0.背景
在很久之前的这篇博客里,我们介绍过C++中一个很方便的线程并行库OpenMP。而在这篇博客中,我们又学习了Python中的并行编程方法,提升了效率。在这篇博客中,我们再学习一个从C++11标准之后就直接支持的标准线程库,std::thread,编译参数是-std=c++11。相比于OpenMP,新标准支持的thread的使用更类似于Python的multiprocessing库。
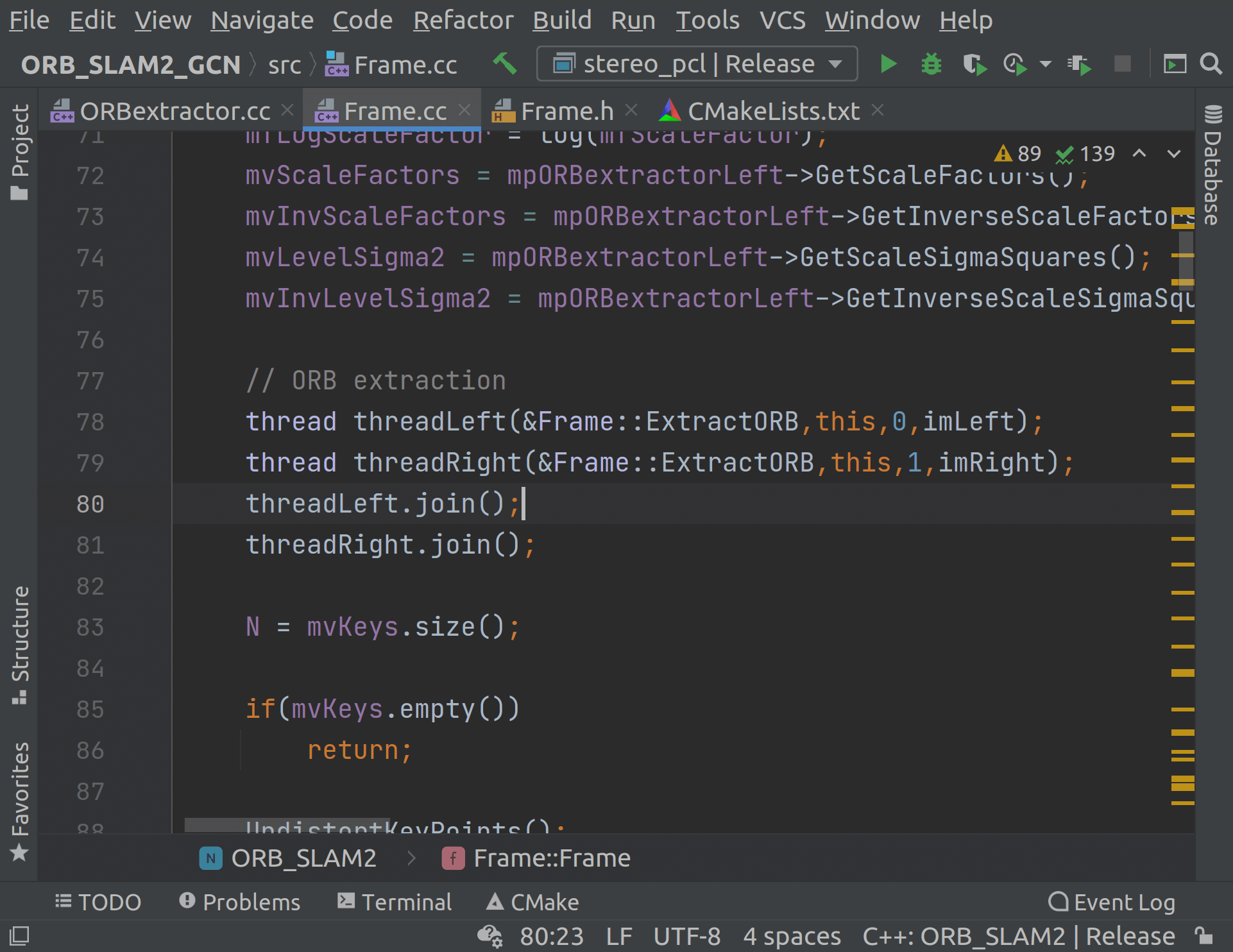
最早见到这个用法是在ORB-SLAM2的代码中,在提取ORB特征的时候,作者就手动开了两个线程分别在双目的左右影像上提取特征,起到并行加速的效果,如下图所示。
 在
在Frame.cc中,通过在左右影像上开两个线程实现加速。本篇博客就对这种在C++使用多线程的方式进行简单学习和介绍。
1.thread的使用
这里我们就以ORB-SLAM中的使用场景为例,读取一张影像,然后提取ORB特征。完整代码见Github项目,点击查看。下面具体介绍。
(1) 头文件与CMake配置
thread包含在thread.h中,由于是标准库支持的,所以直接#include <thread>即可。但由于pthread库不是Linux系统默认的库,可能会出现编译不通过的情况。如果这样的话,需要在CMakeLists.txt中,手动添加Link库pthread,如下所示。
cmake_minimum_required(VERSION 3.1)
project(multiThread)
set(CMAKE_CXX_STANDARD 11)
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
add_executable(multiThread main.cpp)
# 由于pthread库不是Linux系统默认的库,连接时需要指定一下,不然编译不通过
target_link_libraries(multiThread pthread ${OpenCV_LIBS})
(2) 操作函数
如果你有过一些并行编程基本概念的话应该会知道,我们需要将我们要进行的操作写成可以并行执行的函数。这里演示的代码如下所示。
void extractORB(string img_path, Mat &img_kps, vector<KeyPoint> &keyPoint, Mat &descriptor) {
// 读取影像
Mat img = imread(img_path);
// 提取ORB特征
Ptr<ORB> orb = ORB::create(2000);
orb->detectAndCompute(img, Mat(), keyPoint, descriptor);
// 绘制特征点
img.copyTo(img_kps);
drawKeypoints(img, keyPoint, img_kps);
// 对原图进行高斯模糊(单纯为了增加耗时,只提取ORB耗时太短,难以展示多线程效果)
// 如果你发现运行太慢,可以减小卷积核大小
GaussianBlur(img, img, Size(315, 315), 1.5);
}
(3) 开启多线程
多线程的开启其实非常简单,只需要构造一个thread对象,并且在构造函数中指定要执行的函数名称以及传入的参数等即可。
int main() {
string img_path = "../test.jpg";
Mat img_kps_t1, img_kps_t2;
vector<KeyPoint> keyPoint_t1, keyPoint_t2;
Mat descriptor_t1, descriptor_t2;
// 常规方式顺序执行两次
clock_t t1 = clock();
extractORB(img_path, img_kps_t1, keyPoint_t1, descriptor_t1);
extractORB(img_path, img_kps_t2, keyPoint_t2, descriptor_t2);
clock_t t2 = clock();
double dt1 = double(t2 - t1) / CLOCKS_PER_SEC;
cout << "Normal cost time: " << dt1 << " s" << endl;
Mat img_kps_th1, img_kps_th2;
vector<KeyPoint> keyPoint_th1, keyPoint_th2;
Mat descriptor_th1, descriptor_th2;
// 新建两个线程同时执行
clock_t t3 = clock();
// 这里extractORB函数后面的参数是引用传递以便接收处理的结果,因此,需要用ref()函数包裹
thread thread1(&extractORB, img_path, ref(img_kps_th1), ref(keyPoint_th1), ref(descriptor_th1));
thread thread2(&extractORB, img_path, ref(img_kps_th2), ref(keyPoint_th2), ref(descriptor_th2));
thread1.join();
thread2.join();
clock_t t4 = clock();
double dt2 = double(t4 - t3) / CLOCKS_PER_SEC;
cout << "Multi thread time: " << dt2 << " s" << endl;
// 结果展示
cout << "thread1 kps num: " << keyPoint_th1.size() << endl;
cout << "thread2 kps num: " << keyPoint_th2.size() << endl;
imshow("thread1-kps", img_kps_th1);
imshow("thread2-kps", img_kps_th2);
waitKey(0);
return 0;
}
最后需要注意的是线程执行完以后需要调用join()函数来进行同步,不然程序不等两个线程都执行完就推出了。
2.多线程的效果
如下图所示,是上面程序执行的结果。
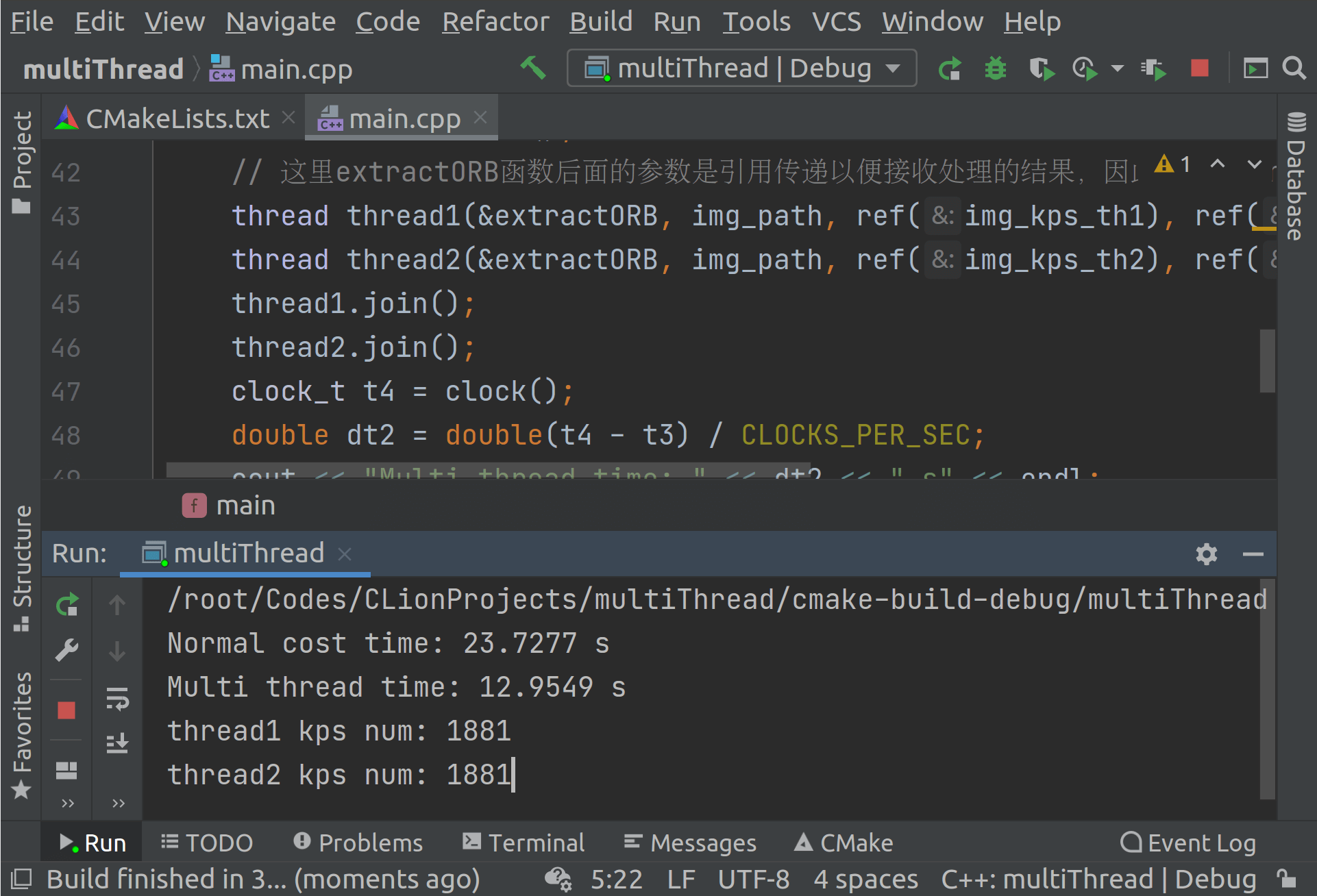
 可以看到常规方法执行2次耗时23.7s,而利用两个线程同时执行,耗时为12.9s,大约是常规方法的54%,大约是1/2。这也说明采用这种方法是可以提升效率的。另外需要说明的一点是,并非并行计算就一定很好。如果说计算量并不是很大,采用多线程并不一定有很大的效率提升,甚至还有可能出现变的更慢的情况。因为线程的创建和关闭本身也需要时间,多线程节省的时间还没有线程调度的时间多,所以就变慢了,如下所示。
可以看到常规方法执行2次耗时23.7s,而利用两个线程同时执行,耗时为12.9s,大约是常规方法的54%,大约是1/2。这也说明采用这种方法是可以提升效率的。另外需要说明的一点是,并非并行计算就一定很好。如果说计算量并不是很大,采用多线程并不一定有很大的效率提升,甚至还有可能出现变的更慢的情况。因为线程的创建和关闭本身也需要时间,多线程节省的时间还没有线程调度的时间多,所以就变慢了,如下所示。
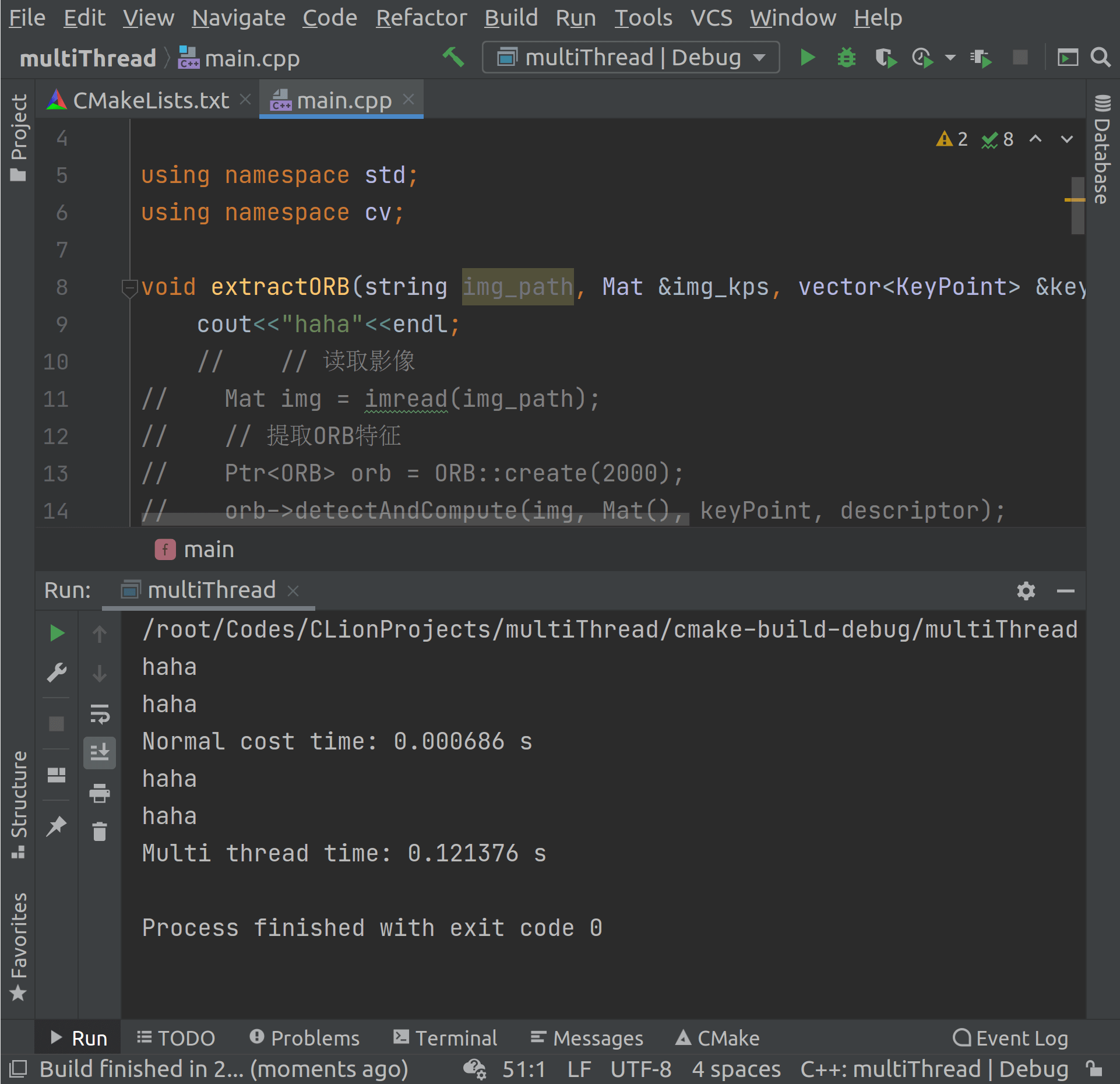 我们把
我们把extractORB函数只保留了一个输出语句,十分简单。而实际运行结果是多线程耗时0.12s,而常规方法只需要约0.6ms。从这个角度来说,这两者的差异,在一定程度上也反映了线程调度的耗时。
3.参考资料
- [1] https://www.runoob.com/w3cnote/cpp-std-thread.html
- [2] https://www.cnblogs.com/Athrun-Kido/p/13564920.html
本文作者原创,未经许可不得转载,谢谢配合
