如之前笔记所述,VPI是一个可以在一定程度上替代OpenCV,并且效率更高的库。这篇笔记主要介绍一下VPI的一些架构以及一些示例。
1.VPI的架构
VPI的主要架构如下。
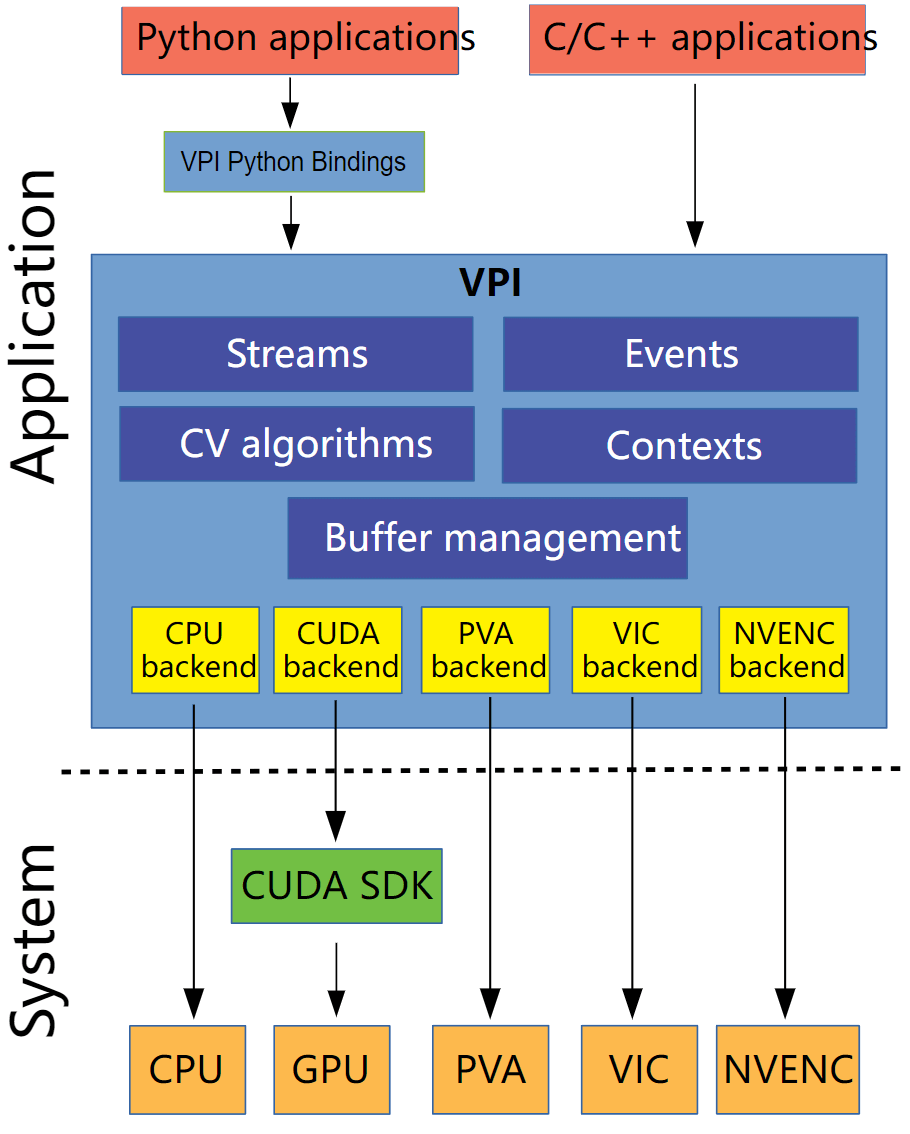 可以看到,主要分为系统层和应用层面。我们编写的Python或者C++程序与VPI交互,VPI通过Streams、Events、Contexts、CV algorithms等包装,在不同的硬件(VPI中叫做Backend)上进行了实现。哪些函数在哪些硬件平台上支持可以看这里。通过针对各自硬件平台的函数和API,最终实现与硬件的“定制化”交互。这样的好处就是可以充分发挥各个硬件平台的性能。
在上图中,各部分进一步的解释如下。
可以看到,主要分为系统层和应用层面。我们编写的Python或者C++程序与VPI交互,VPI通过Streams、Events、Contexts、CV algorithms等包装,在不同的硬件(VPI中叫做Backend)上进行了实现。哪些函数在哪些硬件平台上支持可以看这里。通过针对各自硬件平台的函数和API,最终实现与硬件的“定制化”交互。这样的好处就是可以充分发挥各个硬件平台的性能。
在上图中,各部分进一步的解释如下。
- Algorithms:不可再分的计算运算
- Backends:负责实际运算的硬件引擎
- Streams:异步队列,里面保存了提交的各种Algorithm,最终实现在给定Backend上的顺序执行
- Buffers:存储输入与输出数据
- Events:提供在Streams或者应用线程中可操作的同步功能
- Contexts:保存VPI以及创建的对象的状态
在之前提到,VPI程序的通用流程主要包含三个部分:初始化、主执行循环、变量销毁。而这些部分也就包含在这三个步骤之中,下面进行进一步介绍。
2.Algorithms
前面提到Algorithms表示实际的运算操作,它的操作对象是buffer。读取一个或多个输入的buffer,进行运算,最后将结果输出到用户指定的buffer上去。这些运算都是相对于程序线程异步执行的。目前,有两种Algorithms,一种是需要Payload的,另一种是不需要Payload的。所谓Payload,直译是载荷、负载的意思。在VPI里,它主要指代的是某个算法所需要的临时计算资源。VPI将这种和算法相关的临时资源以VPIPayload的方式进行封装。对于一些简单的操作,比如中值滤波,直接在输入数据上进行处理,然后输出就可以了。但对于一些复杂的操作,比如FFT等,则需要构建一些中间临时变量,算法才能正常运行。这就是VPI中Payload的意义。
2.1 Payload Algorithms
前面说了,Payload是和Algorithms相关联的临时资源,所以需要在初始化阶段就构造好。然后在调用某些函数的时候,将这些创建好的Payload对象传给他。当运算执行完成以后,再销毁初始化阶段创建的Payload。对于创建好的Payload,可以被多个Algorithms多次重复使用,但注意,它是独占的,一次只能有一个函数访问它。比如,下面的代码演示了创建Payload并和FFT Algorithms对象绑定,然后提交给Streams执行,最后销毁的过程。
// 创建VPIPayload对象并绑定
VPIPayload fft;
vpiCreateFFT(VPI_BACKEND_CUDA, width, height, VPI_IMAGE_FORMAT_F32, VPI_IMAGE_FORMAT_2F32, &fft);
// 提交FFT Algorithm对象到Stream执行
vpiSubmitFFT(stream, VPI_BACKEND_CUDA, fft, inputF32, spectrum, 0);
// 执行完成,销毁VPIPayload
vpiPayloadDestroy(fft);
2.2 Payload-Less Algorithms
另一种Algorithms则是不需要Payload临时变量的操作,此类操作一般比较简单。比如之前例子中提到的BoxFilter等。这些算法需要的数据都在Algorithm提交到Stream的时候传递了。比如下面的代码展示了BoxFilter的使用。
vpiSubmitBoxFilter(stream, VPI_BACKEND_CUDA, input, output, 5, 5, VPI_BORDER_ZERO);
3.Backends
前面提到,在VPI中,同一种算法可能在多个backend被实现了。一般而言,给定相同数据,不同后端的算法结果输出是相同的。但由于不同硬件架构实现上的差异,可能会出现轻微的不同。
3.1 CPU
CPU后端主要是基于多核并行实现,通过多个后台工作线程和数据结构来支撑高效的并行计算。VPI支持自定义CPU任务调度策略,具体来说,通过vpiContextSetParallelFor和VPIParallelForCallback函数实现。
3.2 CUDA
这里就是指搭载有CUDA引擎的GPU平台。在VPI编程中,我们并不需要像常规CUDA程序一样显式指定一系列参数,VPI会自动创建相关的Stream。需要注意的是,在目前的VPI中,不支持多GPU的操作,不然可能会出现不可靠结果。
3.3 PVA
全程是Programmable Vision Accelerator,是在NVIDIA Jetson AGX Xavier和Jetson Xavier NX系列上才有的硬件芯片,专门被用来做图像处理和一些计算机视觉任务。它的一大作用就是可以解放一部分GPU算力。把多余出来的GPU算力分给那些只能在GPU上运行的算法,比如深度学习推理等等。另外,PVA硬件要比CPU和CUDA硬件在能耗方面更加高效(power-efficient)。因此,官方文档给出的建议是,对于一些简单的算法,尽可能放在PVA硬件上执行。不过需要注意的是,在PVA上执行算法并不一定会比在CUDA或者CPU上快,只是说更加“省电”。在每个Jetson AGX Xavier和Jetson Xavier NX设备上都包含两个PVA芯片,每个芯片又都包含2个向量处理器(vector processor)。因此对于这些设备,一次最多可以同时执行4个独立的PVA任务。
3.4 VIC
全称是Video Image Compositor,是一个Jetson设备上包含固定功能的芯片,适合于一些低层次的影像处理任务,比如缩放、色彩空间转换、去噪、合成等。和PVA类似的,对于一些简单任务,可以考虑将其分配给VIC,在一定程度上解放GPU,做更多其它的事情。
3.5 NVENC
全称NVIDIA Encoder Engine,是一个Jetson设备上用于视频编码的芯片。它包含的一些功能可以用于其它任务,比如稠密光流估计等。
3.6 OFA
全称NVIDIA Optical Flow Accelerator,是一个只在Jetson AGX Orin设备上才有的、专门用于计算影像间光流的芯片。目前,它可以被用于计算双目视差图。
4.Streams
VPIStream是API的主要入口。VPIStream对象遵循first-in-first-out策略,其中存储了一系列将要被后端执行的命令。我们可以在新建VPIStream对象的时候通过参数的方式显式指定目标后端,否则VPI会使用当前可以使用的默认后端。当VPIStream对象启动之后,VPI会自动开启一个内部工作线程用于派发任务,执行相对于调用线程的异步操作。在初始化阶段我们向VPIStream对象中添加任务的时候,这些任务不会被执行,只有当VPIStream对象被写入(flush)后端时,才会真正开始执行。
5.Buffers
Buffers是VPI实际交互的数据类型。VPI支持三种抽象数据类型:
- Image: 2D影像
- Array: 1D向量
- Pyramid: 包含多个2D影像的向量
下面简单分别介绍。
5.1 Images
VPI中的Images本质上就是二维矩阵结构,所以任何二维数据都可以用它来存放。VPIImage通过尺寸(宽和高)和格式来定义。当新建VPIImages的时候,可以通过参数指定它要在哪个后端运行,可以指定多个或者不指定。如果不指定的话,那么就会用当前环境的默认后端。和VPIImage相关的有以下四个方面的内容。
5.1.1 Image Views
前面说了,VPIImage保存二维影像,而VPI Image Views则是保存影像中某一特定区域的数据。可以通过vpiImageCreateView()函数或者vpiImageSetView()函数创建。
5.1.2 Locking
为了使影像内容能够被VPI外部的API访问,我们需要在访问之前把相关数据“锁住”,可以通过vpiImageLockData()函数实现。而当数据获取完成以后,记得通过vpiImageUnlock()函数解锁数据对象。如果没有解锁直接访问,就有可能出现VPI_ERROR_BUFFER_LOCKED错误。
5.1.3 Image Formats
在VPI中,支持多种影像格式,包括单通道8bit、16bit、32bit影像等。这些都是定义在VPIImageFormat中的枚举类型,根据需要使用即可。需要注意的是,一些算法并不是每一种数据类型都支持,如果不明确,可以查看对应文档。
5.1.4 Warpping External Memory
我们可以利用vpiImageCreateWrapper()函数来直接从外部的内存创建VPIImage对象。这样,外部的数据就会被直接填充进来。当我们销毁这个对象的时候,外部传来的数据并不会被销毁。
5.2 Arrays
和2D的Images类似的,Arrays主要用来存储1D的数据,比如关键点的集合、坐标值等等。在VPI中,Arrays由capability、size和element type来定义。capability是指,在某个backend下(比如带有CUDA的GPU上),某个数据类型(比如int)所能支持的最大的长度(比如1024)。size则是指某个Array的实际长度。element type则是指每个元素的数据类型。所以其实可以发现,VPI中的Arrays的角色就基本等同于C语言里面的数组。
5.2.1 Locking
和Images类似的,在访问Arrays之前,需要利用vpiArrayLockData()先锁住对应的对象。更多信息可以参考Image对应部分。
5.2.2 Wrapping External Memory
还是类似的,我们可以利用vpiArrayCreateWrapper()函数实现外部数据的交互。更多信息可以参考对应文档。
5.3 Pyramids
在VPI中,Pyramids是一组VPI Image的集合,这些VPIImage对象都有相同的格式,但可以有不同的大小(当然也可以相同)。Pyramid由层数(number of levels)、基层的大小(base level dimensions)、缩放因子(scale factor)和影像格式(image format)四个部分确定,各个部分都比较好理解。更多关于Pyramid的用法可以参考相应官方文档。和Images和Arrays类似的,Pyramids也支持Locking。在VPI中可以把他当做一个整体进行处理。
6. Events
在VPI中,所有的操作相对于调用线程都是异步执行的。换言之,不同的并行操作之间并不会主动的互相等待,而是执行完了就立刻返回结果。所以说,需要有一些机制来同步这些操作。VPI中主要有两种方式。
第一种方式是调用vpiStreamSync()函数,该函数会等待VPIStream中所有的操作执行完成以后才继续后面的操作。这种方法比较简单,但是无法提供细粒度(fine-grained)的同步控制,比如等待函数X完成、等待Stream D中的函数C完成后再执行Stream B中的函数A。
第二种方式是使用VPIEvent对象,相比第一种方式更加灵活,设计思路也是仿照CUDA的API。我们可以利用vpiStreamWaitEvent()函数实现同一个Stream内的同步。同时,我们可以使用vpiEventQuery实现对于Event状态的查询。每一个Event都可以统计时间以及耗时。更多内容可以参考官方文档。
7. Contexts
Context是指VPI在执行操作过程中所用到的一切资源。一般情况下他会在第一个VPI资源创建的时候自动生成,在程序运行结束以后自动销毁,我们无需在意。这个自动创建的Context一般被称为Global Context。但如果有更加细致的控制要求,我们也可以手动创建Context,可以通过Context Stack来实现。更多细节参考官方文档,此处不再赘述。
8. 简单示例
在上面,我们介绍了VPI的基本架构以及其中涉及到的基本概念。在这一部分,我们通过一个实例来展示上面提到的架构、流程以及基本概念。首先我们看一个简单示例,这个例子利用Box Filter对输入影像进行滤波,然后输出,流程如下。
 下面针对C++和Python接口分别进行介绍。
下面针对C++和Python接口分别进行介绍。
8.1 C++版本
关于项目的CMake配置文件,此处不再赘述,可以参考之前笔记的内容。进入写代码的部分。
8.1.1 包含头文件
根据前面的描述,我们需要Image Buffers、Stream和Box Filter的头文件,所以代码如下。
#include <vpi/Image.h>
#include <vpi/Stream.h>
#include <vpi/algo/BoxFilter.h>
8.1.2 创建Buffer对象
根据前面的介绍,我们在一开始就新建好需要用的变量。这里因为只是一个简单的滤波操作,所以定义一个输入、一个输出即可,如下。
VPIImage input, output;
vpiImageCreate(input, 640, 480, VPI_IMAGE_FORMAT_U8, 0, &input);
vpiImageCreate(output, 640, 480, VPI_IMAGE_FORMAT_U8, 0, &output);
这里我们新建了一个640×480的单通道影像input,格式为8bit,VPI会以0初始化这个变量。然后又类似地创建了output变量。
8.1.3 创建Stream对象
正如前面说的,我们需要通过Stream来执行操作,如下。
VPIStream stream;
vpiStreamCreate(0, &stream);
这里的参数0表示不指定明确的Backend,算法可以在任何支持的Backend运行。
8.1.4 提交运算和变量到Stream
构造好变量和Stream对象以后,我们就可以把运算以及对应的变量提交了,如下所示。
vpiSubmitBoxFilter(stream, VPI_BACKEND_CUDA, input, output, 3, 3, VPI_BORDER_ZERO);
这里我们创建了一个3×3的滤波器,基于CUDA后端对input进行滤波,结果会输出给output。对于边界问题,补0解决。而且根据前面的描述,提交的运算会被立刻执行并返回结果。
8.1.5 等待同步操作
为了保证所有操作全部完成,根据上面的知识,可以利用vpiStreamSync()函数,如下。
vpiStreamSync(stream);
这样,程序就会一直等待上面的操作执行完以后,才会执行后续操作。
8.1.6 销毁资源
最后,别忘了把所有用到的资源进行销毁。毕竟在嵌入式平台上,资源都是很宝贵的。
vpiStreamDestroy(stream);
vpiImageDestroy(input);
vpiImageDestroy(output);
8.1.7 完整代码
上面功能的完整代码如下。
#include <vpi/Image.h>
#include <vpi/Stream.h>
#include <vpi/algo/BoxFilter.h>
int main(){
VPIImage input, output;
vpiImageCreate(input, 640, 480, VPI_IMAGE_FORMAT_U8, 0, &input);
vpiImageCreate(output, 640, 480, VPI_IMAGE_FORMAT_U8, 0, &output);
vpiSubmitBoxFilter(stream, VPI_BACKEND_CUDA, input, output, 3, 3, VPI_BORDER_ZERO);
vpiStreamSync(stream);
vpiStreamDestroy(stream);
vpiImageDestroy(input);
vpiImageDestroy(output);
return 0;
}
8.1.8 对程序的简单分析
上述构建的程序的概念结构图如下所示。
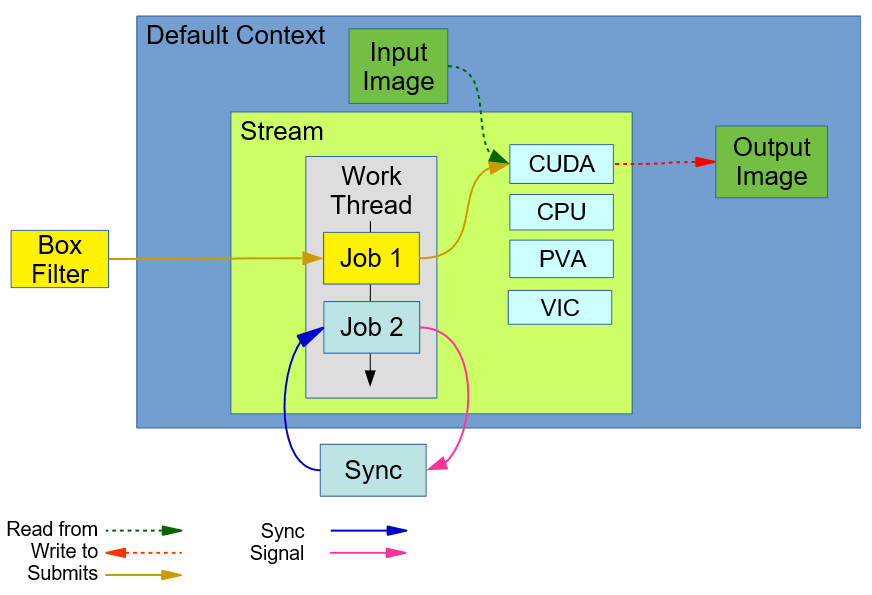 在上图中,Default Context是VPI自动创建和激活的Context。在这个例子中,默认的Context是stream和image buffers。Stream拥有一个working线程,该线程用于分配任务给backends以及处理线程间的同步问题。而我们的BoxFilter算法则是提交到这个stream中。在其内部,Job 1由算法对应的相关API函数创建,在stream的队列中等待执行,直到他之前分配给backend的任务都执行完成。Sync代表
在上图中,Default Context是VPI自动创建和激活的Context。在这个例子中,默认的Context是stream和image buffers。Stream拥有一个working线程,该线程用于分配任务给backends以及处理线程间的同步问题。而我们的BoxFilter算法则是提交到这个stream中。在其内部,Job 1由算法对应的相关API函数创建,在stream的队列中等待执行,直到他之前分配给backend的任务都执行完成。Sync代表vpiStreamSync的调用。它会向working线程中添加Job 2,当他被执行以后,会触发一个内部事件(internal event)。调用线程会一直等待这个内部事件,这样就表示,队列中的所有任务都被执行完成了。
8.2 Python版本
对于Python版本的VPI使用,主要包含如下三个步骤。
8.2.1 导入vpi包
在安装好VPI以后,我们可以直接在Python中按如下方式导入包:
import vpi
8.2.2 创建Image Buffer
和上面类似的,我们创建一个640×480的8bit单通道影像,并用0来初始化。代码如下。
input = vpi.Image((640, 480), vpi.Format.U8)
8.2.3 执行操作
然后,我们可以用with的方式指定执行后端,调用函数,执行命令,如下。
with vpi.Backend.CUDA:
output = input.box_filter(3)
8.2.4 完整代码
完整代码如下。
import vpi
input = vpi.Image((640, 480), vpi.Format.U8)
with vpi.Backend.CUDA:
output = input.box_filter(3)
9. 复杂示例
上面我们介绍了一个简单的例子。这里我们再介绍一个稍微复杂,但和实际应用更贴合的例子。在实际应用中,为了能够取得最好的效果,我们一方面可以充分挖掘执行流程中潜在的可并行的操作,另一方面应该充分利用CPU、GPU、PVA、VIC等不同硬件芯片的优势,取其所长设计整体流程。比如我们需要处理一对双目影像,估计视差图,并且还要在右影像上进行Harris角点提取,流程示意如下所示。
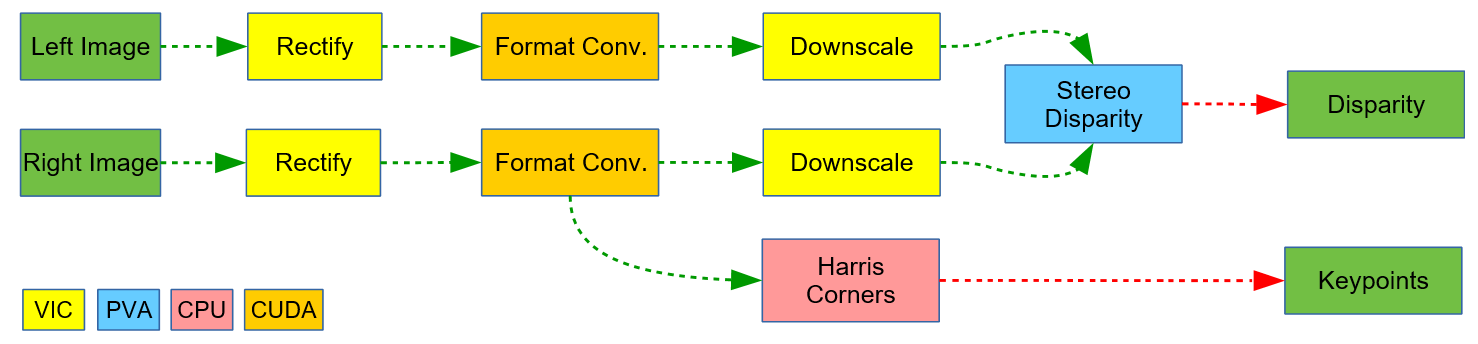 在上图中有三个可以并行的阶段,第一个是对于左影像的处理、第二个是对于右影像的处理,第三个是Harris角点提取。同时,为了最大程度发挥各个后端的优势,不同的步骤被分配给了不同的后端:
在上图中有三个可以并行的阶段,第一个是对于左影像的处理、第二个是对于右影像的处理,第三个是Harris角点提取。同时,为了最大程度发挥各个后端的优势,不同的步骤被分配给了不同的后端:
- VIC:执行双目影像校正和下采样操作
- CUDA:执行影像格式转换操作
- PVA:执行双目视差估计操作
- CPU:处理预处理和Harris角点提取操作
通过将任务分配给不同的后端,就可以在一定程度上减轻GPU的负担,使其可以更有精力处理一些其它任务,比如深度学习等。这里把影像格式转换交给CUDA去做是因为,CUDA进行这个操作非常快速,几乎不会对其它任务造成影响。
9.1 流程示意图
下图展示了上面的流程对应的VPI执行图。简单来说,左stream和右stream同时开始预处理,此时,特征提取stream会等待,直到右stream准备OK以后才会执行。它在执行的同时,右stream会继续把剩下的预处理做完。当左stream预处理完成以后,它会等待右stream也完成。最终,双目视差估计开始执行。
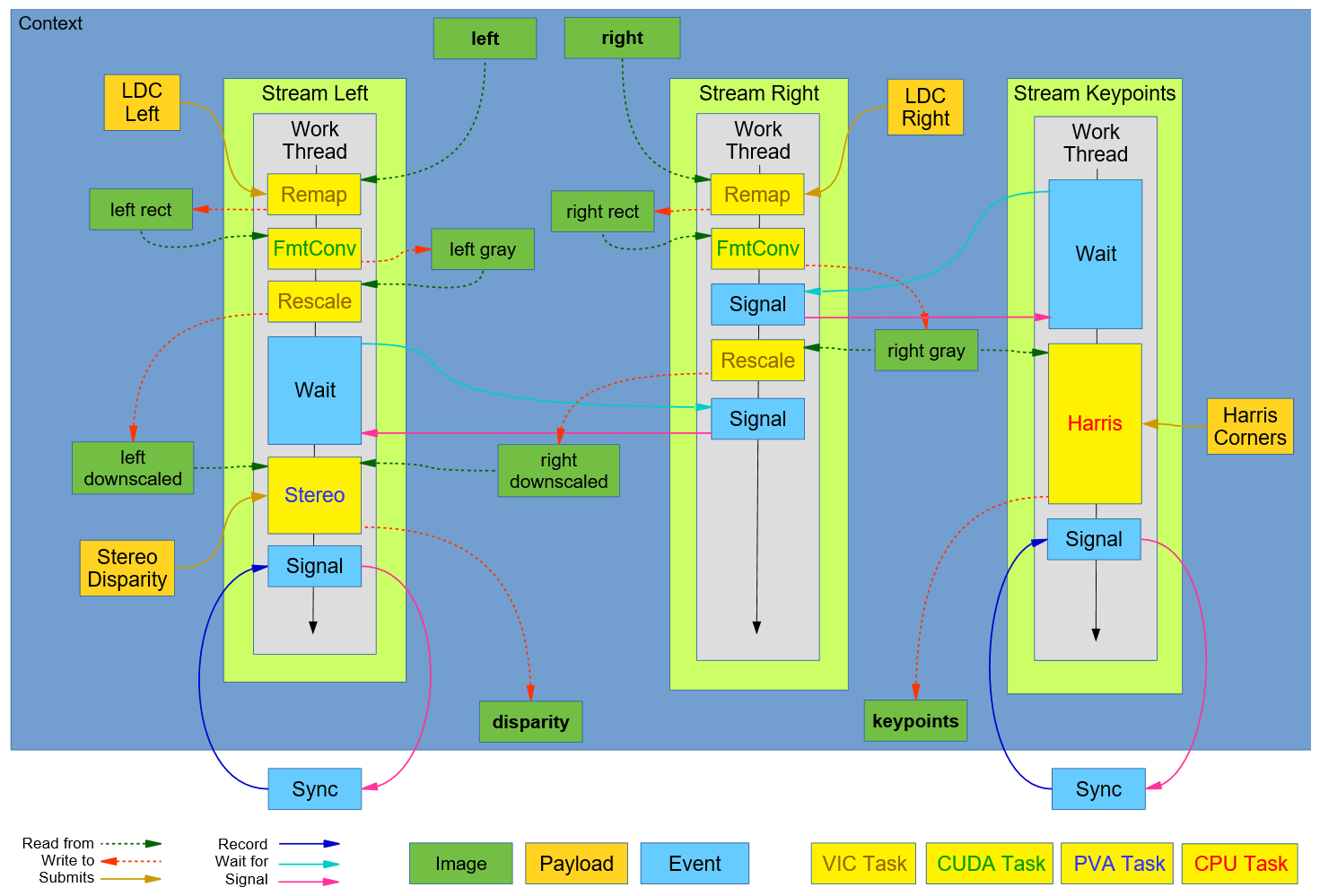 这个图看起来挺复杂,但其实仔细研究一下也是比较好理解的。整个流程分为三个Stream:Stream Left、Stream Right和Stream Keypoints。流程的起点是绿色的left和right影像输入。当程序运行的时候,三个Stream同时开启。但Keypoints流一开始会等待Right流中的信号,所以此时Keypoints流原地待命。Left和Right流同时向下走。首先会对输入数据通过Remap进行校正,然后将输出的结果进行数据格式转换,转换完成后,Right流中的信号发出,此时等待中的Keypoints流接收到信号,开始Harris角点提取,输入数据来自于Right流格式转换以后的影像。同时在Left流中,做完格式转换以后会进行Rescale操作。在这一步之后,Left流会等待Right流也做完Rescale操作。当Right流中的Rescale做完以后,同样会发出一个Signal,Left流接收到这个信号以后,开始执行双目视差估计。这样一个流程就基本完成了。
这个图看起来挺复杂,但其实仔细研究一下也是比较好理解的。整个流程分为三个Stream:Stream Left、Stream Right和Stream Keypoints。流程的起点是绿色的left和right影像输入。当程序运行的时候,三个Stream同时开启。但Keypoints流一开始会等待Right流中的信号,所以此时Keypoints流原地待命。Left和Right流同时向下走。首先会对输入数据通过Remap进行校正,然后将输出的结果进行数据格式转换,转换完成后,Right流中的信号发出,此时等待中的Keypoints流接收到信号,开始Harris角点提取,输入数据来自于Right流格式转换以后的影像。同时在Left流中,做完格式转换以后会进行Rescale操作。在这一步之后,Left流会等待Right流也做完Rescale操作。当Right流中的Rescale做完以后,同样会发出一个Signal,Left流接收到这个信号以后,开始执行双目视差估计。这样一个流程就基本完成了。
9.2 代码实现(C++)
上述例子的C++代码实现简要介绍如下。
9.2.1 包含头文件
根据上面流程的需要,包含头文件,如下。
#include <string.h>
#include <vpi/Array.h>
#include <vpi/Context.h>
#include <vpi/Event.h>
#include <vpi/Image.h>
#include <vpi/LensDistortionModels.h>
#include <vpi/Stream.h>
#include <vpi/WarpMap.h>
#include <vpi/algo/BilateralFilter.h>
#include <vpi/algo/ConvertImageFormat.h>
#include <vpi/algo/HarrisCorners.h>
#include <vpi/algo/Remap.h>
#include <vpi/algo/Rescale.h>
#include <vpi/algo/StereoDisparity.h>
9.2.2 程序初始化
(a) 创建Context并激活
输入下面的代码即可创建Context。
VPIContext ctx;
vpiContextCreate(0, &ctx);
vpiContextSetCurrent(ctx);
尽管VPI会给我们自动创建Context,但如果想实现完全的控制,那么还是自己手动创建比较好。
(b) 创建Stream
根据前面的描述,我们需要三个流来分别处理左、右影像、提取Harris角点,并且重用左影像Stream来进行视差估计,所以代码如下。
VPIStream stream_left, stream_right, stream_keypoints;
vpiStreamCreate(0, &stream_left);
vpiStreamCreate(0, &stream_right);
vpiStreamCreate(0, &stream_keypoints);
(c) 创建Input Image
EGLImageKHR eglLeftFrame = /* First frame from left camera */;
EGLImageKHR eglRightFrame = /* First frame from right camera */;
VPIImage left, right;
VPIImageData dataLeft;
dataLeft.bufferType = VPI_IMAGE_BUFFER_EGLIMAGE;
dataLeft.buffer.egl = eglLeftFrame;
vpiImageCreateWrapper(&dataLeft, NULL, 0, &left);
VPIImageData dataRight;
dataRight.bufferType = VPI_IMAGE_BUFFER_EGLIMAGE;
dataRight.buffer.egl = eglRightFrame;
vpiImageCreateWrapper(&dataRight, NULL, 0, &right);
(d) 创建Image Buffers
VPIImage left_rectified, right_rectified;
vpiImageCreate(640, 480, VPI_IMAGE_FORMAT_NV12_ER, 0, &left_rectified);
vpiImageCreate(640, 480, VPI_IMAGE_FORMAT_NV12_ER, 0, &right_rectified);
VPIImage left_grayscale, right_grayscale;
vpiImageCreate(640, 480, VPI_IMAGE_FORMAT_U16, 0, &left_grayscale);
vpiImageCreate(640, 480, VPI_IMAGE_FORMAT_U16, 0, &right_grayscale);
VPIImage left_reduced, right_reduced;
vpiImageCreate(480, 270, VPI_IMAGE_FORMAT_U16, 0, &left_reduced);
vpiImageCreate(480, 270, VPI_IMAGE_FORMAT_U16, 0, &right_reduced);
VPIImage disparity;
vpiImageCreate(480, 270, VPI_IMAGE_FORMAT_U16, 0, &disparity);
在流程中,我们涉及到校正、格式转换和视差图计算三个步骤,每个步骤都需要对应的变量,所以上述代码就是在创建这些变量(也就对应上面那个流程图中绿色的方块)。
(e) 定义视差算法参数以及创建对应Payload
我们主要使用vpiCreateStereoDisparityEstimator()函数计算视差,代码如下。
VPIStereoDisparityEstimatorParams stereo_params;
stereo_params.windowSize = 5;
stereo_params.maxDisparity = 64;
VPIStereoDisparityEstimatorCreationParams stereo_creation_params;
vpiInitStereoDisparityEstimatorCreationParams(&stereo_creation_params);
stereo_params.maxDisparity = stereo_params.maxDisparity;
VPIPayload stereo;
vpiCreateStereoDisparityEstimator(VPI_BACKEND_CUDA, 480, 270, VPI_IMAGE_FORMAT_U16, &stereo_creation_params,
&stereo);
(f) 创建影像校正Payload和对应参数
影像校正核心使用的是Remap()函数。
VPIPolynomialLensDistortionModel dist;
memset(&dist, 0, sizeof(dist));
dist.k1 = -0.126;
dist.k2 = 0.004;
const VPICameraIntrinsic Kleft =
{
{466.5, 0, 321.2},
{0, 466.5, 239.5}
};
const VPICameraIntrinsic Kright =
{
{466.2, 0, 320.3},
{0, 466.2, 239.9}
};
const VPICameraExtrinsic X =
{
{1, 0.0008, -0.0095, 0},
{-0.0007, 1, 0.0038, 0},
{0.0095, -0.0038, 0.9999, 0}
};
VPIWarpMap map;
memset(&map, 0, sizeof(map));
map.grid.numHorizRegions = 1;
map.grid.numVertRegions = 1;
map.grid.regionWidth[0] = 640;
map.grid.regionHeight[0] = 480;
map.grid.horizInterval[0] = 4;
map.grid.vertInterval[0] = 4;
vpiWarpMapAllocData(&map);
VPIPayload ldc_left;
vpiWarpMapGenerateFromPolynomialLensDistortionModel(Kleft, X, Kleft, &dist, &map);
vpiCreateRemap(VPI_BACKEND_VIC, &map, &ldc_left);
VPIPayload ldc_right;
vpiWarpMapGenerateFromPolynomialLensDistortionModel(Kright, X, Kleft, &dist, &map);
vpiCreateRemap(VPI_BACKEND_VIC, &map, &ldc_right);
(g) 创建Harris角点输出Buffers
VPI中的Harris算法会输出两个Arrays,一个是Keypoints本身,另一个是每个Keypoint的得分。一次最多返回8192个Keypoint,这个数值就是新建Array的Capability。对于Keypoints,以VPIKeypointF32结构存储,得分则是以32bit的无符号值存储。
VPIArray keypoints, scores;
vpiArrayCreate(8192, VPI_ARRAY_TYPE_KEYPOINT_F32, 0, &keypoints);
vpiArrayCreate(8192, VPI_ARRAY_TYPE_U32, 0, &scores);
(h) 定义Harris参数并创建对应Payload
和视差估计类似的,Harris检测也需要Payload,代码如下。
VPIHarrisCornerDetectorParams harris_params;
vpiInitHarrisCornerDetectorParams(&harris_params);
harris_params.gradientSize = 5;
harris_params.blockSize = 5;
harris_params.strengthThresh = 10;
harris_params.sensitivity = 0.4f;
VPIPayload harris;
vpiCreateHarrisCornerDetector(VPI_BACKEND_CPU, 640, 480, &harris);
(i) 创建Events实现同步
Events是用来进行不同Stream之间的同步,在VPI中通过VPIEvent实现。前面说了,在整个流程中需要一些同步机制,所以也需要提前声明。具体说来是:右Stream需要等待Harris角点提取完成才会继续执行降采的操作,左Steam需要等待右影像的预处理完成才会继续执行视差估计的操作。代码如下。
VPIEvent barrier_right_grayscale, barrier_right_reduced;
vpiEventCreate(0, &barrier_right_grayscale);
vpiEventCreate(0, &barrier_right_reduced);
9.2.3 程序主体执行
当初始化完成以后,就进入了主要处理阶段。具体包括以下代码:
(a) 提交左影像预处理步骤
我们需要将前面定义好的校正、格式转换和降采操作提交到左Stream中。
vpiSubmitRemap(stream_left, VPI_BACKEND_VIC, ldc_left, left, left_rectified, VPI_INTERP_CATMULL_ROM,
VPI_BORDER_ZERO, 0);
vpiSubmitConvertImageFormat(stream_left, VPI_BACKEND_CUDA, left_rectified, left_grayscale, NULL);
vpiSubmitRescale(stream_left, VPI_BACKEND_VIC, left_grayscale, left_reduced, VPI_INTERP_LINEAR, VPI_BORDER_CLAMP,
0);
(b) 提交右影像预处理的部分步骤
主要包括校正、格式转换两个步骤,也就是等待Harris执行完前面的步骤。
vpiSubmitRemap(stream_right, VPI_BACKEND_VIC, ldc_right, right, right_rectified, VPI_INTERP_CATMULL_ROM,
VPI_BORDER_ZERO, 0);
vpiSubmitConvertImageFormat(stream_right, VPI_BACKEND_CUDA, right_rectified, right_grayscale, NULL);
(c) 记录右Stream状态
vpiEventRecord(barrier_right_grayscale, stream_right);
这里的barrier_right_grayscale来自初始化阶段创建的Event对象。
(d) 完成右Stream中的降采操作
vpiSubmitRescale(stream_right, VPI_BACKEND_VIC, right_grayscale, right_reduced, VPI_INTERP_LINEAR, VPI_BORDER_CLAMP,
0);
(e) 记录右Steam的状态
vpiEventRecord(barrier_right_reduced, stream_right);
(f) 让左Stream等待右Stream步骤完成
vpiStreamWaitEvent(stream_keypoints, barrier_right_grayscale);
(g) 提交视差估计步骤
vpiSubmitStereoDisparityEstimator(stream_left, VPI_BACKEND_CUDA, stereo, left_reduced, right_reduced, disparity,
NULL, &stereo_params);
(h) 提交关键点检测步骤
vpiSubmitHarrisCornerDetector(stream_keypoints, VPI_BACKEND_CPU, harris, right_grayscale, keypoints, scores,
&harris_params);
(i) 同步流来接收数据
vpiStreamSync(stream_left);
vpiStreamSync(stream_keypoints);
(j) 获取下一帧数据
eglLeftFrame = /* Fetch next frame from left camera */;
eglRightFrame = /* Fetch next from right camera */;
dataLeft.bufferType = VPI_IMAGE_BUFFER_EGLIMAGE;
dataLeft.buffer.egl = eglLeftFrame;
vpiImageSetWrapper(left, &dataLeft);
dataRight.bufferType = VPI_IMAGE_BUFFER_EGLIMAGE;
dataRight.buffer.egl = eglRightFrame;
vpiImageSetWrapper(right, &dataRight);
当有新的数据来的时候,我们把新数据直接放进我们之前就创建好的变量中即可,无需重新创建对象,这样可以更高效一些。
9.2.4 销毁Context
最后,当程序执行完以后,别忘了销毁相关的资源。我们可以直接销毁前面创建的Context,这样他下面的所有资源都会被统一销毁,而无需一个一个的手动销毁。根据官方说法,这个操作之后,不可能会有内存泄漏问题(No memory leaks are possible)。
vpiContextDestroy(ctx);
10.参考资料
- [1] https://docs.nvidia.com/vpi/architecture.html
本文作者原创,未经许可不得转载,谢谢配合
