在之前说过了视频卫星凝视成像模式下的不同帧之间的重采与稳像,可以参考这篇博客。 这里再介绍个类似的成像模式,即面阵推扫。与凝视模式相比,面阵推扫并不凝视某一个区域不动,而是随着卫星的运动拍摄星下地表的样子。 面阵推扫与线阵推扫是类似的。 在本篇博客中,介绍一轨数据中不同面阵影像间的关系以及拼接的原理与方法,最后利用代码实现多个面阵影像的拼接,得到完整的一轨数据。
1.拼接原理与思路
和之前视频帧稳像类似,这里主要也是用到相邻面阵影像间重叠部分,通过提取特征点、匹配,进而可以得到两个面阵影像间的仿射变换关系,再基于这个变换关系将影像重采即可。 重复上述操作,即可实现一整个条带的拼接。
2.实现代码
整个过程的原理比较简单,下面直接放上代码,通过代码更加细致地了解过程。
# coding=utf-8
import cv2
import os
import numpy as np
import argparse
import time
# 搜寻文件
def findAllFiles(root_dir, filter):
print("Finding files ends with \'" + filter + "\' ...")
separator = os.path.sep
paths = []
names = []
files = []
for parent, dirname, filenames in os.walk(root_dir):
for filename in filenames:
if filename.endswith(filter):
paths.append(parent + separator)
names.append(filename)
for i in range(paths.__len__()):
files.append(paths[i] + names[i])
print (names.__len__().__str__() + " files have been found.")
paths.sort()
names.sort()
files.sort()
return paths, names, files
# 获取特征点
def getKeyPoints(img1, img2, flag='sift'):
good_matches = []
good_kps1 = []
good_kps2 = []
good_out = []
good_out_kp1 = []
good_out_kp2 = []
if flag == 'sift':
sift = cv2.xfeatures2d_SIFT.create()
kp1, des1 = cv2.xfeatures2d_SIFT.detectAndCompute(sift, img1, None)
kp2, des2 = cv2.xfeatures2d_SIFT.detectAndCompute(sift, img2, None)
elif flag == 'surf':
surf = cv2.xfeatures2d_SURF.create()
kp1, des1 = cv2.xfeatures2d_SURF.detectAndCompute(surf, img1, None)
kp2, des2 = cv2.xfeatures2d_SURf.detectAndCompute(surf, img2, None)
# FLANN parameters
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50) # or pass empty dictionary
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
# 筛选
for i, (m, n) in enumerate(matches):
if m.distance < 0.5 * n.distance:
good_matches.append(matches[i])
good_kps1.append(kp1[matches[i][0].queryIdx])
good_kps2.append(kp2[matches[i][0].trainIdx])
print(
"kp1:" + kp1.__len__().__str__() + ",kp2:" + kp2.__len__().__str__() + ",good matches:" + good_matches.__len__().__str__())
for i in range(good_kps1.__len__()):
good_out_kp1.append([good_kps1[i].pt[0], good_kps1[i].pt[1]])
good_out_kp2.append([good_kps2[i].pt[0], good_kps2[i].pt[1]])
good_out.append([good_kps1[i].pt[0], good_kps1[i].pt[1], good_kps2[i].pt[0], good_kps2[i].pt[1]])
return good_out_kp1, good_out_kp2, good_out
# 影像透明叠加
def transparentOverlay(img1, img2):
ret, mask = cv2.threshold(cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY), 10, 255, cv2.THRESH_BINARY)
mask_inv = cv2.bitwise_not(mask)
img1_bg = cv2.bitwise_and(img1,
img1,
mask=mask)
img1_fg = cv2.bitwise_and(img2[:img1.shape[0], :img1.shape[1], :],
img2[:img1.shape[0], :img1.shape[1], :],
mask=mask_inv)
dst = cv2.add(img1_bg, img1_fg)
return dst
parser = argparse.ArgumentParser(description='Arguments for program.')
parser.add_argument('-input', default='.', help='Input directory for images.')
parser.add_argument('-type', default='jpg', help='File type of input images.')
parser.add_argument('-output', default='.', help='Output directory for result.')
parser.add_argument('-offX', default='300', help='Offset pixels in x direction.')
parser.add_argument('-offY', default='9000', help='Offset pixels in y direction.')
parser.add_argument('-autoCut', default='1', help='1 - cut the blank part of image;0 - keep the blank part.')
parser.add_argument('-every', default='1', help='1 - output every result for images;0 - only output the final result.')
parser.add_argument('-feature', default='sift', help='sift - sift features;surf - surf features.')
args = parser.parse_args()
# 寻找影像文件
paths, names, files = findAllFiles(args.input, args.type)
# 打开影像文件并存放于list中
imgs = []
for item in files:
imgs.append(cv2.imread(item))
height = imgs[0].shape[0]
width = imgs[0].shape[1]
OFFSET_Y = int(args.offY)
OFFSET_X = int(args.offX)
total_height = height + OFFSET_Y
total_width = width + OFFSET_X
out = np.zeros([total_height, total_width, 3], np.uint8)
sum_offset_y = 0
sum_offset_x = 0
# 对影像两两进行匹配重采
t1 = time.time()
for i in range(imgs.__len__() - 1):
if i == 0:
print "\nFrame " + (i + 1).__str__() + "/" + imgs.__len__().__str__()
good_out_kp1, good_out_kp2, good_out = getKeyPoints(imgs[i + 1], imgs[i], args.feature)
affine_matrix, mask = cv2.estimateAffine2D(np.array(good_out_kp1), np.array(good_out_kp2))
print affine_matrix
tmp_img = cv2.warpAffine(imgs[i + 1],
affine_matrix,
(total_width, total_height),
borderMode=cv2.BORDER_TRANSPARENT)
out[:height, :width, :] = imgs[0]
if args.every == '1':
cv2.imwrite(args.output + os.path.sep + i.__str__().zfill(3) + ".jpg", out)
else:
print "\nFrame " + (i + 1).__str__() + "/" + imgs.__len__().__str__()
good_out_kp1, good_out_kp2, good_out = getKeyPoints(imgs[i + 1], tmp_img, args.feature)
affine_matrix, mask = cv2.estimateAffine2D(np.array(good_out_kp1), np.array(good_out_kp2))
print affine_matrix
sum_offset_x = affine_matrix[0][2]
sum_offset_y = affine_matrix[1][2]
tmp_img = cv2.warpAffine(imgs[i + 1],
affine_matrix,
(total_width, total_height),
borderMode=cv2.BORDER_TRANSPARENT)
out = transparentOverlay(out, tmp_img)
if args.every == '1':
cv2.imwrite(args.output + os.path.sep + i.__str__().zfill(3) + ".jpg", out)
# 保存结果
if args.autoCut == '1':
out = out[:height + int(sum_offset_y), :width + int(sum_offset_x), :]
elif args.autuCut == '0':
out = out
cv2.imwrite(args.output + os.path.sep + "out.jpg", out)
t2 = time.time()
print "\ncost time:" + (t2 - t1).__str__() + " s"
对于代码中一些地方简单介绍,如下。
(1)argparse模块
如果看过我之前的代码应该会知道,我一般会用sys.argv来进行启动参数传递,通过一系列的条件判断等解析参数。
当然这样做自然没什么问题,但是在Python中为了简化这种需求,有个专门的argparse模块。
这个模块的使用也比较简单,示例代码如下。
import argparse
# 创建一个Parser用于处理参数,description是帮助描述信息
parser = argparse.ArgumentParser(description='this is argument test')
# 向parser中增加参数,第一个参数是自定义的参数形式,第二个是默认值,第三个是帮助信息
parser.add_argument('-arg1', default='InputArg1', help='this is arg1')
parser.add_argument('-arg2', default='InputArg2', help='this is arg2')
# 获取parser中的所有参数
args = parser.parse_args()
print(args)
# 想要获取某个参数的值直接调用args.name即可,参数名是args的成员变量
if args.arg1 is None:
print('arg1 is none')
else:
print('arg1:', args.arg1)
if args.arg2 is None:
print('arg2 is none')
else:
print('arg2:', args.arg2)
使用这个模块的好处是,由于指定了参数名,所以参数可以是无序的,不像之前自己实现,参数顺序必须是固定的。 当然固定也有固定的好处,那就是输入参数时不需要输入对应参数名,会更快一些。这两种方法应该根据需求按需选择。
(2)部分参数解释
代码里的OFFSET_Y和OFFSET_X含义是相比于原始的面阵影像而多出来的像素大小。
因为重采之后,由于影像间有位移,所以如果将重采后的影像还放到和原始影像那样的大小的话,会导致重采后的影像显示不全。
直接放个图可能就理解了。
 至于它们的初始值,是按需改变的。
至于它们的初始值,是按需改变的。
(3)SIFT与SURF
在实际中发现SURF比SIFT要快很多,但是在默认参数下,提取的特征点数量会比SIFT少,这可能就会直接导致匹配失败的情况。 SIFT提取的特征点数量很多,最后获得的匹配点对也很多,更有利于计算变换矩阵。 在使用的数据上,SURF获得的匹配点对基本在50到80之间,有时会出现没有的情况。 SIFT获得的点对一般在100-180之间,没有出现无正确匹配的情况。 因此从结果的稳健性上来说,使用SIFT更好一些。
(4)warpAffine函数
在warpAffine()函数中,有个参数叫borderMode。这个参数是用来指定重采后的空白部分是否是透明的,如果不指定,默认是黑色,灰度值为0。
在实际使用过程中发现,最好把这个参数设为cv2.BORDER_TRANSPARENT,这样就不会出现拼接缝了。如下所示。
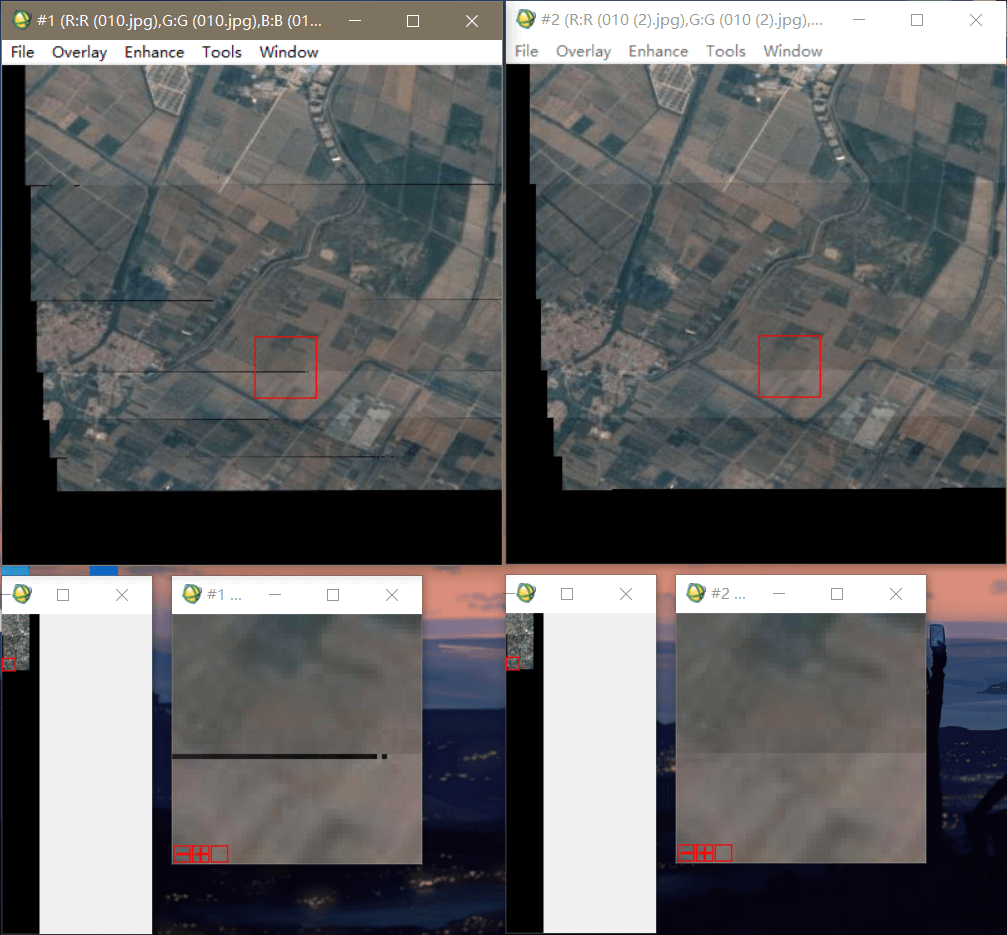
(5)透明叠加问题
正如在上面提到的重采后的空白区域问题,如果直接把重采后的影像放到原始影像上,你会发现原始影像被黑色区域覆盖了。 这样就没有办法实现条带拼接了。所以需要自己写函数来实现,主要利用图像的位运算来进行,具体做法参考了之前OpenCV笔记,点击查看。 由于这里是要把纯黑色的空白区域和影像分开,所以二值化的阈值设的就比较低,当然也可以是其它数,如5等。 但不能太大,否则有可能干扰到影像本身,导致不能准确分离空白区域。
3.测试结果
选取了完整的一轨122景面阵影像进行测试,进行条带拼接后效果如下图所示。
出现的不均匀的灰度跳变是由于不同面阵影像间未进行匀光匀色和灰度拉伸造成的。
 图片比较长,可以另存为原图查看。
图片比较长,可以另存为原图查看。
最后把代码放到了Github上,在里面也上传了使用的示例数据以供测试。 感兴趣的话可以Star或Fork,点击查看。
本文作者原创,未经许可不得转载,谢谢配合
