在之前的这篇博客中,介绍了相机标定和校正的相关知识,在那篇博客里最后给出了基于影像的相机校正代码。 但其实更方便的是通过摄像头视频流进行标定,其实在之前就写过一个实时摄像头标定的代码,但找了半天也没找到。所以这次正好借着新买的双目摄像头重新写一下。 其实之前还写了个生成棋盘格的代码,但怎么找都找不到了。以后有空再重新写一个,现在就在网上下个棋盘格凑合用吧。
1.双目相机标定
相机标定的意义无需多说,它是进行各种计算的前提,会深深影响后续计算步骤的精度。 其实双目相机的标定和普通相机没有任何区别,最简单的办法就是分别对两个摄像头进行标定,获得各自的内参和畸变参数就好了。 这里需要注意的是,采用OpenCV进行标定,会获得一个内参矩阵和5个畸变参数。内参矩阵中的fx和fy,严格来说并不完全等于f,可以分别称为x轴和y轴上的归一化焦距。 它们之间存在倍数关系,fx=f/dx,fy=f/dy。一般情况下f的单位为mm,dx、dy的单位为mm/pixel,所以fx、fy的单位为像素。 这里dx、dy表示CCD中每个像素的物理尺寸大小为dx×dy(mm)。 一般情况下相元都是正方形的,所以理论上x方向上的像素分辨率和y方向上的分辨率应该是相同的,所以dx=dy,fx=fy。但实际过程中难免会有误差,所以fx和fy不绝对相等,但也差不太多。 如果你标定出来的结果fx和fy差很多,那十有八九就是有问题了。
这让我想到了之前做过的一类题目,图像缩放与相机内参的关系。解答这类问题不能想当然说相机内参是不会变的,认为影像改变后内参还和原来一样。最好还是从定义出发。有两种问法。
第一种是对影像进行裁剪。已知原图像内参K=(fx, fy, cx, cy),图像大小为(w, h),现对图像进行裁剪,从影像(m, n)处截出一定大小(w2,h2)的图像(m+w2≤w, n+h2≤h),问截取后的图像的内参为多少?示意图如下。
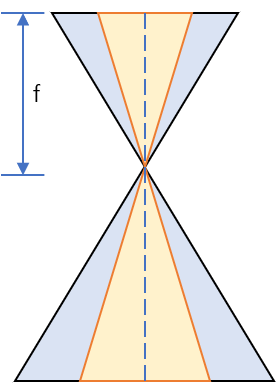
首先从基本公式出发,由于只是对影像进行裁剪并没有改变相机原有的成像系统,只相当于缩小了相机的视场,因此f是不会改变的。 dx、dy表示CCD中每个像素的物理尺寸,所以dx、dy是不会改变的。 因此fx=f/dx,fy=f/dy,所以fx、fy不变。
cx、cy的定义是相机光心在像素坐标系中的坐标,抓住这个定义。 由于裁剪后的影像原点在原始影像中的坐标是(m, n),因此相机光心在新坐标系中的坐标应该为cx’=cx-m, cy’=cy-n。如下图所示。
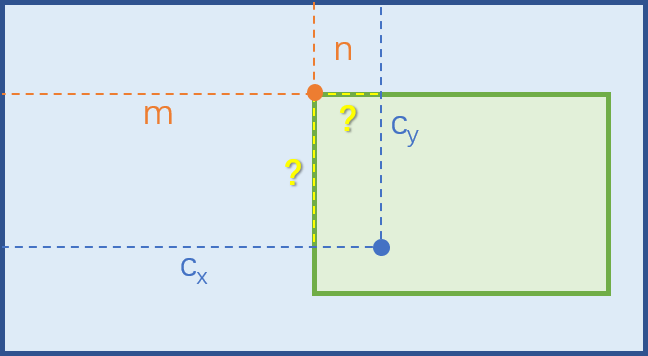
换句话说,裁剪后的新的cx’、cy’与裁剪了多大没关系(例如经常有题目中说裁剪为原图的一半作为干扰),只与裁剪的左上角点在原始影像中的坐标有关。
根据上面的公式可知,特别的当裁剪影像的左上角点与原图重合时(即m、n都为0),cx’=cx, cy’=cy。
第二种问法是对影像进行缩放。有一个相机,已知内参为f、cx、cy、fx、fy。问将影像缩小一倍后(长宽都变为原来一半、影像大小变为原来的1/4),相机的内参变为多少。
还是从公式出发。dx、dy表示CCD中每个像素的物理尺寸,所以dx、dy不会改变。
而在改变影像大小的过程中,其实等价于调焦的过程,将像面向着焦点拉近了,所以f’=1/2f。示意图如下。
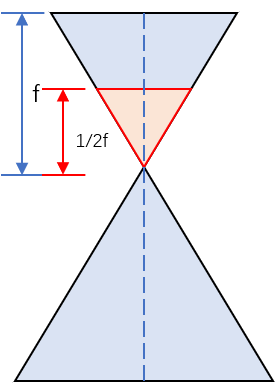 由公式fx=f/dx,fy=f/dy,可知fx、fy都变成了原来的1/2。
由公式fx=f/dx,fy=f/dy,可知fx、fy都变成了原来的1/2。
而对于cx、cy,根据上面的分析,其只与变换后影像的原点在原始坐标系中的坐标有关。 但这里并没有说是以光心为中心进行缩放还是以左上角点为中心进行缩放,如下图所示。

这里暂且认为是以左上角点进行缩放,因此cx’=cx,cy’=cy。所以最终答案是f、fx、fy变成了原来的1/2,cx、cy不变。 而若是以光心为中心缩放为原图的1/2大小,那么新影像的原点在原始坐标系中的坐标应该为(1/4w,1/4h)。 根据上面推导的公式有:cx’=cx-m=cx-1/4w,cy’=cy-n=cy-1/4h。若cx、cy可近似认为是1/2w、1/2h,则cx’=1/2w-1/4w=1/4w=(1/2)cx, cy’=1/2h-1/4h=1/4h=(1/2)cy。 这种情况下最终答案是f、fx、fy、cx、cy都变成了原来的1/2。
2.标定代码
下面代码实现了通过摄像头实时拍摄棋盘格,然后进行标定的功能。同时不仅仅可以用于双目,对于单目相机同样可以标定,只需修改启动参数即可。
# coding=utf-8
import cv2
import numpy as np
import argparse
start_x = 30
start_y = 30
def reactionEvent(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
if start_x < x < start_x + 70 and start_y < y < start_y + 30:
if not img_ret:
print "No chessboard detected."
else:
objpoints.append(objp)
imgpoints.append(img_corners2)
cv2.imwrite(
args.flag + "_" + int(width).__str__() + "@" + int(
height).__str__() + "_" + imgpoints.__len__().__str__().zfill(2) + ".jpg",
img_gray)
print imgpoints.__len__(), "image(s) added."
elif start_x + 80 < x < start_x + 215 and start_y < y < start_y + 30:
if imgpoints.__len__() >= 10:
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, img_gray.shape[::-1], None,
None)
np.savetxt(args.flag + "_" + int(width).__str__() + "@" + int(height).__str__() + "_inner.txt", mtx)
np.savetxt(args.flag + "_" + int(width).__str__() + "@" + int(height).__str__() + "_distort.txt", dist)
print "Saved parameters."
else:
print imgpoints.__len__().__str__() + " images,no enough 10 images."
elif start_x + 225 < x < start_x + 285 and start_y < y < start_y + 30:
cv2.destroyAllWindows()
exit()
def getCameraInstance(index, cam_flag, resolution):
"""
用于初始化获取相机实例,从而读取数据
:param index: 相机的索引编号,如果只有一个相机那就是0,有多个则以此类推
:param cam_flag: 标定相机类型,单目或双目
:param resolution: 相机数据的分辨率设置
:return: 相机实例,以及设置的影像长宽
"""
cap = cv2.VideoCapture(index)
if cam_flag == 'single':
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
return cap, width, height
else:
if resolution == '960p':
width = 2560
height = 960
elif resolution == '480p':
width = 1280
height = 480
elif resolution == '240p':
width = 640
height = 240
# OpenCV有相关API可以设置视频流的长宽
cap.set(cv2.CAP_PROP_FRAME_WIDTH, width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height)
return cap, width, height
if __name__ == '__main__':
# 创建一个Parser用于处理参数,description是帮助描述信息
parser = argparse.ArgumentParser(description='Camera Calibration Script Written by Zhao Xuhui.')
# 向parser中增加参数,第一个参数是自定义的参数形式,第二个是默认值,第三个是帮助信息
parser.add_argument('-row', default='6', help='Row number of chessboard,6 as default')
parser.add_argument('-col', default='8', help='Column number of chessboard,8 as default')
parser.add_argument('-num', default='0',
help='Index of camera that you want to calibrate in your computer,0 as default')
parser.add_argument('-flag', default='single',
help='Camera type,one of these:\'single\',\'left\',\'right\',\'single\' as default')
parser.add_argument('-reso', default='480p',
help='Camera resolution for stero camera,one of these:\'240p\',\'480p\',\'960p\',\'480p\' as default')
# 获取parser中的所有参数
args = parser.parse_args()
ROWS = int(args.row)
COLOMONS = int(args.col)
# prepare object points, like (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)
objp = np.zeros((ROWS * COLOMONS, 3), np.float32)
objp[:, :2] = np.mgrid[0:ROWS, 0:COLOMONS].T.reshape(-1, 2)
# Arrays to store object points and image points from all the images.
objpoints = [] # 3d point in real world space
imgpoints = [] # 2d points in image plane.
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# 读取启动参数
cam_no = int(args.num)
cam_flag = args.flag
reso_flag = args.reso
# 获取相机实例并返回对象
cap, width, height = getCameraInstance(cam_no, cam_flag, reso_flag)
cv2.namedWindow("img_cam")
cv2.setMouseCallback("img_cam", reactionEvent)
# 不断循环读取帧数据
while True:
ret, frame = cap.read()
if cam_flag == 'single':
img_cam = frame
elif cam_flag == 'left':
img_cam = frame[:, :int(width / 2), :]
elif cam_flag == 'right':
img_cam = frame[:, int(width / 2):, :]
# Find the chess board corners
img_gray = cv2.cvtColor(img_cam, cv2.COLOR_BGR2GRAY)
img_ret, img_corners = cv2.findChessboardCorners(img_gray, (ROWS, COLOMONS), None)
if img_corners is not None:
img_corners2 = cv2.cornerSubPix(img_gray, img_corners, (11, 11), (-1, -1), criteria)
img_cam = cv2.drawChessboardCorners(img_cam, (ROWS, COLOMONS), img_corners2, img_ret)
cv2.rectangle(img_cam, (start_x, start_y), (start_x + 70, start_y + 30), (0, 0, 255), 2)
cv2.putText(img_cam, "save", (start_x, start_y + 25), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 1,
cv2.LINE_AA)
cv2.rectangle(img_cam, (start_x + 80, start_y), (start_x + 215, start_y + 30), (0, 0, 255), 2)
cv2.putText(img_cam, "calibrate", (start_x + 80, start_y + 25), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 1,
cv2.LINE_AA)
cv2.rectangle(img_cam, (start_x + 225, start_y), (start_x + 285, start_y + 30), (0, 0, 255), 2)
cv2.putText(img_cam, "exit", (start_x + 225, start_y + 25), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 1,
cv2.LINE_AA)
cv2.imshow("img_cam", img_cam)
k = cv2.waitKey(1) & 0xFF
if k == 27:
break
标定的界面如下。
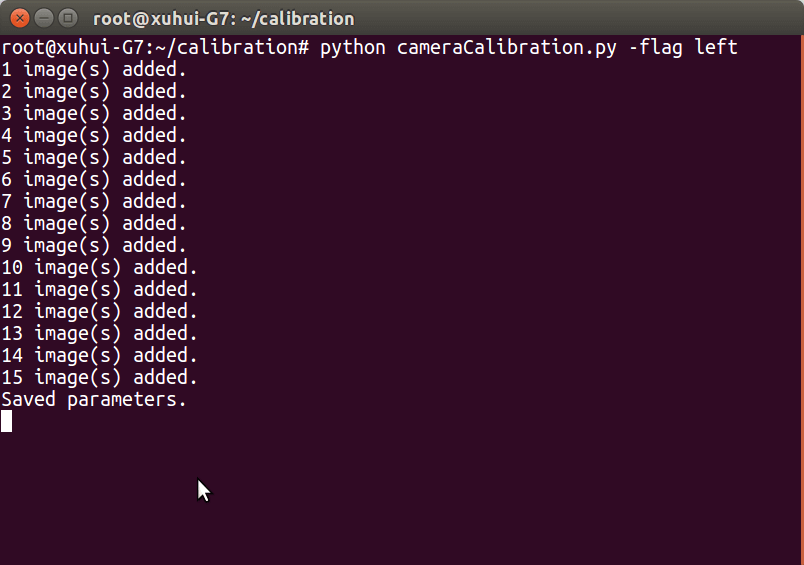
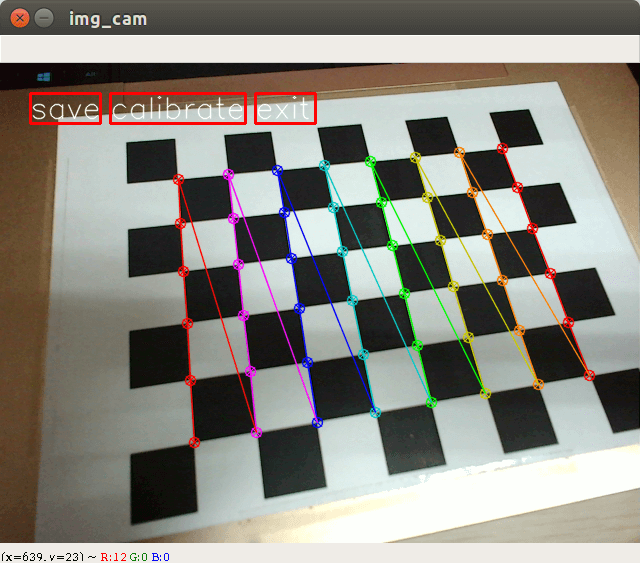 可以通过点击”save”按钮来保存图片,通过”calibrate”来计算内参矩阵和畸变参数,控制台输出如下。
可以通过点击”save”按钮来保存图片,通过”calibrate”来计算内参矩阵和畸变参数,控制台输出如下。
3.校正代码
基于已经获得的相机内参矩阵和畸变参数,可以实时对相机影像进行校正,代码如下。
# coding=utf-8
import cv2
import numpy as np
import argparse
def getCameraInstance(index, cam_flag, resolution):
"""
用于初始化获取相机实例,从而读取数据
:param index: 相机的索引编号,如果只有一个相机那就是0,有多个则以此类推
:param cam_flag: 标定相机类型,单目或双目
:param resolution: 相机数据的分辨率设置
:return: 相机实例,以及设置的影像长宽
"""
cap = cv2.VideoCapture(index)
if cam_flag == 'single':
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
return cap, width, height
else:
if resolution == '960p':
width = 2560
height = 960
elif resolution == '480p':
width = 1280
height = 480
elif resolution == '240p':
width = 640
height = 240
# OpenCV有相关API可以设置视频流的长宽
cap.set(cv2.CAP_PROP_FRAME_WIDTH, width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height)
return cap, width, height
if __name__ == '__main__':
# 创建一个Parser用于处理参数,description是帮助描述信息
parser = argparse.ArgumentParser(description='Camera Correction Script Written by Zhao Xuhui.')
# 向parser中增加参数,第一个参数是自定义的参数形式,第二个是默认值,第三个是帮助信息
parser.add_argument('-inner', default='./inner.txt', help='File path of inner params.')
parser.add_argument('-distort', default='./distort.txt', help='File path of distort params.')
parser.add_argument('-num', default='0',
help='Index of camera that you want to calibrate in your computer,0 as default')
parser.add_argument('-flag', default='single',
help='Camera type,one of these:\'single\',\'left\',\'right\',\'single\' as default')
parser.add_argument('-reso', default='480p',
help='Camera resolution for stero camera,one of these:\'240p\',\'480p\',\'960p\',\'480p\' as default')
# 获取parser中的所有参数
args = parser.parse_args()
# 读取启动参数
inner_path = args.inner
distort_path = args.distort
cam_no = int(args.num)
cam_flag = args.flag
reso_flag = args.reso
dist = np.loadtxt(distort_path)
inner = np.loadtxt(inner_path)
# 获取相机实例并返回对象
cap, width, height = getCameraInstance(cam_no, cam_flag, reso_flag)
# 不断循环读取帧数据
while True:
ret, frame = cap.read()
if cam_flag == 'single':
img_cam = frame
elif cam_flag == 'left':
img_cam = frame[:, :int(width / 2), :]
elif cam_flag == 'right':
img_cam = frame[:, int(width / 2):, :]
cv2.imshow("frame_cam", img_cam)
h, w = img_cam.shape[:2]
newcameramtx, roi = cv2.getOptimalNewCameraMatrix(inner, dist, (w, h), 1, (w, h))
# undistort
dst = cv2.undistort(img_cam, inner, dist, None, newcameramtx)
# crop the image
x, y, w, h = roi
dst = dst[y:y + h, x:x + w]
cv2.imshow("correct_cam", dst)
k = cv2.waitKey(1) & 0xFF
if k == 27:
break
演示效果如下。
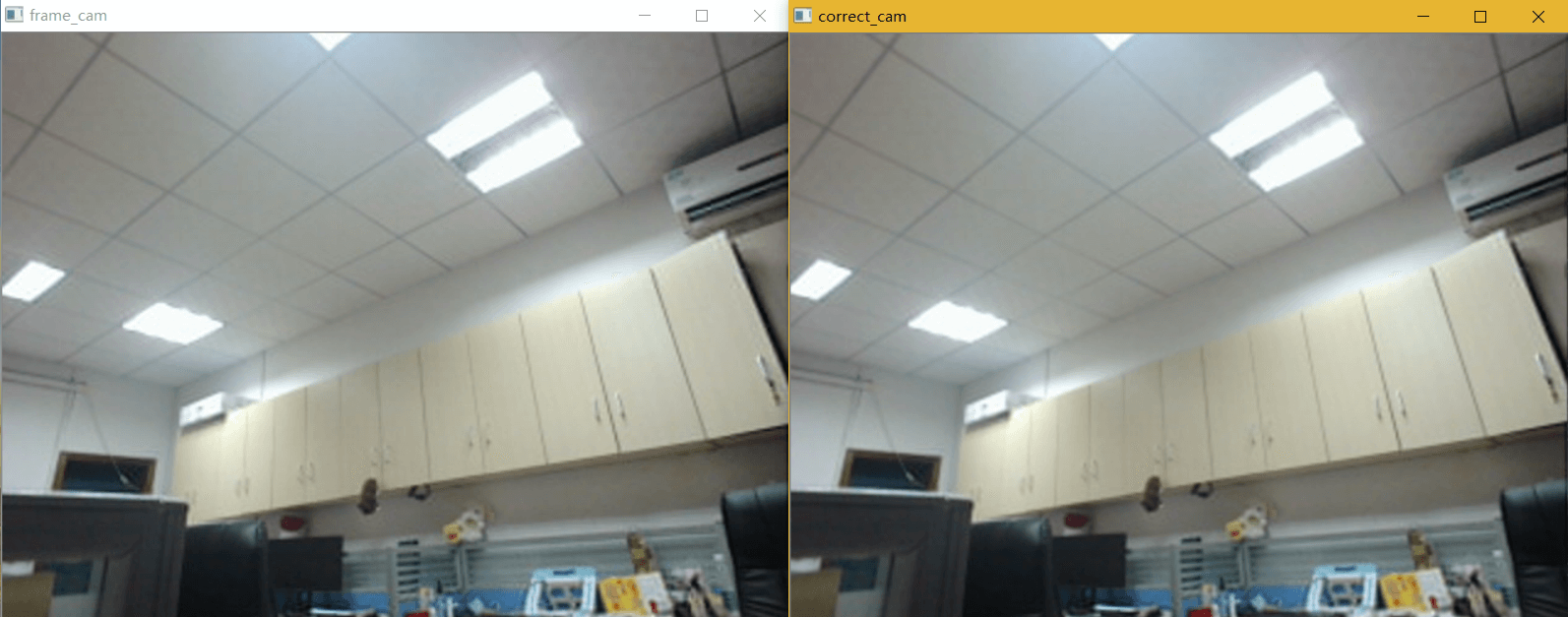 左边是原始影像,右边是校正后影像。由于相机本身畸变不是很大,所以校正效果并不是很明显。
左边是原始影像,右边是校正后影像。由于相机本身畸变不是很大,所以校正效果并不是很明显。
最后,按照惯例代码上传到了Github,欢迎Star或Fork,点击查看。
本文作者原创,未经许可不得转载,谢谢配合
