前面几篇博客相继介绍了光流法、背景减除法等方法。这里简单对于视频运动目标提取的方法做个总结。 目前视频运动目标提取主要有帧间差分法、背景减除法以及光流法三大类。下面逐一介绍。 本篇博客参考了这篇博客,如果感兴趣可以阅读。
一、帧间差分法
1.基本原理
帧间差分法一般用来检测固定摄像头拍摄的运动物体。 其本质就是认为如果没有运动物体出现,视频中相邻两帧应该是相同的(因为是固定摄像头,所以背景应该没有大的变化)。 这样如果相邻两帧做差分运算(相减),那么结果应该为0或接近于0。但如果有运动物体出现,那么相邻两帧相减差值变化会很大,差别很大的部分就是运动物体。 帧间差分法便是依据这个思想进行运动目标检测的。其基本原理可用下式表示:
\[D(i,j)=\begin{cases} & \text{ 1, } |I_{t}(i,j)-I_{t-1}(i,j)|>T \\ & \text{ 0, } else \end{cases}\]其中\(I_{t}(i,j)\)表示t时刻(i,j)处的像素值,T为阈值,D(i,j)为两帧之间的差分值。 t与t-1时刻的图像做差,如果差异大于阈值T,则认为该像素为运动目标,使其值为1。 得到的是一个只有0和1的掩膜图像,使用它与原始影像做与运算即可获得运动目标。 当然,其实完全可以直接用相邻两帧的差值进行阈值操作,作为结果图像,这样就不需要进行掩膜操作了。如下:
\[D(i,j)=\begin{cases} & \text{ |I_{t}(i,j)-I_{t-1}(i,j)|, } |I_{t}(i,j)-I_{t-1}(i,j)|>T \\ & \text{ 0, } else \end{cases}\]更简单与原始的想法是,不需要阈值操作,直接将相邻两帧相减,得到的差值作为结果,如下:
\[D(i,j)=\begin{cases} & \text{ |I_{t}(i,j)-I_{t-1}(i,j)|, } \\ & \text{ 0, } else \end{cases}\]这样最简单,得到的结果也最“简单粗暴”。因为即使同一背景,在相邻两帧之间某一像素的灰度值也不是一点都不变的。 很可能有细微的上下浮动。这种变化其实在上一篇博客介绍灰度随时间变化时,那个曲线图里已经可以看到。 不可能是一条直线。因此这就带来一个问题,如果直接相减作为结果。那么得到的结果很可能有很多细小的噪声点。 这些噪声点就是由每帧之间灰度的细微变化导致的。因此对差分结果使用阈值操作是不错的选择。
2.优缺点
当然这种方法的优缺点也是明显的。 优点是原理简单,易于实现,动态环境自适应性强,对场景光线变化不敏感(因为不依赖于某个固定背景,而是实时相邻帧做差)。 缺点是算法过于简单导致检测结果精度不高。出现“空洞”现象(因为运动物体内部灰度值相近);“双影”现象(差分图像物体边缘轮廓较粗); 不能提取出运动对象的完整区域,仅能提取轮廓。算法效果严重依赖所选取的帧间时间间隔和分割阈值。 对快速运动的物体,需要选择较小的时间间隔。如果选择不合适,当物体在前后两帧中没有重叠时,会被检测为两个分开的物体; 而对慢速运动的物体,应该选择较大的时间差,如果时间选择不适当,当物体在前后两帧中几乎完全重叠时,则检测不到物体。
3.三帧差法
针对“双影”现象,提出了“三帧差法”, 可在一定程度上消除帧间差分法的“双影”现象。算法流程如下所示:
- 1.由I(t)和I(t-1)做差,得到差分影像D(t)
- 2.有I(t+1)和I(t)做差,得到差分影像D(t+1)
- 3.对D(t)和D(t+1)取交集,得到差分图像D
- 4.对D进行形态学操作去噪
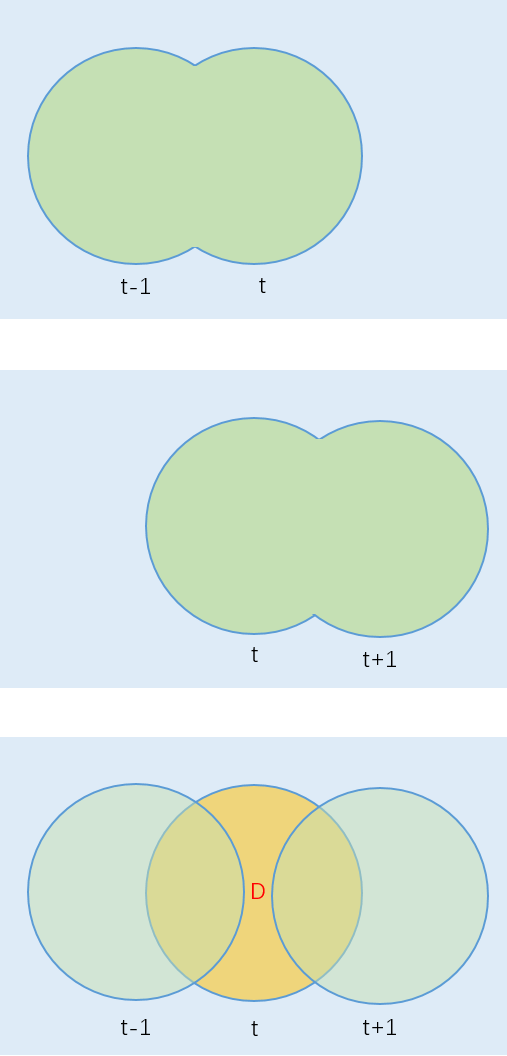 图中用红色字母D标识出的橙色区域为提取结果。
图中用红色字母D标识出的橙色区域为提取结果。
二、背景减除法
背景减除法在上一篇博客中已经有了比较详细的介绍,这里只是简单总结一下。更多细节可以看上一篇博客。
背景减除法其实可以叫做背景差分法。与帧间差分法相比,它用的是另一种思路。 即并不是相邻帧相减,不考虑相邻帧之间的关系。 而是通过视频中的帧序列利用各种算法(如均值法、中值法、直方图法、混合高斯模型、Kalman滤波、背景预测等算法)得到一个背景。 然后再将每一帧与这个得到的背景做差分,结果就是运动目标了。 这个得到背景的过程可以叫做背景建模,在这一方面已经有了很多研究和算法。 当然如果有一幅“干净”的背景,也就不用谈这些了。 然而在实际环境中,这样“干净”的背景是很难被捕捉到的。所以才需要通过各种算法尽可能得到“完美”的、接近真实的背景。
背景减除一般包含以下三个步骤:背景初始化、背景更新、目标检测。下面逐一介绍。
1.背景初始化
背景初始化是指从视频开始的前N帧图像中“训练”出不包含任何运动目标的背景图像的过程。 与背景更新不同的是,背景初始化仅仅完成从视频第一帧到第N帧的背景建立工作。 通常,使用一些相对“干净”的视频帧(不包含运动前景)来“训练”出高质量的背景。
2.背景更新
通过上面初始化后的背景需要更新的原因在于,背景并不是一尘不变的。 在实际的场景中,即便是室内环境,也存在光线等各种变化造成的干扰,或者人为造成的开灯等光线的强烈变化。 所以在背景差分法的实现中,它的固定背景不能一成不变。 如果不进行重新初始化,错误的检测结果将随时间不断累计,造成恶性循环,从而造成监控失效。 因此,在提出检测算法的同时,要建立背景更新模型和机制。保证背景图像能随着光线的变化而变化,确保检测的准确性。 不同的算法都有着不同的背景更新方法,但这一步骤通常涉及到以下几个问题:
(1)更新机制
目前,有全更新、选择更新,以及模糊自适更新三种背景更新方法。
a.全更新
全更新是指更新所有的像素,如下式所示:
\[B_{t+1}(i,j)=(1-\alpha)B_{t}(i,j)+\alpha I_{t}(i,j)\]其中,\(B_{t}(i,j)\)为t时刻提取的背景,\(I_{t}(i,j)\)为t时刻的帧内容。 α为学习率。很明显如果α较大,则每次背景更新都受上一帧较大影响。 这种方法的主要缺点是,前帧的前景将会被更新到背景模型中,这就导致了背景模型更新的不准确。
b.选择更新
为了解决上面的问题,一些学者就提出了选择更新,即针对当前帧的背景和前景区域,采用不同的更新机制,如下所示:
\[B_{t+1}(i,j)=\begin{cases} & (1-\alpha)B_{t}(i,j)+\alpha I_{t}(i,j), I_{t}(i,j)\in B_{t}(i,j)\\ & (1-\beta)B_{t}(i,j)+\beta I_{t}(i,j), else \end{cases}\]这样的更新机制是,首先根据t时刻已经获得的背景判断t时刻帧内容哪些属于背景,哪些不属于背景。 对于背景和前景采用不同的学习率来进行更新。 通常希望背景像素更多的参与到背景模型中,而前景像素采用较慢的更新机制,所以设置α值较大,β值较小。 特别的,当β=0的时候,就是去除掉前景元素,只对背景元素进行更新,也就是全更新。 这样就在一定程度上能够加快背景更新的速率,然而,这种更新机制也存在一定的问题。 当前景和背景的提取发生错误时,就可能更新为一个错误的背景模型。
c.模糊更新
模糊自适应更新机制由于考虑到前景和背景提取的不确定性,所以能够较好的解决上面的问题,但是缺点是计算量较大。
(2)学习率
学习率决定了背景模型变化的快慢,可以是固定的数字,或者动态的数字。 而且从上面的公式也可以看到,学习率越高,背景受前景影响就越大。
(3)更新频率
传统的背景更新是对每一帧都进行背景更新,但背景往往并没有任何显著的变化。 所以,有些学者提出了有选择性地进行背景更新的方法。
3.目标检测
目标检测就是利用背景模型,将当前帧的像素标注为背景或前景的过程。对于不同的算法,其采用的检测方法也各有不同。 此外,所有背景减除法都涉及特征尺寸选择和特征类型选择的问题。 特征尺寸的选择有三种情况:像素、块和集群; 而特征类型的选择通常也有三种情况:颜色特征、纹理特征和帧特征等。 常用的颜色特征是像素点的灰度值或RGB值,它们是场景中视觉信息的最直观反映,但是两者都极易受到光照变化的影响, 所以,在光线变化的环境中,基于灰度值和RGB值的运动目标检测方法都会产生大量的误检。 针对颜色特征的不足,研究人员又提出了纹理特征以及帧特征等,并应用到背景减除法上,有效克服了光线变化场景中的问题。 显然,选择不同的特征尺寸和特征类型,在特殊情况下(如:光照变化,动态背景等)背景和前景的提取的方式也就不同。
4.优缺点
背景减除法优点是:检测的准确性比较高,实时性较好,并且鲁棒性也较好; 但是在实际复杂多变的环境中,很难找到理想的背景模型极其更新机制。 所以,在近十几年里,众多学者研究出很多背景减除算法。
三、光流法
光流法在OpenCV笔记17中已经有了详细的介绍,这里就不再介绍理论推导等等了。只是简单回顾一下。
1.基础原理
为什么会有光流法?因为在非固定摄像头下的视频中,背景也是动态改变的,这种情况下对运动目标的检测就不能采用以上两种方法,而得采用光流法。 由于光流包含了目标运动的信息,所以,光流场近似于运动场。 通常,视频序列中背景的光流是一致的,与运动目标的光流不同,因此,根据光流的不同就可以提取运动目标和背景区域。
同时由于求解光流方程的约束条件各有不同,所以有很多种方法,有微分法、区域匹配法等。 其中最经典的两种算法为HS(Horn-Schunck)算法与之前介绍过的LK(Lucas-Kanade)算法。
2.优缺点
光流法的优点是:针对运动的摄像头下的视频,也可以对运动目标与背景的进行提取。 但是,在实际应用中,当复杂性与多变性的外界环境不满足光流场的约束条件时,就不能正确的求解出光流场; 此外,光流法的算法复杂度高,用于运动检测实时性差。
四、小结
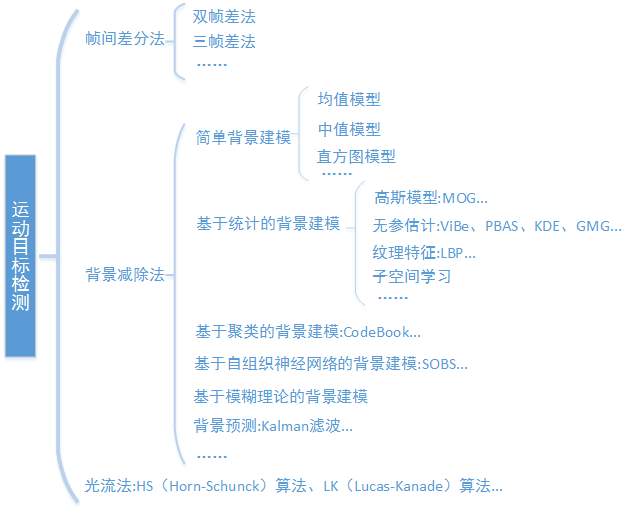
本文总结了目前视频运动目标提取的三大类算法:帧间差法、背景减除法和光流法。
三种算法分别对应了三种不同的思路。
帧间差法考虑的是各帧之间的差异。背景减除法考虑的是每一帧与固定背景的差异。
光流法考虑的也是帧间差异,但是用光流场来描述。
三类方法各有优缺点和适用范围。
最后用如下结构图总结三种方法。
目前,虽然有大量的运动目标检测算法,但由于实际环境的复杂多变,所以这些算法并不都是十分的健壮。 最主要的影响是动态背景和光照变化。 因此没有什么算法是适用于全部情况的。很多时候需要针对特定或某一类场景对算法进行优化或提出新的算法。 用一句古语总结就是“路漫漫其修远兮,吾将上下而求索”。
本文作者原创,未经许可不得转载,谢谢配合
