这篇博客主要介绍利用PyTorch实现卷积神经网络的相关内容,同时介绍利用CUDA进行加速的方法。
1.CNN网络
直接放代码,如下。
import torch
import torchvision
import torch.utils.data as Data
import torch.nn as nn
from matplotlib import pyplot as plt
import time
# 超参数
BATCH_SIZE = 50
LEARNING_RATE = 0.001
EPOCH_NUM = 3
# 数据准备
# torchvision中有MNIST下载相关函数,可以直接调用
train_data = torchvision.datasets.MNIST(
root='./mnist', # root为下载数据的存放路径
train=True, # 是否是训练数据,True是训练数据,False是测试数据
transform=torchvision.transforms.ToTensor(), # 将数据转换成Tensor格式
download=True # 是否下载数据,True下载,False不下载
)
# 下载测试数据
test_data = torchvision.datasets.MNIST(root='./mnist', train=False)
# DataLoader配置
train_loader = Data.DataLoader(
dataset=train_data, # 设置数据集
batch_size=BATCH_SIZE, # 设置batch size
shuffle=True # 设置是否随机顺序,True随机,False不随机
)
# 对测试数据进行处理,解析出x、y
# unsqueeze()是squeeze()的反向操作,用于增加指定的维度
# 首先获取到测试数据,然后给数据增加一个维度(dim=1),然后将数据类型转换成FLoatTensor,再取前2000个,最后对数据进行归一化
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000] / 255.
test_y = test_data.test_labels[:2000]
# 网络构建
class CNN(nn.Module):
def __init__(self):
# 注意不要忘了继承父类的初始化函数
super(CNN, self).__init__()
# 快速搭建模式,一个完整的卷积层包括卷积层+激活函数+池化层
self.conv1 = nn.Sequential(
# 卷积层
nn.Conv2d(
in_channels=1, # 输入为灰度图像,所以通道数为1
out_channels=16, # 卷积输出通道为16,可以理解为用16个不同卷积核进行卷积得到16个结果
kernel_size=5, # 卷积核大小
stride=1, # 卷积步长
padding=2 # 卷积边缘设置,(kernel-1)/2
),
# 激活函数
nn.ReLU(),
# 池化层
nn.MaxPool2d(kernel_size=2)
)
# 第二层卷积层
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=16, # 上一卷积层输出channel是16,所以这里输入为16
out_channels=32, # 输出通道为32
kernel_size=5,
stride=1,
padding=2
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
# 线性输出层,由于原图大小是28,经过两次卷积核为2的池化,最后图片大小为7*7,且有32个通道,所以共有32 * 7 * 7个输出,线性映射到10个分类上
self.out = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
conv1_res = self.conv1(x)
conv2_res = self.conv2(conv1_res)
# view()函数作用是将一个多行的Tensor,拼接成一行
out = conv2_res.view(conv2_res.size(0), -1)
output = self.out(out)
return output
# 网络新建与训练
cnn = CNN()
print(cnn)
# 采用Adam优化算法、交叉熵作为损失函数
optimizer = torch.optim.Adam(cnn.parameters(), lr=LEARNING_RATE)
loss_func = nn.CrossEntropyLoss()
# 创建用于存放绘图数据的list
step_list = []
loss_list = []
accuracy_list = []
counter = 0
t1 = time.time()
for epoch in range(EPOCH_NUM):
# enumerate用于对一个可迭代对象返回索引值+内容
for step, (b_x, b_y) in enumerate(train_loader):
predict_y = cnn(b_x)
loss = loss_func(predict_y, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 用于记录步骤数
counter += 1
# 可视化代码
if step % 25 == 0:
test_output = cnn(test_x) # 获取网络输出结果
pred_y = torch.max(test_output, 1)[1].data.squeeze().numpy() # 获取预测的y
accuracy = float(torch.sum(pred_y == test_y)) / float(test_y.size(0)) # 计算精度
print('epoch:', epoch, '|step:%4d' % step, '|loss:%6f' % loss.data.numpy(), '|accuracy:%4f' % accuracy)
# 添加数据到list
step_list.append(counter)
loss_list.append(loss.data.numpy())
accuracy_list.append(accuracy)
# 绘图
plt.cla()
plt.plot(step_list, loss_list, c='red', label='loss')
plt.plot(step_list, accuracy_list, c='blue', label='accuracy')
plt.legend(loc='best')
plt.pause(0.1)
t2 = time.time()
print(t2 - t1)
这里我们建立了有两个隐层的神经网络用于处理图像。整体框架和之前拟合、分类的相同。
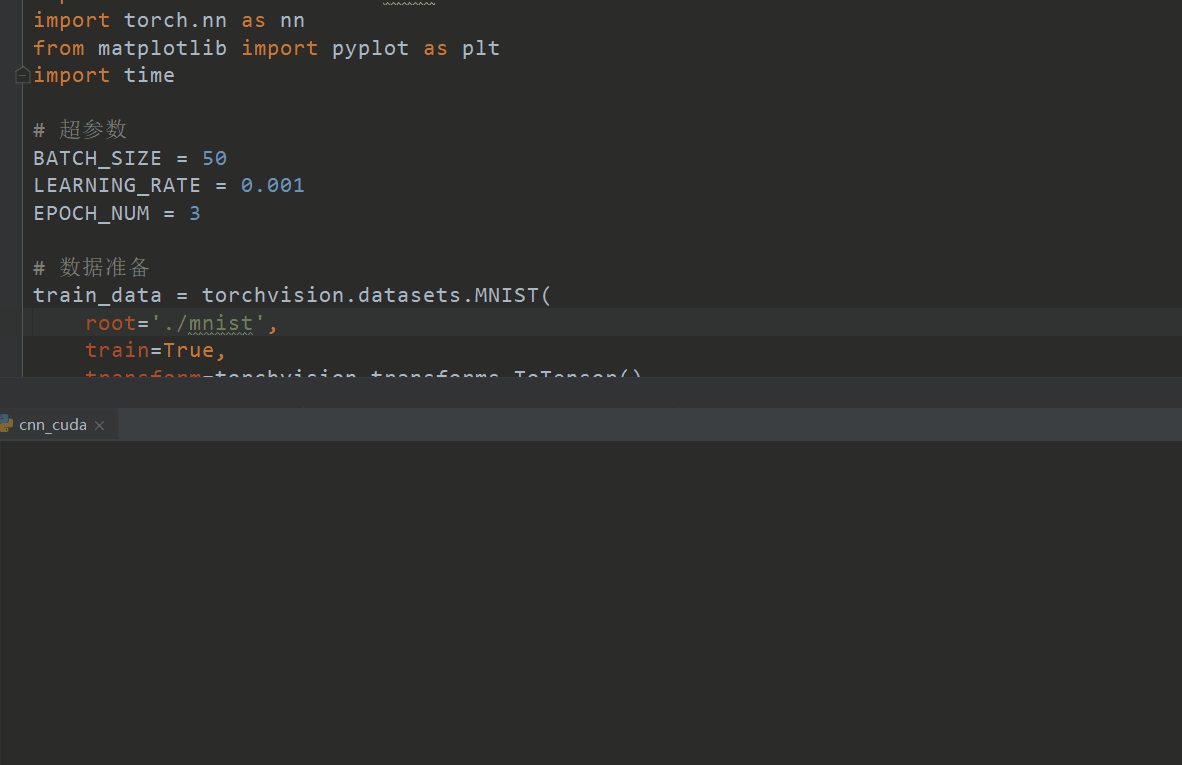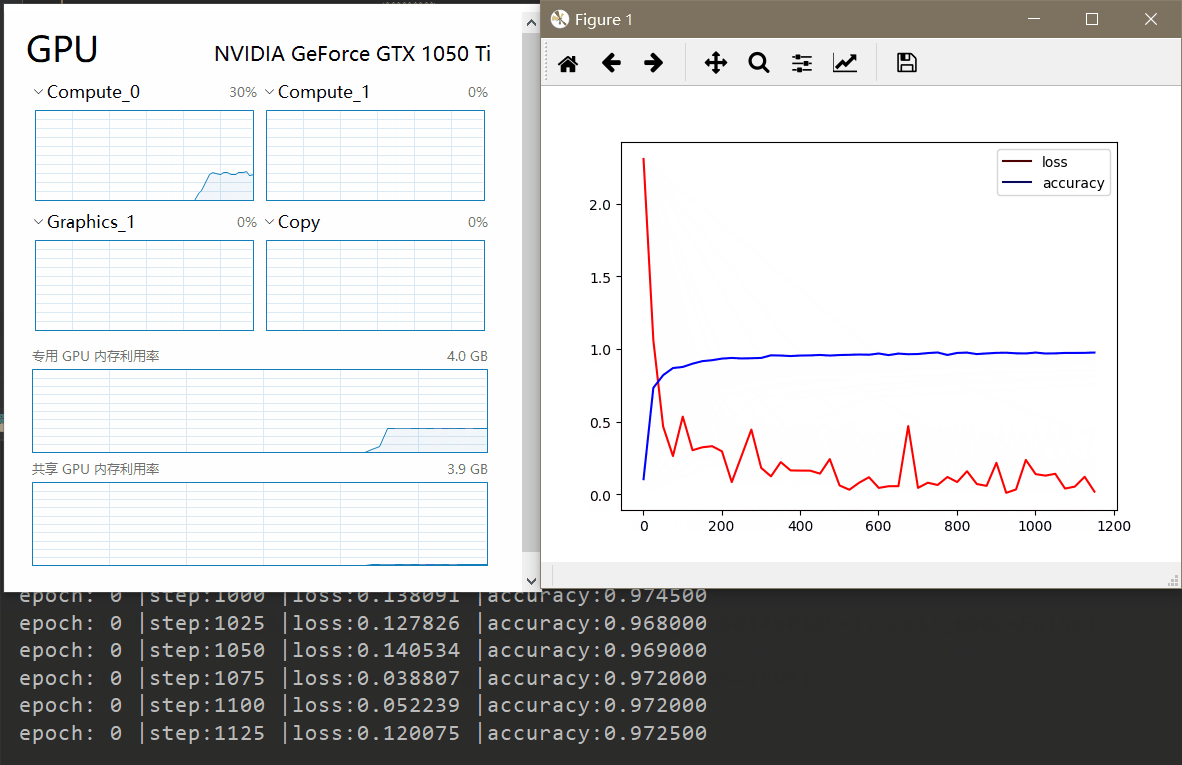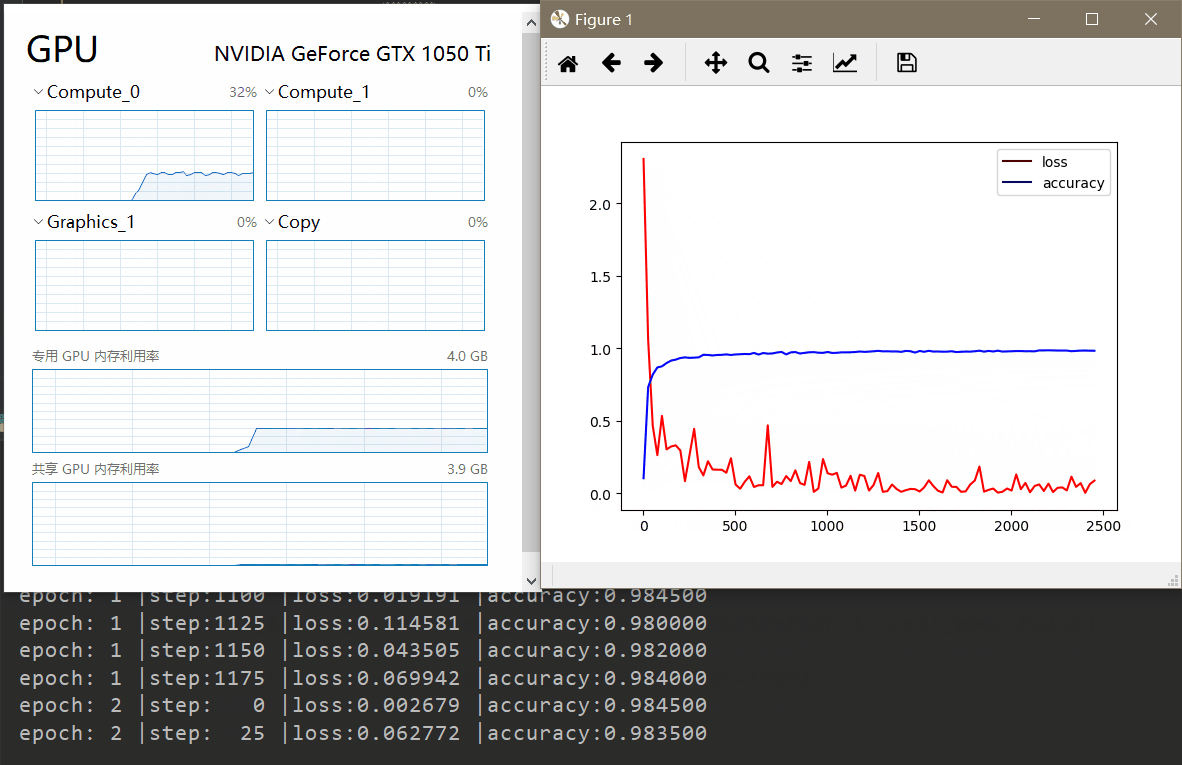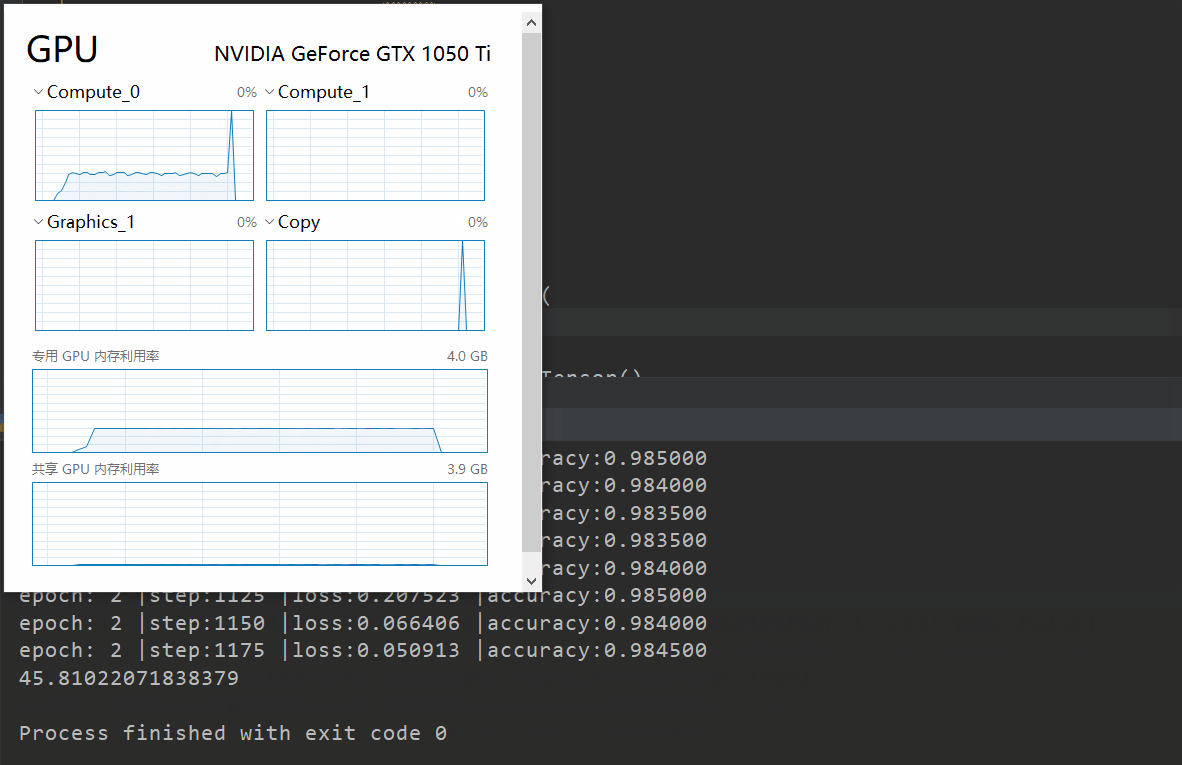
在数据获取部分,利用了torchvision模块进行获取与预处理。模型训练效果如下。
由于过程比较慢,所以进行了一定的加速。单纯利用CPU训练耗时300秒左右。
2.CUDA加速
之前说过,PyTorch本身就是支持CUDA加速的。而将普通的CPU版本代码改成GPU版本也非常简单,如下所示。
import torch
import torchvision
import torch.utils.data as Data
import torch.nn as nn
from matplotlib import pyplot as plt
import time
# 超参数
BATCH_SIZE = 50
LEARNING_RATE = 0.001
EPOCH_NUM = 3
# 数据准备
train_data = torchvision.datasets.MNIST(
root='./mnist',
train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
test_data = torchvision.datasets.MNIST(root='./mnist', train=False)
train_loader = Data.DataLoader(
dataset=train_data,
batch_size=BATCH_SIZE,
shuffle=True
)
# 修改1:将数据改成CUDA可识别的格式
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000].cuda() / 255.
test_y = test_data.test_labels[:2000].cuda()
# 网络构建
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=1,
out_channels=16,
kernel_size=5,
stride=1,
padding=2
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=16,
out_channels=32,
kernel_size=5,
stride=1,
padding=2
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.out = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
conv1_res = self.conv1(x)
conv2_res = self.conv2(conv1_res)
out = conv2_res.view(conv2_res.size(0), -1)
output = self.out(out)
return output
# 网络新建与训练
cnn = CNN()
# 修改2:给网络设置cuda
cnn.cuda()
print(cnn)
optimizer = torch.optim.Adam(cnn.parameters(), lr=LEARNING_RATE)
loss_func = nn.CrossEntropyLoss()
step_list = []
loss_list = []
accuracy_list = []
counter = 0
t1 = time.time()
for epoch in range(EPOCH_NUM):
for step, (b_x, b_y) in enumerate(train_loader):
# 修改3:将数据转换成CUDA可识别的格式
predict_y = cnn(b_x.cuda())
loss = loss_func(predict_y, b_y.cuda())
optimizer.zero_grad()
loss.backward()
optimizer.step()
counter += 1
# 可视化代码
if step % 25 == 0:
test_output = cnn(test_x)
# 修改4:将数据转换成CUDA可识别的格式
pred_y = torch.max(test_output, 1)[1].data.squeeze()
accuracy = float(torch.sum(pred_y == test_y)) / float(test_y.size(0))
# 修改5:将数据转换成Python可识别的格式
print('epoch:', epoch, '|step:%4d' % step, '|loss:%6f' % loss.data.cpu(), '|accuracy:%4f' % accuracy)
step_list.append(counter)
loss_list.append(loss.data.cpu())
accuracy_list.append(accuracy)
plt.cla()
plt.plot(step_list, loss_list, c='red', label='loss')
plt.plot(step_list, accuracy_list, c='blue', label='accuracy')
plt.legend(loc='best')
plt.pause(0.1)
t2 = time.time()
print(t2 - t1)
主要修改的就是数据类型,把输入数据都通过.cuda()修改成GPU能接受的类型,同时对于一些需要输出的数据通过.cpu()转换成CPU能识别的类型。
同时在网络中加一句cnn.cuda()指定开启CUDA加速即可。整体来说非常简单。而且使用GPU加速后效果非常明显。
上面同样的网络在我电脑上GPU只需要50秒左右,而CPU版本需要300秒左右。训练过程如下。
本文作者原创,未经许可不得转载,谢谢配合
