1.背景
众所周知,现在提到深度学习就离不开PyTorch。但其实PyTorch从更广泛的意义上来说,也只是Torch的Python接口而已。只是大家现在都习惯用Python写代码,所以PyTorch比较火。但是不要忘了Torch其实还有C++的接口,名字叫libtorch。这个名字一看就很有Linux C++库的感觉,libxxx。因为最近在做一些深度学习和SLAM相结合的工作,需要在C++中调用一些神经网络。因此,本篇博客主要介绍Ubuntu下libtorch如何安装以及简单的使用。
2.安装
libtorch安装有两种方式,一种是从源码编译,一种是下载已经编译好的文件。如果没有特殊需求的话,这里推荐第二种方式,直接下载库文件。另外libtorch和PyTorch一样,也有CPU和GPU两个版本,下载的时候需要注意一下。
(1) 查看CUDA版本
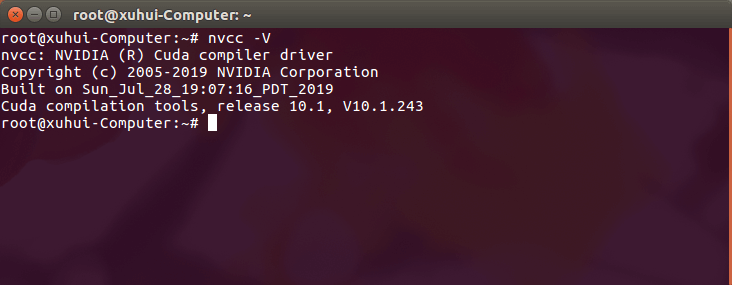
首先,建议先查看一下自己电脑上的CUDA版本,终端中输入nvcc -V即可。例如在我的电脑上CUDA版本是10.1。
(2) 下载文件
在知道CUDA版本以后,就可以根据需求下载对应的libtorch文件了。这里需要注意一下libtorch不同版本之间的API差异可能较大,所以建议提前确定好要下载的版本,不要太奇怪,以防止不兼容。而且新版本的libtorch只支持用C++14标准,而如果你现有项目是C++11标准就会比较麻烦。
下载地址可以在这里查看。比如我选择的是CUDA 10.1对应的libtorch 1.3.0版本。
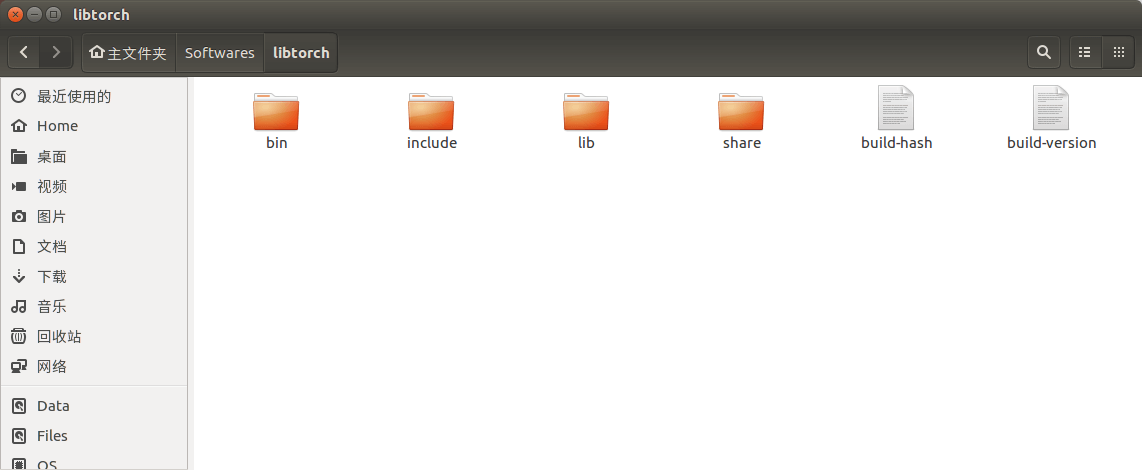
下载完成后,你会得到一个压缩包。剩下需要做的就是将这个压缩包解压到你想要放的位置,libtorch就“安装”成功了。解压之后的内容如下图所示。
(3) 潜在依赖cuDNN
在实际测试中发现,libtorch可能还会需要安装cuDNN。官网是这里。安装的步骤也十分简单粗暴。首先我们在这里下载对应的cuDNN库文件(注意和CUDA的版本对应关系)。下载完成后,你同样会得到一个压缩包,然后进行解压,就可以得到一个叫做cuda的文件夹。然后在当前目录下打开终端,依次输入下面的命令即可完成安装。
cp cuda/include/cudnn.h /usr/local/cuda/include/
cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
chmod a+r /usr/local/cuda/include/cudnn.h
chmod a+r /usr/local/cuda/lib64/libcudnn*
复制完成之后,这个cuda文件夹就可以删掉了。而如何查看cuDNN版本也非常简单,在终端中输入如下命令即可。
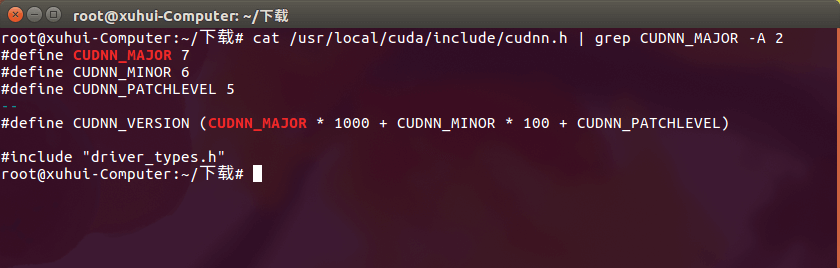
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
如果你安装了,就会正常输出如下内容,本机中的cuDNN是7.6.5。
 否则就说明没有安装。从这个角度来说,cuDNN的“卸载”就是上面这些操作的逆操作。事实上,在有些可带可不带cuDNN的时候,带cuDNN编译反而容易出错,不带cuDNN就可以正常通过。所以如果你编译项目的时候遇到cuDNN相关的错误,不妨先把机器上的cuDNN先“卸载”一下。其实就是把
否则就说明没有安装。从这个角度来说,cuDNN的“卸载”就是上面这些操作的逆操作。事实上,在有些可带可不带cuDNN的时候,带cuDNN编译反而容易出错,不带cuDNN就可以正常通过。所以如果你编译项目的时候遇到cuDNN相关的错误,不妨先把机器上的cuDNN先“卸载”一下。其实就是把/usr/local/cuda/include/cudnn.h文件换个名字什么的,让系统找不到就可以了。
3.测试
(1) CMake写法
细心的你可能已经注意到了,这样简单粗暴的安装,CMake是不可能自动找到libtorch库的。所以我们需要在CMake文件中显式地指定libtorch的路径。本机中libtorch的路径为/root/Softwares/libtorch,所以CMake文件应该这样写:
cmake_minimum_required(VERSION 3.15)
project(libtorchDemo)
set(CMAKE_CXX_STANDARD 11)
set(Torch_DIR /root/Softwares/libtorch/share/cmake/Torch)
find_package(Torch REQUIRED)
add_executable(libtorchDemo main.cpp)
target_link_libraries(libtorchDemo ${TORCH_LIBRARIES})
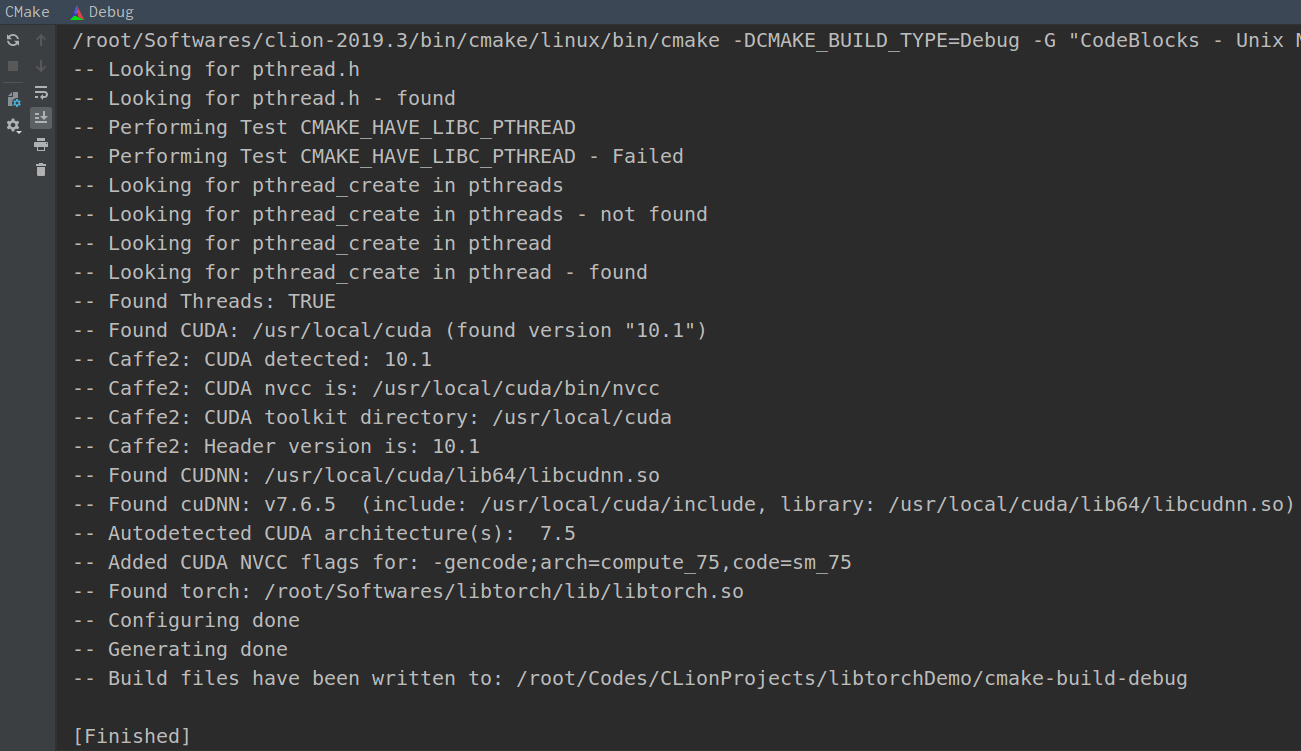
正常情况下,CMake的输出如下。
(2) 代码调用
在代码中,我们至少需要包含torch/torch.h。一个非常简单的打印GPU是否可用的代码如下。
#include <iostream>
#include <torch/torch.h> // libtorch头文件
using namespace torch; // libtorch命名空间
using namespace std;
int main() {
// 分别打印CUDA、cuDNN是否可用以及可用的CUDA设备个数
// 可以发现函数名是和PyTorch里一样的
cout << torch::cuda::is_available() << endl;
cout << torch::cuda::cudnn_is_available() << endl;
cout << torch::cuda::device_count() << endl;
return 0;
}
代码执行效果如下。
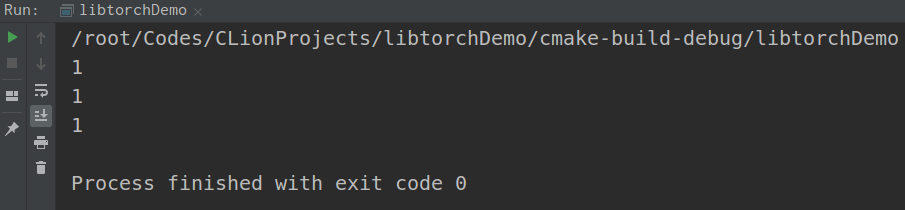 也就是说,本机上CUDA、cuDNN都可以使用,CUDA设备数为1。
也就是说,本机上CUDA、cuDNN都可以使用,CUDA设备数为1。
(3) 进阶示例
这里我们以一个实际暗光增强的网络DCE作为例子。DCE全程Deep Curve Estimation,Github主页见这里。
a.模型的训练与保存
这里使用已经打包好的DCE网络文件,由我的学弟Wu Xin训练并提供,已经放到了Github项目中,点击查看。对于libtorch而言,其一般调用的是.pt文件,而PyTorch一般保存的是.pth文件。因此这就涉及到转换的问题。由.pth到.pt的转换也非常简单。简单来说就是调用PyTorch提供的torch.jit.trace函数即可。详情可以参考这个网页。如下展示的是将SuperPoint的模型文件转成.pt文件的代码。
import torch
import singleImg_wx2
import numpy as np
sp_net = singleImg_wx2.SuperPointNet().cuda()
sp_net.load_state_dict(torch.load('superpoint_v1.pth'))
example = torch.rand(1,1,640,480).cuda()
torch.jit.trace(sp_net, example).save('./superpoint_test.pt')
对于trace()这个函数,简单来说,只需要传入网络模型,以及一个示例数据,即可导出模型,十分简单。
b.模型调用
在C++中,同样可以通过torch::jit::load()函数进行加载,核心代码如下。
#include <iostream>
// torch相关引用
#include "torch/torch.h"
#include "torch/script.h"
// OpenCV相关引用
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
using namespace torch;
using namespace std;
using namespace cv;
int main() {
// 感谢Wu Xin提供的训练好的DCE网络模型(打包Torch版本1.0.0)
string model_path = "../DCE.pt";
string img_path = "../test.png";
// 加载模型
cout << "Loading low-light model" << endl;
std::shared_ptr<torch::jit::script::Module> module = torch::jit::load(model_path);
cout << "Initialized low-light model" << endl;
torch::DeviceType device_type;
device_type = torch::kCUDA;
torch::Device device(device_type);
Mat im = imread(img_path, IMREAD_COLOR);
Mat normedImg;
// 影像灰度归一化,img是OpenCV的float32的Mat类型
im.convertTo(normedImg, CV_32FC3, 1.f / 255.f, 0);
int img_width = im.cols;
int img_height = im.rows;
// 将OpenCV的Mat类型构造成Tensor,然后再转换成可求导的变量
auto img_tensor = torch::CPU(torch::kFloat32).tensorFromBlob(normedImg.data, {1, img_height, img_width, 3});
img_tensor = img_tensor.permute({0, 3, 2, 1});
auto img_var = torch::autograd::make_variable(img_tensor, false).to(device);
// 前向推理
std::vector<torch::jit::IValue> inputs;
inputs.push_back(img_var);
auto output = module->forward(inputs).toTuple();
// 后处理
auto img_enhanced = output->elements()[1].toTensor().to(torch::kCPU).squeeze();
cv::Mat img_enhanced_cv(cv::Size(img_height, img_width), CV_32FC1, img_enhanced.data<float>());
cv::Mat img_post;
cv::transpose(img_enhanced_cv, img_post);
cv::Mat final_img(img_width, img_height, CV_8UC3);
img_post = img_post * 255;
img_post.convertTo(final_img, CV_8UC3);
final_img.convertTo(final_img, CV_8UC1);
imshow("enhanced img", final_img);
imshow("raw img", im);
waitKey(0);
return 0;
}
运行之后,可以看到效果如下。
 影像中较暗的部分被很好地增强了。最后,本篇博客中所有的代码全部上传到了Github上,点击查看,欢迎Fork或Star。
影像中较暗的部分被很好地增强了。最后,本篇博客中所有的代码全部上传到了Github上,点击查看,欢迎Fork或Star。
4.参考资料
- [1] https://blog.csdn.net/lxx4610/article/details/105806017/
- [2] https://blog.csdn.net/wanzhen4330/article/details/81699769
- [3] https://blog.csdn.net/yz2zcx/article/details/100609210
本文作者原创,未经许可不得转载,谢谢配合
