OpenCV绘图
所有绘图函数都需要一下参数:
img:想要绘制的图像
color:绘制形状的颜色。BGR格式,传入元组,如(255,0,0)。对于灰度只需传入灰度值。
thickness:线条粗细,如果给一个闭合图形设置为为-1,则表示填充。默认为1。
linetype:线条类型,8链接、抗锯齿等。默认是8连接。cv2.LINE_AA为抗锯齿。
画线
参数依次为:原图像、起点、终点、颜色、粗细。
draw = np.zeros((300, 300, 3), np.uint8)
cv2.line(draw, (200, 200), (300, 0), (255, 0, 0), 3)
for i in range(200):
cv2.line(draw, (i - 1, i - 1), (i, i), (i, i, 200), 3)
cv2.imshow("draw", draw)
cv2.waitKey(0)
我们可以更设置更复杂的代码画出更好看的线段,如下图:
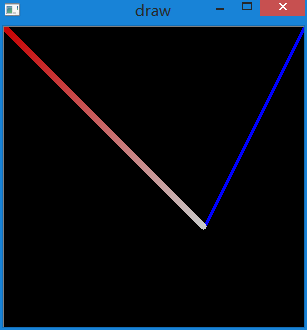
cv2.polylines()可以画多条线。只需要把想画的线放在一个list中,将这个list传递给该函数即可。
每条线都被独立绘制,这比用cv2.line()一条条绘制要快一些。
画矩形
参数与直线完全一样,只是这里的坐标分别代表左上角和右下角点坐标。这里我们可以指定 最后一个参数为-1,表示填充矩形。
draw = np.zeros((300, 300, 3), np.uint8)
cv2.rectangle(draw, (150, 100), (250, 50), (255, 0, 0), 2)
cv2.rectangle(draw, (50, 250), (100, 50), (0, 0, 255), -1)
cv2.imshow("draw", draw)
cv2.waitKey(0)
效果如下:
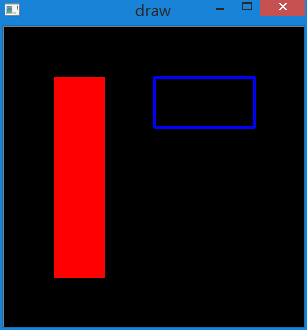
画圆
只需要指定圆心以及半径即可。
draw = np.zeros((300, 300, 3), np.uint8)
draw2 = np.zeros((300, 300, 3), np.uint8)
cv2.circle(draw, (150, 150), 70, (100, 100, 200), -1)
cv2.circle(draw, (200, 200), 50, (0, 0, 200), 5)
cv2.imshow("draw", draw)
cv2.circle(draw2, (150, 150), 70, (100, 100, 200), -1, cv2.LINE_AA)
cv2.circle(draw2, (200, 200), 50, (0, 0, 200), 5, cv2.LINE_AA)
cv2.imshow("draw2", draw2)
cv2.waitKey(0)
效果如下,其中一个对边缘使用了抗锯齿,一个没有使用,可以看出还是有差别的。
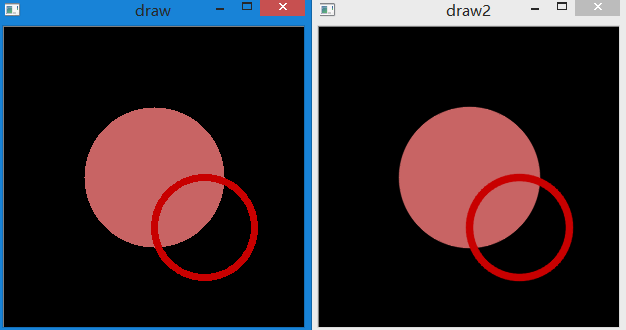
文字
对于绘制文字,一般需要设置以下参数:文字内容、位置、字体、大小、颜色等等。
cv2.putText(img, "test text", (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 1, cv2.LINE_AA)
效果如下:
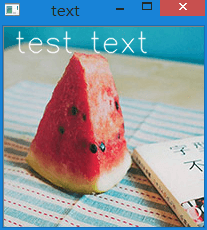
更多内容,如画多边形、椭圆等,因为暂时用不到,就不写了。也都十分简单。
像素操作小技巧
1.在读取图像时,返回的是Numpy的数组。而Numpy是经过优化的进行快速矩阵运算的软件包。
所以不推荐逐个获取像素并修改,这样可能会很慢,能用矩阵运算就不要用循环。
例如对图像的每个像素的像素值加1。可以直接用矩阵运算操作,而不需要再自己写循环遍历。
2.获取某个像素的值除了使用数组索引,如img[10,10,2]之外,还可以使用Numpy的item()
函数,img.item(10,10,2)。同理也可以使用itemset()函数修改,如将(10,10)像素的R通道
修改为100:img.itemset((10,10,2),100)。但要注意的是,item()返回的是标量,不能返回向量。
如img.item[10,10]并不会像img[10,10]一样返回由3个通道组成的向量,而是会报错。
图像ROI
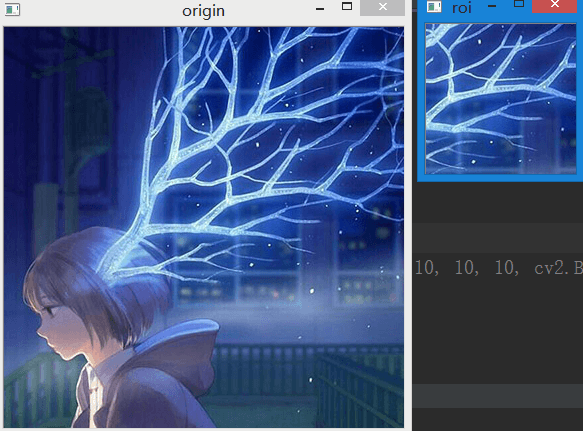
有时需要对一幅图像的特定区域进行操作,如检测一幅图像中眼睛的位置,我们首先应该在图像中 找到脸,然后再在脸的区域找眼睛。而不是直接在一幅图像中搜索。这样可以提高准确性和性能。 这一点很像截图功能,将图像的某一部分截取出来单独处理。 对于图像ROI也是通过Numpy索引来获得的。例如,将下面的图像中x坐标100-200、y坐标200-300的区域 提取出来。代码如下:
img = cv2.imread("E:\\400.jpg")
roi = img[100:250, 200:350]
cv2.imshow("origin", img)
cv2.imshow("roi", roi)
cv2.waitKey(0)
结果如下,将感兴趣的区域截取了出来:
图像扩边
在使用卷积核对图像进行卷积操作时,经常要涉及到图像边缘扩充的问题。在OpenCV中,已经预置好了相应的
函数cv2.copyMakeBorder(),我们可以直接调用。主要有三类参数,一类参数指定输入图像,一类参数指定
边界大小,一类参数指定边界类型。具体如下:
src:输入图像
top,bottom,left,right:图像上下左右的边界大小
borderType:
cv2.BORDER_CONSTANT:添加颜色为常数值的边界,还需要下一个颜色参数(value)。
cv2.BORDER_REFLECT:边界元素的镜像。
cv2.BORDER_REFLECT_101 or CV2.BORDER_DEFAULT:与上面的类似。
cv2.BORDER_REPLICATE:重复最后一个元素。
cv2.BORDER_WRAP:填充。
具体代码及演示效果如下所示:
result = np.zeros((680, 450, 3), np.uint8) + 255
img = cv2.imread("E:\\300.jpg")
img2 = cv2.copyMakeBorder(img, 10, 10, 10, 10, cv2.BORDER_REPLICATE)
cv2.rectangle(img2, (10, 10), (210, 210), (0, 0, 255), 1)
cv2.putText(img2, "REPLICATE", (20, 30), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA)
img3 = cv2.copyMakeBorder(img, 10, 10, 10, 10, cv2.BORDER_REFLECT)
cv2.rectangle(img3, (10, 10), (210, 210), (0, 0, 255), 1)
cv2.putText(img3, "REFLECT", (20, 30), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA)
img4 = cv2.copyMakeBorder(img, 10, 10, 10, 10, cv2.BORDER_REFLECT_101)
cv2.rectangle(img4, (10, 10), (210, 210), (0, 0, 255), 1)
cv2.putText(img4, "REFLECT_101", (20, 30), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA)
img5 = cv2.copyMakeBorder(img, 10, 10, 10, 10, cv2.BORDER_WRAP)
cv2.rectangle(img5, (10, 10), (210, 210), (0, 0, 255), 1)
cv2.putText(img5, "WRAP", (20, 30), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA)
img6 = cv2.copyMakeBorder(img, 10, 10, 10, 10, cv2.BORDER_CONSTANT, value=[255, 0, 0])
cv2.rectangle(img6, (10, 10), (210, 210), (0, 0, 255), 1)
cv2.putText(img6, "CONSTANT", (20, 30), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA)
cv2.putText(img, "original", (10, 20), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA)
result[0:220, 0:220] = img2
result[0:220, 230:450] = img3
result[230:450, 0:220] = img4
result[230:450, 230:450] = img5
result[460:680, 0:220] = img6
result[470:670, 240:440] = img
cv2.imshow("result", result)
cv2.waitKey(0)
在这段代码中,利用前面所说的拼接图片以及绘制文字的相关知识点,将多个结果融合到了一张图片中。红色框框表示
原始影像的边界,白色文字表示该图片所使用的扩边模式。如下图:

图像算数运算
图像加法
我们可以使用cv2.add()对两幅图像进行加法运算,当然也可以直接使用Numpy,从矩阵的角度直接进行,如res = img1 + img。
相加的两幅图像大小、类型必须一致。但需要注意的是OpenCV中的加法和Numpy中的加法是有所不同的。如下面的例子:
x = np.uint8([250])
y = np.uint8([10])
print cv2.add(x, y)
print x + y
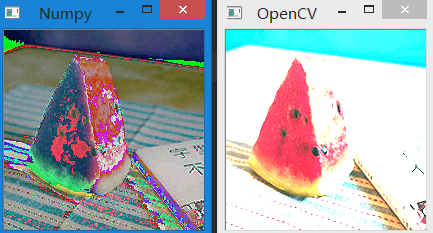
OpenCV输出的结果是255,但Numpy输出的结果是4。OpenCV的加法是一种饱和操作,Numpy的加法是一种模操作。显然,在图像处理 中,OpenCV的结果更加接近于我们的期望。所以我们尽量使用OpenCV的加法。下面的例子更加直观,我们对两幅图像进行加法:
img = cv2.imread("E:\\300.jpg")
img2 = cv2.imread("E:\\3002.jpg")
img3 = cv2.add(img, img2)
img4 = img + img2
cv2.imshow("OpenCV", img3)
cv2.imshow("Numpy", img4)
cv2.waitKey(0)
结果如下:
更多图像代数运算函数如下表:

图像混合
通过cv2.addWeighted()函数可实现两幅图像以不同的权重混合。其对应的混合公式如下:
alpha、beta分别是img1、img2的混合系数,gamma个偏移量,在这里为0。
img1 = cv2.imread("E:\\img1.jpg")
img2 = cv2.imread("E:\\img2.jpg")
img3 = cv2.addWeighted(img1, 0.7, img2, 0.3, 0)
mix = np.zeros((200, 630, 3), np.uint8) + 255
mix[0:200, 0:200] = img1
mix[0:200, 215:415] = img2
mix[0:200, 430:630] = img3
cv2.putText(mix, "img1(0.7)", (10, 20), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA)
cv2.putText(mix, "img2(0.3)", (220, 20), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA)
cv2.putText(mix, "mix", (450, 20), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA)
cv2.imshow("mix", mix)
cv2.waitKey(0)
效果如下所示,为了对比,同样对图片进行了拼接:

位运算
包括AND、OR、NOT、XOR等。当我们提取图像的一部分,选择非矩形ROI时这些操作会很有用。例如,有一个背景透明的 logo,要将其放到另一张图片上。如果采用加法,则颜色会改变;如果使用混合,会得到透明效果,因为权重之和是1。 如果我们想要完全不透明的logo,则背景的权重只能为0了。而且图片混合要求图片的大小是相同的。因此图片混合也 满足不了我们的需求。我们可以按照如下代码进行:
img1 = cv2.imread("E:\\img1.jpg")
img2 = cv2.imread("E:\\banner.png")
# 新建一个图片用于显示各步结果
show = np.zeros((620, 415, 3), np.uint8) + 240
font = cv2.FONT_HERSHEY_PLAIN
# 将读取的图像复制到画布上,并添加文字
show[:200, :200] = img1
show[80:120, 215:415] = img2
cv2.putText(show, "img1", (80, 210), font, 1, (0, 0, 0), 1, cv2.LINE_AA)
cv2.putText(show, "logo", (300, 210), font, 1, (0, 0, 0), 1, cv2.LINE_AA)
# 首先获取logo图像的宽高
rows, cols, channels = img2.shape
# 然后取出背景图中对应大小的待融合的影像
# 需要保证取出的ROI的大小与logo大小相同
# 可以通过索引来控制ROI的位置
roi = img1[:rows, :cols]
show[220:260, :200] = roi
cv2.putText(show, "ROI", (80, 275), font, 1, (0, 0, 0), 1, cv2.LINE_AA)
# 将logo图像灰度化
img2gray = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 需要注意的是灰度化后的图像只有一个通道了,
# 因此需要手工将灰度图像变成RGB三个通道相等的图像
show[220:260, 215:415, 0] = img2gray
show[220:260, 215:415, 1] = img2gray
show[220:260, 215:415, 2] = img2gray
cv2.putText(show, "GRAY", (300, 275), font, 1, (0, 0, 0), 1, cv2.LINE_AA)
# 对灰度化的logo图像进行二值化操作
# 第一个参数是待二值化的图像
# 第二个参数是二值化阈值
# 第三个参数是对应的灰度最大值
# 第四个参数是二值化类型
# 第一个返回值是我们设定的阈值,第二个是二值化后的图像
ret, mask = cv2.threshold(img2gray, 125, 255, cv2.THRESH_BINARY)
show[280:320, :200, 0] = mask
show[280:320, :200, 1] = mask
show[280:320, :200, 2] = mask
cv2.putText(show, "mask", (80, 335), font, 1, (0, 0, 0), 1, cv2.LINE_AA)
# 通过非运算,创建一个相反的mask
mask_inv = cv2.bitwise_not(mask)
show[280:320, 215:415, 0] = mask_inv
show[280:320, 215:415, 1] = mask_inv
show[280:320, 215:415, 2] = mask_inv
cv2.putText(show, "mask_inv", (290, 335), font, 1, (0, 0, 0), 1, cv2.LINE_AA)
# 对ROI区域进行与运算,同时与mask_inv进行掩膜操作,
# 也即掩膜中黑色(0)的部分不会显示,白色(1)的部分显示。
# 由于是ROI和ROI本身做与运算,所以结果还是它本身
# 这样便得到了ROI区域的背景
img1_bg = cv2.bitwise_and(roi, roi, mask=mask_inv)
show[340:380, :200] = img1_bg
cv2.putText(show, "background", (60, 395), font, 1, (0, 0, 0), 1, cv2.LINE_AA)
# 同理对logo进行与运算,结果还是本身。
# 但使用的掩膜是mask,所以不是白色(1)的部分不会显示。
img2_fg = cv2.bitwise_and(img2, img2, mask=mask)
show[340:380, 215:415] = img2_fg
cv2.putText(show, "foreground", (280, 395), font, 1, (0, 0, 0), 1, cv2.LINE_AA)
# 在背景和前景运算完成后,将两幅影像通过加法运算加起来,
# 得到ROI区域的最终合成影像dst
dst = cv2.add(img1_bg, img2_fg)
show[480:520, :200] = dst
cv2.putText(show, "dst", (60, 615), font, 1, (0, 0, 0), 1, cv2.LINE_AA)
# 把dst重新赋给原始影像中的对应部分,进行替换,完成操作
img1[:rows, :cols] = dst
show[400:600, 215:415] = img1
cv2.putText(show, "final", (300, 615), font, 1, (0, 0, 0), 1, cv2.LINE_AA)
cv2.imshow("show", show)
cv2.waitKey(0)
运行结果如下所示:
 logo背景是透明的,但读取显示是黑色的。在二值化以后则确实变为黑色了。所以logo原图和二值化以后的背景虽然看起来都是
黑色,但是二者是不同的。
在这里用到了灰度转换、图像复制等前面说过的知识。也用到了
logo背景是透明的,但读取显示是黑色的。在二值化以后则确实变为黑色了。所以logo原图和二值化以后的背景虽然看起来都是
黑色,但是二者是不同的。
在这里用到了灰度转换、图像复制等前面说过的知识。也用到了cv2.bitwise_and()、cv2.threshold()等函数。
本次笔记就结束了。主要介绍了OpenCV绘图操作、图像运算等操作,是后续处理的基础。
本文作者原创,未经许可不得转载,谢谢配合
