0.申请
之前就看新闻说过武大超算,说是目前全国高校排名第二,软硬件资源可参考这里,总的来说还行(主要是内存够大)。这几天抽空简单了解了一下武大超算,官网是这里。总体而言对于学生还是比较友好的,基本在线填个申请表,然后就直接通过了。下面就简单记录下在超算上运行代码的过程。
1.登录超算节点
首先找到提供给你的节点服务器地址和账户、密码等信息,如下。
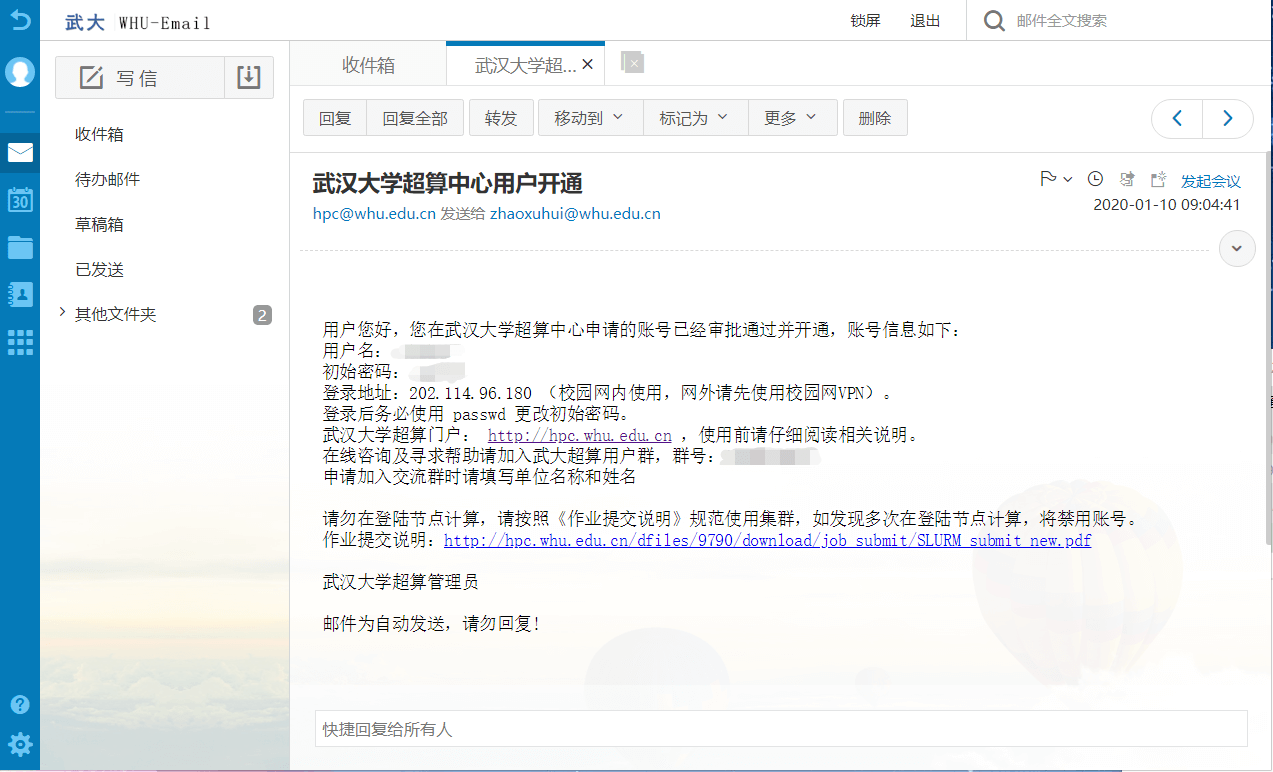 启动XShell,以
启动XShell,以ssh的方式连接,如下。

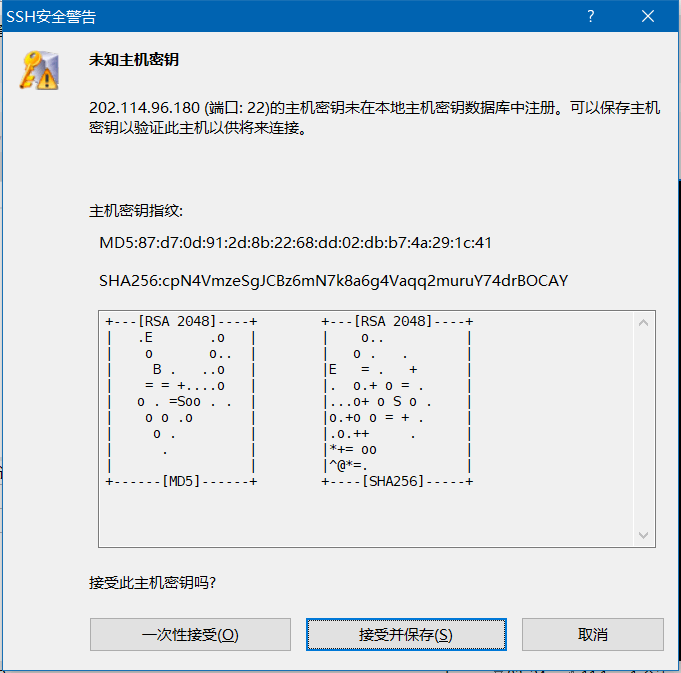 第一次连接的时候会弹出密钥,点击“接受并保存”即可。然后再弹出的对话框中依次输入用户名和密码,即可登录到服务器了。如下所示。
第一次连接的时候会弹出密钥,点击“接受并保存”即可。然后再弹出的对话框中依次输入用户名和密码,即可登录到服务器了。如下所示。
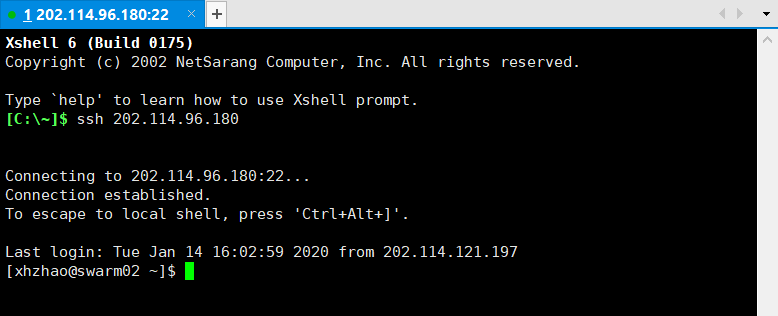 登录之后的当前文件夹是
登录之后的当前文件夹是/home/xhzhao,之后相关数据等都可以放在这里。一个比较有意思的是你可以用cd ..切换到/home目录下,然后再ls一下,就可以看到当前集群上的所有用户文件夹了(虽然没有权限访问就是了,个别用户的文件夹有权限访问),如下。
此外简单介绍一下超算节点上的文件分区。武汉大学高性能计算平台文件系统被分为/home 、/project和/workfs三个分区。
/home分区
该分区下的用户主目录为用户默认家目录,仅用于存储用户的环境变量等信息。在脚本中使用/home/系统账号引用该分区下的用户主目录。该分区的磁盘容量较小,其磁盘限额为每用户1GB,长期保存。所有登录服务节点和计算节点皆可以访问该分区下的文件。
/project分区
/project分区为数据存放区域,主要用于项目文件和运行作业。在脚本中使 用“/project/系统账号”引用该分区下的用户主目录。同时用户也可通过“/home/系统账号/project”访问该分区。该分区磁盘容量大,数据读写快。其磁盘限额为每用户1TB,长期保存。所有登录服务节点和计算节点都可以访问该分区下的文件。
/workfs分区
/workfs分区为数据存放区域,主要用于数据文件。在脚本中使 用/workfs/系统账号引用该分区下的用户主目录。同时用户也可通过/home/系统账号/workfs访问该分区。该分区磁盘容量大,数据读写快。其磁盘限额为每用户3TB,超过3个月的数据会自动清理。所有登录服务节点和计算节点都可以访问该分区下的文件。
2.超算基本操作
其实超算节点本质上还是一个Linux服务器,所以和之前自己的CentOS服务器或者Ubuntu并没有本质区别,很多命令和操作都是一样的。这里也就不再多说了,如果想了解可以参考之前这篇博客中的内容。这里主要介绍一下超算节点上的一些有用的和特有的命令。
(1)查看CPU信息
命令lscpu,输出结果如下。
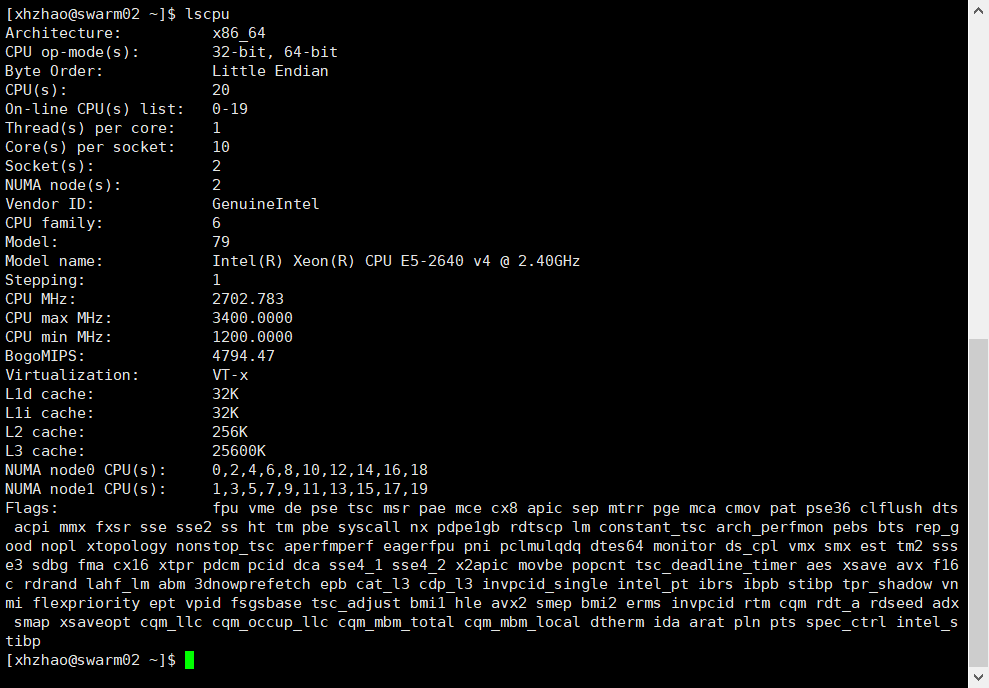
(2)查看硬盘信息
命令df -h,输出结果如下。
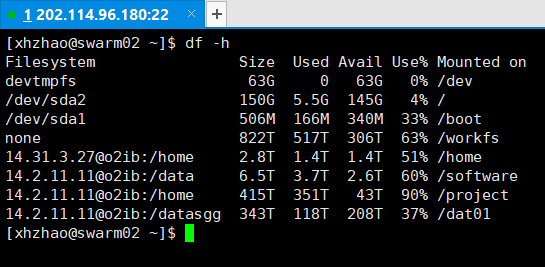
(3)查看内存信息
命令free -m,输出结果如下。
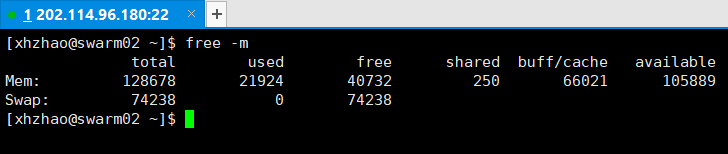 注意这里free显示的并不是真正可用的内存,可用内存是available显示的内存。另外这里数字的单位是MB。另外也可以用
注意这里free显示的并不是真正可用的内存,可用内存是available显示的内存。另外这里数字的单位是MB。另外也可以用top命令查看一些进程信息。
(4)查看超算节点分区信息
命令sinfo,输出结果如下。

(5)将程序投射到节点上运行
命令srun,例如srun -p hpxg ./a.out,将a.out可执行文件放到集群上运行。但这个命令提交的程序在运行时控制台会阻塞,一直等待程序执行完毕,返回结果。处于交互模式下运行的程序被人工退出(如Ctrl+c、终端关闭等)或因登录节点故障退出时,程序运行节点的程序也会退出。
(6)作业任务提交
命令sbatch。相比于srun,这是一个更实用和有价值的命令。用它提交的程序即使连接结束程序也不会终止运行。利用此命令提交作业后会返回一个job的ID,根据这个ID可以后续查询执行状态。具体而言,首先新建一个脚本文件(*.sbatch),然后输入以下内容:
#!/bin/bash
./a.out
并且给这个脚本加上可执行权限:chmod +x a.sbatch。最后使用sbatch提交即可:sbatch -p hpxg a.sbatch。运行这行命令后,系统会返回给我们一个job ID并且回到命令提示符状态。这样执行的程序是不会受连接的中断而终止的。
任务运行完之后,如果需要查看我们程序的输出情况(不是输出的文件,是控制台的输出信息等),默认会在提交任务的目录产生slurm-jobid.out的文件(其实就是一个文本文件),所有任务运行的错误以及标准输出会重定向至此文件中。
另外说一下,终止一个任务的命令是scancel jobid,JobID可以通过下面提到的squeue命令查询。
(7)查看作业信息
命令squeue:查看我们已经提交了的、正在运行的作业的信息;
命令sacct:查看已经结束的任务历史。
换句话说,如果一个程序执行完成了,用squeue是查询不到的,需要用sacct查询。
(8)加载编译环境
命令module。超算集群上由管理员安装的软件需使用module工具调用。这是一个非常有用的命令。因为正是通过它加载Anaconda、CUDA、Tensorflow、PyTorch等等有用的库。
module avail:查看可用软件
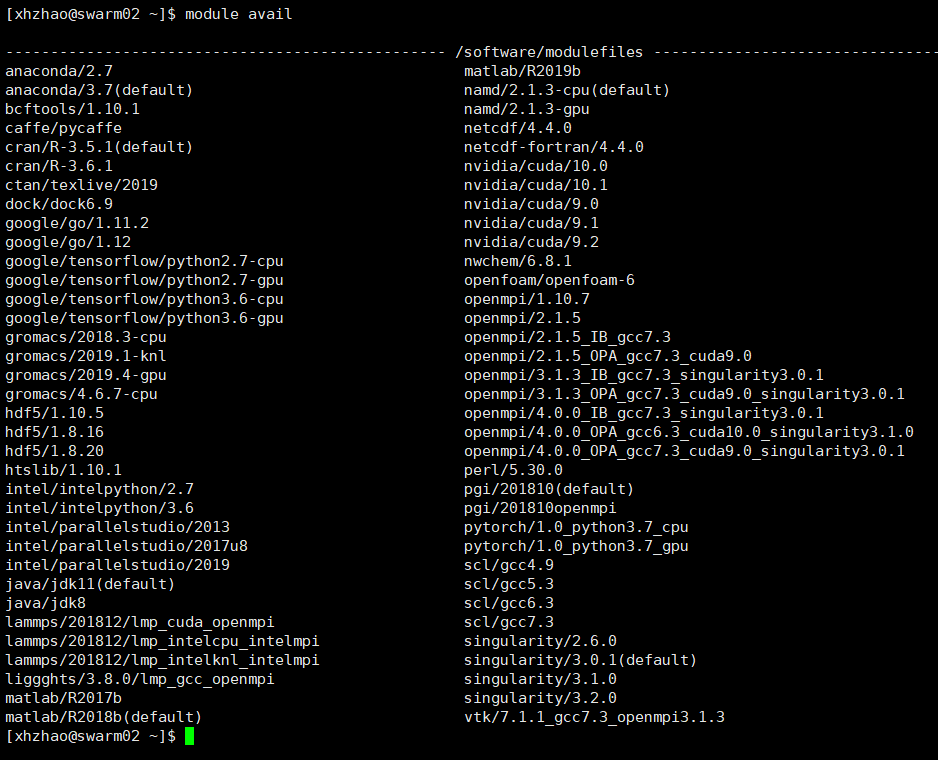 可以看到常用的Anaconda、Caffe、Java、Matlab、CUDA、PyTorch等软件/框架/环境已经有了。
可以看到常用的Anaconda、Caffe、Java、Matlab、CUDA、PyTorch等软件/框架/环境已经有了。
module load:加载软件环境
module list:显示用户已经加载的编译器及库
module unload:卸载软件环境
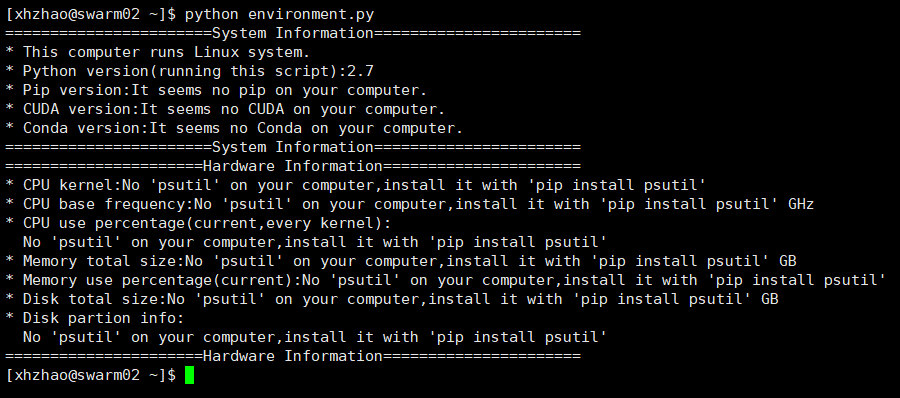
用之前这篇博客中编写的环境检测脚本在未加载任何环境的情况下进行检测,如下。
运行module load anaconda/3.7、module load nvidia/cuda/10.1分别加载Anaconda和CUDA环境,再次运行检测脚本,结果如下。
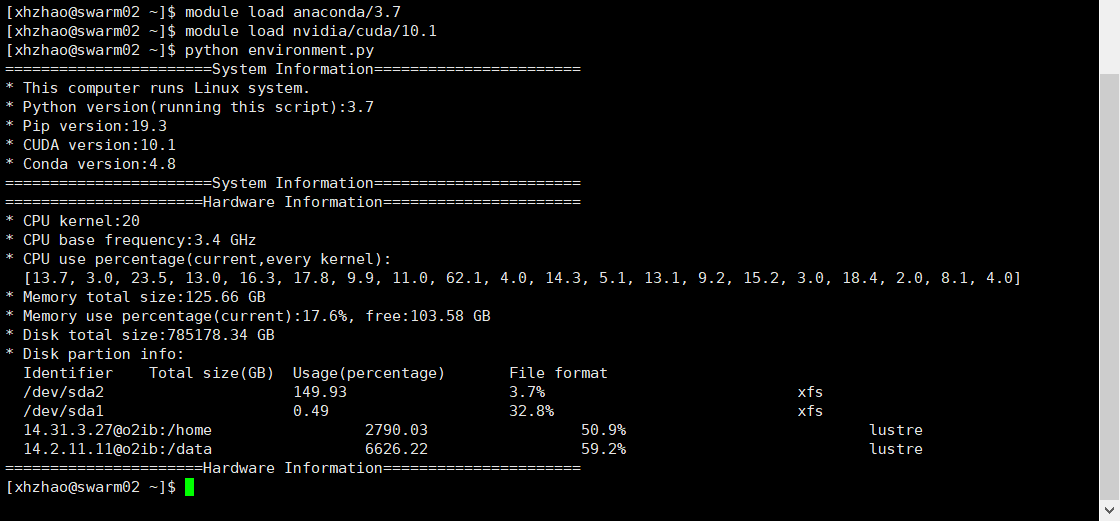 可以看到已经成功检测到了部署的环境。
可以看到已经成功检测到了部署的环境。
3.简单实例
下面以一个简单的Hello World演示如何在超算节点上编译、运行代码。
首先可以现在本地新建一个HelloWorld.c文件,然后输入如下内容:
# include<stdio.h>
# include<stdlib.h>
int main(){
char hostname[1024];
gethostname(hostname,1024);
printf("%s\n",hostname);
printf("Hello World!\n");
return 0;
}
代码非常简单的调用了gethostname函数获取了运行当前代码的节点名称以及输出了一个“Hello World”。将代码文件通过FTP上传到你的文件夹下,如/home/xhzhao/。然后在控制台中输入gcc HelloWorld.c进行编译,如下:
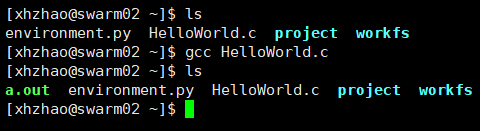 这样便完成了最简单的代码编译,编译好的可执行文件默认叫
这样便完成了最简单的代码编译,编译好的可执行文件默认叫a.out,ls一下就可以看到了。
至此,其实直接就可以在控制台中./a.out运行了。但为了体现超算节点的不一样,可以用命令srun -p hpkg ./a.out,如下图。
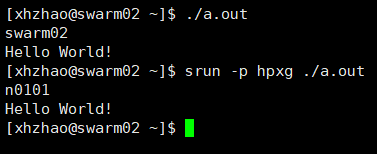 可以看到当前登录的节点是
可以看到当前登录的节点是swarm02,采用srun调度超算节点后显示运行节点是n0101。但正如上面说的,如果程序需要长时间运行,采用srun方式会一直阻塞终端,连接不能中断。所以可以用sbatch命令运行。
可以在本地新建一个test.sbatch脚本文件,内容如下。
#!/bin/bash
./a.out
然后利用FTP传上去,并运行命令sbatch -p hpxg test.sbtach,这样就可以得到job ID并利用sacct可查看执行情况,如下。
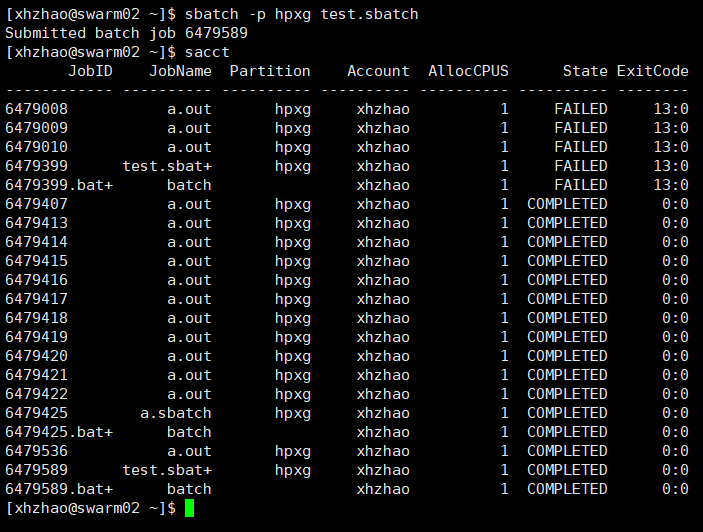 同时在可执行文件目录下生成了
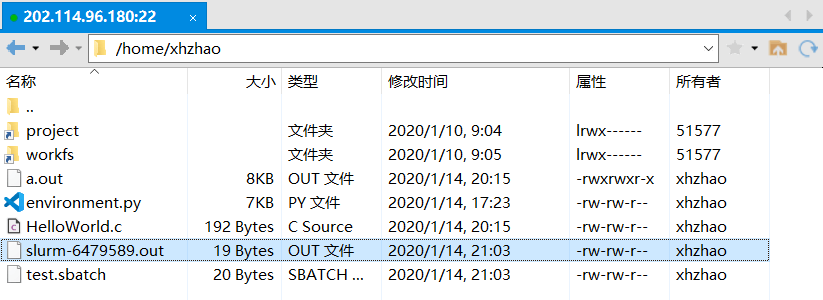
同时在可执行文件目录下生成了slurm-6479589.out文件,这便是程序在控制台中的输出语句,可以打开内容如下。
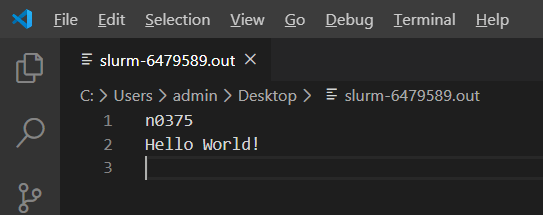 可以看到程序是在
可以看到程序是在n0375跑的。这样便在超算节点上通过它的调度系统实现了代码的运行。
另外建议简单了解一下vim的基本操作,因为超算节点是没有界面的。虽然通过FTP可以将代码传上去,但遇到需要修改的时候毕竟有些麻烦。vim基本操作如下:
-
打开文件:
vim filename。如果有就打开,没有就新建 -
编辑文件:按
i进入编辑模式 -
保存退出:按Esc退出编辑模式,输入
:wq保存并退出
4.运行Matlab程序
(1)拷贝/home/software/MATLAB/MDCS/matlab_mdcs_slurm.sh到您的工作目录
cp /home/software/MATLAB/MDCS/matlab_mdcs_slurm.sh matlab_mdcs_slurm.sh
(2)事先准备好了一个简单的m文件叫test_on_swarm.m,内容如下:
function[]=test_on_swarm()
A = [1,2,3;4,5,6;7,8,9];
B = [4,7,2;9,5,7;1,7,2];
C = A*B;
C
save('final.mat','A','B','C') ;
非常简单的操作,有A、B两个矩阵,相乘的结果赋给C,并将A、B、C都保存到final.mat中。编辑刚刚拷贝的matlab_mdcs_slurm.sh,自定义以下参数:
#--------------------------------------------------------#
# Warning: #
# Do not modify SBATCH settings #
# 请修改SBATCH设置 #
#--------------------------------------------------------#
#SBATCH -n1
#--------------------------------------------------------#
# Change the following variables according to your needs #
#--------------------------------------------------------#
# The directory used to submit the matlab job
work_dir="/home/xhzhao/"
# The .m file that needs to be calculated.
# Do not need to add the .m suffix
mfile="test_on_swarm"
# Number of tasks
ntasks=16
# Request a specific partition for the resource allocation.
partition="hpxg"
# Save the calculation result to .mat
save_mat="$mfile.mat"
# Turn on or turn off warnings
warning="off"
# Change to pay or free account
account="xhzhao"
编辑完成后保存即可。
(3)提交MATLAB MDCS作业
./matlab_mdcs_slurm.sh
运行该命令后,控制台会输出一些Matlab启动的相关内容。
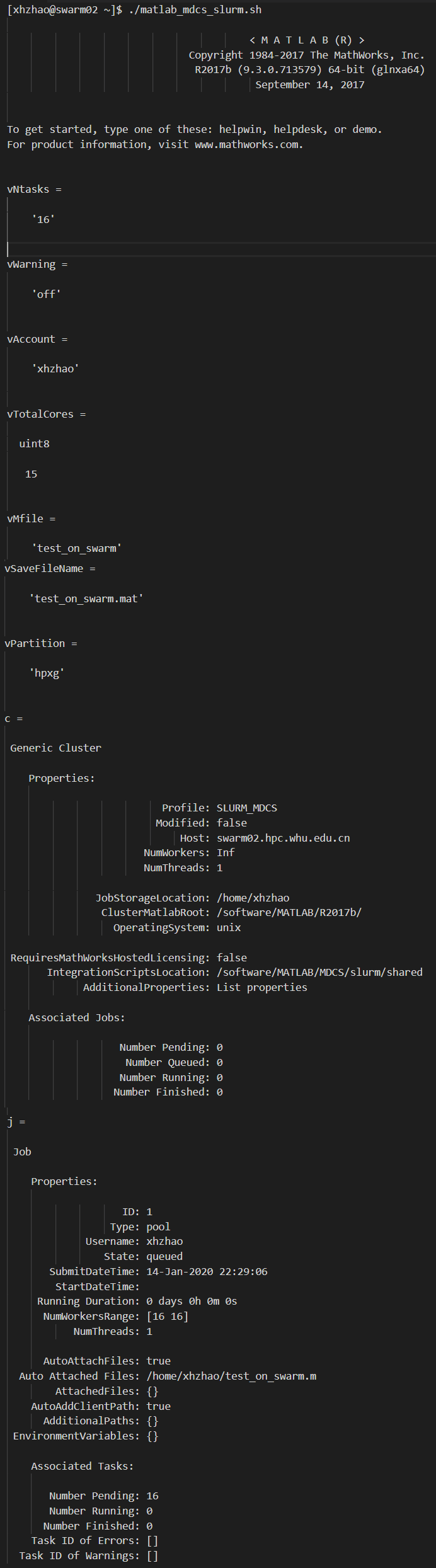 如果没有什么报错就放在那里等待就可以了。
如果没有什么报错就放在那里等待就可以了。
(4)查询作业情况
squeue
例如当前查询如下所示:
 提示我说当前任务被pending,有更高优先级的任务在运行。这种状态就只能等待了。在执行完毕后,会在指定的路径下生成对应的
提示我说当前任务被pending,有更高优先级的任务在运行。这种状态就只能等待了。在执行完毕后,会在指定的路径下生成对应的.mat文件。
等了大约十几分钟再次查看,可以看到,已经生成了fina.mat文件,也就是最终的结果。
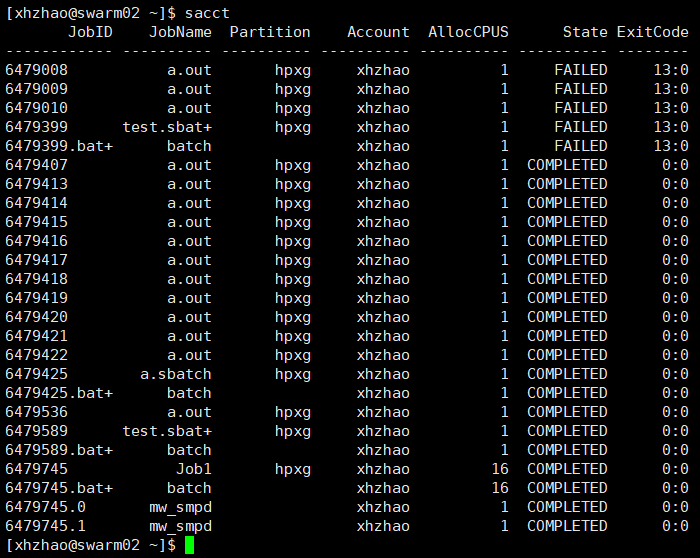
 输入
输入sacct命令查看作业历史记录可以看到,649745的Job已经完成了。
以上便是在超算节点上跑Matlab代码的基本流程,更多知识以后用到了再继续学习。武大超算官网也有一个快速入门教程,感兴趣也可以查看。
5.参考资料
- [1]http://hpc.whu.edu.cn/index/ksrm.htm
- [2]http://hpc.whu.edu.cn/sjfw/wdypx/byhj.htm
- [3]http://hpc.whu.edu.cn/info/1026/1141.htm
- [4]http://hpc.whu.edu.cn/info/1025/1133.htm
本文作者原创,未经许可不得转载,谢谢配合
