这篇博客的内容其实很早以前就想写了,因为之前在写数据密集型程序的时候时常感叹要是能用多线程优化就好了,会让运算快很多。但一直没有较为全面和完整的学习Python并行加速编程的相关内容。昨天花了点时间研究了Python的并行编程,并自己写了个实例。下面就进行介绍。
1.Python之痛
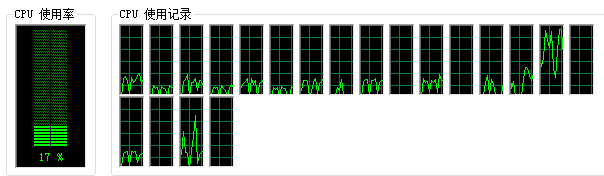
众所周知,Python作为一种解释型编程语言,其运行效率就注定了无法和编译型语言如C/C++等相提并论。然而抛开这个天然劣势不谈,如果Python能很好的使用多线程等技术进行并行编程,至少可以稍微挽回点局面(一般而言一个多线程Python程序总比单线程C程序快了吧…)。事实上,由于在Python中有大名鼎鼎的GIL锁存在,使得Python使用多线程又多了个障碍。GIL全称是Global Interpreter Lock,中文是全局解释锁。简而言之就是一个Python程序中只能同时有一个线程在运行,即使有所谓的多线程,其实不过是在多个线程间来回切换,本质上同一时刻还是只运行了一个线程。如果你用Python跑过计算密集型程序,一定会发现CPU使用率永远都很低。如果电脑有4核,CPU使用率最多只能到25%,其它核为0%,一核有难,三核围观。如下所示,共有20核,而CPU利用率最高只有20%不到。只有某几核使用率较高,其余几乎处于闲置状态,十分浪费计算资源。
 那么Python的效率真的就有这么不堪吗?和C/C++相比到底如何?和别人交流的时候很多人问过我这个问题。我的回答首先是肯定的,即Python效率肯定比C/C++差。然后我会补充一句,但要看差的这点效率你是否能接受。例如一个程序C/C++运行需要0.1秒,Python运行需要0.5秒。那么你是否能够接受这0.4秒的时间。如果你觉得这0.4秒无所谓,那么在这个应用中Python和C/C++在效率上对你而言是一样的,但由于Python代码读写更为简单,所以自然优先选择Python。而如果说这0.4秒对你来说是无法接受的,你有10000个数据,每次运行都多出0.4秒,那么就是4000秒,也就是66分钟。这时虽然Python代码读写简单,但考虑到效率和耗时问题,自然优先选择C/C++。
那么Python的效率真的就有这么不堪吗?和C/C++相比到底如何?和别人交流的时候很多人问过我这个问题。我的回答首先是肯定的,即Python效率肯定比C/C++差。然后我会补充一句,但要看差的这点效率你是否能接受。例如一个程序C/C++运行需要0.1秒,Python运行需要0.5秒。那么你是否能够接受这0.4秒的时间。如果你觉得这0.4秒无所谓,那么在这个应用中Python和C/C++在效率上对你而言是一样的,但由于Python代码读写更为简单,所以自然优先选择Python。而如果说这0.4秒对你来说是无法接受的,你有10000个数据,每次运行都多出0.4秒,那么就是4000秒,也就是66分钟。这时虽然Python代码读写简单,但考虑到效率和耗时问题,自然优先选择C/C++。
那么Python难道就真的没有办法加速优化吗?答案当然是否定的。虽然Python有GIL锁,但是这个锁是只针对一个Python进程的,换句话说,如果打开两个Python解释器同时运行同一个脚本,那不就等效于“双线程”了吗?事实上也确实如此。
在Python中有subprocess、signal、threading等包可以实现相关功能。我们这里使用的是一个叫multiprocessing的包,这个包就是专门用来解决这类问题的。其官方文档点此查看。在介绍下面的内容之前,简单说一下线程和进程的区别。简单解释就是一个进程可以理解为就是一个程序,一个进程中可以有多个线程,线程之间可以互相通信。线程是比进程低一级的单位。说多线程程序可能不太严谨,准确来说应该是多进程程序,或者说并行程序可能更加严谨。
2.Multiprocess包的使用
这里我并不打算一点点介绍如何使用它,而是通过一个我经常会遇到的需求为例,将单线程代码改成多线程的并进行比较。因为我是做图像处理这一块的,所以就以图像处理作为例子。我的需求就是影像间的配准与重采,这是一个典型的计算密集型程序。这里以视频的稳像为例,在这篇博客中已经介绍了相关知识,这里就不说了。下面直接上代码。
(1)单线程
首先是单线程版本的。
# coding: utf-8
import time
import os
import cv2
import numpy as np
def findAllFiles(root_dir, filter):
print("Finding files ends with \'" + filter + "\' ...")
separator = os.path.sep
paths = []
names = []
files = []
# 遍历
for parent, dirname, filenames in os.walk(root_dir):
for filename in filenames:
if filename.endswith(filter):
paths.append(parent + separator)
names.append(filename)
for i in range(paths.__len__()):
files.append(paths[i] + names[i])
print (names.__len__().__str__() + " files have been found.")
paths.sort()
names.sort()
files.sort()
return paths, names, files
def match_SURF(img_pair):
t1 = time.time()
img1 = img_pair[0]
img2 = img_pair[1]
# 新建SURF对象,参数默认
surf = cv2.xfeatures2d_SURF.create()
# 调用函数进行SURF提取
kp1, des1 = cv2.xfeatures2d_SURF.detectAndCompute(surf, img1, None)
kp2, des2 = cv2.xfeatures2d_SURF.detectAndCompute(surf, img2, None)
good_matches = []
good_kps1 = []
good_kps2 = []
good_out_kp1 = []
good_out_kp2 = []
# FLANN parameters
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
# 筛选
for i, (m, n) in enumerate(matches):
if m.distance < 0.5 * n.distance:
good_matches.append(matches[i])
good_kps1.append(kp1[matches[i][0].queryIdx])
good_kps2.append(kp2[matches[i][0].trainIdx])
# surf匹配出来的点对都是KeyPoint类型的对象,所以需要解析一下才可以使用
for i in range(good_kps1.__len__()):
good_out_kp1.append([good_kps1[i].pt[0], good_kps1[i].pt[1]])
good_out_kp2.append([good_kps2[i].pt[0], good_kps2[i].pt[1]])
affine, mask = cv2.estimateAffine2D(np.array(good_out_kp2), np.array(good_out_kp1))
img_resampled = cv2.warpAffine(img2, affine, (img1.shape[1], img1.shape[0]))
t2 = time.time()
print("kp1 size:" + kp1.__len__().__str__() + " kp2 size:" + kp2.__len__().__str__())
print(affine)
print("cost time:" + (t2 - t1).__str__())
return affine, img_resampled
if __name__ == '__main__':
res = []
resample_imgs = []
paths, names, files = findAllFiles("img", '.jpg')
# 注意不要在循环里载入影像,这样会开辟出许多重复的空间
# 先载入,然后添加则是浅拷贝,只相当于拷贝了内存的地址
base_img = cv2.imread(files[0])
for i in range(1, files.__len__()):
resample_imgs.append([base_img, cv2.imread(files[i])])
print(files[i] + " was loaded." + (i + 1).__str__() + "/" + files.__len__().__str__())
print("SingleProcess")
t1 = time.time()
for i in range(resample_imgs.__len__()):
print("\n")
result = match_SURF(resample_imgs[i])
res.append(result)
print("processing " + (i + 1).__str__() + "/" + resample_imgs.__len__().__str__())
t2 = time.time()
print("\nTotal time:" + (t2 - t1).__str__() + "\n")
# 保存重采后的影像
for i in range(res.__len__()):
cv2.imwrite("resampled/resampled_" + (i + 1).__str__().zfill(2) + ".jpg", res[i][1])
print("saved " + (i + 1).__str__() + "/" + res.__len__().__str__())
这里准备了50帧视频影像,程序会依次读取,然后与基准帧进行匹配与重采,并将结果保存为新的图片文件。未稳像视频与输出的结果如下动图所示。

 处理50帧影像在Intel Xeon E5-2630 v4 @ 2.20GHz的CPU、32GB内存的台式机上跑需要68.338秒。
处理50帧影像在Intel Xeon E5-2630 v4 @ 2.20GHz的CPU、32GB内存的台式机上跑需要68.338秒。
(2)多进程并行
在上述代码的基础上稍加改动,即可以实现并行加速的效果。代码如下。
# coding: utf-8
from multiprocessing import Pool
import time
import os
import cv2
import numpy as np
def findAllFiles(root_dir, filter):
print("Finding files ends with \'" + filter + "\' ...")
separator = os.path.sep
paths = []
names = []
files = []
# 遍历
for parent, dirname, filenames in os.walk(root_dir):
for filename in filenames:
if filename.endswith(filter):
paths.append(parent + separator)
names.append(filename)
for i in range(paths.__len__()):
files.append(paths[i] + names[i])
print (names.__len__().__str__() + " files have been found.")
paths.sort()
names.sort()
files.sort()
return paths, names, files
def match_SURF(img_pair):
t1 = time.time()
img1 = img_pair[0]
img2 = img_pair[1]
# 新建SURF对象,参数默认
surf = cv2.xfeatures2d_SURF.create()
# 调用函数进行SURF提取
kp1, des1 = cv2.xfeatures2d_SURF.detectAndCompute(surf, img1, None)
kp2, des2 = cv2.xfeatures2d_SURF.detectAndCompute(surf, img2, None)
good_matches = []
good_kps1 = []
good_kps2 = []
good_out_kp1 = []
good_out_kp2 = []
# FLANN parameters
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
# 筛选
for i, (m, n) in enumerate(matches):
if m.distance < 0.5 * n.distance:
good_matches.append(matches[i])
good_kps1.append(kp1[matches[i][0].queryIdx])
good_kps2.append(kp2[matches[i][0].trainIdx])
# surf匹配出来的点对都是KeyPoint类型的对象,所以需要解析一下才可以使用
for i in range(good_kps1.__len__()):
good_out_kp1.append([good_kps1[i].pt[0], good_kps1[i].pt[1]])
good_out_kp2.append([good_kps2[i].pt[0], good_kps2[i].pt[1]])
affine, mask = cv2.estimateAffine2D(np.array(good_out_kp2), np.array(good_out_kp1))
img_resampled = cv2.warpAffine(img2, affine, (img1.shape[1], img1.shape[0]))
t2 = time.time()
print("kp1 size:" + kp1.__len__().__str__() + " kp2 size:" + kp2.__len__().__str__())
print(affine)
print("cost time:" + (t2 - t1).__str__())
return affine, img_resampled
if __name__ == '__main__':
MultiNum = 6
res = []
resample_imgs = []
paths, names, files = findAllFiles("img", '.jpg')
# 注意不要在循环里载入影像,这样会开辟出许多重复的空间
# 先载入,然后添加则是浅拷贝,只相当于拷贝了内存的地址
base_img = cv2.imread(files[0])
for i in range(1, files.__len__()):
resample_imgs.append([base_img, cv2.imread(files[i])])
print(files[i] + " was loaded." + (i + 1).__str__() + "/" + files.__len__().__str__())
print("MultiProcess:" + MultiNum.__str__())
# 新建指定数量的进程池用于对多进程进行管理
pool = Pool(processes=MultiNum)
t1 = time.time()
# 注意map函数中传入的参数应该是可迭代对象,如list
res = pool.map(match_SURF, resample_imgs)
pool.close()
pool.join()
t2 = time.time()
print("Total time:" + (t2 - t1).__str__())
# 保存重采后的影像
for i in range(res.__len__()):
cv2.imwrite("resampled/resampled_" + (i + 1).__str__().zfill(2) + ".jpg", res[i][1])
print("saved " + (i + 1).__str__() + "/" + res.__len__().__str__())
相比于单线程版本,并行版本首先建立了一个进程池,然后调用map()函数“优雅”地实现了程序并行。其中map()函数中第一个参数是需要并行的函数名称,注意不用括号,第二个参数是传递给函数的参数,要求必须是可迭代对象,如list等。map()函数的返回值也是一个可迭代对象,如list。join()函数用于实现进程间的同步,等待所有进程退出。close()函数用来阻止多余的进程涌入进程池从而造成进程阻塞。
当然multiprocessing模块还有更多高级的功能,但这里从实用的角度而言,掌握这些基本就可以应付大部分实际需求了。同时在设计函数的时候需要注意传入对象和传出对象的类型。在map()函数里都是整体输入整体输出的,一个list输入,一个list输出。这点有点类似于TensorFlow中的map、reduce的感觉,都是操作一个盛放数据的容器,而不是容器中的具体数据。
在本段代码中使用了6个进程来进行运算。所以在任务管理器里就会发现有6个python.exe在同时运行,如下。
 同时再看性能检测,再也不是“一核有难,八方围观”了,CPU使用率最高可以到90%左右,基本都参与运算了。
同时再看性能检测,再也不是“一核有难,八方围观”了,CPU使用率最高可以到90%左右,基本都参与运算了。
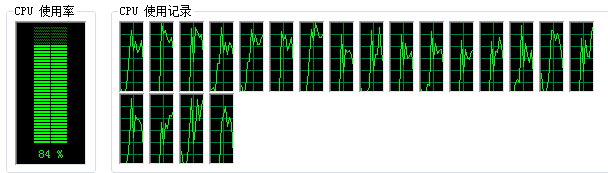 采用6个进程并行,耗时20.799秒,相比于单线程节省了一大半的时间。但这里要注意的是这个耗时的缩短并不是说完成单项任务的时间缩短了,而是同时有多个进程在工作了。举个例子,如有100个苹果需要清点(清点的人不知道个数)。如果一个人清点,效率是1秒钟一个,那么清点完所有苹果需要100秒。但这时又来了3个人,说我们帮你一起清点吧。那么总清点人数就变成了4个。虽然单人的清点效率还是一秒一个,但因为有4个人,所以总的效率就变成了4个每秒,总效率就提升了4倍。所以并行编程的道理是一样的,并不是说程序匹配一帧的速度变快了,而是同时有多个进程在进行匹配了。这个要注意理解。
采用6个进程并行,耗时20.799秒,相比于单线程节省了一大半的时间。但这里要注意的是这个耗时的缩短并不是说完成单项任务的时间缩短了,而是同时有多个进程在工作了。举个例子,如有100个苹果需要清点(清点的人不知道个数)。如果一个人清点,效率是1秒钟一个,那么清点完所有苹果需要100秒。但这时又来了3个人,说我们帮你一起清点吧。那么总清点人数就变成了4个。虽然单人的清点效率还是一秒一个,但因为有4个人,所以总的效率就变成了4个每秒,总效率就提升了4倍。所以并行编程的道理是一样的,并不是说程序匹配一帧的速度变快了,而是同时有多个进程在进行匹配了。这个要注意理解。
3.最优并行进程数
看了上面的代码肯定会有个小疑问,使用6个进程效果就这么明显了。那要是使用10个、15个,甚至20个会这么样呢?这就涉及到计算效率与并行核数之间的关系了。从大体上来说,多核计算效率肯定是要优于单核的。但事实上核数与效率之间是不是线性关系呢?通过下面的代码可以进行验证。
# coding: utf-8
from multiprocessing import cpu_count
from multiprocessing import Pool
import time
import os
import cv2
import numpy as np
def findAllFiles(root_dir, filter):
print("Finding files ends with \'" + filter + "\' ...")
separator = os.path.sep
paths = []
names = []
files = []
# 遍历
for parent, dirname, filenames in os.walk(root_dir):
for filename in filenames:
if filename.endswith(filter):
paths.append(parent + separator)
names.append(filename)
for i in range(paths.__len__()):
files.append(paths[i] + names[i])
print (names.__len__().__str__() + " files have been found.")
paths.sort()
names.sort()
files.sort()
return paths, names, files
def match_SURF(img_pair):
t1 = time.time()
img1 = img_pair[0]
img2 = img_pair[1]
# 新建SURF对象,参数默认
surf = cv2.xfeatures2d_SURF.create()
# 调用函数进行SURF提取
kp1, des1 = cv2.xfeatures2d_SURF.detectAndCompute(surf, img1, None)
kp2, des2 = cv2.xfeatures2d_SURF.detectAndCompute(surf, img2, None)
good_matches = []
good_kps1 = []
good_kps2 = []
good_out_kp1 = []
good_out_kp2 = []
# FLANN parameters
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
# 筛选
for i, (m, n) in enumerate(matches):
if m.distance < 0.5 * n.distance:
good_matches.append(matches[i])
good_kps1.append(kp1[matches[i][0].queryIdx])
good_kps2.append(kp2[matches[i][0].trainIdx])
# surf匹配出来的点对都是KeyPoint类型的对象,所以需要解析一下才可以使用
for i in range(good_kps1.__len__()):
good_out_kp1.append([good_kps1[i].pt[0], good_kps1[i].pt[1]])
good_out_kp2.append([good_kps2[i].pt[0], good_kps2[i].pt[1]])
affine, mask = cv2.estimateAffine2D(np.array(good_out_kp2), np.array(good_out_kp1))
img_resampled = cv2.warpAffine(img2, affine, (img1.shape[1], img1.shape[0]))
t2 = time.time()
print("kp1 size:" + kp1.__len__().__str__() + " kp2 size:" + kp2.__len__().__str__())
print(affine)
print("cost time:" + (t2 - t1).__str__())
return affine, img_resampled
if __name__ == '__main__':
# 用于设置测试起始于结束的进程个数,cpu_count()函数用于获取CPU的核心数
start_cpu_num = 1
end_cpu_num = cpu_count()
print("cpu num:" + cpu_count().__str__())
print("test range:" + start_cpu_num.__str__() + " - " + end_cpu_num.__str__() + "\n")
res = []
cost_time = []
resample_imgs = []
paths, names, files = findAllFiles("img", '.jpg')
base_img = cv2.imread(files[0])
for i in range(1, files.__len__()):
resample_imgs.append([base_img, cv2.imread(files[i])])
print(files[i] + " was loaded." + (i + 1).__str__() + "/" + files.__len__().__str__())
for MultiNum in range(start_cpu_num, end_cpu_num + 1):
print("\nMultiProcess:" + MultiNum.__str__())
pool = Pool(processes=MultiNum)
t1 = time.time()
res = pool.map(match_SURF, resample_imgs)
pool.close()
pool.join()
t2 = time.time()
cost_time.append((MultiNum, t2 - t1))
print("Total time:" + (t2 - t1).__str__())
for item in cost_time:
print(item[0].__str__() + "\t" + item[1].__str__())
上面的这段代码时专门为验证这个问题而写的。程序首先会获取本计算机的CPU核心数,然后默认进程数从1开始一直到最大,依次记录不同进程数与耗时的关系,最后可以得到如下数据。
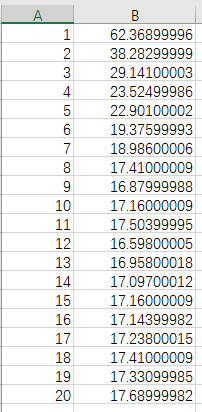 以时间为横轴,耗时为纵轴可以画出如下折线图。
以时间为横轴,耗时为纵轴可以画出如下折线图。
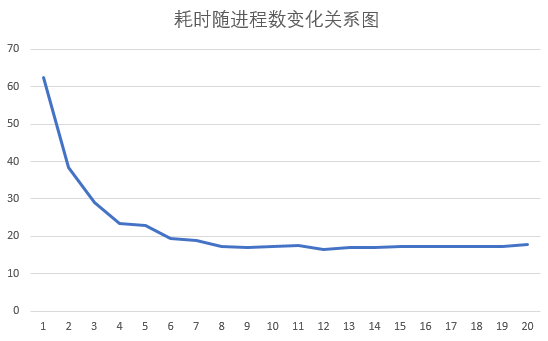 这便很明显地反应了进程数与效率之间的关系,随着进程数的增加,耗时急剧下降,但随着进程数的持续增加,效率的提升就不是这么明显了。甚至当进程数大于某一数值后,随着进程数的增加,耗时反而增加了。出现这种情况的原因在于,当进程数过多后,进程间通信将变得更加复杂,相比于进程数增加带来的效率提升,其增加带来的副作用(进程调度、通信等复杂操作)更大了,所以导致了效率的下降。
这便很明显地反应了进程数与效率之间的关系,随着进程数的增加,耗时急剧下降,但随着进程数的持续增加,效率的提升就不是这么明显了。甚至当进程数大于某一数值后,随着进程数的增加,耗时反而增加了。出现这种情况的原因在于,当进程数过多后,进程间通信将变得更加复杂,相比于进程数增加带来的效率提升,其增加带来的副作用(进程调度、通信等复杂操作)更大了,所以导致了效率的下降。
4.最优进程数自动选择
在上面介绍了进程数与效率之间的关系后,我们可以得到一个结论,进程数和效率之间并不是简单的线性关系,进程数也并不是越多越好。因此选择一个合理、最优的进程数就显得尤为重要。进程数选少了会导致计算资源的浪费,无法充分利用计算能力。进程数选多了,又会因为进程间的复杂调度、通信带来效率的降低。因此最优进程数是一个关键问题。下面的代码简单实现了最优进程数的选择。
# coding=utf-8
from multiprocessing import cpu_count
from multiprocessing import Pool
import time
import numpy as np
def processImg(img):
# 利用Numpy矩阵操作对图像进行简单的二值化处理
np.uint8(np.where(img < 128, 0, 255))
def takeTime(item):
# 用于返回列表中指定位置的元素
return item[1]
def selectCPUNum(imgNum=100, imgW=800, imgH=800):
start_cpu_num = 1
end_cpu_num = cpu_count()
print("cpu num:" + cpu_count().__str__())
print("test range:" + start_cpu_num.__str__() + " - " + end_cpu_num.__str__() + "\n")
# 利用Numpy生成imgNum张imgW*imgH的随机矩阵作为图像用于测试
imgs = []
for i in range(imgNum):
img = np.uint8(np.random.randint(0, 255, size=(imgW, imgH)))
imgs.append(img)
cost_time = []
for MultiNum in range(start_cpu_num, end_cpu_num + 1):
print("MultiProcess:" + MultiNum.__str__())
pool = Pool(processes=MultiNum)
t1 = time.time()
pool.map(processImg, imgs)
pool.close()
pool.join()
t2 = time.time()
cost_time.append((MultiNum, t2 - t1))
print("cost time:" + (t2 - t1).__str__())
cost_time.sort(key=takeTime)
print("\ntest result for num " + MultiNum.__str__() + ":")
for item in cost_time:
print(item)
ave_num = int((cost_time[0][0] + cost_time[1][0] + cost_time[2][0]) / 3)
print("\nrecommend cpu num:" + ave_num.__str__() + "\n")
return ave_num
def selectCPUNumRobust(runTime=4, imgNum=100, imgW=800, imgH=800):
nums = []
for i in range(runTime):
print("Run for " + (i + 1).__str__() + " time...")
nums.append(selectCPUNum(imgNum=imgNum, imgW=imgW, imgH=imgH))
final_num = sum(nums) / nums.__len__()
print("final recommend cpu num:" + final_num.__str__())
return final_num
if __name__ == '__main__':
selectCPUNumRobust()
上述代码首先利用Numpy生成了100张800*800的随机图像,然后采用不同进程数进行二值化操作,并记录不同进程数的完成时间。之后对耗时进行排名,取前三耗时短的进程数求平均值。这样便得到一个进程数的推荐值。将上述步骤重复4遍,最后再将这4遍的推荐值相加取平均,便得到最终的推荐值。
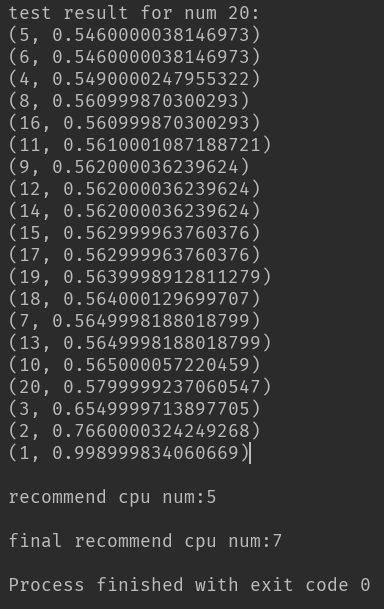 如上图所示,经过4次运算,在本机最终推荐的最佳进程数是7。即可以认为在本机进行类似的图像处理时,采用7个进程数并行可以发挥机器的最佳效率。这个结果和上面那个对比结果相比差不多,虽然在那个对比实验中7个进程并不是最优,但是已经很接近了,而且至少比选3或4要好得多。当然采用这种方法得到的只是个推荐值,并不一定真的是最好的结果,仅供参考。
如上图所示,经过4次运算,在本机最终推荐的最佳进程数是7。即可以认为在本机进行类似的图像处理时,采用7个进程数并行可以发挥机器的最佳效率。这个结果和上面那个对比结果相比差不多,虽然在那个对比实验中7个进程并不是最优,但是已经很接近了,而且至少比选3或4要好得多。当然采用这种方法得到的只是个推荐值,并不一定真的是最好的结果,仅供参考。
至此,本篇关于Python并行编程的博客就到此结束了。最后,将本博客中的代码上传到了Github,点击查看。本文只是就目前自己能用到的东西进行了记录,更多高级的功能,如进程通信、队列等等,因为目前用不到所以暂时就不学了,等需要的时候再研究一下。感兴趣的话可以看参考资料里的相关网页。
5.参考资料
- [1]https://blog.csdn.net/dutsoft/article/details/54694798
- [2]https://docs.python.org/3.5/library/multiprocessing.html
- [3]https://blog.csdn.net/cityzenoldwang/article/details/78584175
- [4]https://blog.csdn.net/dev_csdn/article/details/78424704
- [5]https://blog.csdn.net/u013045749/article/details/50242097
- [6]https://python.jobbole.com/87645/
本文作者原创,未经许可不得转载,谢谢配合
