这是一篇拖了很久很久的博客,从7月上旬起始基本代码就基本写完了,但一直到现在才有时间简单写个博客总结一下。
1.它是干什么的
简单说一下阅读笔记自动生成代码是干什么的。
俗话说好记性不如烂笔头,文章读久了以后如果没有些笔记的话就像没读过一样。所以适当地做些笔记是十分必要的。
而之前我一直想用一些文献管理软件做笔记,但最后觉得都不太符合我的要求。
于是就决定自己写一个了。
简单来说就是根据格式化的笔记内容自动生成一个完整的Word文档。
比如我们阅读了文献A.pdf,然后将一些笔记放在了A.note文件中。时间长了以后有很多篇笔记,这个脚本就是将这些单个的零碎笔记按照一定规则组合成一个总的Word文档。
2.它是怎么实现的
在介绍了它的功能以后,实现起始就没那么难了。
主要涉及到文件遍历搜索与内容读写、Word文档操作两方面内容。同时为了使用更加方便,也编写了.bat批处理文件更快捷地操作。
而且如果对之前博客内容比较了解的话会发现,这些功能基本在之前都是接触过的,这里只是进行一些综合与修改。
比如对Word文件的操作在这篇博客中就有介绍,而整个代码的设计是与之前Word Bank博客类似的,而且在代码中也实现了与它的联动。而自动化脚本的代码则参考了之前博客自动生成的那篇博客。
由于只是简单记录下,这里就不贴代码了,只是简单介绍一些有意思的点。完整的代码上传到了Github,点击查看。
(1)文件操作
这其实是个很古老的话题了,文件遍历也一直都是用的是很久以前写的那个函数。至于文件读写则还是Python的open()函数。这里简单介绍一下自己设计的.note文件包含哪些内容(说是自己设计的,其实就是按一定格式写的文本文件),如下图所示。
 主要包含文章的标题、作者、关键词、出版商、出版日期、阅读日期、评论、好的表达、重要单词这些内容。所以在代码的
主要包含文章的标题、作者、关键词、出版商、出版日期、阅读日期、评论、好的表达、重要单词这些内容。所以在代码的readNoteFiles()函数里就是按照这个规则读取的。如果以后有一些新的想法也会继续添加。
如果仔细的话会发现,最后的Great Expressions和Important Words是为了Word Bank自动生成预留的,目前已经整合到一起了。不需要自己手动编写.exp和.wd文件了,直接在这里写好就行。
(2)Word文件操作
相比于文件操作,Word文件操作才是更加重要的。这里用的还是Python-docx库,只不过相比于之前那篇博客,更深入研究了一下,比如如何设置字体、段落、标题、超链接等等。感兴趣的话直接去代码中看就好了。 不过通过这次写代码,得到的一个经验是,Python-docx也并不是万能的,Word的什么功能都可以实现,比如说插入页码、目录这种就很难直接通过代码实现。这个库并不能进行复杂的渲染或排版,只是能够将内容放到Word文档里。 因此,如果想实现一些稍微复杂的功能,可以考虑事先建好一个空的Word模板,基于此进行内容填充。这样就可以解决比如说页码的问题。
但在这里其实页码对我来说没那么重要,对我而言最重要的是如何自动生成目录。我研究了很多代码发现都没有办法实现这个功能。因为目录的插入是在渲染和排版好后的Word文档中进行的。 因此Python-docx中并不存在那种一行代码就能生成目录的办法。最后我也终于找到了一种相对曲折,但最后实际效果还可以的目录生成方法。 简单来说就是现在空白模板文件中插入一个目录,然后我们利用Python-docx基于这个模板将内容写入。这样我们就会得到一个目录没有更新但内容OK的Word文档。 下面就是重点了,我们通过使用Windows系统提供的win32com API自动用Word软件打开这个文件,然后更新目录并保存。最终实现对于目录的更新。
# 调用Win32 API更新Word文件目录
word = win32com.client.DispatchEx("Word.Application")
# 注意传给Word的文件路径必须是绝对路径
doc = word.Documents.Open(outpath)
doc.TablesOfContents(1).Update()
doc.Close(SaveChanges=True)
word.Quit()
这样便解决了我的需求。最后还有如何插入超链接的问题。通过在网上不断寻找,找到了一个能用的代码,直接拿过来用了。不过这个超链接只能是网址,而不能是文档内的引用。
总体而言,如果有需求Python-docx的官方文档还是值得好好研究一下的,可以实现更多功能。而win32com也是个值得关注的强大的工具。
(3)其它
当然,要想实现一个可用、好用的脚本,上面两个方面还是不够的,还有很多细节上的东西。比如指定输出某段时间内的笔记、文件内容的对比与更新等等。
这里指定输出某段时间内的笔记这个功能花了我挺多时间。原因在于前期的想法一直不太对,各种试还是不行。字符串之间直接的比较并不容易。
最后将所有的时间都转化成统一的时间戳,然后以此进行比较,获取范围。如果感兴趣可以看代码中的getIndexRange()函数。
[↓2020-08-13更新↓]
因为有时候想要知道一些统计信息,因此简单实现了文章阅读篇数的统计,以及平均每天、每周、每月阅读论文数量的计算。并且利用Matplotlib绘制了每月阅读论文数量的柱状图。最后利用Python-docx将绘制好的图片插入到Word文档中。
关于利用Matplotlib绘图可以参考之前的这篇博客,或直接在网站里搜索Matplotlib就可以找到相关内容。
关于插入图片,这里只是用了最简单的功能,设置了个宽高,如果需要更复杂的功能还是建议参考官方文档。
[↑更新完毕↑]
请注意,博客里贴出的代码可能不是最新的,实际代码中的一些改动可能不会同步到这篇博客里,最新版本请参阅Github项目。
3.它的效果怎么样
如下图所示。
 可以看到,整个文档自动生成了可以点击的目录。在左边,每篇文章都是一个二级标题,下面又按照内容进一步分成了作者、评论等内容。
可以看到,整个文档自动生成了可以点击的目录。在左边,每篇文章都是一个二级标题,下面又按照内容进一步分成了作者、评论等内容。
 整个文档被分为Closely Relevant和Generally Relevant两大部分,都用深蓝色的标题写出。同时在右下方也会写上这篇文档生成的日期。
在下面也会有个总的统计,有多少篇文章,在什么时间段内。
而在具体的文章页面,标题用蓝色标出,其它子部分用绿色标出。同时,为了更方便引用和查阅,在Publisher & Time部分加入了谷歌学术的超链接,点击就可以跳转到对应文章的搜索结果页面。
整个文档被分为Closely Relevant和Generally Relevant两大部分,都用深蓝色的标题写出。同时在右下方也会写上这篇文档生成的日期。
在下面也会有个总的统计,有多少篇文章,在什么时间段内。
而在具体的文章页面,标题用蓝色标出,其它子部分用绿色标出。同时,为了更方便引用和查阅,在Publisher & Time部分加入了谷歌学术的超链接,点击就可以跳转到对应文章的搜索结果页面。
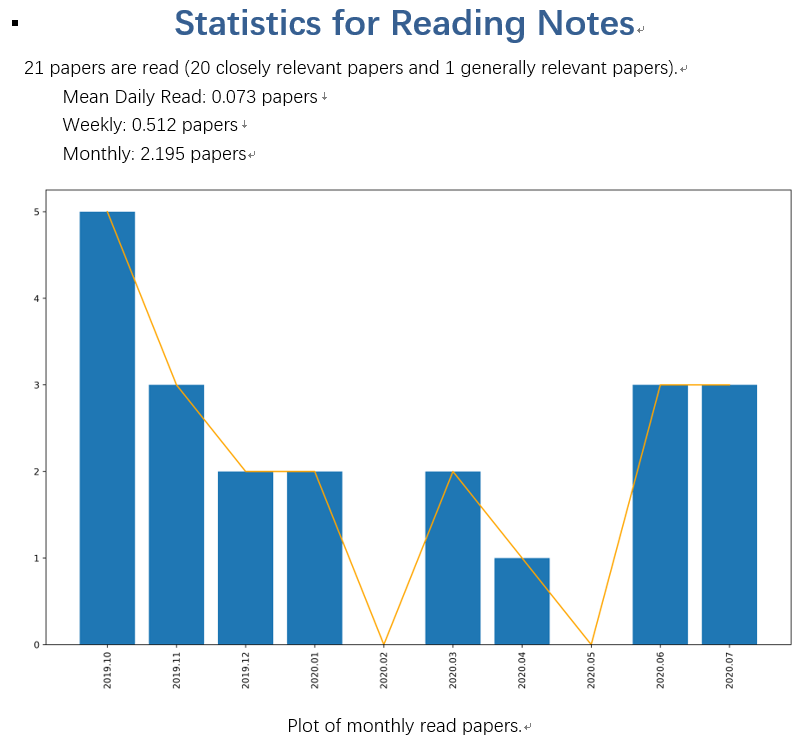 在文档的最后,加入了一些统计信息,并绘制了每月阅读的论文数量柱状图。
在文档的最后,加入了一些统计信息,并绘制了每月阅读的论文数量柱状图。
综上,总体而言效果还是不错的,基本上达到了我之前的预期。而且因为是自己写代码实现的,所以可控性和自定义程度会更大一些。后续如果想进行一些统计等都是非常方便的。
本文作者原创,未经许可不得转载,谢谢配合
