一、灰度随时间的变化
在之前的图像处理中,我们只考虑了x、y二维的情况。但是在视频中,还存在着第三维t,如下图所示。
 因此研究物体的运动就有必要研究像素灰度值随时间变化的趋势。其实在上一篇博客进行光流方程推导时,已经引入了时间这个概念。
这里通过一小段代码,可以更直观地感受视频中某个位置的像素灰度随时间的变化关系。
因此研究物体的运动就有必要研究像素灰度值随时间变化的趋势。其实在上一篇博客进行光流方程推导时,已经引入了时间这个概念。
这里通过一小段代码,可以更直观地感受视频中某个位置的像素灰度随时间的变化关系。
# coding=utf-8
import cv2
from matplotlib import pyplot as plt
path = 'E:\\vtest.avi'
cap = cv2.VideoCapture(path)
width = int(cap.get(3))
height = int(cap.get(4))
r_list = []
g_list = []
b_list = []
gray_list = []
while 1:
ret, frame = cap.read()
if frame is None:
cv2.waitKey(0)
break
else:
b, g, r = frame[int(width / 2), int(height / 2), :].ravel()
b_list.append(b)
g_list.append(g)
r_list.append(r)
gray_list.append((r * 30 + g * 59 + b * 11 + 50) / 100)
print 'R:', r_list[-1], 'G:', g_list[-1], 'B:', b_list[-1], 'Gray:', gray_list[-1]
cv2.imshow('frame', frame)
k = cv2.waitKey(50) & 0xff
if k == 27:
break
plt.plot(r_list, color='red', label='Red')
plt.plot(g_list, color='green', label='Green')
plt.plot(b_list, color='blue', label='Blue')
plt.plot(gray_list, color='gray', label='Gray')
plt.legend(loc='upper right')
plt.show()
cap.release()
cv2.destroyAllWindows()
如下是视频中心点像素灰度值随时间变化的曲线。
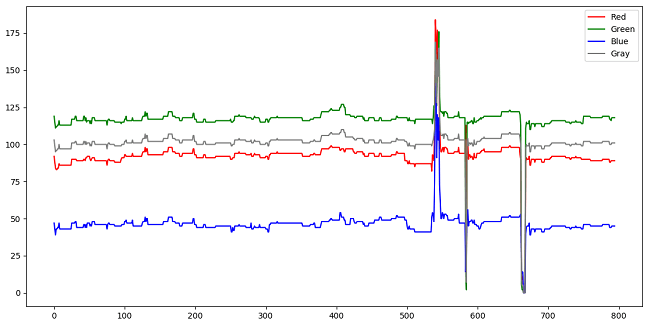 可以看到整体比较平稳,变化很小,说明该像素灰度随时间没什么变化。
但在后半部分有几个波动比较大的地方,然后又恢复原始灰度。
这说明该像素灰度发生了突变,也就是说有新的物体经过该位置。
通过观看视频可以发现,确实有行人经过中心点像素,导致了灰度变化。如下图所示。
可以看到整体比较平稳,变化很小,说明该像素灰度随时间没什么变化。
但在后半部分有几个波动比较大的地方,然后又恢复原始灰度。
这说明该像素灰度发生了突变,也就是说有新的物体经过该位置。
通过观看视频可以发现,确实有行人经过中心点像素,导致了灰度变化。如下图所示。
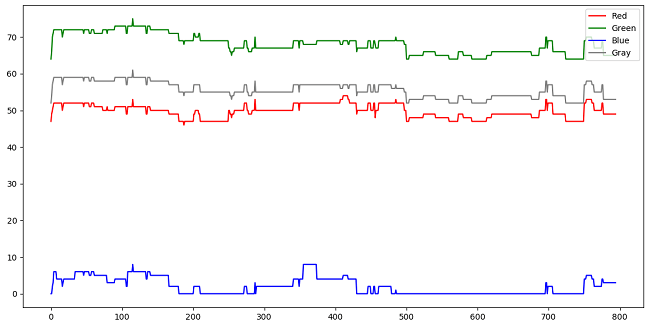
 下图是没有任何物体经过的像素随时间变化的关系,可以发现没有灰度的突变。
下图是没有任何物体经过的像素随时间变化的关系,可以发现没有灰度的突变。
二、OpenCV图像数据类型与代数运算
在OpenCV中,对图像数据进行代数运算需要注意图像数据类型和代数操作,否则很有可能得到错误的结果。这里简单总结一下。
1.加法
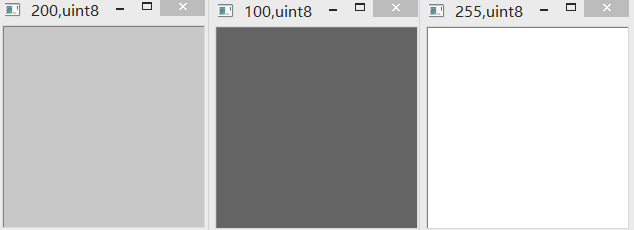
(1)cv2.add & uint8
uint8范围为0-255。采用OpenCV内置加法进行相加时,如果超限,则以255代替。如下图所示。
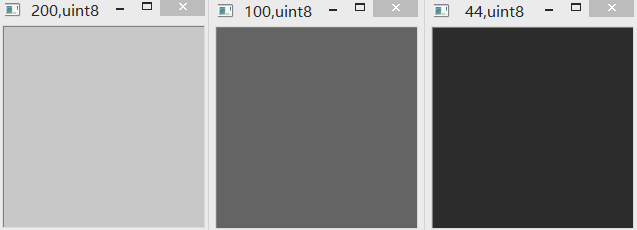
(2)“+” & uint8
uint8范围为0-255。采用普通加法相加,如果超限,则减去256(即该范围包含的数字个数)。如下图所示。
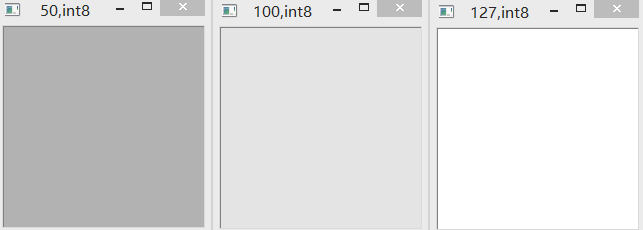
(3)cv2.add & int8
int8范围为-128到127。采用OpenCV加法相加,如果超限,则以最大值127代替。如下图所示。
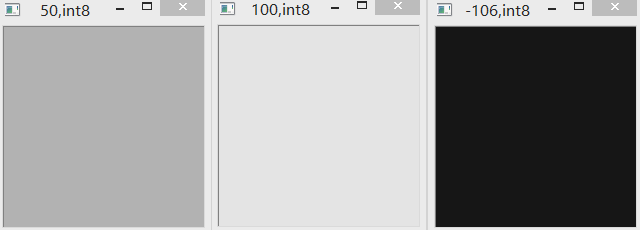
(4)“+” & int8
int8范围为-128到127。采用普通加法相加,如果超限,则减去256(即该范围包含的数字个数)。如下图所示。
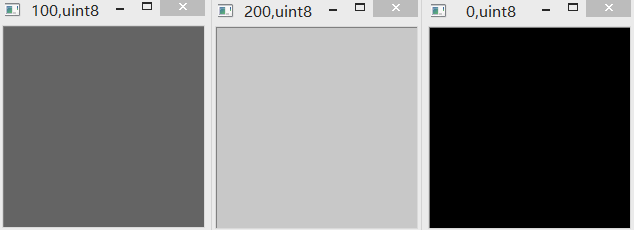
(5)cv2.subtract & uint8
uint8范围为0-255。采用OpenCV减法相减,如果超限,则以最小值0代替。如下图所示。
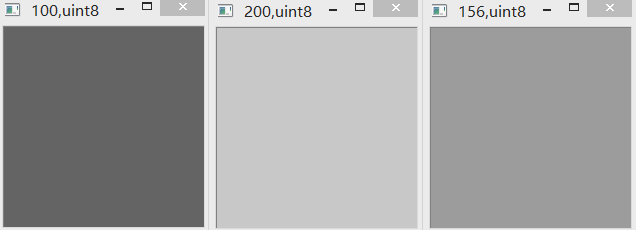
(6)“-” & uint8
uint8范围为0-255。采用普通减法相减,如果超限,则以加上256(即该范围包含的数字个数)。如下图所示。
(7)cv2.subtract & int8
int8范围为-128到127。采用OpenCV减法相减,如果超限,则以最小值-128代替。如下图所示。
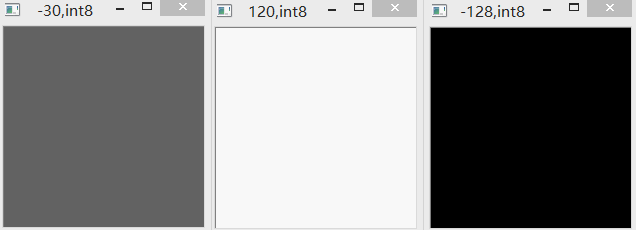
(8)“-” & int8
int8范围为-128到127。采用普通减法相减,如果超限,则以加上256(即该范围包含的数字个数)。如下图所示。
测试代码如下:
import cv2
import numpy as np
img1 = np.zeros((200, 200, 3), np.int8)
img1[...] = -30
img2 = np.zeros((200, 200, 3), np.int8)
img2[...] = 120
# img3 = cv2.add(img1, img2)
# img3 = img1 + img2
# img3 = cv2.subtract(img1, img2)
img3 = img1 - img2
cv2.imshow(img1[0, 0, 0].__str__() + ',' + img1.dtype.__str__(), img1)
cv2.imshow(img2[0, 0, 0].__str__() + ',' + img1.dtype.__str__(), img2)
cv2.imshow(img3[0, 0, 0].__str__() + ',' + img1.dtype.__str__(), img3)
cv2.waitKey(0)
(9)相减获得绝对值
最后给出如何获取相减绝对值的办法。先将数据类型转换为可为负数的类型,然后相减,再取绝对值,最后再转换为正数。
import cv2
import numpy as np
img1 = np.zeros((200, 200, 3), np.uint8)
img1[...] = 90
img2 = np.zeros((200, 200, 3), np.uint8)
img2[...] = 200
img3 = np.uint8(np.abs(np.int32(img1) - np.int32(img2)))
cv2.imshow(img1[0, 0, 0].__str__() + ',' + img1.dtype.__str__(), img1)
cv2.imshow(img2[0, 0, 0].__str__() + ',' + img1.dtype.__str__(), img2)
cv2.imshow(img3[0, 0, 0].__str__() + ',' + img1.dtype.__str__(), img3)
cv2.waitKey(0)
运行效果如下:
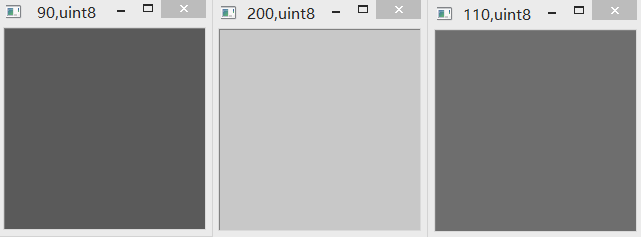 90-200,结果取了绝对值,为110。便是我们想要的结果了。
90-200,结果取了绝对值,为110。便是我们想要的结果了。
三、背景减除
0.最初的想法
对于背景减除,最原始的想法就是直接用相邻两帧相减,这样就可以得到帧间运动了。
但仔细一想就会发现问题。因为每帧之间运动物体会有重叠,如果直接相减会导致重叠部分消失,如下图所示。
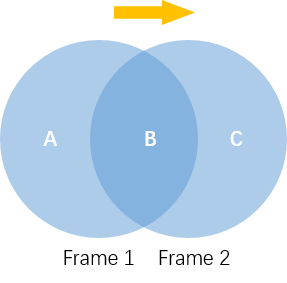 如图所示,蓝色圆形在第一帧和第二帧之间向右移动了。如果直接相减则中间重叠区域B就消失了。
这显然不是我们想要的结果。因此不能直接用相邻帧相减。
但如果非要直接相减,那么相邻帧直接相减代码及效果如下:
如图所示,蓝色圆形在第一帧和第二帧之间向右移动了。如果直接相减则中间重叠区域B就消失了。
这显然不是我们想要的结果。因此不能直接用相邻帧相减。
但如果非要直接相减,那么相邻帧直接相减代码及效果如下:
# coding=utf-8
import cv2
import numpy as np
path = 'E:\\vtest.avi'
cap = cv2.VideoCapture(path)
width = int(cap.get(3))
height = int(cap.get(4))
initial = np.zeros((height, width, 3), np.uint8)
while 1:
ret, frame = cap.read()
if frame is None:
cv2.waitKey(0)
break
else:
# 两帧相减
sub = cv2.subtract(initial, frame)
# 将当前帧赋给循环变量作为上一帧
initial = frame
cv2.imshow('frame', sub)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
相减的某一帧及动图如下。
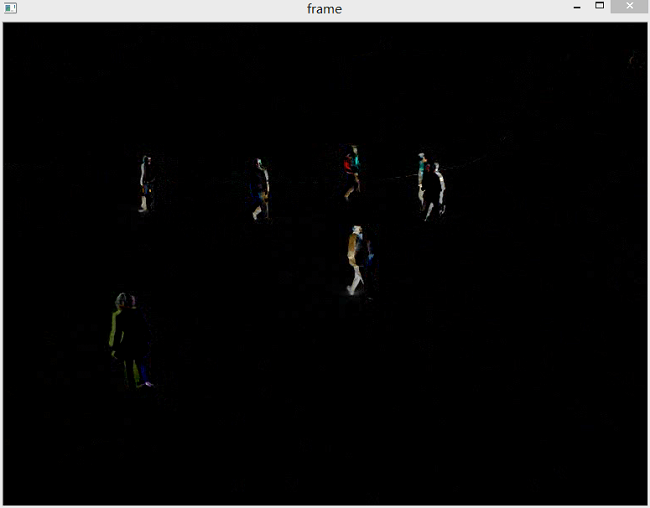
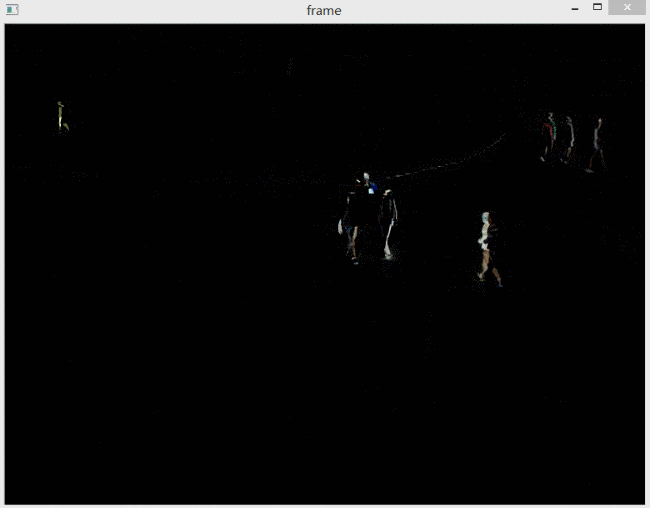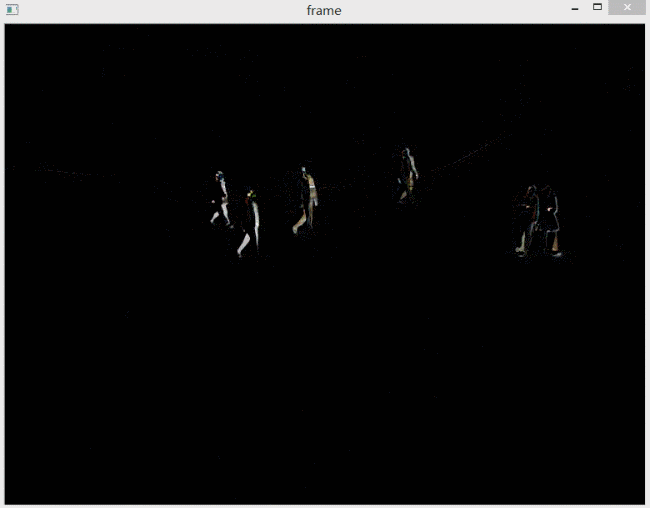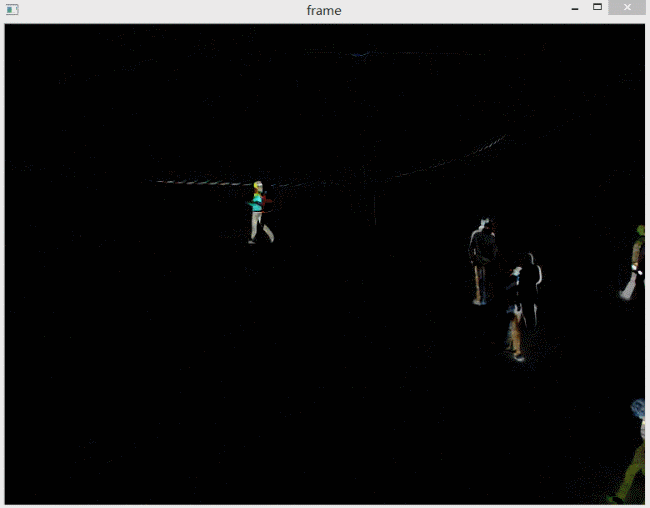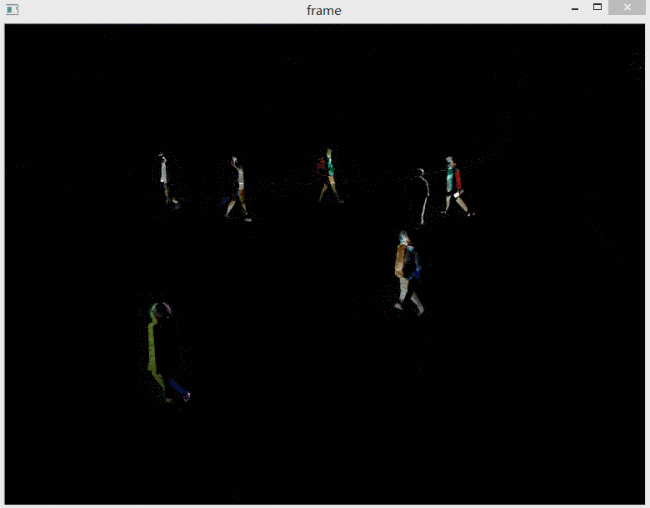 可以看到结果类似于对运动物体提取边缘。这也很好理解。
因为相邻帧相减获取到的是两帧间的差异,而差值正好是物体轮廓的移动量。
因此移动越快,相邻帧差异越大,相减后“轮廓”越粗。
可以看到结果类似于对运动物体提取边缘。这也很好理解。
因为相邻帧相减获取到的是两帧间的差异,而差值正好是物体轮廓的移动量。
因此移动越快,相邻帧差异越大,相减后“轮廓”越粗。
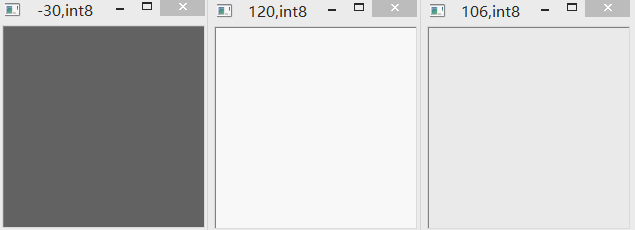
同时还需要注意相减顺序问题,不同相减顺序会导致不同结果。 这是由于OpenCV的减法以及图像数据类型共同造成的。例如50-200,结果应该是-150。 但由于数据类型是uint8,所以自动变为0。如果数据类型是int8,则结果为106。 因为OpenCV的减法是循环的。即相当于从255开始,往下数150个数,254、253…一直到106。 小结一下就是,首先看数据类型,如果不能为负数,直接为0;如果可以为负数,但OpenCV的减法会自动加256,使其变成正数。 所以对于数据类型和范围的问题需要特别注意。有时得不到正确结果很有可能是因为这个问题。
简单来说就是,如果是前一帧减后一帧,差异会出现在运动物体的前方。
如果是后一帧减前一帧,差异会出现在运动物体后方,形成类似“拖影”的效果。
下图分别是前减后和后减前的对比。
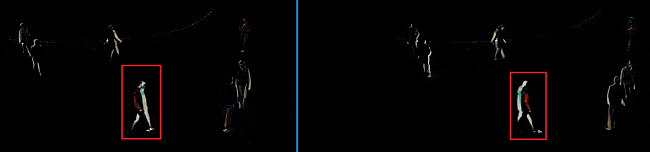 图中的行人是向右走的。左边是前减后的效果,右边是后减前的效果。
因此,简单用相邻帧相减来提取运动目标是不可行的,应该寻找其它办法。
图中的行人是向右走的。左边是前减后的效果,右边是后减前的效果。
因此,简单用相邻帧相减来提取运动目标是不可行的,应该寻找其它办法。
当然如果采用了上面相减取绝对值的办法,可以解决这个问题,90-200和200-90最后的结果都是110。
# coding=utf-8
import cv2
import numpy as np
path = 'E:\\vtest.avi'
cap = cv2.VideoCapture(path)
width = int(cap.get(3))
height = int(cap.get(4))
initial = np.zeros((height, width, 3), np.uint8)
while 1:
ret, frame = cap.read()
if frame is None:
cv2.waitKey(0)
break
else:
# 两帧相减
sub = np.uint8(np.abs(np.int32(initial) - np.int32(frame)))
# 将当前帧赋给循环变量作为上一帧
initial = frame
cv2.imshow('F', sub)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
这样相减顺序也就无所谓了,结果如下所示,是我们想要的结果。但是采用这个方法的计算速度相较于OpenCV的减法会慢很多(10倍左右)。
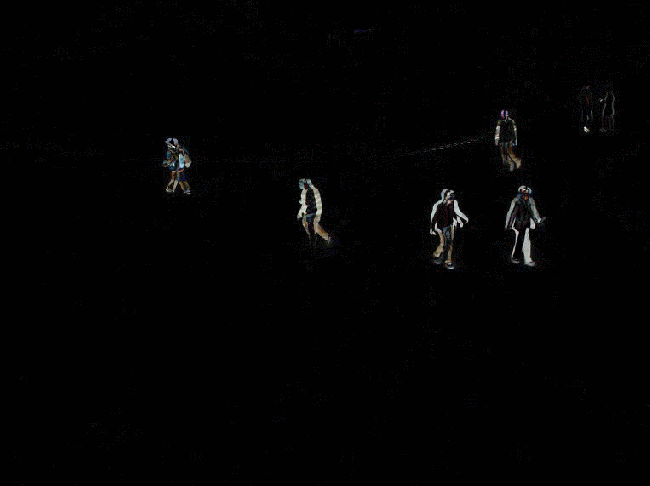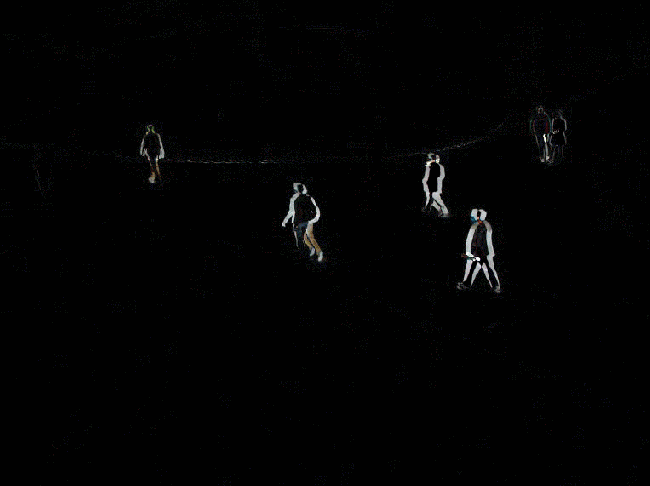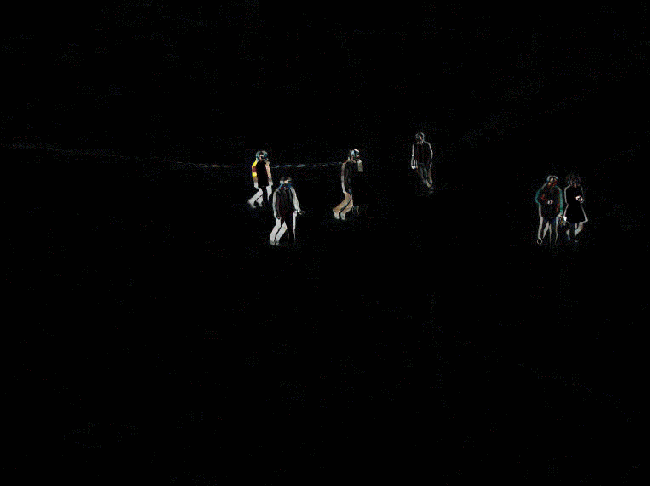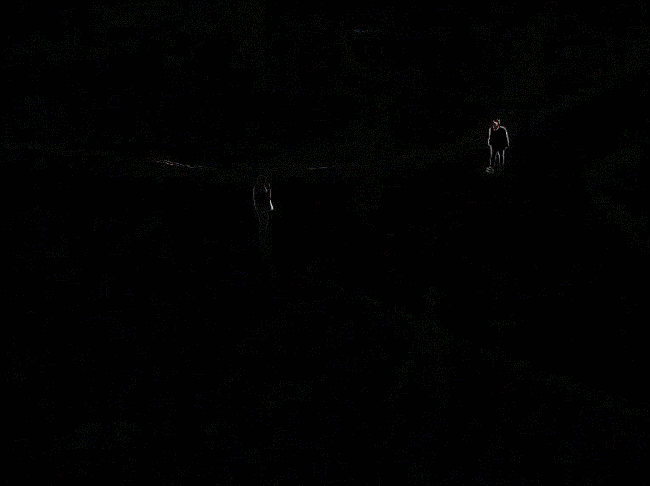 当然,由于我们只对变化像素感兴趣,并不对颜色感兴趣,因此完全可以先将帧图像转成灰度再做减法,这样会少2/3的计算量(在上面的代码中没有这样做)。
帧间差法可以很方便的提取目标在某一帧的范围,这对于后续处理时有帮助的。
当然,由于我们只对变化像素感兴趣,并不对颜色感兴趣,因此完全可以先将帧图像转成灰度再做减法,这样会少2/3的计算量(在上面的代码中没有这样做)。
帧间差法可以很方便的提取目标在某一帧的范围,这对于后续处理时有帮助的。
1.基础
在上面介绍了直接相减法不行后,下面研究如何实现想要的效果。 在很多基础应用中背景检测都是一个非常重要的步骤。 例如顾客统计,使用一个静态摄像头来记录进入和离开房间的人数,或者是交通摄像头,需要提取交通工具的信息等。 在所有的这些例子中,首先要将人或车单独提取出来。 技术上来说,我们需要从静止的背景中提取移动的前景。 如果你有一张背景(仅有背景不含前景)图像,比如没有顾客的房间,没有交通工具的道路等,那就好办了。 我们只需要在新的图像中减去背景就可以得到前景对象了。 但是在大多数情况下,我们没有这样的(背景)图像,所以我们需要从我们有的图像中提取背景。 如果图像中的交通工具还有影子的话,那这个工作就更难了,因为影子也在移动,仅仅使用减法会把影子也当成前景。为了实现这个目的科学家们已经提出了几种算法。 OpenCV中已经包含了几种比较容易使用的方法。
2.OpenCV中的方法
在OpenCV不同版中存在不同的方法。在我的电脑上OpenCV版本是3.2,有MOG2和KNN两种背景减除方法。 但还是按照官方教程顺序介绍各种方法。
(1)BackgroundSubtractorMOG
这是一个以混合高斯模型为基础的前景/背景分割算法。它是P.KadewTraKuPong和R.Bowden在2001年提出的。 它使用K(K=3或5)个高斯分布混合模型对背景像素进行建模。 使用不同颜色(在整个视频中)存在时间的长短作为混合的权重。 背景颜色一般持续的时间最长,而且更加静止。
一个像素怎么会有分布呢?在上面已经说过了,这里增加了时间维。
在x-y平面上一个像素就是一个像素没有分布,但是我们现在讲的背景建模是基于时间序列的,因此每一个像素点所在的位置在整个时间序列中就会有很多值,从而构成一个分布。
在编写代码时,我们需要使用函数:cv2.createBackgroundSubtractorMOG()创建一个背景对象。
这个函数有些可选参数,比如要进行建模场景的时间长度,高斯混合成分的数量,阈值等,可以将他们全部设置为默认值。
然后在整个视频中,使用backgroundsubtractor.apply()就可以得到前景的掩模了。
(2)BackgroundSubtractorMOG2
这个也是以高斯混合模型为基础的背景/前景分割算法。它是以2004年和2006年Z.Zivkovic的两篇文章为基础的。
这个算法的一个特点是它为每一个像素选择一个合适数目的高斯分布。(上一个方法中每一个像素都使用相同且固定的K个高斯分布)。
这样就会对由于亮度等发生变化引起的场景变化产生更好的适应。
和前面一样我们需要创建一个背景对象。但在这里我们我们可以选择是否检测阴影。
如果函数参数中detectShadows = True(默认值),它就会检测并将影子标记出来,但是这样做会降低处理速度。
影子会被标记为灰色。
# coding=utf-8
import cv2
path = 'E:\\vtest.avi'
cap = cv2.VideoCapture(path)
# 新建一个MOG背景减除对象
fgbg = cv2.createBackgroundSubtractorMOG2()
# 新建一个卷积核用于开运算
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
while 1:
ret, frame = cap.read()
if frame is None:
cv2.waitKey(0)
break
else:
# 应用MOG到每一帧,返回结果是动目标的掩膜
fgmask = fgbg.apply(frame)
# 利用开运算进行噪声去除
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)
cv2.imshow('frame', fgmask)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
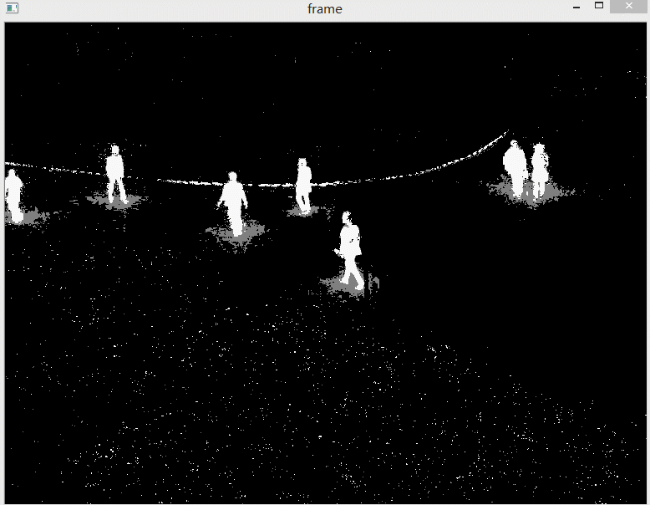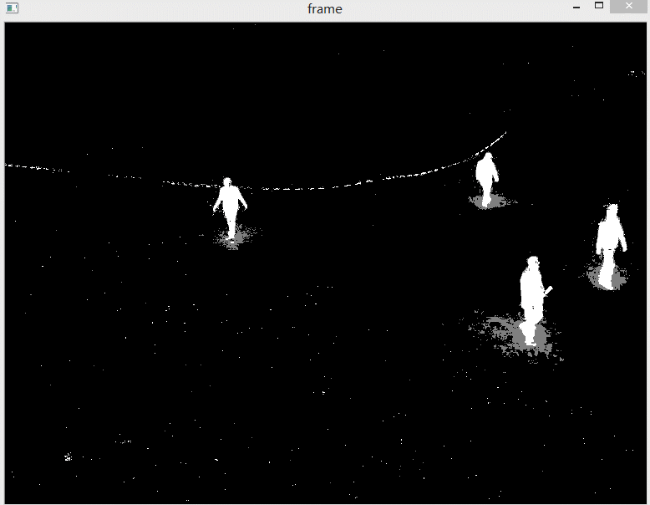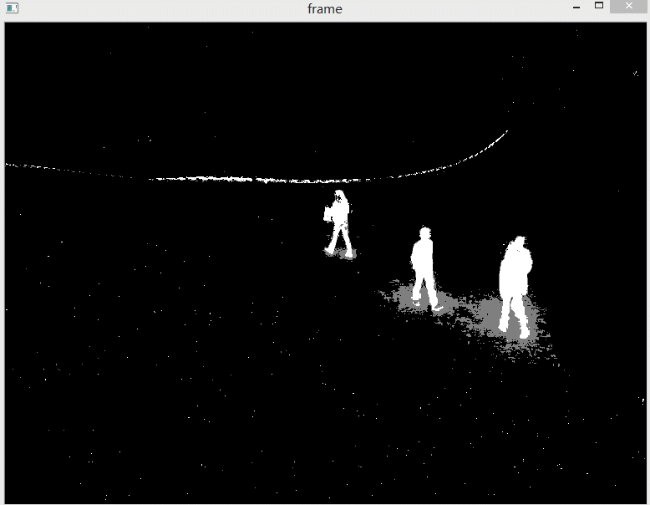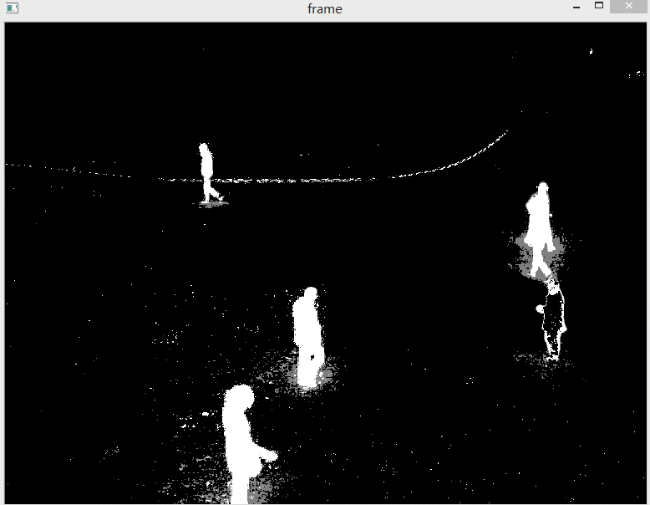
识别的效果如下。灰色区域代表阴影。对结果进行形态学开运算对与去除噪声很有帮助,因此这里使用了形态学开运算对噪声进行去除。
 下图是没有对噪声进行去除的效果。
下图是没有对噪声进行去除的效果。
 下图是设置不检测阴影。注意所谓不检测阴影的含义是,不把阴影用灰色标识出来,并不是说不显示阴影。
阴影还是会被检测出来,但是不和前景物体区分开。
下图是设置不检测阴影。注意所谓不检测阴影的含义是,不把阴影用灰色标识出来,并不是说不显示阴影。
阴影还是会被检测出来,但是不和前景物体区分开。
 如果想去除阴影,其实也很简单,对获得的掩膜进行阈值操作即可。因为检测出的阴影是灰色的,所以设置一个比较高的阈值,如200,然后阈值操作,接收结果即可。下图是不显示阴影的效果。
如果想去除阴影,其实也很简单,对获得的掩膜进行阈值操作即可。因为检测出的阴影是灰色的,所以设置一个比较高的阈值,如200,然后阈值操作,接收结果即可。下图是不显示阴影的效果。
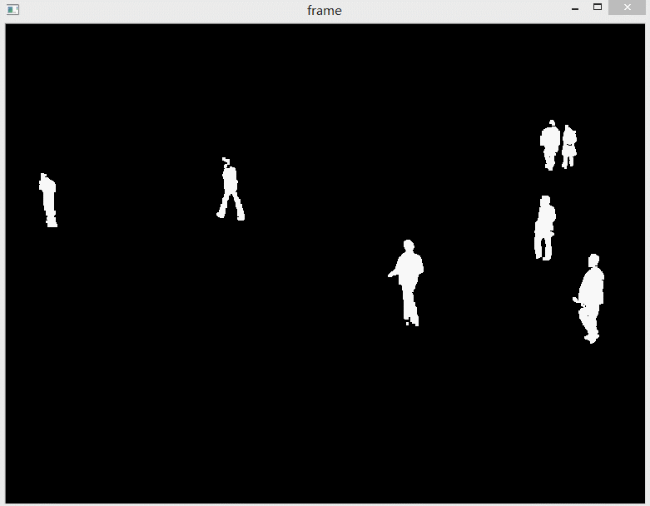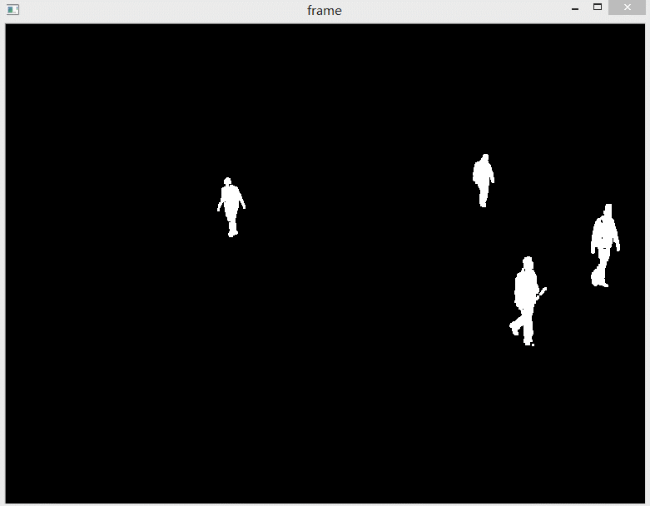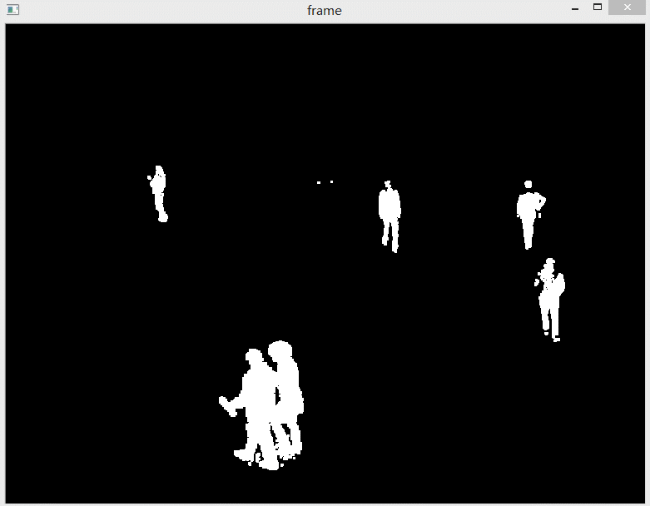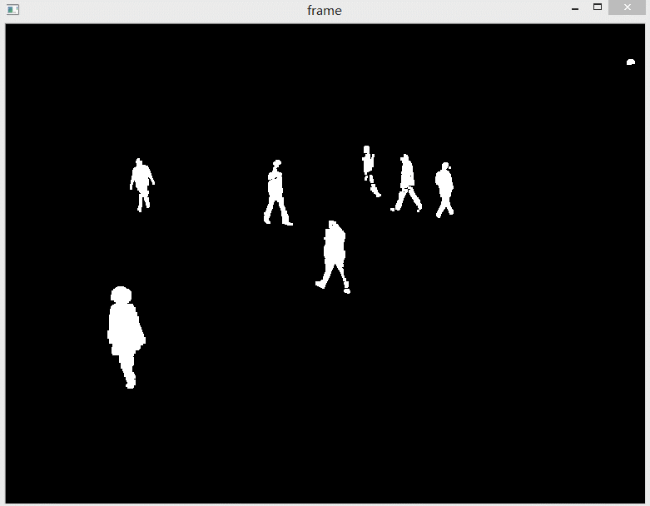 可以看到,效果很好,可以清晰地识别出行人的脚步。
可以看到,效果很好,可以清晰地识别出行人的脚步。
(3)BackgroundSubtractorGMG
此算法结合了静态背景图像估计和每个像素的贝叶斯分割。 这是2012年Andrew B.Godbehere,Akihiro Matsukawa和Ken Goldberg在文章中提出的。 它使用前面很少的图像(默认为前 120 帧)进行背景建模。使用了概率前景估计算法(使用贝叶斯估计鉴定前景)。 这是一种自适应的估计,新观察到的对象比旧的对象具有更高的权重,从而对光照变化产生适应。 一些形态学操作如开运算闭运算等被用来除去不需要的噪音。在前几帧图像中会得到一个黑色窗口。 由于在我的OpenCV中没有这个函数,因此暂时无法测试。
(4)总结对比
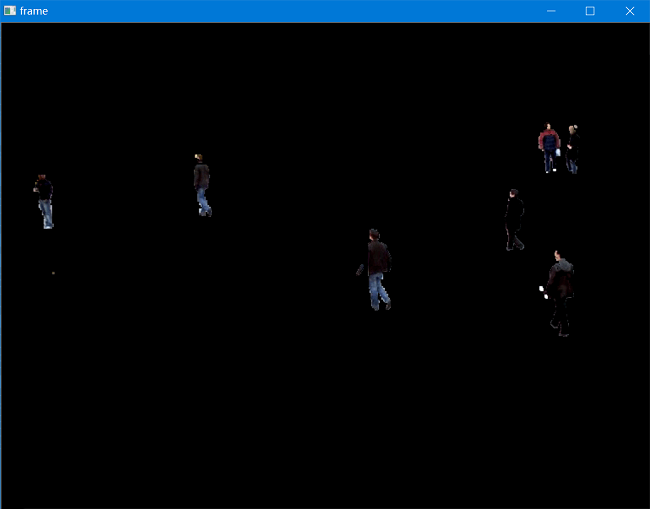
下面是某一帧原图以及使用KNN和MOG2背景减除后影像的对比:


 可以看到两种方法差异不大,只是在部分阴影区域有较小差异。
可以看到两种方法差异不大,只是在部分阴影区域有较小差异。
3.较完善的程序
下面代码实现了比较完善的背景减除功能,并打包成exe以供使用。
# coding=utf-8
import cv2
path = ''
path = raw_input("Path of input video:\n")
output = ''
output = raw_input("Path of output video('None' means don't save):\n")
noiseFilter = 1
noiseFilter = input("Whether use morphological opening to remove noise.0 means no,1 means yes:\n")
showVideo = 1
showVideo = input("Whether show video during processing.0 means no,1 means yes:\n")
outputType = 1
outputType = input("Select type of output video.\n0:mask video\n1:subtraction video\n")
method = 0
method = input("Select method for background subtraction.\n0:MOG2 method\n1:KNN method\n")
subtractMode = 1
subtractMode = input(
"Select mode for subtraction.\n1:Detect shadows and show\n2:Detect shadows and remove\n3:Don't detect shadows\n")
cap = cv2.VideoCapture(path)
width = int(cap.get(3))
height = int(cap.get(4))
total = int(cap.get(7))
count = 0
if method is 0:
if subtractMode is 1 or 2:
fgbg = cv2.createBackgroundSubtractorMOG2()
elif subtractMode is 3:
fgbg = cv2.createBackgroundSubtractorMOG2(detectShadows=False)
elif method is 1:
if subtractMode is 1 or 2:
fgbg = cv2.createBackgroundSubtractorKNN()
elif subtractMode is 3:
fgbg = cv2.createBackgroundSubtractorKNN(detectShadows=False)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
fps = 10
waitTime = 1
if cap.get(5) != 0:
waitTime = int(1000.0 / cap.get(5))
fps = cap.get(5)
if output is not "None":
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter(output, fourcc, fps, (width, height))
while 1:
ret, frame = cap.read()
if frame is None:
cv2.waitKey(0)
break
else:
fgmask = fgbg.apply(frame)
if subtractMode is 2:
ret, fgmask = cv2.threshold(fgmask, 200, 255, cv2.THRESH_BINARY)
if noiseFilter is 1:
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)
if outputType is 1:
dst = cv2.bitwise_and(frame, frame, mask=fgmask)
if showVideo is 1:
cv2.imshow('frame', dst)
if output is not "None":
out.write(dst)
elif outputType is 0:
if showVideo is 1:
cv2.imshow('frame', fgmask)
if output is not "None":
out.write(fgmask)
count += 1
print (count * 1.0 / total) * 100, "% finished."
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
out.release()
cv2.destroyAllWindows()
程序需要输入如下参数。
- 待处理视频路径,如”E:\vtest.avi”
- 输出视频路径,如”C:\output.avi”,”None”代表不输出视频
- 是否使用形态学开运算去除噪声,0-不使用,1-使用
- 是否在处理时显示视频,0-不显示,1-显示
- 输出视频类型,0-掩膜,1-掩膜后的视频内容
- 背景减除算法,0-MOG2,1-KNN
- 减除模式,1-检测并显示阴影,2-检测并去除阴影,3-不检测阴影
测试截图如下所示:
 exe链接:https://pan.baidu.com/s/1jI5NweM 密码:tsnf。
exe链接:https://pan.baidu.com/s/1jI5NweM 密码:tsnf。
四、背景减除方法综述
前面主要介绍了背景减除的具体实现方法。本部分主要介绍其相关算法和原理,部分内容节选修改自这篇博客,如果感兴趣可以了解。
1.简单背景建模方法
简单背景建模方法适用于相对简单的场景。常见的有均值模型、中值模型和直方图模型。 均值模型是先对视频序列中连续的N帧图像的同一位置的像素点累加,然后求均值,并将求得的均值结果作为背景模型。 然后将每一帧与背景进行差分运算,最后将差分运算后的结果进行阈值比较,进而将运动目标与背景分割。该模型可用以下公式描述:
\[B_{t}(i,j)=\frac{1}{N}\sum_{t=0}^{N}I_{t}(i,j)\] \[X_{t}(i,j)=\left\{\begin{matrix} 1,|I_{t}(i,j)-B_{t}(i,j)|>T\\ 0,|I_{t}(i,j)-B_{t}(i,j)|\leq T \end{matrix}\right.\]式中\(B_{t}(i,j)\)表示从0到t时刻对应的背景图像。\(I_{t}(i,j)\)表示t时刻的视频帧。 T表示分割阈值,\(X_{t}(i,j)\)表示t时刻提取出的运动目标的二值图像(掩膜)。
相对于均值模型而言,中值模型、直方图模型仅仅是将背景模型定义为N帧图像的中值和众数,其它没有区别。 简单背景建模算法的优点是原理简单且易于实现。 缺点是由均值、中值、众数获得的背景模型与实际背景相差很多,所以由此背景提取的运动目标就不够精确。 并且该模型没有背景更新机制。此外,由于这种模型的关键是参数N,也就是一共有多少帧,当N值越大时,提取的背景质量越好。 但同时运算时间、内存消耗也会增加。
下面的代码使用均值模型对背景进行了提取。
# coding=utf-8
import cv2
import numpy as np
# 利用简单背景建模法提取背景(均值模型)
cap = cv2.VideoCapture("E:\\vtest.avi")
# 获取视频宽高以及总帧数
width = int(cap.get(3))
height = int(cap.get(4))
total = int(cap.get(7))
# 注意数据类型对应的范围
# 由于各帧相加会得到很大的数,因此先使用int32类型
average = np.zeros((height, width, 3), np.int32)
while cap.isOpened():
ret, frame = cap.read()
if frame is None:
break
else:
cv2.imshow("video", frame)
# 对每一帧进行累加
average += frame
k = cv2.waitKey(30) & 0xFF
if k == 27:
break
# 将累加结果除以总帧数
average = np.uint8(average / total)
cv2.imshow("background", average)
cv2.waitKey(0)
cap.release()
视频中的某帧和提取的背景分别如下:

 可以看到比较好地提取出了视频的背景。这种简单的模型可以用于拍照时对行人进行去除等应用领域。
通过一次性拍摄多张照片形成多张影像,最后利用均值模型即可对不想要的行人进行去除。
可以看到比较好地提取出了视频的背景。这种简单的模型可以用于拍照时对行人进行去除等应用领域。
通过一次性拍摄多张照片形成多张影像,最后利用均值模型即可对不想要的行人进行去除。
下面的代码实现了均值模型提取运动目标。
# coding=utf-8
import cv2
import numpy as np
# 利用简单背景建模法提取前景(均值模型)
cap = cv2.VideoCapture("E:\\vtest.avi")
# 获取视频宽高以及总帧数
width = int(cap.get(3))
height = int(cap.get(4))
total = int(cap.get(7))
count = 0
# 注意数据类型对应的范围
# 由于各帧相加会得到很大的数,因此先使用int32类型
average = np.zeros((height, width, 3), np.int32)
while cap.isOpened():
ret, frame = cap.read()
if frame is None:
break
else:
count += 1
print (count * 1.0 / total) * 100, '%'
# 对每一帧进行累加
average += frame
k = cv2.waitKey(30) & 0xFF
if k == 27:
break
# 将累加结果除以总帧数
average = average / total
cap.release()
# 重新打开视频进行前景提取
cap2 = cv2.VideoCapture("E:\\vtest.avi")
while cap2.isOpened():
ret, frame = cap2.read()
if frame is None:
cv2.waitKey(0)
break
else:
# 每一帧与背景相减
# 注意这里不要使用OpenCV的减法,因为数据类型不同
# 首先将两帧相减,得到int32型的数据,然后再取绝对值,再化为uint8
foreground_mask = np.uint8(np.abs(frame - average))
# 对前景掩膜灰度化然后再二值化得到最终掩膜
foreground_mask = cv2.cvtColor(foreground_mask, cv2.COLOR_BGR2GRAY)
ret, foreground_mask = cv2.threshold(foreground_mask, 40, 255, cv2.THRESH_BINARY)
# 与每一帧进行与操作,获取内容
foreground = cv2.bitwise_and(frame, frame, mask=foreground_mask)
cv2.imshow("thresh=40", foreground)
k = cv2.waitKey(30) & 0xFF
if k == 27:
break
cap2.release()
可以看到,总体效果还不错。
同时由于算法是将每一帧与背景相减,因此当运动物体与背景颜色相近时,有可能造成物体的缺失和不完整。
要使物体尽可能完整,就需要选择合适的阈值,所以提取效果与阈值T的选择有很大关系。
如下图所示是不同阈值对提取结果的影响。
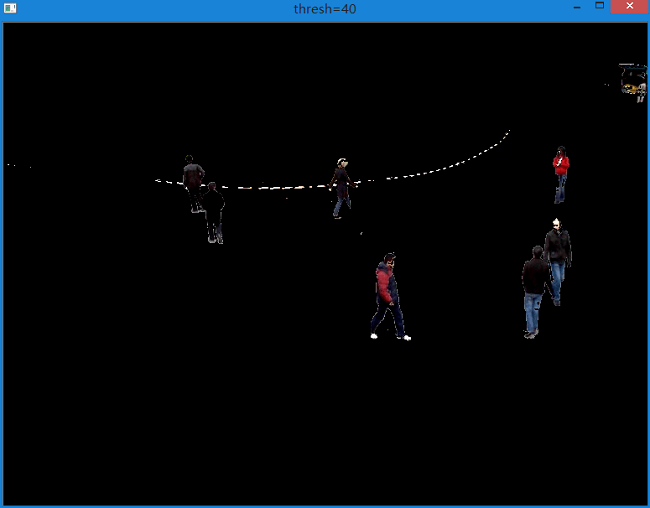
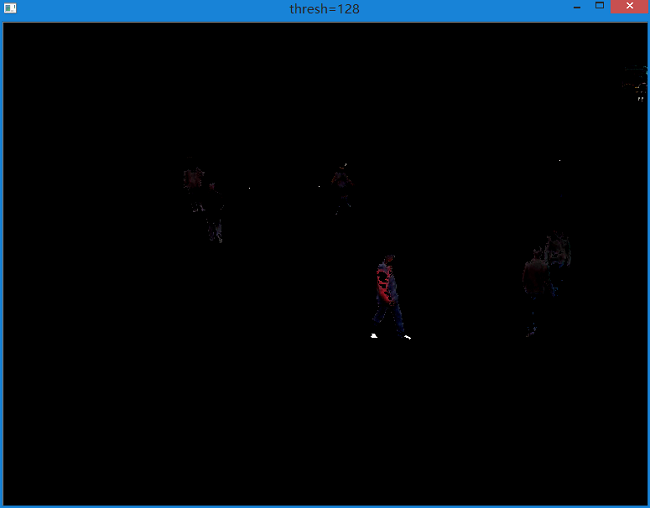
可以看到差别很大。
2.基于统计的背景建模方法
(1)高斯模型(Gaussian Mixture Model,GMM)
最初提出的是单高斯模型。该模型能够较好地适应略微复杂的场景,对于一些干扰也具有一定的鲁棒性,如缓慢光线变化、噪声等。 对于复杂多变的场景,单高斯模型的效果就不太理想,如晃动的树枝、波动的水面等。 所以可以采用混合高斯模型完成运动目标提取。
在混合高斯背景模型中,认为像素之间的颜色信息互不相关,对各像素点的处理都是相互独立的。 对于视频图像中的每一个像素点,其值在序列图像中的变化可看作是不断产生像素值的随机过程, 即用高斯分布来描述每个像素点的颜色呈现规律。 混合高斯背景建模的核心思想是采用K个不同的高斯函数来描述视频图像序列中每一个像素点的值, 然后对K个高斯函数按照优先级进行排序,并用前B个高斯函数代表实际的背景模型。 然后通过匹配的高斯函数的序号与B相比来判断该像素点是背景还是前景。
a.模型初始化
假设每个像素在时间上的分布都用K个高斯函数描述,第k个高斯函数的权重为ωk,那么在t时刻,背景像素Xt的高斯模型可表述为:
\[P(X_{t})=\sum_{k=1}^{K}\omega _{k}\cdot \eta (X_{t},\mu _{k},\sum_{ }{ }_{k})\]其中:
\[\eta (X_{t},\mu _{k},\sum_{ }{ }_{k})=\frac{1}{|\sum_{ }{ }_{k}|^{\frac{1}{2}}}e^{-\frac{1}{2}(x-\mu _{k})^{T}\sum_{ }{ }_{k}^{-1}(x-\mu _{k})}\\ \sum_{ }{ }_{k}=\sigma _{k}^{2}I\]其中K为使用的高斯函数总数,\(\eta (X_{t},\mu _{k},\sum_{ }{ }_{k})\)表示t时刻第k个高斯分布。 \(\mu _{k}\)为其均值,\(\sum_{ }{ }_{k}\)为其协方差矩阵,\(\sigma _{k}\)为其方差,I为三维单位阵。 \(\omega _{k}\)为t时刻第k个高斯分布的权重。
使用上述模型对背景进行建模后,背景的每一个像素值就可以通过一个高斯序列来描述了,其中每个高斯函数都有权重\(\omega _{k}\)。 K一般取值在3-5之间,K越大,算法处理波动的能力越强,抗噪性越好,背景建模效果更加稳定。 但同时,计算量也会增加,建模速度会变慢。
b.目标检测
高斯函数序列要求按照权重比(ωk/σ)进行排序。这样取前B个权重之和大于阈值T的高斯函数来描述实际的背景模型。 后面的高斯函数由于权重太低,被认为是无效模型。B使用数学语言描述如下:
\[B=arg(min(\sum_{j=1}^{b}\omega _{j}>T))\]对于新时刻N的像素值\(X_{N}\)而言,按顺序遍历表示背景的高斯模型序列。当第一个满足下面公式的高斯模型为第k个,且k<B,即认为该点是前景,否则为背景。
\[|X_{N}-\mu _{k}|<2.5\sigma _{k}\]c.参数更新
对匹配的高斯模型,也就是第一个满足上式的高斯模型进行如下参数更新。
\[\omega _{k}^{'}=(1-\alpha)\omega_{k}+\alpha\rho \\ \mu_{k}^{'}=(1-\rho)\mu_{k}+\rho X_{t}\\ \sigma_{k}^{2^{'}}=(1-\rho)\sigma_{k}^{2}+\rho(X_{t}-\mu_{k})^{T}(X_{t}-\mu_{k})\]其中α为学习率,\(\rho=\alpha\eta (X_{t};\mu_{k};\sum_{}{}_{k})\)。
(2)无参估计法
高斯模型是一种基于参数估计的统计学背景减除法,这种方法假定背景像素点的值符合高斯分布。 通过统计不同帧的像素值分布对模型的参数进行估计,然后构建背景模型。再将每一帧内容与背景进行差分,进而提取运动目标。 而无参估计背景减除法,不需要假定潜在的模型,也不需要顾及模型的参数。 经典方法有:ViBe、PBAS、KDE、GMG等。这里简单介绍。
a.ViBe
在ViBe模型中,背景模型的每个不同位置由n个背景样本组成。一般地,n=20。记V(i,j)为(i,j)点处的像素值。 M(i,j)={V1,V2,V3,…,Vn}为(i,j)处的背景样本集。模型的初始化就是选取Vi的过程。 ViBe模型通过欧氏距离进行前景与背景的分割。记Sr(V(i,j))表示以V(i,j)为圆心,半径为r的二维空间范围。 当Sr(V(i,j))与M(i,j)交集的样本个数,小于一定数值min,则V(i,j)就属于背景。一般地,取min=2,r=20。
b.KDE
核密度估计(KDE)方法是读取历史样本数据,当样本数量足够多,质量足够好时,由该点的核密度估计可以直接得到该点的实际概率密度。 因此此方法适用于分布未知的问题。但其计算量较大,实时性不好,检测准确度一般,在某些情况下会发生拖影现象。
(3)纹理特征法
基于LBP的背景建模法特点是不再选取像素值作为特征,而是选择LBP纹理特征,进而采用多个这样的特征及权重来描述背景模型,从而提取运动目标。 LBP纹理描述子计算相对简单,所依赖参数较少,对阴影有很好的鲁棒性。 其最大缺点在于计算纹理需要花费很多时间,所以这种方法实时性不好。
(4)子空间学习法
传统像素级、区域级的运动目标检测算法都没有考虑到相邻帧之间的空间相关性。 因此Oliver等人提出了一种以帧为特征的背景减除法,并将子空间学习理论应用于背景建模,以降低空间维度。 模型的核心思想是:对连续帧视频图像的特征向量进行主成分分析,由于特征子空间能够较好地代表背景部分的特征, 所以可以通过特征子空间来建立背景模型,进而提取运动目标。该方法最大的缺点是没有考虑背景的实时更新,同时计算量大,实时性不好。
3.基于聚类的背景建模法
CodeBook算法是一种经典的基于聚类的背景建模方法。该算法从一长串视频序列中建立背景模型,并为每个像素建立一个包含一个或多个码字的CodeBook。 码字中存放着每个像素的色彩失真量和亮度区间。通过色彩失真量和亮度区间来区分背景和前景。
4.基于自组织神经网络的背景建模法
SOBS是一种基于自组织神经网络的背景减除算法。该方法将视频帧映射成一幅神经网络背景模型图,并考虑了相邻像素间的空间相关性。 此外,该方法选择HSV颜色空间进行建模,由于它能很好地分离亮度和色调信息,这使得运动检测结果不受光线影响。
5.基于模糊理论的背景建模法
根据模糊理论的不同,该方法分为传统模糊背景建模和二型模糊背景建模两类。 传统模糊背景建模是利用隶属度值将精确集合中的元素模糊化。 二型模糊背景建模利用集合中元素隶属度值的模糊程度理论,进一步增强了描述集合的模糊性。
6.背景预测法
背景预测法是指使用滤波器对将来的背景值进行预测的方法,典型的滤波器有:Wiener滤波器、Kalman滤波器。 基本思想是根据信号的过去值对当前值作尽可能接近真值的估计。 如果预测值与实际值相差较大,那么就将该点判断为运动前景。 Kalman滤波器要求已知状态方程和观测方程,而基于Kalman滤波器的背景建模只需利用状态方程来估计背景模型,然后使用背景差分得到运动目标。 该方法的有点是能够较快的检测出背景中轻微的变化,也能适应缓慢光照变化的场景。 但检测的精确度不够好,常常会出现拖影的问题。
7.各类方法比较

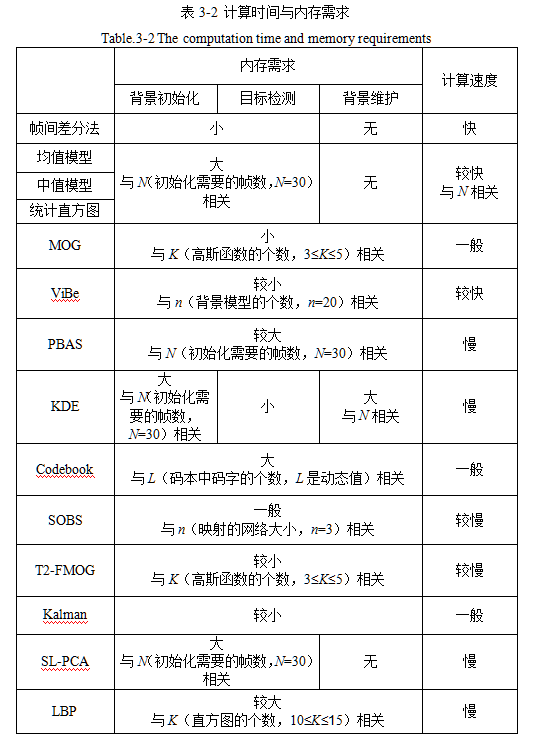
本文作者原创,未经许可不得转载,谢谢配合
