 前视、侧视、后视摄像头
一般采用普通的摄像头。前视方向一般三个,分别负责远、中、近场景。侧视一般一边两个,放在车的前部和后部。后视用于拍摄后部环境。
1.4.3 驾驶舱内摄像头
一般采用普通的摄像头。主要用于监控驾驶舱内的情况。
2.小鹏与特斯拉的传感器比较
特斯拉作为“视觉为王”智能驾驶的引领者,一直延续着其“仿生”路线(一些视觉硬件与算法由Mobileye供应)。而小鹏汽车算是国内跟进者。下面就简单对二者进行比较。首先是传感器,下图比较了小鹏和特斯拉的传感器配置。
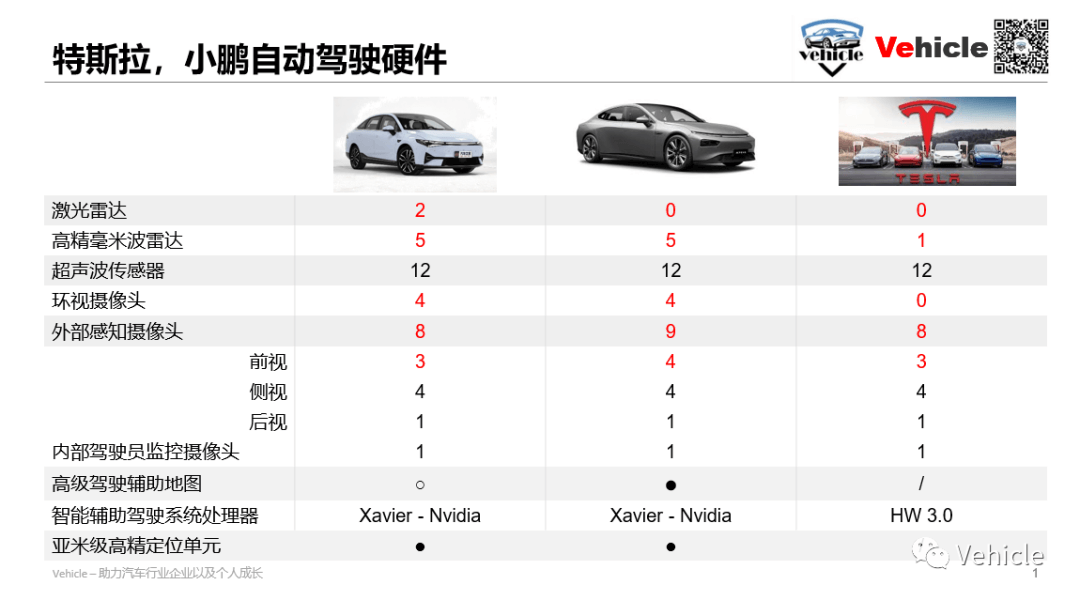 下面针对不同类型的摄像头进行对比。
下面针对不同类型的摄像头进行对比。
2.1 环视摄像头对比
 特斯拉没有泊车辅助的环视摄像头,其借用其它摄像头来帮助呈现后视等功能。
特斯拉没有泊车辅助的环视摄像头,其借用其它摄像头来帮助呈现后视等功能。
2.2 前视摄像头对比
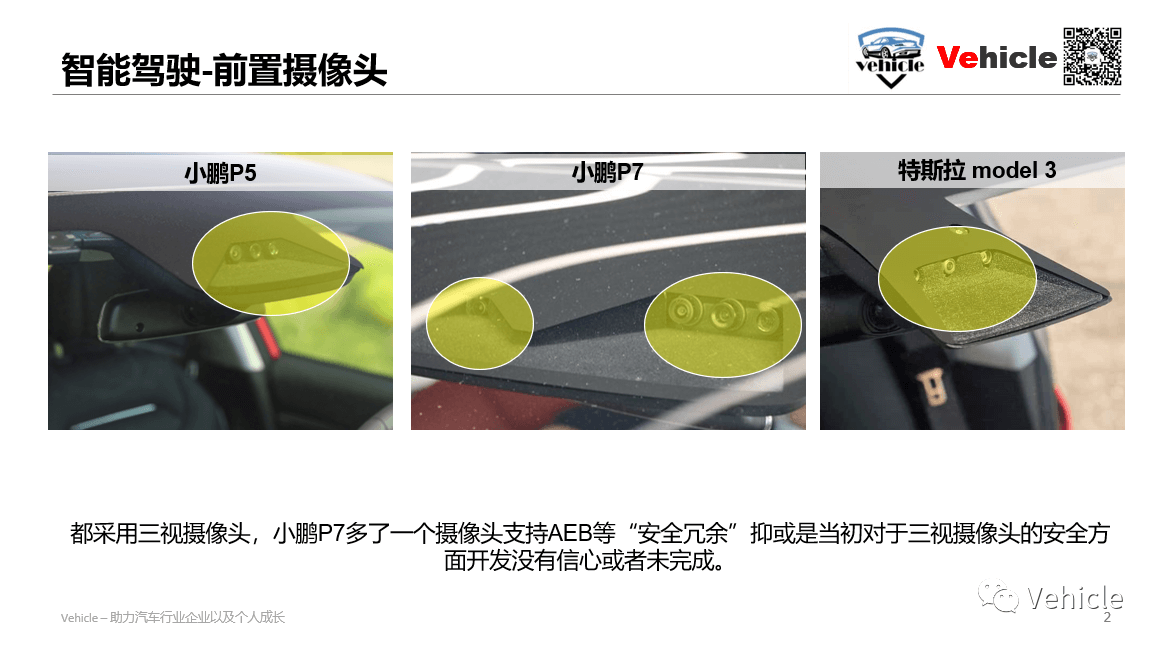 小鹏P7前视4个摄像头、P5为3个,特斯拉为3个。小鹏前视摄像头为2M像素,帧率为15/60FPS,按照水平视场角(HFOV)可分为:
小鹏P7前视4个摄像头、P5为3个,特斯拉为3个。小鹏前视摄像头为2M像素,帧率为15/60FPS,按照水平视场角(HFOV)可分为:
- HFOV 28:窄视角前向摄像头,用于AEB(自动紧急刹车)、ACC(自适应巡航)和前向碰撞预警。这个摄像头可用于关注150m以上的路面情况;可能是1828×948的分辨率,15FPS,用于远距离的感知;
- HFOV 52:主前向摄像头,用于交通信号灯检测(会看红绿灯)、AEB、ACC、前向碰撞预警和车道感知;
- HFOV 100:宽视角前向摄像头,用于交通信号灯检测(会看红绿灯、辅助主前向摄像头)、雨量检测(自动雨刮要靠它)和防加塞(看的角度更广),猜测应该是60FPS。
而特斯拉的前置摄像头分辨率为1280×960 1.2M像素,提供长达250m的前方图像捕捉系统。
2.3 侧向及后向摄像头对比
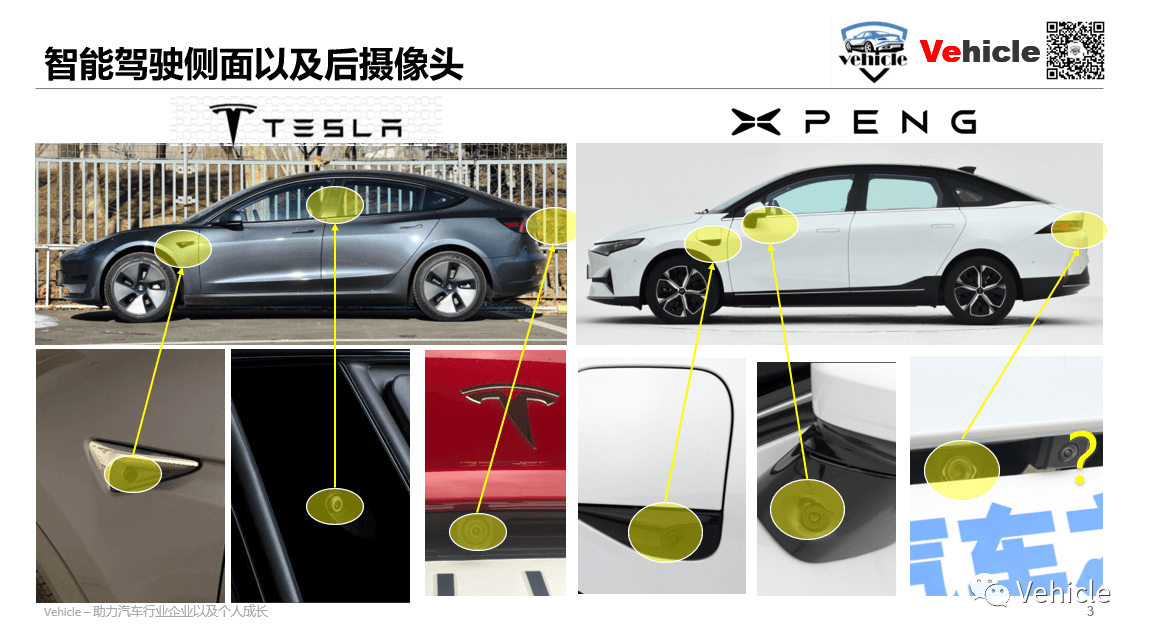 小鹏的侧向摄像头安装在左右车身,HFOV为100,1M像素。侧前方摄像头是60FPS,侧后方为30FPS。这四个摄像头基本可以完成360°的覆盖,甚至视场还有重叠。前侧向摄像头可以用于防加塞和侧向车辆检测,分辨率为457×237,较低的分辨率可以获得更快的相应速度。后侧向摄像头主要用于自动变道(ALC)、开门预警和盲区检测。特斯拉在B柱上布置了侧向前视摄像头,侧向后视和小鹏一致。所谓B柱是指汽车前后门之间的柱子。类似的,A柱指的是前挡风玻璃和前车门之间的柱子,C柱则是指后车门和后挡风玻璃之间的柱子。小鹏和特斯拉都在牌照灯位置布置了后视摄像头,用于自动变道(ALC)、盲区检测和追尾预警。
小鹏的侧向摄像头安装在左右车身,HFOV为100,1M像素。侧前方摄像头是60FPS,侧后方为30FPS。这四个摄像头基本可以完成360°的覆盖,甚至视场还有重叠。前侧向摄像头可以用于防加塞和侧向车辆检测,分辨率为457×237,较低的分辨率可以获得更快的相应速度。后侧向摄像头主要用于自动变道(ALC)、开门预警和盲区检测。特斯拉在B柱上布置了侧向前视摄像头,侧向后视和小鹏一致。所谓B柱是指汽车前后门之间的柱子。类似的,A柱指的是前挡风玻璃和前车门之间的柱子,C柱则是指后车门和后挡风玻璃之间的柱子。小鹏和特斯拉都在牌照灯位置布置了后视摄像头,用于自动变道(ALC)、盲区检测和追尾预警。
2.4 FOV对比图
最后,放出小鹏和特斯拉的FOV对比图。
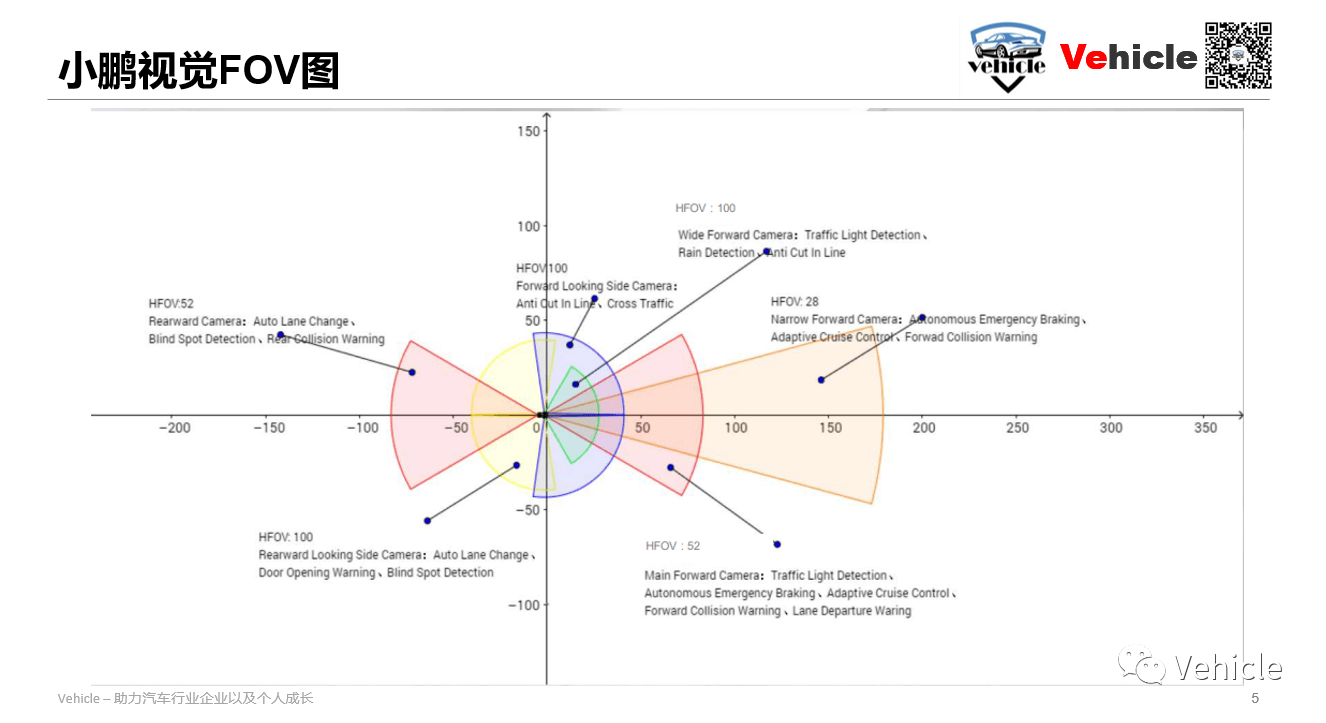 首先是小鹏的视觉FOV图。可以清楚地看到各个摄像头的覆盖范围。对于视觉摄像头而言,一般最长有效距离在150到200m之间。
首先是小鹏的视觉FOV图。可以清楚地看到各个摄像头的覆盖范围。对于视觉摄像头而言,一般最长有效距离在150到200m之间。
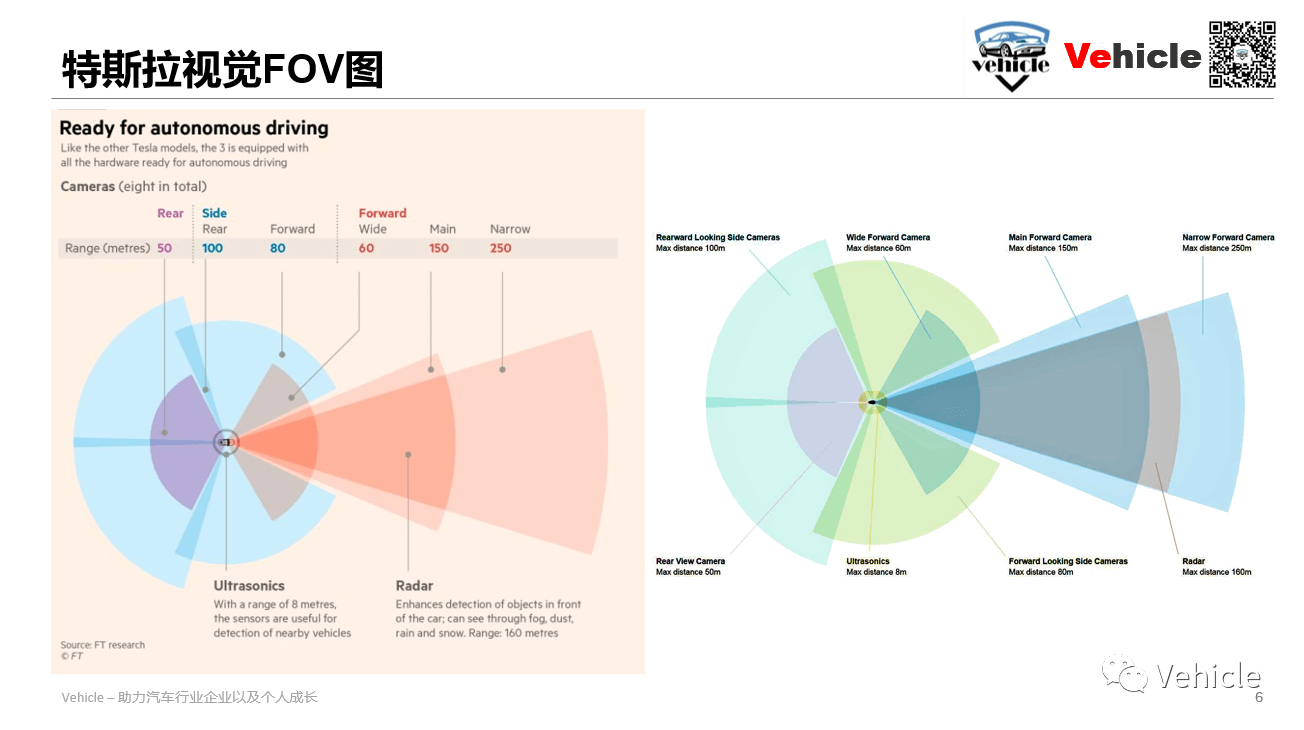 上图为特斯拉的FOV图。可以看到主要内容都是类似的。前向采用了三个摄像头以覆盖远、中、近范围,四个侧向摄像头以覆盖360°范围,以及一个后向摄像头。不同之处在于其前视窄视角的摄像头宣称可以达到250m的有效距离,比小鹏远了近100m。此外,侧向后视摄像头的FOV也有一些差异。小鹏的尾部摄像头视线长,但窄,而特斯拉采用两个侧向摄像头覆盖后视场景,而尾部摄像头视线短,但宽。这里可以看出特斯拉的尾部摄像头主要是用作倒车或者泊车影像,而小鹏有另外一套泊车环视摄像头。
上图为特斯拉的FOV图。可以看到主要内容都是类似的。前向采用了三个摄像头以覆盖远、中、近范围,四个侧向摄像头以覆盖360°范围,以及一个后向摄像头。不同之处在于其前视窄视角的摄像头宣称可以达到250m的有效距离,比小鹏远了近100m。此外,侧向后视摄像头的FOV也有一些差异。小鹏的尾部摄像头视线长,但窄,而特斯拉采用两个侧向摄像头覆盖后视场景,而尾部摄像头视线短,但宽。这里可以看出特斯拉的尾部摄像头主要是用作倒车或者泊车影像,而小鹏有另外一套泊车环视摄像头。
3.自动驾驶应用场景
自动驾驶根据难易程度可以分为三种场景:低速场景-泊车、高速场景-高速封闭道路、复杂场景-城市道路。无论各家分的如何细致,其实都是对这三种场景的进一步细分。一些更加细分的场景介绍可以参考这个网页。
3.1 低速场景-泊车
当前最原始的泊车主要依赖超声波传感器,利用基于鱼眼摄像头为主导的视觉融合方案,寻找车位和辅助泊车。而小鹏利用前置摄像头的SLAM实现这个功能,其目标是为了导航,将他们的周围环境与他们自己的位置相关联。
3.2 高速场景-高速或高架等封闭道路巡航
这也是当前相对成熟的领域,主要基于高精地图实施自动进出匝道,以及在封闭道路进行巡航。这一部分一个重点的内容是规避,比如规避一些复杂的交通参与者等。
3.3 复杂场景-城市道路
该场景为自动驾驶最难以应付的场景,情况复杂、拥挤且各种速度都有所覆盖。这其中又有两类情景最难处理。
一类是“变道插车(cut in)”。所谓变道插车是指侧向或后向的车忽然变道,以“插队”的方式短时间内插到了你的前面。下图展示了变道插车的示意。
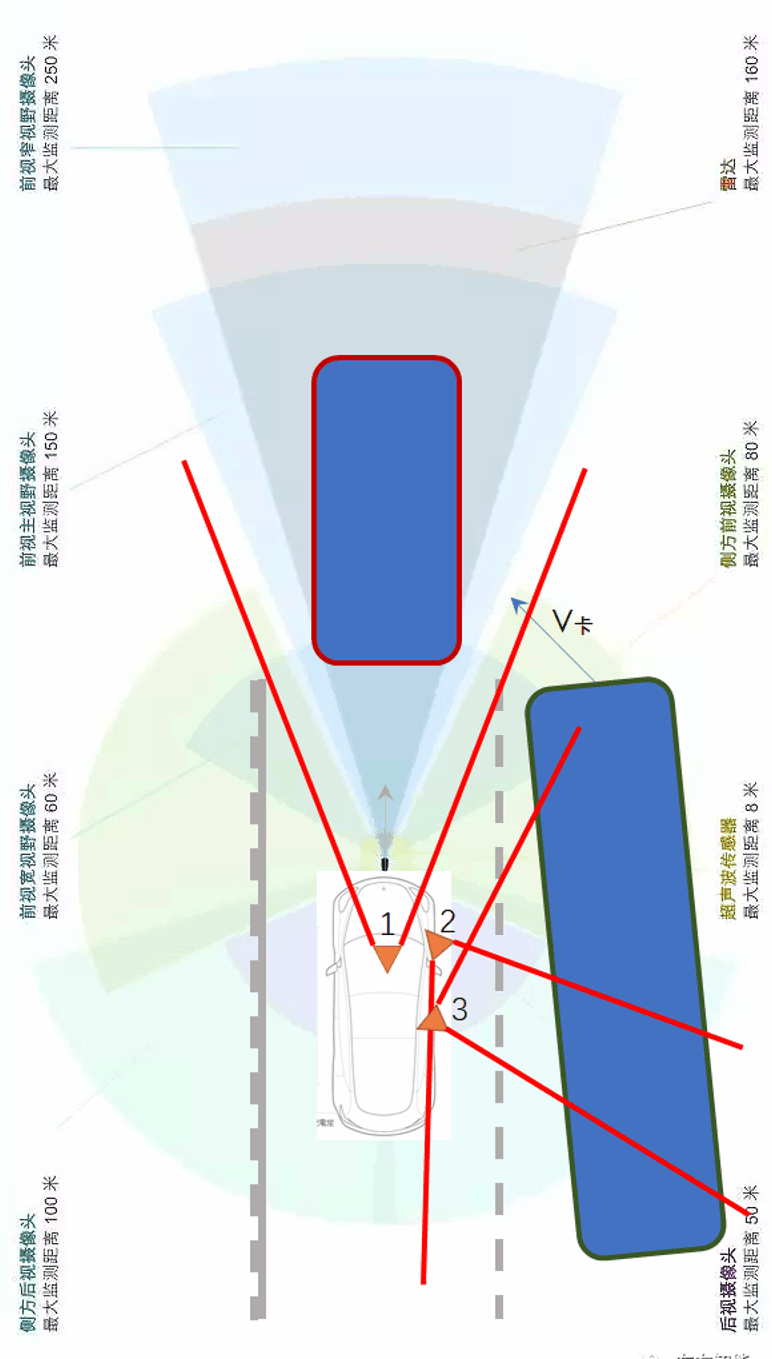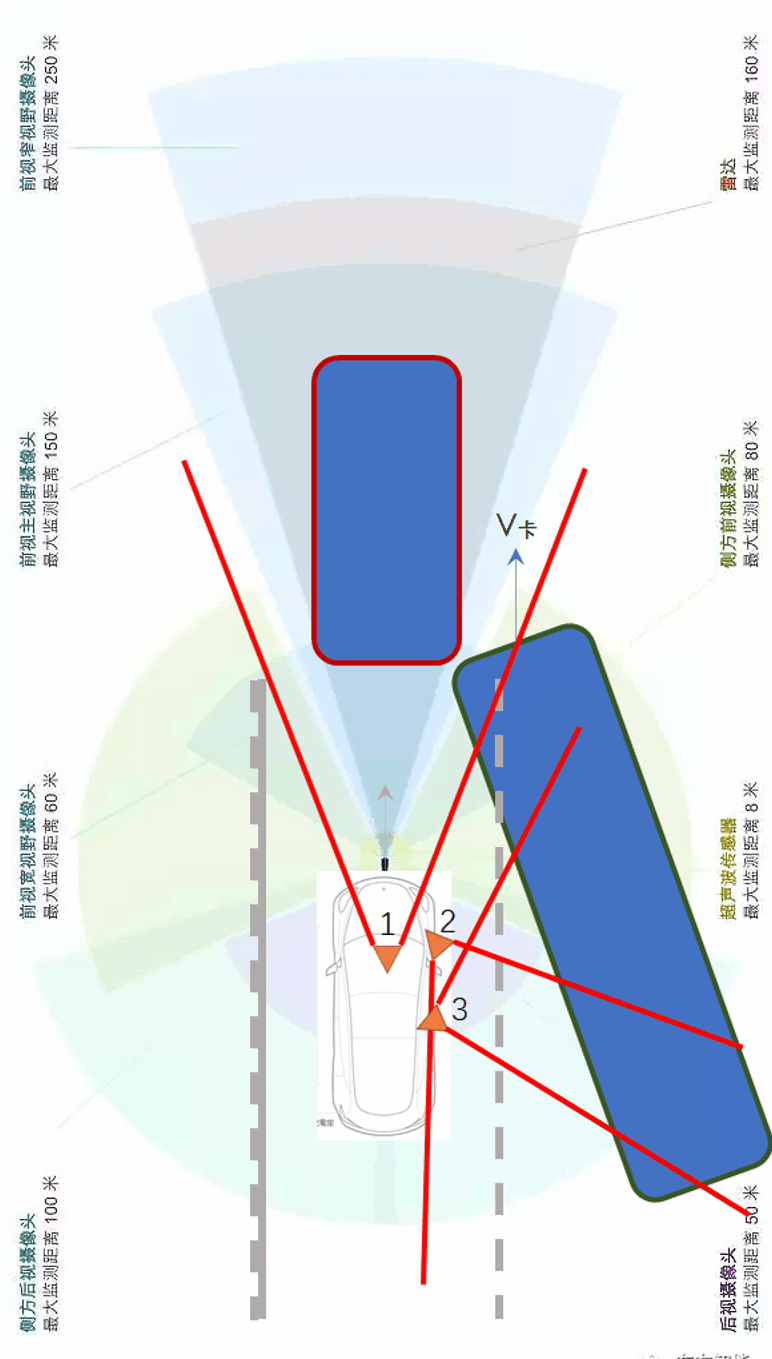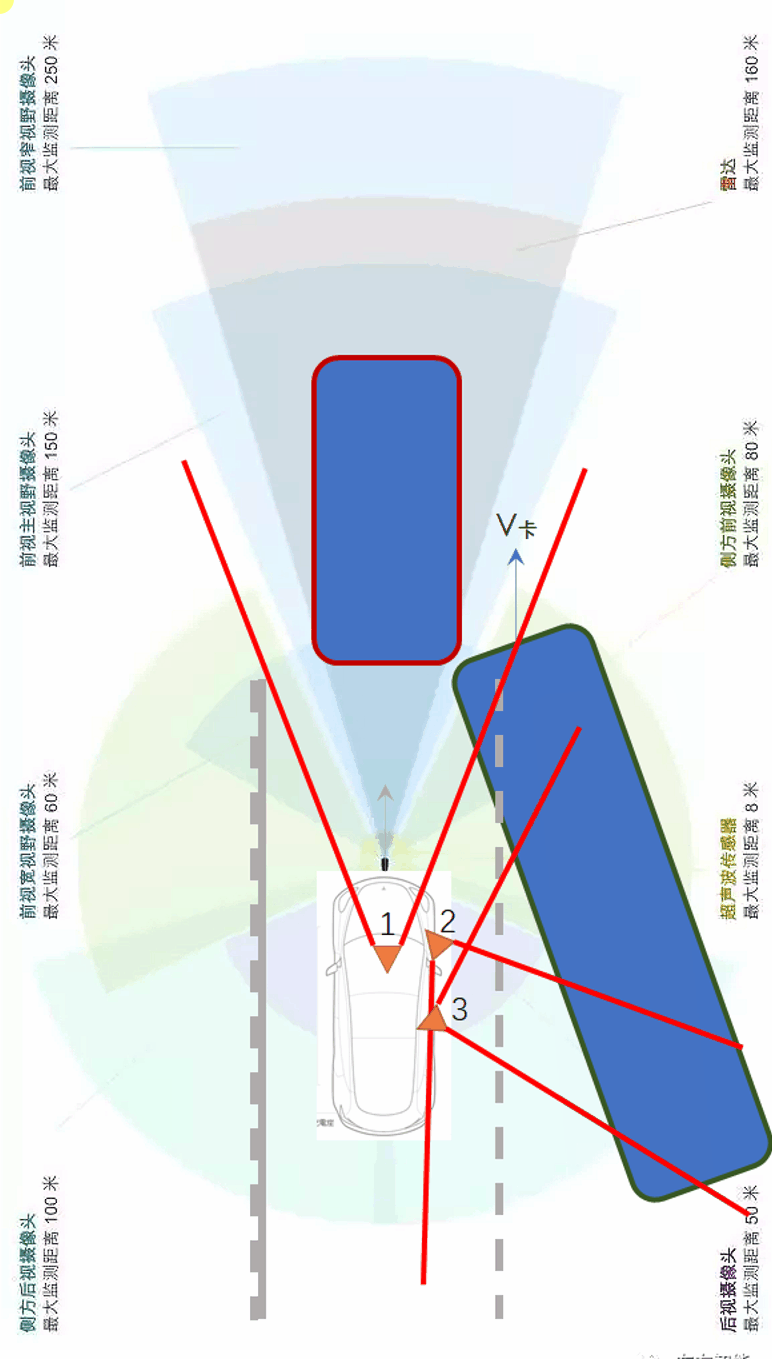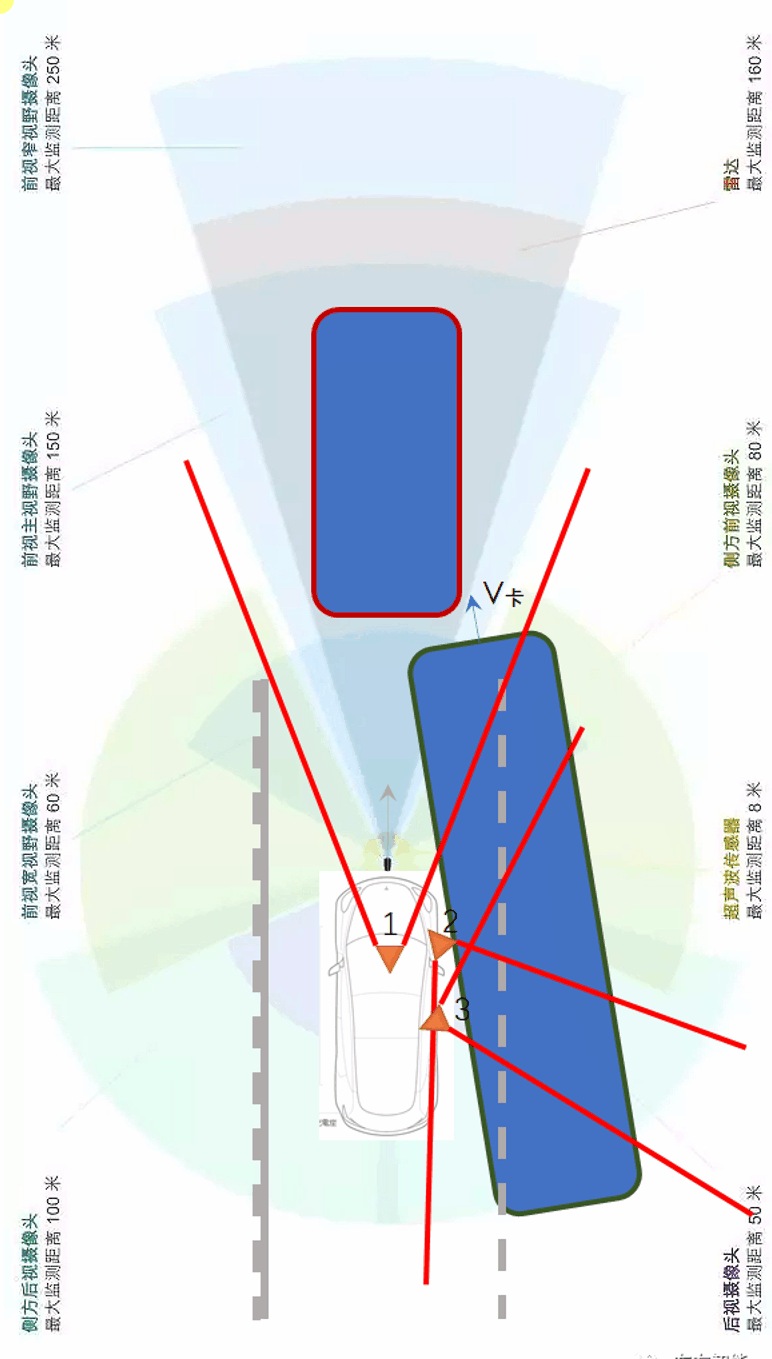
另一类是“鬼探头”。所谓鬼探头是交通领域的一个说法,指的是某些行人或车辆从驾驶员的视野盲区里突然出现的情况。如果驾驶员来不及反应,就会造成事故。一个典型的场景如下。

4.自动驾驶中的一些概念与缩写
在前面,我们也提到了一些英文缩写与概念,这里就简单再总结一下。本部分主要参考这个网页,感兴趣可以阅读。
4.1 行车功能
-
ACC:全称Adaptive Cruise Control,即自适应巡航控制。作为智能驾驶的基本功能,ACC是大家都耳熟能详的一项功能,也已经发展地比较成熟。通过对道路环境和障碍物的感知,自动控制油门和制动系统,实现车辆在本车道内的自动加减速,以及起步、停车等动作,ACC可以帮助驾驶员解放双脚,缓解直线行驶的疲劳。
-
LCC,全称Lane Centering Control,即车道居中控制。LCC是一项纯横向控制功能,通过对车道线的识别和对转向系统的自动控制,解放驾驶员的双手,让车辆自动保持在本车道内居中行驶。
-
ALC,全称Auto Lane Change,即自动变道辅助。虽然字面名称叫做“自动变道”,但其实目前主流做法是“指令式变道”,一般是通过转向拨杆,控制车辆的转向系统,实现自动变道。ALC可以有效辅助驾驶员实现变道,解放双手。
-
TJA,全称Traffic Jam Assistant,即交通拥堵辅助。TJA可以理解为ACC和LCC功能的叠加,属于L2级功能。该功能在堵车时,通过自动控制车辆的启停和加减速,以及微调行驶方向,实现车辆自动保持在本车道居中跟车,或巡航行驶的功能。
-
NOA,全称Navigate On Autopilot,即领航辅助驾驶。基于导航地图,NOA可以让车辆自动按导航的路径实现点到点行驶,长时间解放驾驶员的手和脚。NOA属于L3级的智能驾驶功能,是低级别智能驾驶功能如ACC、LCC、ALC等的叠加。按可用区域的不同,NOA主要分为高速领航驾驶辅助和城区领航驾驶辅助。受技术条件的限制,当前已量产的NOA都是高速领航辅助驾驶;造车新势力如特斯拉和蔚来、小鹏、理想等,已经在探索城区道路的领航辅助驾驶功能。
4.2 泊车功能
-
APA,全称Auto Parking Assist,即自动泊车辅助功能。功能开启后,APA识别出车辆周围可用的车位,并且在驾驶员选定车位后,控制车辆的横纵向运动,实现自动泊入和泊出车位。APA功能需要保持驾驶员在车上,随时接管。目前APA功能已经发展成熟,日渐成为车辆的标准化配置。
-
RPA,全称Remote Parking Assist,即遥控泊车辅助。驾驶员下车后,通过手机APP等遥控方式,控制车辆自动泊入和泊出车位。
-
SS,全称Smart Summon,即智能召唤功能。智能召唤功能最早由特斯拉推出,可以让车主在车外通过手机APP的方式,发出召唤指令,从而控制车辆自动行驶,到达指定的位置。
-
HPA,全称Home-zone Parking Assist,即记忆泊车功能。通过系统自学习,记住车辆在特定区域(家庭或公司停车场)的特定车位,以及行驶轨迹,HPA可以控制车辆从停车场入口开始,自动完成寻找车位和泊车的所有动作。目前小鹏已经实现了量产的HPA功能,由于可用区域限定在停车场内,且需要驾驶员在车上随时接管,因此HPA属于L3级的智能驾驶。
-
AVP,全称Automated Valet Parking,即自主代客泊车。AVP是真正意义上的全自动驾驶,车辆可以自行进入完全陌生的停车场,不需要先行学习,就能完成所有的泊车动作,并且不需要驾驶员在车上。作为L4级别的智能驾驶,目前对软硬件,尤其是算法和安全性要求很高,目前还没有量产的产品。
5.自动驾驶中的高精地图
高精地图也称为高分辨率地图(High Definition Map, HDMap)或者高度自动驾驶地图(Highly Automated Driving Map, HAD Map)。高精地图拥有精确的地理位置信息和丰富的道路元素语义信息,能起到构建类似于人脑对于空间的整体记忆与认知功能,可以帮助自动驾驶车辆预知路面复杂信息,如坡度、曲率、航向等,更好的规避潜在的风险,是实现自动驾驶的关键所在。本部分主要参考这个网页。
5.1高精地图对自动驾驶的意义
具体来说,其对自动驾驶有以下三个方面的意义:
-
辅助环境感知。各类传感器都有其局限性,如易受恶劣环境影响,性能受限或者算法鲁棒性不足等。高精地图可以对传感器无法探测或者探测精度不够的部分进行补充,实现实时状况的检测以及外部信息的反馈,进而获取当前位置精准的交通状况。另一个例子是,如果自动驾驶汽车在行驶过程中检测到高精地图不存在的元素,则在一定程度上可将这些元素视为障碍物。通过该方式,可以帮助感知系统识别周围环境,提高检测精度和检测速度,并节约计算资源。
-
辅助定位。由于定位系统可能因环境关系或者系统稳定性问题存在定位误差,无人驾驶车辆并不能与周围环境始终保持正确的位置关系,在无人驾驶车辆行驶过程中,利用高精地图元素匹配可精确定位车辆在车道上的具体位置,从而提高无人驾驶车辆的定位精度。相比更多的依赖于GNSS提供定位信息的普通导航地图,高精地图更多依靠其准确且丰富的先验信息(如车道形状、曲率、路面导向箭头、交通标志牌等),通过结合高维度数据与高效率的匹配算法,能够实现符合自动驾驶车辆所需的高精度定位功能。
-
辅助路径规划与决策。普通导航地图仅能给出道路级的路径规划,而高精地图的路径规划导航能力则提高到了车道级,例如高精地图可以确定车道的中心线,可以保证无人驾驶车辆尽可能地靠近车道中心行驶。在人行横道、低速限制或减速带等区域,高精地图可使无人驾驶车辆能够提前查看并预先减速。对于汽车行驶附近的障碍物,高精地图可以帮助自动驾驶汽车缩小路径选择范围,以便选择最佳避障方案。
-
辅助控制。高精地图是对物理环境道路信息的精准还原,可为无人驾驶车辆加减速、并道和转弯等驾驶决策控制提供关键道路信息。而且,高精地图能给无人驾驶车辆提供超视距的信息,并与其它传感器形成互补,辅助系统对无人驾驶车辆进行控制。高精地图为无人驾驶车辆提供了精准的预判信息,具有提前辅助其控制系统选择合适的行驶策略功能,有利于减少车载计算平台的压力以及对计算性能瓶颈的突破,使控制系统更多关注突发状况,为自动驾驶提供辅助控制能力。因此,高精地图在提升汽车安全性的同时,有效降低了车载传感器和控制系统的成本。
5.2高精地图的采集方式
目前,主流高精地图有“高配”和“低配”两种采集方式。高配版是指激光雷达(LiDAR)+组合惯导+RTK的高精度自采方案,低配版是指RTK+视觉的众包采集方案。这两种方案主要是在精度与成本两个因素中进行取舍的结果。两者都经历了长期的演进,孰优孰劣无法一概而论。或者说,方案的选择更多的要看具体的业务需求与场景条件。
5.2.1高精度自采方案
很多自动驾驶厂商目前上线使用的高精地图的原始数据都采集自高规格的多传感器(LiDAR+惯导+RTK)采集设备。这种数据可重建出具备厘米级精度的道路地图,但其采用的各种“顶配传感器”动辄几十万元。业界常见的装备齐全的高精地图采集车通常都需要几百万元一辆,如下图所示。
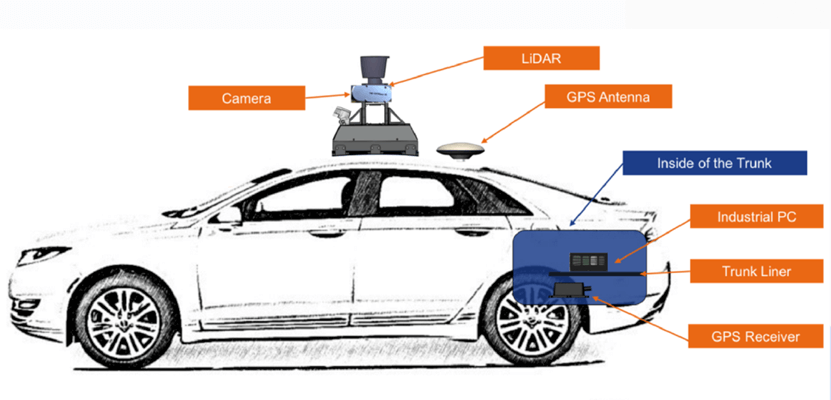 在这种方案下,建图主要过程是以惯导+RTK融合的位姿作为先验,之后基于LiDAR点云进行三维场景的高精重建。得到精确的位姿和点云后,再通过LiDAR在地面上的反射率图恢复出路面标识,并进一步进行矢量化,最终完成高精地图的生产。
在这种方案下,建图主要过程是以惯导+RTK融合的位姿作为先验,之后基于LiDAR点云进行三维场景的高精重建。得到精确的位姿和点云后,再通过LiDAR在地面上的反射率图恢复出路面标识,并进一步进行矢量化,最终完成高精地图的生产。
5.2.2视觉众包方案
对于高精地图生产而言,最大的成本不在于完成一次全路网的地图构建,而在于如何解决高精地图的随时更新。如何用较低的成本维持一个城市级别乃至国家级别路网的鲜度,才是各大地图厂商面临的最大挑战。随着传感器芯片的不断发展,集成了GNSS、IMU模块与摄像头的模块的一体式设备成本已经到达百元级别,如下图所示。
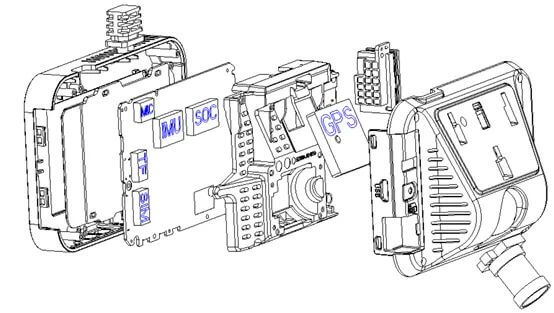 事实上,这一传感器组合采集的数据在很多路况下已经可以胜任高精地图重建任务。目前道路上有大量乘用车已经安装了带有GNSS功能的行车记录仪。一方面,行车记录仪可以保证日常的行车安全需要。另一方面,记录仪采集的原始数据可以通过网络回传到服务器,经过数据清洗工作后形成建图数据集,并进一步通过地图重建算法形成高精地图。
事实上,这一传感器组合采集的数据在很多路况下已经可以胜任高精地图重建任务。目前道路上有大量乘用车已经安装了带有GNSS功能的行车记录仪。一方面,行车记录仪可以保证日常的行车安全需要。另一方面,记录仪采集的原始数据可以通过网络回传到服务器,经过数据清洗工作后形成建图数据集,并进一步通过地图重建算法形成高精地图。
但这种方案的缺点是,由于传感器成本较低,同时受路况和天气的影响较大,其采集的数据质量难以保证。因此在这种方案下,需要有很好的算法能力以及数据清洗能力,技术上有很多难关要攻克。例如如何高效合理的对原始采集数据进行回传与筛选,如何指定特定的区域进行更新,如何克服低价传感器带来的各种误差,如何解决设备多样性带来的误差等等。同时,如果真的将这种方式投入到规模化的高精地图生产,还需要解决好法律上的测绘合规的问题。
基于视觉众包方案的地图生产可以简单分为三类方法:基于Structure-from-Motion的重建、基于深度网络的视觉重建、基于语义的矢量化视觉重建。感兴趣可以参考这个网页,这里不再赘述。
6.深度学习在自动驾驶中的应用
基于深度学习的计算机视觉在无人驾驶的视觉感知系统中主要有以下四个方面的作用:
- 动态物体检测(Dynamic Object Detection)
- 通行空间监测(Free Space Detection)
- 车道线检测(Lane Detection)
- 静态物体检测(Static Object Detection)
本部分主要参考这个网页。
6.1 动态物体检测
-
检测需求:对车辆(轿车、卡车、电动车、自行车)、行人等动态物体的识别
-
检测难点:(三座大山:检测类别多、多目标追踪难度大、测距精度足够准)

对于实际应用场景,我们希望的是获得物体的3D框而非2D框。另外,对于动态物体的检测,最后需要结合激光雷达的结果进行融合,在夜间、雨雪天气,视觉无法处理;同时,有激光雷达信息,对于车辆的朝向信息判断更准确,仅凭一个摄像头去做检测、去做heading、去做精准的距离判断,难度太大。
6.2 通行空间检测
-
检测需求:对车辆行驶的安全边界(可行驶区域)进行划分,主要对车辆、普通路边沿、侧石边沿、没有障碍物可见的边界、未知边界进行划分
-
检测难点:(1)复杂环境场景时,边界形状复杂多样,导致泛化难度较大。不同于其它的检测有明确的检测类型(如车辆、行人、交通灯),通行空间需要把本车的行驶安全区域划分出来,需要对凡是影响本车前行的障碍物边界全部划分出来,如平常不常见的水马、锥桶、坑洼路面、非水泥路面、绿化带、花砖型路面边界、十字路口、T字路口等进行划分。(2)标定参数校正;在车辆加减速、路面颠簸、上下坡道时,会导致相机俯仰角发生变化,原有的相机标定参数不再准确,投影到世界坐标系后会出现较大的测距误差,通行空间边界会出现收缩或开放的问题。(3)边界点的取点策略和后处理;通行空间考虑更多的是边缘处,所以边缘处的毛刺,抖动需要进行滤波处理,使边缘处更平滑。障碍物侧面边界点易被错误投影到世界坐标系,导致前车隔壁可通行的车道被认定为不可通行区域,如下图所示。

对于上面提到的第二个难点,若不能实现实时在线标定功能,可以考虑增加读取车辆的IMU信息,利用车辆IMU信息获得的俯仰角自适应地调整标定参数。
6.3 车道线检测
- 检测需求:对各类车道线(单侧/双侧车道线、实线、虚线、双线)进行检测,还包括线型的颜色(白色/黄色/蓝色)以及特殊的车道线(汇流线、减速线等)的检测
标准单一情况下的车道线识别难度不大,路况大都是平行笔直的实线或虚线(如特斯拉支持高速公路的辅助驾驶,它们的车道线检测拟合的效果极好)。车道线的检测难点在于:
- 线型种类多,不规则路面检测车道线难度大;如遇地面积水、无效标识、修补路面、阴影情况下的车道线容易误检、漏检;
- 上下坡、颠簸路面,车辆启停时,容易拟合出梯形、倒梯形的车道线;
- 弯曲的车道线、远端的车道线、环岛的车道线,车道线的拟合难度较大,检测结果易闪烁。

传统的图像处理算法需经过摄像头的畸变校正,对每帧图片做透视变换,将相机拍摄的照片转到鸟瞰图视角,再通过特征算子或颜色空间来提取车道线的特征点,使用直方图、滑动窗口来做车道线曲线的拟合,传统算法最大的弊端在于场景的适应性不好。采用神经网络的方法进行车道线的检测跟通行空间检测类似,选取合适的轻量级网络,打好标签;车道线的难点在于车道线的拟合(三次方程、四次方程),所以在后处理上可以结合车辆信息(速度、加速度、转向)和传感器信息做航位推算,尽可能的使车道线拟合结果更佳。
6.4 静态物体检测
-
检测需求:对交通红绿灯、交通标志等静态物体的检测识别
-
检测难点:(1)红绿灯、交通标识属于小物体检测,在图像中所占的像素比极少,尤其远距离的路口,识别难度更大。如在1920×1208的影像上,红绿灯可能仅为18×45像素左右,在强光照的情况下,人眼都难以辨别,而停在路口的斑马线前的汽车,需要对红绿灯进行正确的识别才能做下一步的判断。(2)交通标识种类众多;采集到的数据易出现数量不均匀的情况。(3)交通灯易受光照的影响,在不同光照条件下颜色难以区分(红灯与黄灯),且到夜晚时,红灯与路灯、商店的灯颜色相近,易造成误检。

通过感知去识别红绿灯,有一种“舍身取义”的感觉,效果一般,适应性差,条件允许的话(如固定园区限定场景),该装V2X就装V2X,多个备份冗余,V2X > 高精度地图 > 感知识别。若碰上GPS信号弱的时候,感知识别可以出场了,大部分情况,V2X足以满足大部分场景。所谓V2X是指Vehicle to everything,即车对外界的信息交换。一个简单的例子是,如果某个交通红绿灯实施向周围广播其状态,我们通过V2X的思想,采用某种手段实时获取到红绿灯的状态,就可以准确地知道当前状态,进而进行决策。而且这种传输方式可靠,不易受外界干扰。
7.自动驾驶中的多传感器融合
这里简单概述一下自动驾驶中的多传感器融合相关内容。本部分主要参考这个网页、这个网页和这个网页。
传感器融合是自动驾驶汽车的关键技术之一。这是自动驾驶汽车工程师都必须具备的技能。自动驾驶汽车通过4个关键技术工作:感知、定位、规划和控制。
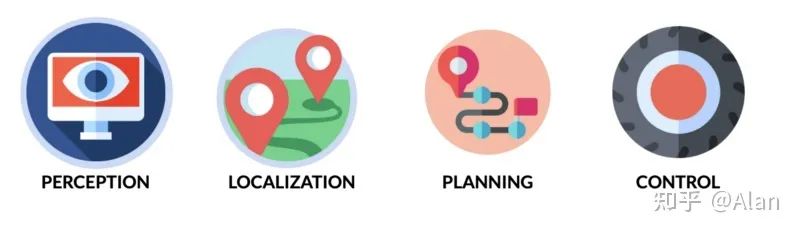 传感器融合是感知模块的一部分。我们希望融合来自视觉传感器的数据,以增加冗余、确定性或利用多个传感器的优势。
传感器融合是感知模块的一部分。我们希望融合来自视觉传感器的数据,以增加冗余、确定性或利用多个传感器的优势。
7.1 LiDAR、视觉相机、雷达传感器概述
 上图展示了现在常用的三类传感器:相机、LiDAR和雷达,并进行了比较。可以看到,摄像头擅长处理对象分类与场景理解;而激光雷达非常适合距离测量;雷达则可以直接测量障碍物的速度。
上图展示了现在常用的三类传感器:相机、LiDAR和雷达,并进行了比较。可以看到,摄像头擅长处理对象分类与场景理解;而激光雷达非常适合距离测量;雷达则可以直接测量障碍物的速度。
LiDAR本质上是一种通过激光进行探测与测距的传感器,其可以获取到被测物体较为准确的三维信息。一般而言LiDAR的探测距离在200m左右,其感知范围小于视觉传感器(理论上视觉传感器可以拍到无穷远处的物体,只要分辨率够高就能够识别)。另一方面,LiDAR的角分辨率(一般为0.1°或0.2°)数值比较大,导致点云的分辨率远小于图像传感器,在远距离感知时,投射到目标物上的点可能及其稀疏,甚至无法成像。对于点云目标检测来说,算法真正能用的点云有效距离大约只有100米左右。另外,激光雷达虽然对环境光线影响不敏感,但对于积水路面、玻璃墙面等,测距将受到很大影响。
而图像传感器能以高帧率、高分辨率获取周围复杂信息,且价格便宜。在车上可以同时部署多个不同FOV和分辨率的传感器用于不同距离和范围的视觉感知,分辨率可以达到2K-4K。但图像传感器是一种被动式传感器,深度感知不足,测距精度差,特别是在恶劣环境下完成感知任务的难度会大幅提升。在面对强光、夜晚低照度、雨雪雾等天气和光线环境下,视觉传感器一定程度上会失效。
所以,激光雷达和图像传感器各有优劣。大多数高级别智能驾驶乘用车选择将不同传感器进行融合使用,优势互补、冗余融合。这样的融合感知方案也成为了高级别自动驾驶的关键技术之一。
按照不同维度,可以有不同的融合分类标准和技术路线。“我们想要哪种类型的融合?”至关重要,进一步又有三个问题:
-
按抽象级别,“何时”进行融合?(When) 按照融合系统中信息处理的抽象程度,可以分为数据层(low level)、特征层(mid-level)、决策层(high level)三个层次。
-
按中心化级别,在“哪里”进行融合?(Where) 按照处理数据的方式,可以分为中心化、去中心化和分布式三种。
-
按竞争级别,为了“什么”而融合?(What) 按照融合的目的,可以分为竞争、互补、协同三种。
下面分别对每种进行简单介绍。
7.2 按抽象级别划分
如下图所示,展示了不同抽象等级划分的融合策略。
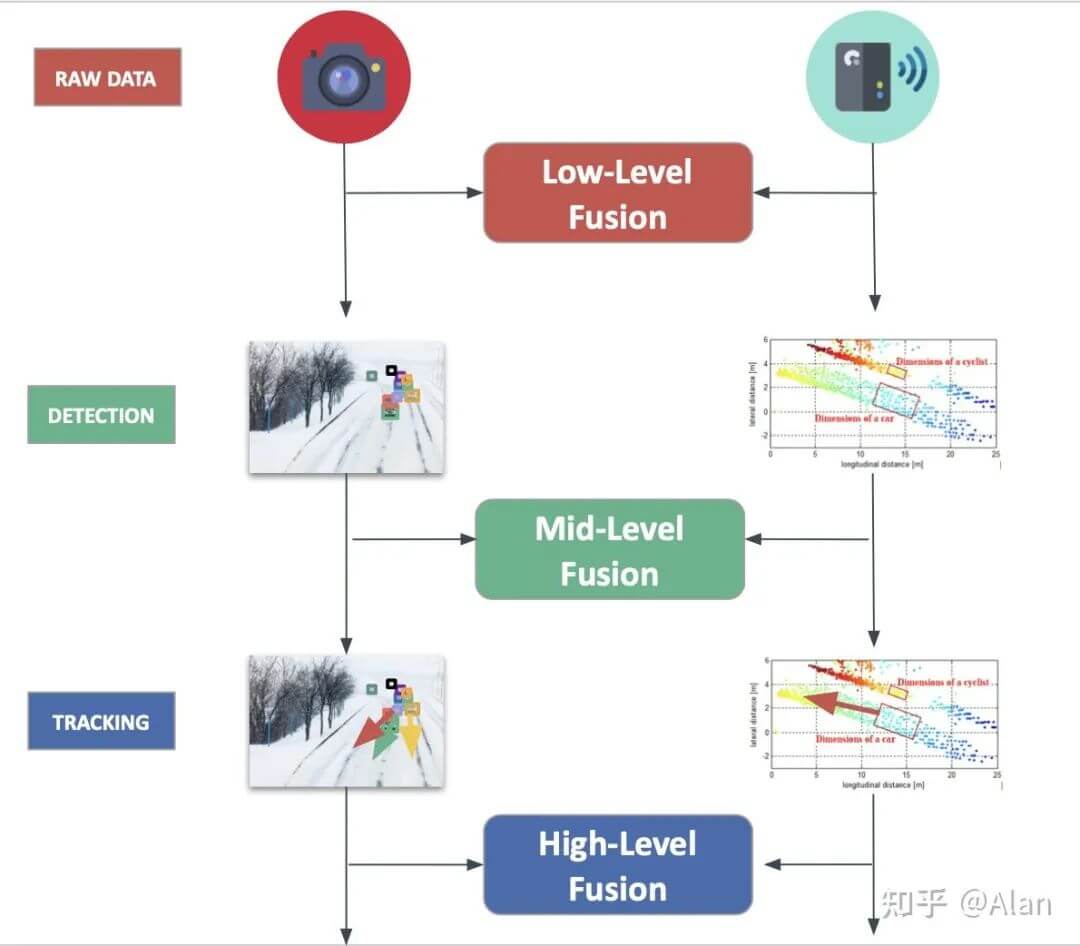
7.2.1 数据层融合
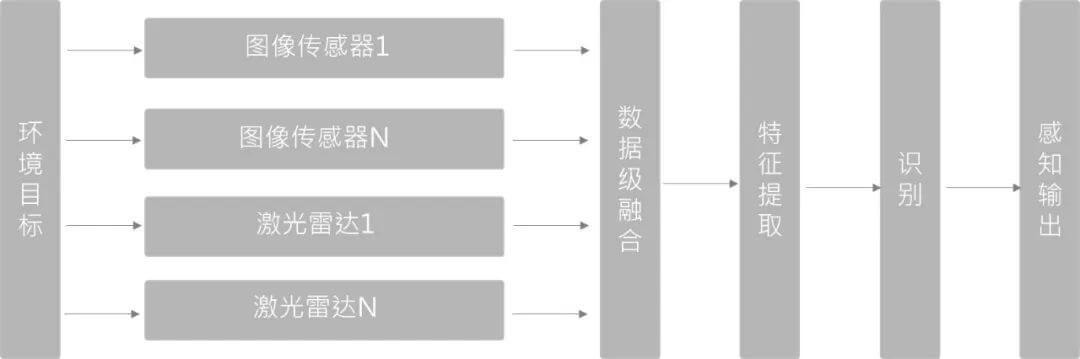 如上图所示,数据层融合是比较容易理解的一类方法。直接将多模态数据进行融合,在融合后的数据上进行特征提取等后续操作。这种类型的融合在未来几年具有很大的潜力,因为其考虑了所有数据。当然缺点就是这样直接融合数据量是比较大的,如融合几十万个点云和RGB影像,对算力有一定要求。
如上图所示,数据层融合是比较容易理解的一类方法。直接将多模态数据进行融合,在融合后的数据上进行特征提取等后续操作。这种类型的融合在未来几年具有很大的潜力,因为其考虑了所有数据。当然缺点就是这样直接融合数据量是比较大的,如融合几十万个点云和RGB影像,对算力有一定要求。
7.2.2 特征层融合
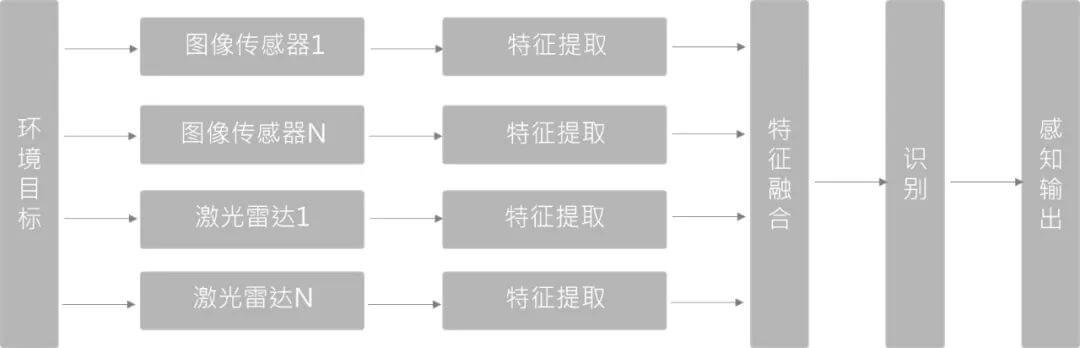 如上图所示,对于每一种数据,我们先提取多种特征,然后对这些提取的特征进行融合,得到最终可用于后续处理的总特征。比如摄像头检测到了障碍物,雷达也检测到了,我们就把这些结果融合到一起形成对障碍物的位置、类别和速度的最佳估计。通常使用的方法是卡尔曼滤波器(贝叶斯算法)。
如上图所示,对于每一种数据,我们先提取多种特征,然后对这些提取的特征进行融合,得到最终可用于后续处理的总特征。比如摄像头检测到了障碍物,雷达也检测到了,我们就把这些结果融合到一起形成对障碍物的位置、类别和速度的最佳估计。通常使用的方法是卡尔曼滤波器(贝叶斯算法)。
7.2.3 决策层融合
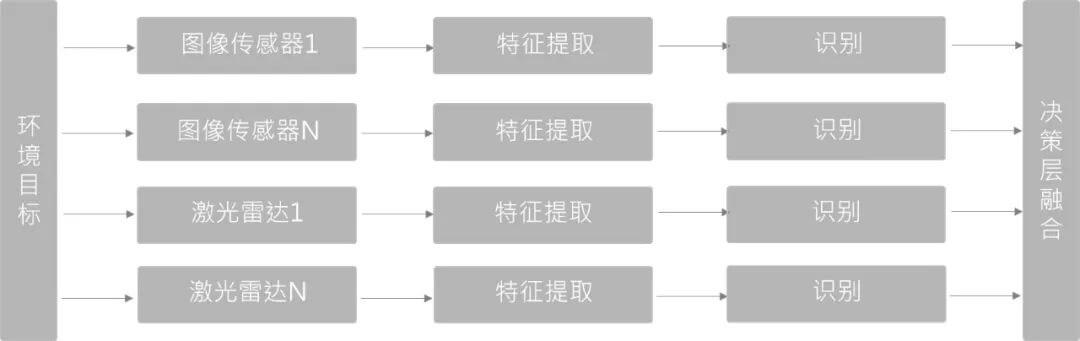 如上图所示,相对前两种来说,是复杂度最低的一种融合方式。不在数据层或特征层融合,是一种目标/对象级别的融合。不同传感器网络结构互不影响,可以独立训练和组合。由于决策层融合的两类传感器和检测器相互独立,一旦某传感器发生故障,仍可进行传感器冗余处理,工程上鲁棒性更好。
如上图所示,相对前两种来说,是复杂度最低的一种融合方式。不在数据层或特征层融合,是一种目标/对象级别的融合。不同传感器网络结构互不影响,可以独立训练和组合。由于决策层融合的两类传感器和检测器相互独立,一旦某传感器发生故障,仍可进行传感器冗余处理,工程上鲁棒性更好。
7.3 按中心化级别划分
如下图所示,展示了不同中心化方式的融合策略。
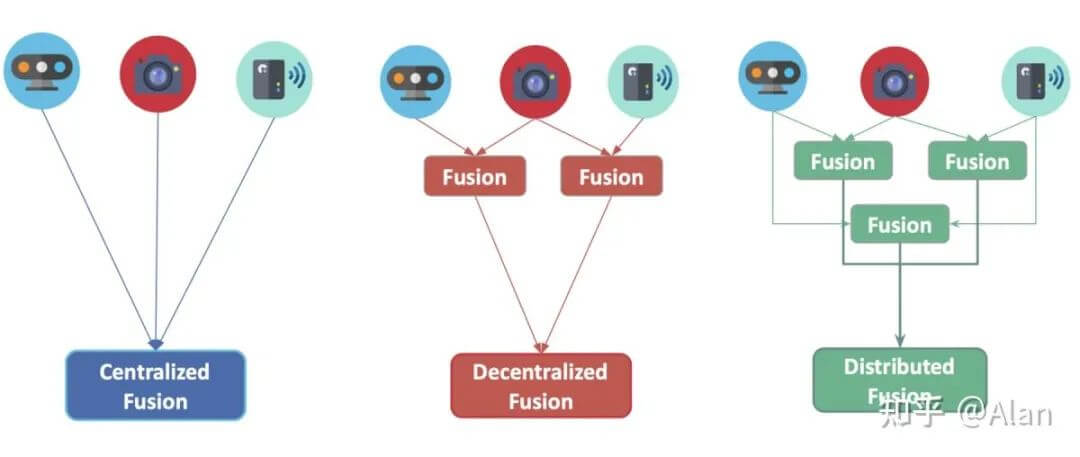
7.3.1 中心化融合
顾名思义就是所有传感器融合都在一个中央单元处理器进行。
7.3.2 去中心化融合
所谓去中心化融合是指每个传感器在一些边缘计算设备上融合数据,并将其转发到下一级处理单元。
7.3.3 分布式融合
分布式融合是指每个传感器在本地处理数据,并将其发送到下一级处理单元。
7.4 按竞争级别划分
如下图所示,展示了不同竞争级别的融合策略。
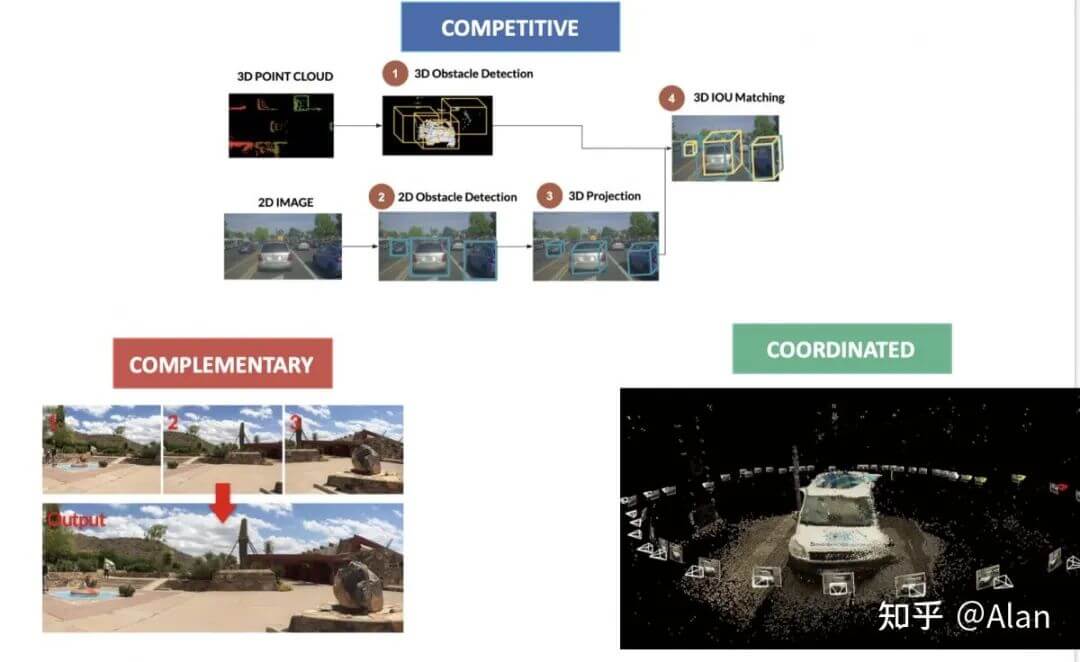
7.4.1 竞争融合
竞争融合是指传感器用于相同目的。例如,当同时使用雷达和激光雷达来检测行人时,这里发生的数据融合过程称为冗余,使用术语“竞争”。
7.4.2 互补融合
互补融合是指使用不同的传感器观察不同的场景来获取我们使用其它方式无法获得的东西。例如,使用多个摄像头构建全景图时,由于这些传感器相互补充,使用术语“互补”。
7.4.3 协同融合
协同融合是关于使用两个或更多传感器来产生一个新场景,但是关于同一个对象的。例如,在使用2D传感器进行3D扫描或3D重建时。
当然,这里你可能会有疑惑,协同融合和竞争融合是什么关系。我的个人理解是协同融合是针对的同模态传感器,而竞争融合针对的是多模态传感器。例如我们用10个相机拍摄同一场景,他们都是同模态的,所以这10个相机之间是协同融合关系。而如果此时又多了个LiDAR也来观测这个场景,那么这个LiDAR和10个相机之间就是竞争融合关系。最后,如果又有个新的相机,同时观测了另一个场景。那么这个新的相机相对于其它传感器就是互补融合关系。
8.参考资料
- [1] https://www.leiphone.com/category/transportation/ucmlrPV2DBPgMn6f.html
- [2] https://mp.weixin.qq.com/s/XbPesOXT1sGAemiaFmRr2Q
- [3] https://zhuanlan.zhihu.com/p/56413233
- [4] https://www.oktesla.cn/2020/07/56083.html
- [5] https://www.leiphone.com/category/transportation/GKB6Zsn4dHQ7cYAu.html
- [6] https://baijiahao.baidu.com/s?id=1713218844449003713
- [7] https://mp.weixin.qq.com/s/SbABjUE1aZ-G_hP2UdJDew
- [8] https://mp.weixin.qq.com/s/YsxE3gO5nmg2ybcbWoIiaQ
- [9] https://mp.weixin.qq.com/s/TSMZcT6rErILXFrI6J1NQA
- [10] https://mp.weixin.qq.com/s/vFiMnNOhBgP5roaY_4WA0A
- [11] https://mp.weixin.qq.com/s/lgAoYIG_ZQZvbfALkJcI-g
- [12] https://mp.weixin.qq.com/s/I0a8MVxAUaS-O-s9mrEZcg
本文作者原创,未经许可不得转载,谢谢配合
