今天又突然接到个比较繁琐的任务。有一堆word文档(好几百个),内容都是一样的表格,但由于一些原因,需要把表格中的某些单元格内容进行修改和删除。又是这种“没有技术含量”的大量重复的工作,于是第一反应就想到了用Python。600多个文档就算找别人帮忙,每个人都要分快一百个,太浪费时间。
1.实现思路分析
利用Python实现简单来说就是读取表格内容,然后将指定的单元格内容置空即可。Python读取docx文件内容可以使用python-docx这个库。修改完之后,再将内容保存成新的文件即可。python-docx的安装十分简单,直接pip install python-docx即可。它的PYPI主页是这里,说明文档是这里,里面有简单的使用说明,可以参考。
这里还有另外一个问题,那就是我拿到的word文档都是doc格式的,而这个库似乎只能读取docx文件,读取不了doc文件。因此要想使用这个库进行批量处理,第一步就是先将这些文件批量转成docx格式。在网上找了相关资料也比较多,例如这个网页。简单来说基本都是通过win32com这个库实现和Word的交互。但因为转换并不是这篇博客的主题,这里就不多介绍了。这里直接使用了别人写好的一个程序实现批量转换,程序的下载地址在上面这个网页上有。作者给出的百度云链接:https://pan.baidu.com/s/1fOfFpIU4rKnAYCBdNCa1tg 密码:pmlu。当然如果有兴趣,可以去作者的博客,网页是这里,介绍了程序实现的原理和代码。下面使用的所有数据都是经过上面转换后的docx文件,如果你的文件本身就是docx就不需要这一步了。
2.脚本设计
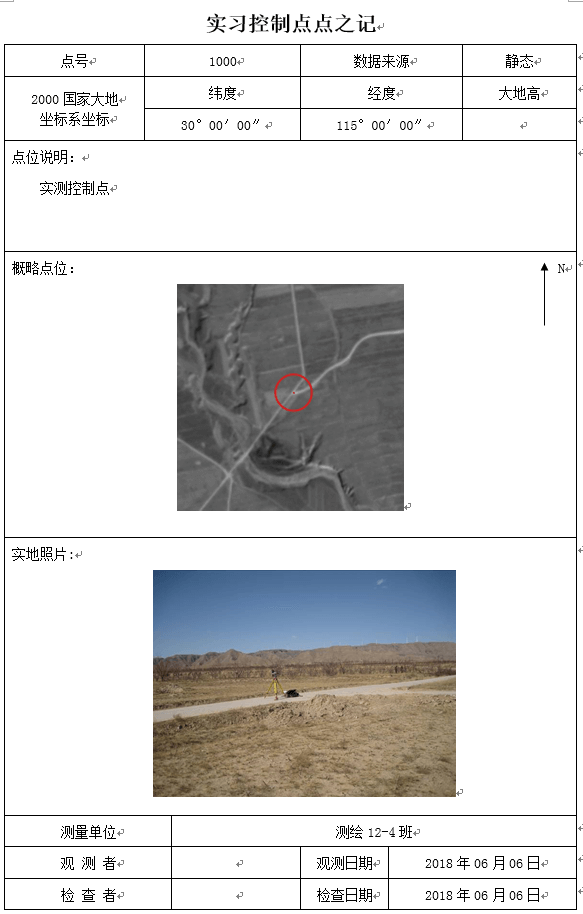
首先,需要处理的word文件截图如下。是实习中使用的控制点的点之记。
 在给别人的时候需要做如下修改。首先是将点的经度、纬度精度降低,只保留到整数秒,同时删去高程、观测者和检查者信息,最后重新保存成一个word文件,如下。
在给别人的时候需要做如下修改。首先是将点的经度、纬度精度降低,只保留到整数秒,同时删去高程、观测者和检查者信息,最后重新保存成一个word文件,如下。
 对于需要修改的经纬度,考虑采用字符串截取的办法,保留一定长度的字符串,对于需要删除的单元格,直接将其值赋为空。在编写正式代码之前,我们应该读取一下文档内容,看看我们需要处理的单元格的位置,然后将这些位置记下来,在处理程序中做进一步处理。下面是利用代码读取每个单元格内容并输出其位置的代码。
对于需要修改的经纬度,考虑采用字符串截取的办法,保留一定长度的字符串,对于需要删除的单元格,直接将其值赋为空。在编写正式代码之前,我们应该读取一下文档内容,看看我们需要处理的单元格的位置,然后将这些位置记下来,在处理程序中做进一步处理。下面是利用代码读取每个单元格内容并输出其位置的代码。
# coding=utf-8
from docx import Document
import sys
# 手动设置字符编码,防止文件内容包含中文而导致出错
reload(sys)
sys.setdefaultencoding('utf8')
file_path = "C:\\Users\\obtdata005\\Desktop\\1000.docx"
doc = Document(file_path)
# 遍历所有表格,由于我们这里只有一个表,所以这个循环只执行一次
for table in doc.tables:
# table.rows包含了table中所有的行
for i in range(table.rows.__len__()):
# table.rows[i].cells表示第i行中所有的单元格
for j in range(table.rows[i].cells.__len__()):
print(i, j)
# 单元格有text属性
print(table.rows[i].cells[j].text)
注意这里设置字符编码的代码不能省略,否则在含有中文的时候会报错。更多内容可以参考API文档。运行代码后,输出如下结果。

 我们只需要按照要求,修改或删除这些位置的内容就可以了。至于说为什么会出现很多重复的情况暂时还不清楚。不过没有关系,不影响使用,如(2,1)和(2,2)位置上都是纬度信息,在处理的时候就把两个单元格同时处理即可。
我们只需要按照要求,修改或删除这些位置的内容就可以了。至于说为什么会出现很多重复的情况暂时还不清楚。不过没有关系,不影响使用,如(2,1)和(2,2)位置上都是纬度信息,在处理的时候就把两个单元格同时处理即可。
2.实现代码
代码并不复杂,直接上代码。
# coding=utf-8
from docx import Document
import sys
import os
import time
reload(sys)
sys.setdefaultencoding('utf8')
def modifyDocx(file_path, out_path):
doc = Document(file_path)
# 遍历所有表格
for table in doc.tables:
for i in range(table.rows.__len__()):
for j in range(table.rows[i].cells.__len__()):
# 纬度,截取到整数秒
if i == 2 and j == 1:
table.rows[i].cells[j].text = table.rows[i].cells[j].text[:8] + "\""
if i == 2 and j == 2:
table.rows[i].cells[j].text = table.rows[i].cells[j].text[:8] + "\""
# 经度,截取到整数秒
if i == 2 and j == 3:
table.rows[i].cells[j].text = table.rows[i].cells[j].text[:9] + "\""
if i == 2 and j == 4:
table.rows[i].cells[j].text = table.rows[i].cells[j].text[:9] + "\""
# 高程信息,删去
if i == 2 and j == 5:
table.rows[i].cells[j].text = ''
# 观测、检查人员信息,删去
if i == 7 and j == 2:
table.rows[i].cells[j].text = ''
if i == 8 and j == 2:
table.rows[i].cells[j].text = ''
doc.save(out_path)
def findAllFiles(root_dir, filter):
print("Finding files ends with \'" + filter + "\' ...")
separator = os.path.sep
paths = []
names = []
# 遍历
for parent, dirname, filenames in os.walk(root_dir):
for filename in filenames:
if filename.endswith(filter):
paths.append(parent + separator)
names.append(filename)
for i in range(paths.__len__()):
print(paths[i] + names[i])
print (names.__len__().__str__() + " files have been found.")
paths.sort()
names.sort()
return paths, names
root_dir = "C:\\Users\\obtdata005\\Desktop\\out_file"
filter = ".docx"
out_path = "C:\\Users\\obtdata005\\Desktop\\out_file2"
# 遍历寻找word文件,构建docx文件全路径
paths, names = findAllFiles(root_dir, filter)
input_filenames = []
for i in range(names.__len__()):
input_filenames.append(paths[i] + names[i])
# 创建输出文件的输出路径和文件名
output_filenames = []
for i in range(names.__len__()):
output_filenames.append(out_path + "\\" + names[i])
# 调用函数批量修改表格内容
t1 = time.time()
for i in range(input_filenames.__len__()):
print("converted " + (i + 1).__str__() + "/" + input_filenames.__len__().__str__())
modifyDocx(input_filenames[i], output_filenames[i])
t2 = time.time()
dt = t2 - t1
print("cost " + dt.__str__() + " s")
控制台中运行结果如下。
 可以看到,一共耗时58s。如果要是人工一个个去改,就算修改一个文件需要20s,那620个文件一共需要12400s,也就是3.44个小时,这还是在不休息的情况下。利用脚本效率提升了213倍。随便打开一个处理完成后的文件如下。圆满的完成了任务。
可以看到,一共耗时58s。如果要是人工一个个去改,就算修改一个文件需要20s,那620个文件一共需要12400s,也就是3.44个小时,这还是在不休息的情况下。利用脚本效率提升了213倍。随便打开一个处理完成后的文件如下。圆满的完成了任务。
 最后,附上两个未处理前的文件以供测试。链接:https://pan.baidu.com/s/1_cTGmerjsdLfrhjpXVZnAA 密码:ag36
最后,附上两个未处理前的文件以供测试。链接:https://pan.baidu.com/s/1_cTGmerjsdLfrhjpXVZnAA 密码:ag36
本文作者原创,未经许可不得转载,谢谢配合
