在之前已经搭建好了TensorFlow的运行环境。忽然觉得用pip安装确实是很方便。 不由地想说“你和深度学习只有一个pip的距离”。本篇博客开始进行TensorFlow的学习。 TensorFlow的中文官方社区是这里,由于英文原版官网打不开,因此这里有很多可以学习的知识。
一、基本概念
Tensor翻译成中文就是“张量”,Flow为“流”。TensorFlow就是“张量流”。 什么是张量,什么又是张量流。这里简单介绍一下。
1.张量
张量简单来说是一个“容器”,可以想象是一个数字的水桶。在深度学习中,张量一般在0-5维之间。
(1)0维张量
0维张量=标量。装在张量中的每个数字成为“标量”。标量是一个数字。为什么不干脆叫它们一个数字呢? 也许数学家只是喜欢听起来酷?标量听起来确实比数字酷。
(2)1维张量
1维张量=向量。对于编程而言,可以理解为使一个一维数组,在深度学习中成为一维张量。
张量是根据一共有多少坐标轴来定义的。一维张量只有一个坐标轴。同理对于一个标量(数字)而言,没有坐标轴可言,所以就是0维张量。
可以使用Numpy查看张量的维数。x.ndim即可,x为要查看维数的张量。
(3)2维张量
2维张量=矩阵。有行、列两个方向,即两个坐标轴。 张量具有“形状”,它的形状是一个水桶,既装着我们的数据也定义了张量的最大尺寸。 例如我们可以把100个学生的语数外成绩放进二维张量中,它是(100,3)。
(4)3维张量
3维张量=3维矩阵。其有三个坐标轴,如x、y、z,可以理解为是2维平面在z方向上的累计。
我们经常需要把一系列的二维张量存储在水桶中,这就形成了3维张量。
这也很容易理解。如一幅图像具有RGB三个通道,每个通道是一个二维矩阵,存放灰度信息。
那么通过OpenCV读取的影像,即是一个三维张量(三维矩阵)。可以用x.shape查看矩阵的大小。
(5)4维张量
4维张量其实可以看作是3维张量的累计。简单的例子是,有100张500×300尺寸相同,内容不同的RGB彩色图片。 我们可以用4维张量这样表示:(100,500,300,3)。第一维表示图片数量,第二、三维表示图片长宽、第四维表示RGB通道。 通过这样一个四维向量,我们就可以很方便地、唯一地找到我们想要的东西了。 如寻找第60张图片的G通道,可以表示为(100,500,300,2)。
(6)5维张量
5维张量可以用来存储视频数据。TensorFlow中,视频数据将如此编码:
(sample_size, frames, width, height, color_depth)
如果我们考察一段5分钟(300秒),1080pHD(1920 x 1080像素),每秒15帧(总共4500帧),颜色深度为3的视频。 我们可以用4D张量来存储它:
(4500,1920,1080,3)
当我们有多段视频的时候,张量中的第五个维度将被使用。如果我们有10段这样的视频,我们将得到一个5D张量:
(10,4500,1920,1080,3)
仔细思考就会发现,其实这么大的张量有巨大的数据量。
10×4500×1920×1080×3 = 279,936,000,000
我们5D张量中的每一个值都将用32 bit来存储,现在,我们以TB为单位来进行转换:
279,936,000,000×32 = 8,957,952,000,000
这还只是保守估计,或许用32bit来储存根本就不够。这个例子说明,你不能什么工作也不做就把大堆数据扔向你的AI模型。 你必须清洗和缩减那些数据让后续工作更简洁更高效。 降低分辨率,去掉不必要的数据(也就是去重处理),这大大缩减了帧数,等等这也是数据科学家的工作。 如果你不能很好地对数据做这些预处理,那么你几乎做不了任何有意义的事。
2.流
而之所以叫做“流”,是因为TensorFlow采用了数据流图(data flow graphs)用于数值计算。
节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。
在TensorFlow中进行运算的步骤是定义图,然后启动会话运行图。
数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。
“节点” 一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,
或者是读取/写入持久变量(persistent variable)的终点。
“线”表示“节点”之间的输入/输出关系。
这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。
张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。
这些张量可以是一个数字(标量),也可能是一张图片,或者一个视频。
图可以简单理解为对张量的一系列有序操作的集合。
这些数据在图中进行各种操作,“流过”数据图,最终得到结果。
一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
下面这张动图是TensorFlow演示的数据流图。
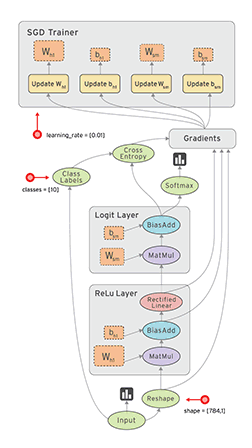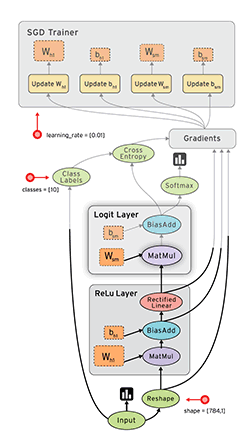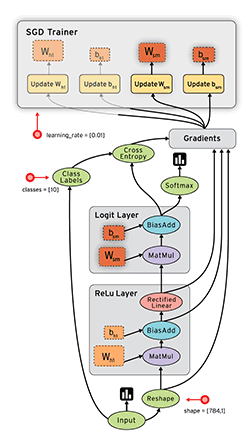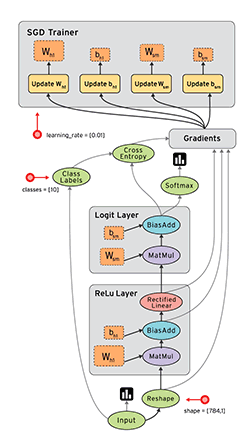
二、编程基础
在TensorFlow中使用图(Graph)来表示计算任务,在被称之为会话(Session)的上下文(Context)中执行图。 使用张量(Tensor)表示数据,通过变量(Variable)维护状态。 最后使用feed和fetch可以为任意的操作(Arbitrary Operation)赋值或从中获取数据。
TensorFlow是一个编程系统,使用图来表示计算任务。 图中的节点被称之为op(operation的缩写)。一个op获得0个或多个Tensor执行计算,产生0个或多个Tensor。 每个Tensor是一个类型化的多维数组。例如,你可以将一小组图像集表示为一个四维浮点数数组,这四个维度分别是[batch, height, width, channels]。 一个TensorFlow图描述了计算的过程。为了进行计算,图必须在会话里被启动。会话将图的op分发到诸如CPU或GPU之类的设备上,同时提供执行op的方法这些方法执行后,将产生的tensor返回。 在Python语言中,返回的tensor是numpy ndarray对象;在C和C++语言中,返回的tensor是tensorflow::Tensor实例。
1.计算图
TensorFlow程序通常被组织成一个构建阶段和一个执行阶段。在构建阶段,op的执行步骤被描述成一个图。 在执行阶段,使用会话执行执行图中的op。
(1)构建图
TensorFlow Python库有一个默认图(default graph),op构造器可以为其增加节点。这个默认图对许多程序来说已经足够用了。 例如我们有两个矩阵,进行矩阵乘法。可以这样写:
import tensorflow as tf
# 创建一个常量 op, 产生一个 1x2 矩阵. 这个 op 被作为一个节点
# 构造器的返回值代表该常量 op 的返回值
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量 op, 产生一个 2x1 矩阵
matrix2 = tf.constant([[2.], [2.]])
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入
# 返回值 'product' 代表矩阵乘法的结果
product = tf.matmul(matrix1, matrix2)
默认图现在有三个节点,两个constant() op,和一个matmul() op。 为了真正进行矩阵相乘运算,并得到矩阵乘法的结果,必须在会话里启动这个图。
(2)启动图
构造阶段完成后,才能启动图。启动图的第一步是创建一个Session对象。如果无任何创建参数,会话构造器将启动默认图。
# 启动默认图.
sess = tf.Session()
# 调用 sess 的 'run()' 方法来执行矩阵乘法 op, 传入 'product' 作为该方法的参数
# 上面提到, 'product' 代表了矩阵乘法 op 的输出, 传入它是向方法表明, 我们希望取回
# 矩阵乘法 op 的输出
# 整个执行过程是自动化的, 会话负责传递 op 所需的全部输入. op 通常是并发执行的
# 函数调用 'run(product)' 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op) 的执行
# 返回值 'result' 是一个 numpy `ndarray` 对象
result = sess.run(product)
print(result)
# 任务完成, 关闭会话
sess.close()
x,y,z分别是三个tensor对象,对象间的运算称之为操作(op), tf不会去一条条地执行各个操作,而是把所有的操作都放入到一个图(graph)中,图中的每一个结点就是一个操作。然后行将整个graph 的计算过程交给一个 TensorFlow 的Session, 此 Session 可以运行整个计算过程,比起操作(operations)一条一条的执行效率高的多。
Session对象在使用完后需要关闭以释放资源。除了显式调用close外,也可以使用Python自带的”with”代码块来自动完成关闭动作。
with tf.Session() as sess:
result = sess.run(product)
print(result)
2.Tensor
TensorFlow程序使用tensor数据结构来代表所有的数据。 计算图中,操作间传递的数据都是tensor。你可以把TensorFlow tensor看作是一个n维的数组或列表。 一个tensor包含一个静态类型rank,和一个shape。例如一个1×2的常量矩阵和一个字符串变量,输出结果如下:
Tensor("Const:0", shape=(1, 2), dtype=float32)
<tf.Variable 'Variable:0' shape=() dtype=string_ref>
3.常量
TensorFlow中常量定义如下:
const = tf.constant(10.5)
又如下面这段字符串常量”Hello world!”的代码。
import tensorflow as tf
str = tf.constant("Hello world!")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(str))
输出结果即为”Hello World!”。
4.变量
变量使用Variable()函数定义,并且必须初始化变量。定义数值类型的变量时,若没有指定数据类型,则默认为float32。
var = tf.Variable(tf.ones([3, 3]))
在变量定义完成后,还必须显式执行初始化操作,即需要在后面加上一句:
init=tf.global_variables_initializer()
而对于常量,定义完成后直接就可以使用了,不需要初始化。例如上面的例子中,并没有初始化。 因此需要记住变量需要初始化,常量不用初始化。 下面的代码定义了一个拉普拉斯卷积核:
import tensorflow as tf
import numpy as np
# 首先使用Numpy数组构建卷积核
x = np.array([[1, 1, 1], [1, -8, 1], [1, 1, 1]])
# 将构建好的卷积核作为初始值赋给TF变量w
w = tf.Variable(initial_value=x)
# 开启会话,运行图
with tf.Session() as sess:
# 在会话中初始化变量
sess.run(tf.global_variables_initializer())
# 运行w操作
result = sess.run(w)
# 打印结果
print(result)
输出结果如下:
[[ 1 1 1]
[ 1 -8 1]
[ 1 1 1]]
Process finished with exit code 0
6.占位符
变量在定义时要初始化,但是如果有些变量刚开始我们并不知道它们的值,无法初始化。需要使用占位符来占个位置,如:
x = tf.placeholder(tf.float32, [None, 10])
第一个参数是数据类型,第二个参数表示变量的shape。其中None表示未知。定义的这个变量以后可以用feed来赋值。
7.Fetch
为了取回操作的输出内容,可以在使用Session对象的run()调用执行图时,传入一些tensor。 这些tensor会帮助你取回结果。 例如某个计算式为a=2+3,b=5×a。根据上面所学的知识,代码应该如下:
import tensorflow as tf
p1 = tf.constant(2.0)
p2 = tf.constant(3.0)
a = tf.add(p1, p2)
# 注意这里如果写成5会报错
# TypeError: Input 'y' of 'Mul' Op has type float32 that does not match type int32 of argument 'x'.
b = tf.multiply(5.0, a)
with tf.Session() as sess:
result = sess.run(b)
print(result)
这样可以顺利得到计算结果为25。但问题是如果还想获得a的值,就可以给run()函数传入多个参数,代码如下:
import tensorflow as tf
p1 = tf.constant(2.0)
p2 = tf.constant(3.0)
a = tf.add(p1, p2)
b = tf.multiply(5.0, a)
with tf.Session() as sess:
result = sess.run([a, b])
print(result)
这样输出结果是5.0和25.0。
8.Feed
上述示例在计算图中引入了tensor,以常量或变量的形式存储。
TensorFlow还提供了feed机制,该机制可以临时替代图中的任意操作中的tensor。
可以对图中任何操作提交补丁,直接插入一个 tensor。
feed使用一个tensor值临时替换一个操作的输出结果。你可以提供feed数据作为run()调用的参数。
feed只在调用它的方法内有效,方法结束,feed就会消失。
最常见的用例是将某些特殊的操作指定为”feed”操作,标记的方法是使用tf.placeholder()为这些操作创建占位符。
import tensorflow as tf
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.multiply(input1, input2)
with tf.Session() as sess:
print(sess.run([output], feed_dict={input1: [7.5], input2: [2.3]}))
本篇博客主要介绍了TensorFlow的相关概念和编程基础,下一篇博客学习机器学习的经典MNIST问题。
本文作者原创,未经许可不得转载,谢谢配合
