因为目前博客内容也比较多了,所以想着做一个类似于Google“手气不错”这样的一个功能,点击一下就可以随机访问一篇博客。主要流程就是网页端发送一个请求到服务器,服务器根据发送的请求随机返回一个博客地址,网页端根据返回的网址打开新页面。 整篇博客主要参照之前写的这篇博客作为技术架构,如果想了解可以先读一下那篇。
1.网页端消息的发送与处理
相关技术细节在之前的那篇博客里都介绍过了,这里就不再赘述。网页端主要包括:向服务器发送请求、处理服务器返回的网址并打开新页面两个步骤。直接上代码。
<!DOCTYPE HTML>
<html>
<head>
<meta charset="utf-8">
<title>随机访问示例</title>
<script type="text/javascript">
function sendRequest() {
var requestInfo = "randomRequest";
// 打开连接
var ws = new WebSocket("ws://localhost:4200");
// 发送数据
ws.onopen = function () {
// 使用send()方法发送数据
ws.send(requestInfo);
};
// 接收数据
ws.onmessage = function (evt) {
var received_msg = evt.data;
alert(received_msg);
// 作为一个好习惯,在接收完数据后就关闭连接,这样可以减少服务器的负担
ws.close();
//window.location.href = received_msg;//本窗口打开网页
window.open(received_msg);//新建窗口打开网页
};
// 关闭连接后的事件
ws.onclose = function () {
};
}
</script>
</head>
<body>
<button type="button" onclick="sendRequest()">随机选择</button>
</body>
</html>
2.服务器端消息的接收与处理
技术框架还是采用WebSocket,主要包括:下载or读取索引文件、解析索引文件内容、根据内容范围生成随机数、根据随机数索引找到对应条目内容并拼接字符串、返回网址,这几个步骤。直接上代码。
# coding=utf-8
import urllib
import os
import time
import random
from websocket_server import WebsocketServer
import sys
import logging
# 因为考虑到传入的字符串有非英文字符,
# 所以手动设置编码,否则可能会报编码错误
reload(sys)
sys.setdefaultencoding('utf-8')
def findAllFiles(root_dir, filter):
"""
在指定目录查找指定类型文件
:param root_dir: 查找目录
:param filter: 文件类型
:return: 路径、名称、文件全路径
"""
# print("Finding files ends with \'" + filter + "\' ...")
separator = os.path.sep
paths = []
names = []
files = []
for parent, dirname, filenames in os.walk(root_dir):
for filename in filenames:
if filename.endswith(filter):
paths.append(parent + separator)
names.append(filename)
for i in range(paths.__len__()):
files.append(paths[i] + names[i])
# print (names.__len__().__str__() + " files have been found.")
paths.sort()
names.sort()
files.sort()
return paths, names, files
def download():
_, _, files = findAllFiles(".", "download.idx")
if len(files) == 0:
url = "http://zhaoxuhui.top/posts.idx"
urllib.urlretrieve(url, "download.idx")
# print "no file,download"
return "download.idx"
else:
c_time = os.path.getmtime(files[0])
n_time = time.time()
if abs(n_time - c_time) > 86400:
url = "http://zhaoxuhui.top/posts.idx"
urllib.urlretrieve(url, "download.idx")
# print "have file but expired,download"
return "download.idx"
else:
# print "have file and not expired"
return files[0]
def readFile(file_path):
urls = []
f = open(file_path, 'r')
for item in f.readlines()[1:]:
urls.append(item.decode('gb2312').encode('utf-8').strip())
return urls
def select(urls):
index = random.randint(0, len(urls) - 1)
return "http://zhaoxuhui.top/blog/" + urls[index]
def new_client(client, server):
# print "Time:", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print("Client(%d) has joined." % client['id'])
def client_left(client, server):
print("Client(%d) disconnected\n" % client['id'])
def message_back(client, server, message):
# 这里的message参数就是客户端传进来的内容
print("Client(%d) said: %s" % (client['id'], message))
# 这里可以对message进行各种处理
result = handle_login(message)
# 将处理后的数据再返回给客户端
server.send_message(client, result)
def handle_login(text):
# 根据传入的参数处理
if text == "randomRequest":
url = select(readFile(download()))
print "Return:", url
return url
else:
print "error param"
return "http://zhaoxuhui.top"
if __name__ == '__main__':
server = WebsocketServer(4200, host='', loglevel=logging.INFO)
server.set_fn_new_client(new_client)
server.set_fn_client_left(client_left)
server.set_fn_message_received(message_back)
server.run_forever()
如果仔细看会发现,代码中有下载一个叫做download.idx的文件,这个文件就是自定义的博客索引了。里面存放着每篇博客的名称和上传时间,可以用文本编辑器打开,如下。
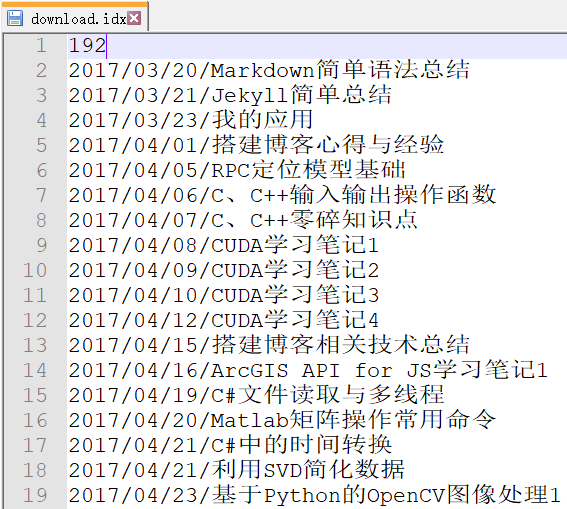 这其实是属于本地端的任务。这个文件是用Python脚本自动生成的,完整的代码见Github项目,这里就不贴了,点击查看。
这其实是属于本地端的任务。这个文件是用Python脚本自动生成的,完整的代码见Github项目,这里就不贴了,点击查看。
本地端将文件依据一定规则生成索引文件,然后索引文件被上传到网上。网页端点击按钮时,向服务器发送请求,服务器会下载我们上传的索引文件并返回一个随机网址。网页端接收到网址后将其在新页面打开。
3.测试
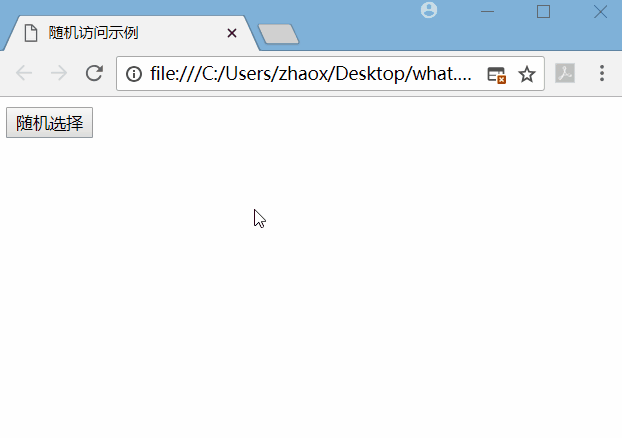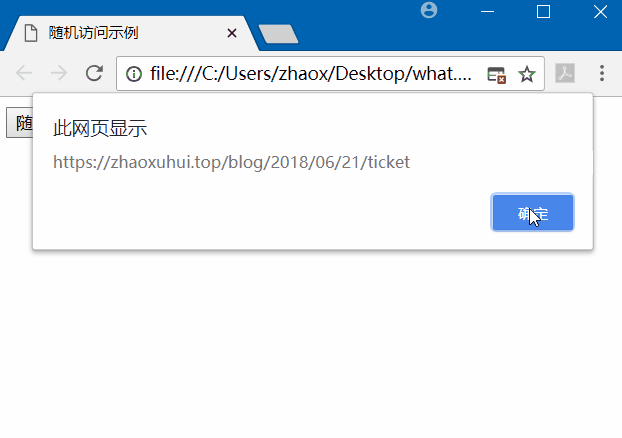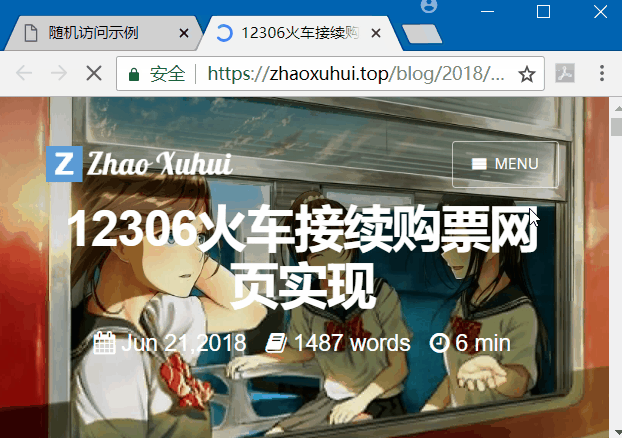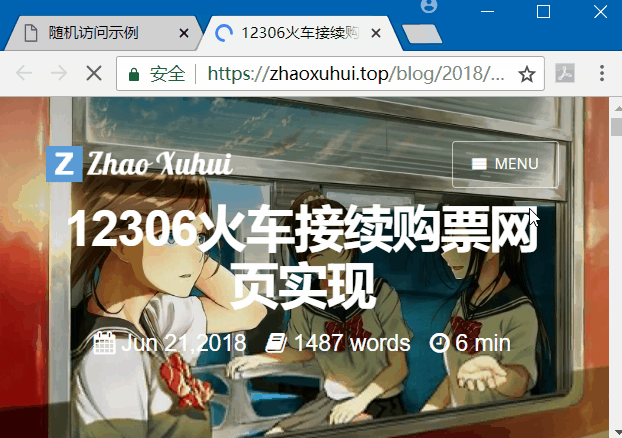
在本机先运行服务器端代码,然后打开网页,点击随机选择,效果如下。
[2019-10-19更新] 又做了一个Ukulele谱的随机选择功能,点击查看网页。 [更新结束]
本文作者原创,未经许可不得转载,谢谢配合
