Notes for CUDA on ARM Platform Summer Camp Day1.由于只记录了一些我认为比较重要的东西,笔记内容可能并非非常完整,完整内容可以直接参考课程视频,点击查看百度云,密码2qom。但我尽量保证了笔记内容的逻辑性和整体性,方便其他人阅读。

1.L4T Ubuntu基础
(1)什么是L4T
Linux系统发展简史如下。
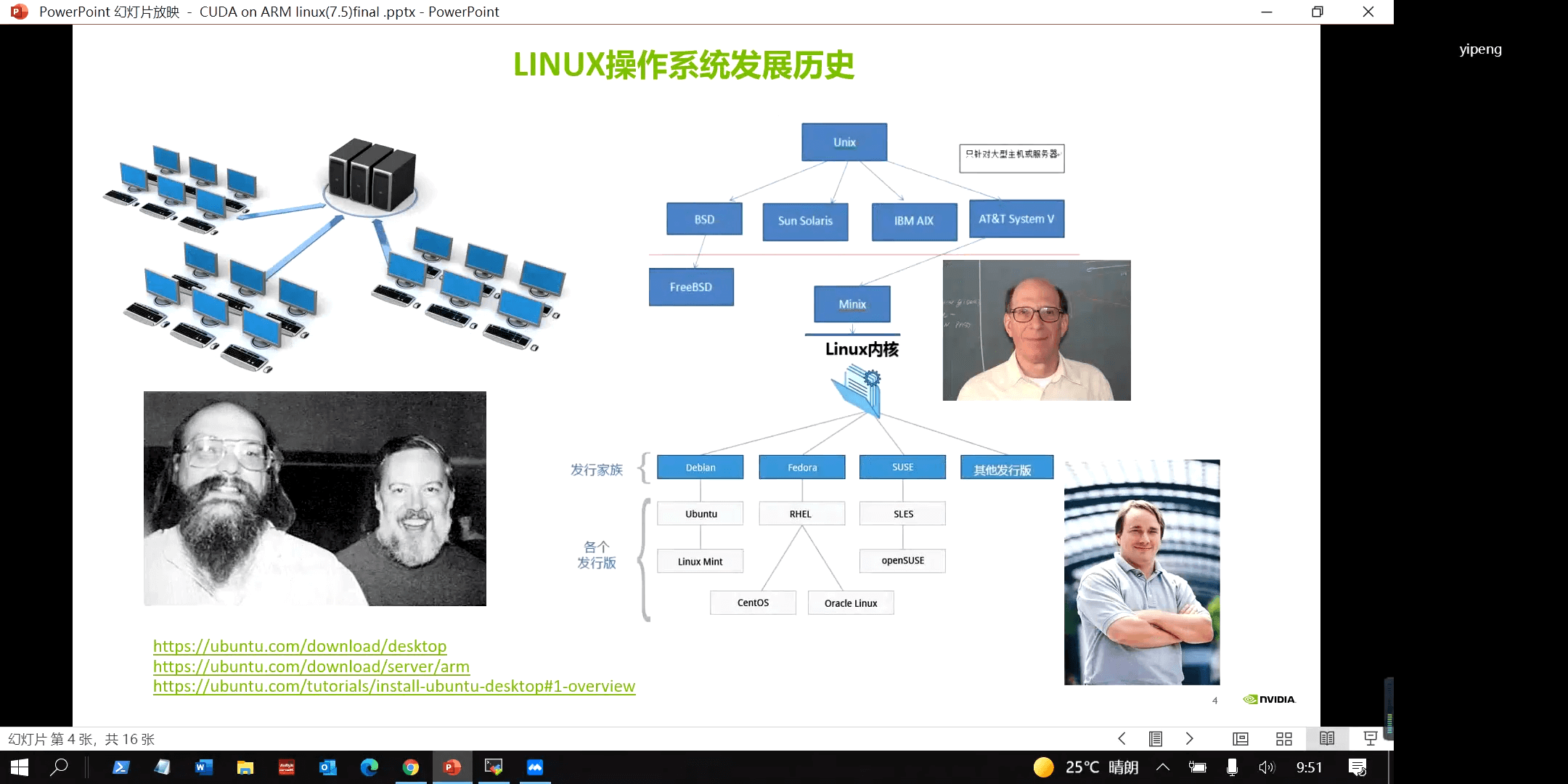 而我们要使用的是L4T,它是Linux For Tegra的缩写,如下。
而我们要使用的是L4T,它是Linux For Tegra的缩写,如下。
- L4T - Linux for Tegra
所以它可以看作是专门为Tegra处理器定制的Linux版本。而Tegra是NVIDIA推出的基于ARM架构的通用处理器系列,是一种系统芯片(SoC),融合了ARM架构的CPU和NVIDIA的GPU。
(2)L4T Ubuntu和X86 Ubuntu
而L4T Ubuntu和X86 Ubuntu的对比如下。
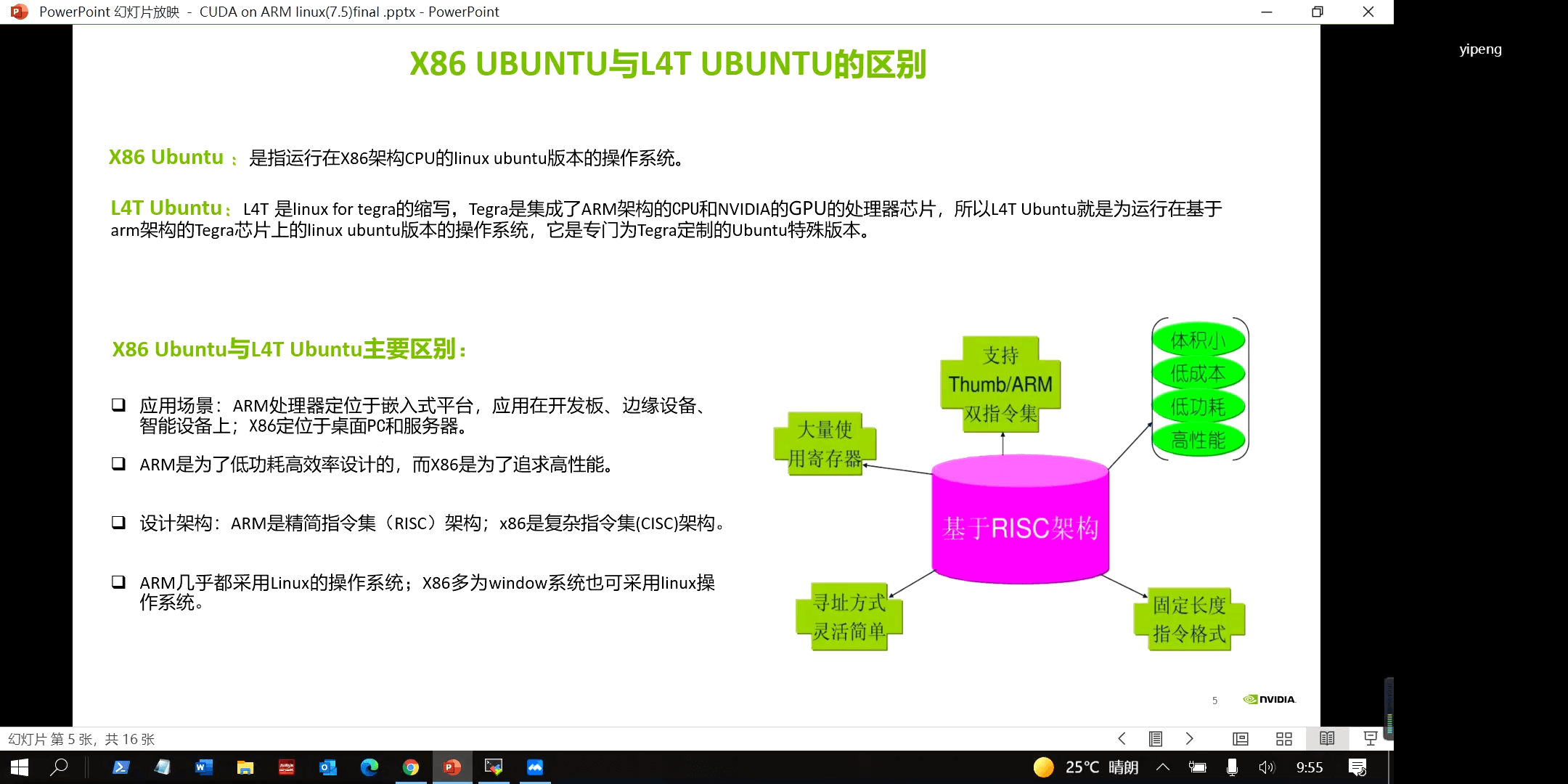 从更抽象的概念来说,两者的区别就是X86架构和ARM架构的区别了,如上图所示。
从更抽象的概念来说,两者的区别就是X86架构和ARM架构的区别了,如上图所示。
(3)Jtop工具
在之前这篇博客中也介绍了Jtop工具,是一个和htop类似的查看系统状态的命令。由于Jetson平台无法使用nvidia-smi命令查看GPU相关信息,jtop就成为了最方便的工具。
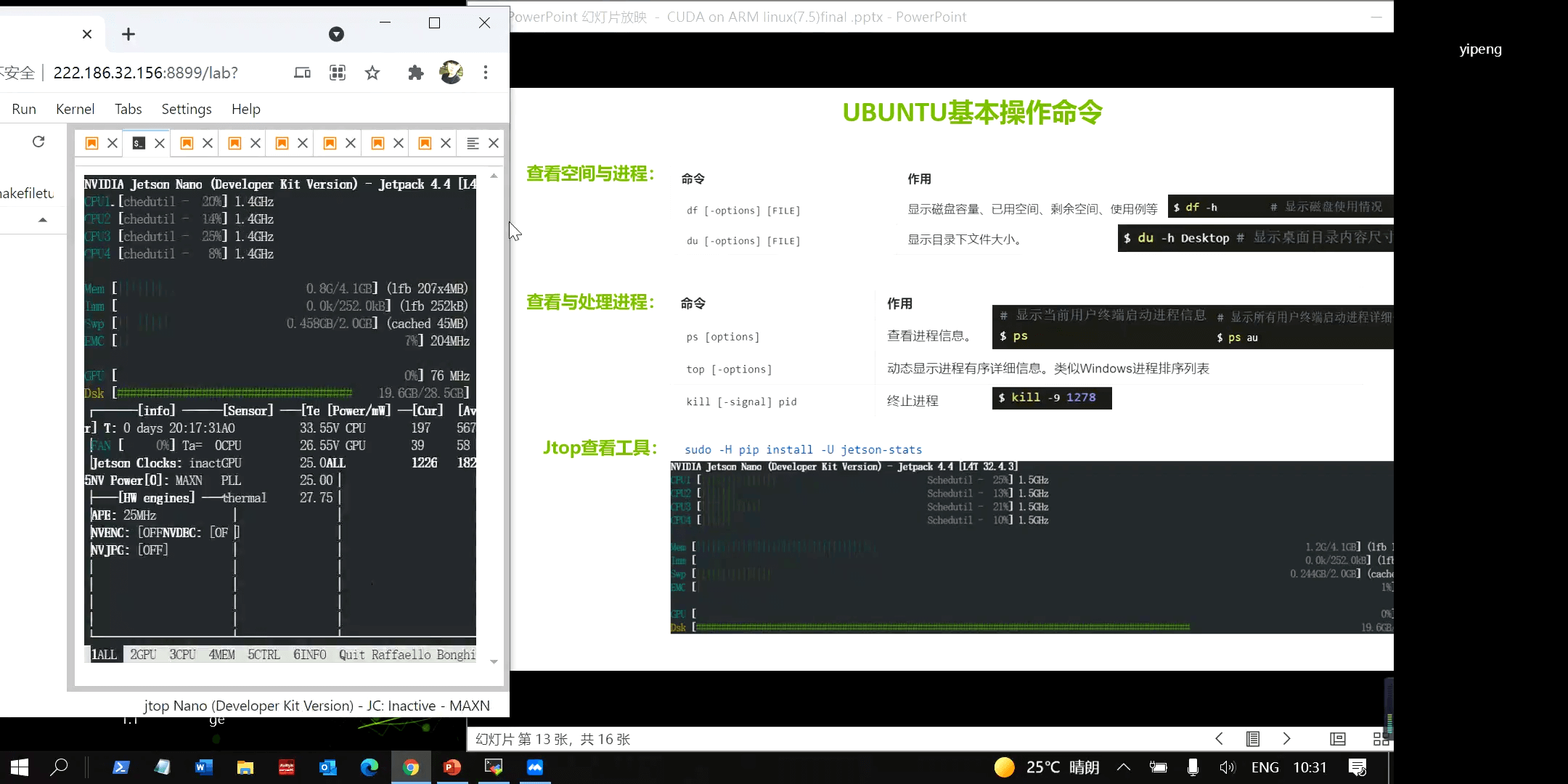 小结就是,对于服务器、工作站、个人电脑等,使用nvidia-smi查看设备中的GPU状态,对于Jetson设备,使用jtop查看。
小结就是,对于服务器、工作站、个人电脑等,使用nvidia-smi查看设备中的GPU状态,对于Jetson设备,使用jtop查看。
2.实验相关环境
实验硬件平台使用的Jetson NANO相关参数如下。
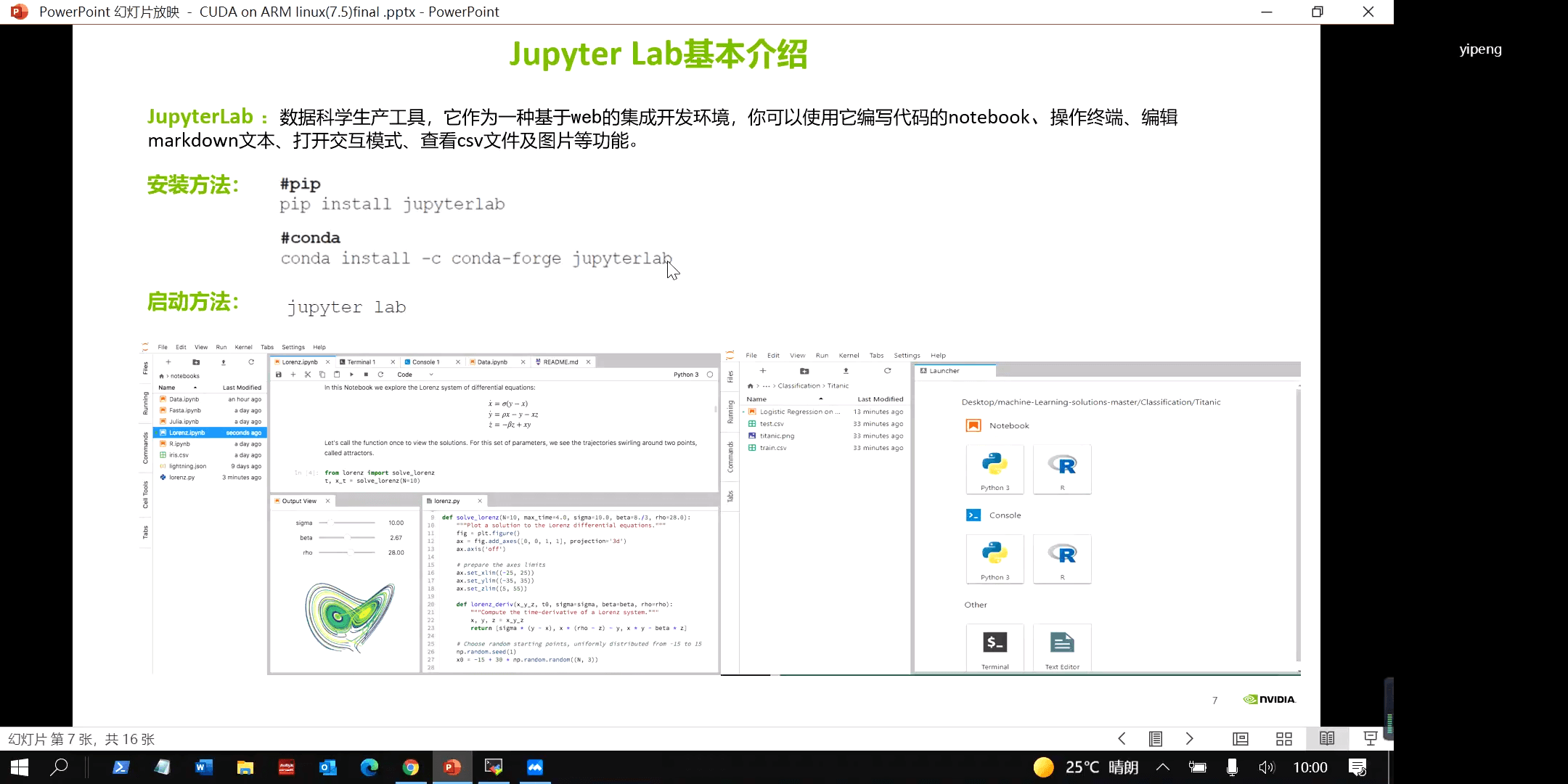
 实验软件平台使用过的是Jupyter Lab,一个基于Web的集成开发环境,简介如下。
实验软件平台使用过的是Jupyter Lab,一个基于Web的集成开发环境,简介如下。
3.Makefile基本介绍
在之前的绝大多数项目中,我们都是使用CMake生成Makefile文件,所以其实我们并不陌生。它就是一个自动化的编译脚本,指定需要编译哪些代码、依赖哪些内容。它有它自己的语法,简单来说就是“目标+依赖+执行命令”。对于这个文件我们当然可以手写,但一般情况下都是直接用CMake自动生成了,所以直接接触它的机会不多。
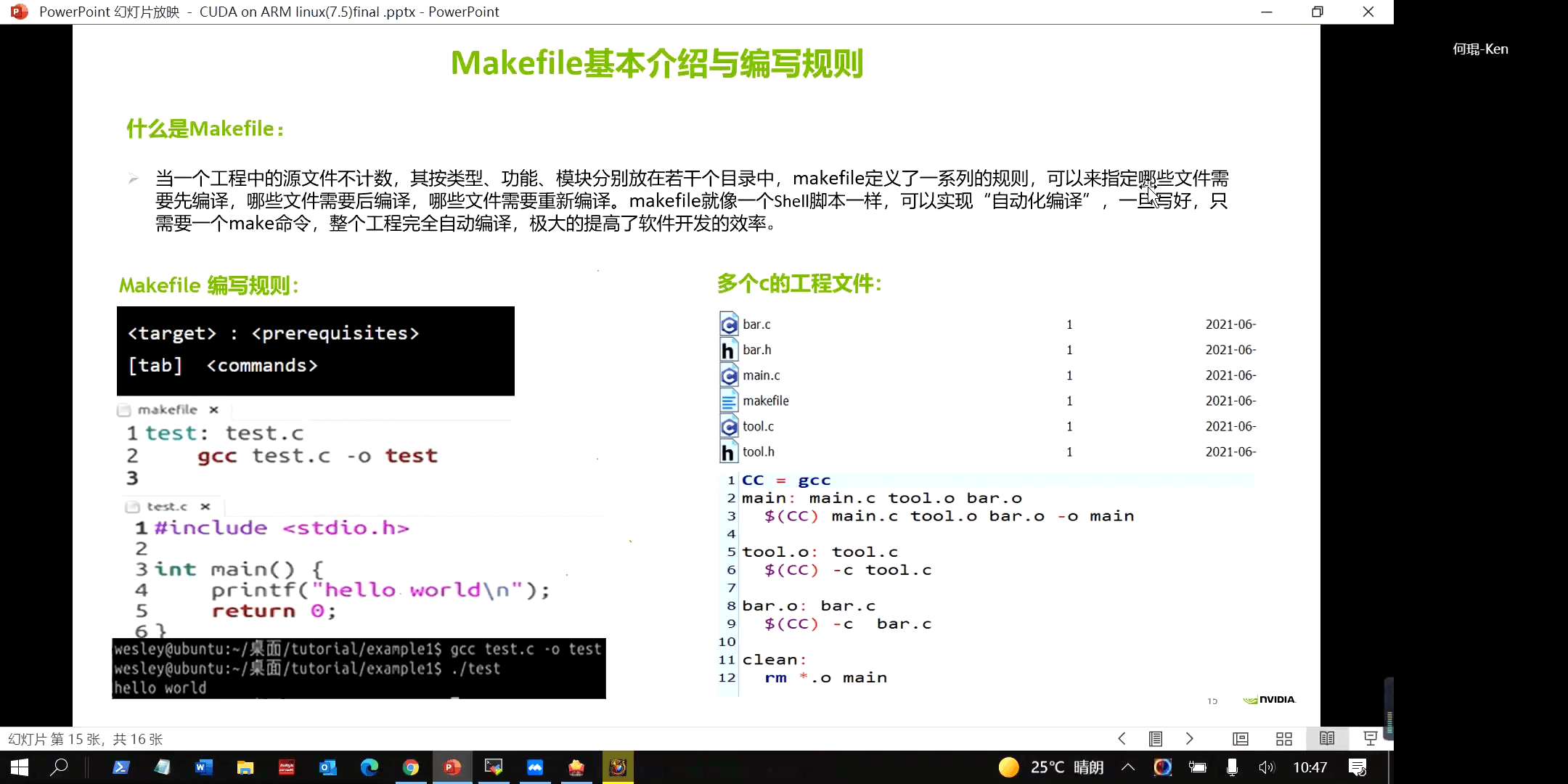 另外这里可以简单总结一下CMake、Makefile、gcc/nvcc之间的关系。gcc/nvcc是最直接的编译命令,可以直接用来编译代码。但是如果代码一多一点点手写就比较麻烦,所以Makefile就出现了。通过将多个gcc命令写在Makefile脚本里,实现了一定程度上的编译自动化。但是Makefile还是不够方便,所以CMake就出现了,用于自动生成Makefile文件。Cmake生成Makefile文件,Makefile文件又调用gcc/nvcc等编译器,最终生成可执行程序。
另外这里可以简单总结一下CMake、Makefile、gcc/nvcc之间的关系。gcc/nvcc是最直接的编译命令,可以直接用来编译代码。但是如果代码一多一点点手写就比较麻烦,所以Makefile就出现了。通过将多个gcc命令写在Makefile脚本里,实现了一定程度上的编译自动化。但是Makefile还是不够方便,所以CMake就出现了,用于自动生成Makefile文件。Cmake生成Makefile文件,Makefile文件又调用gcc/nvcc等编译器,最终生成可执行程序。
4.GPU硬件架构
 CUDA架构如下:
CUDA架构如下:
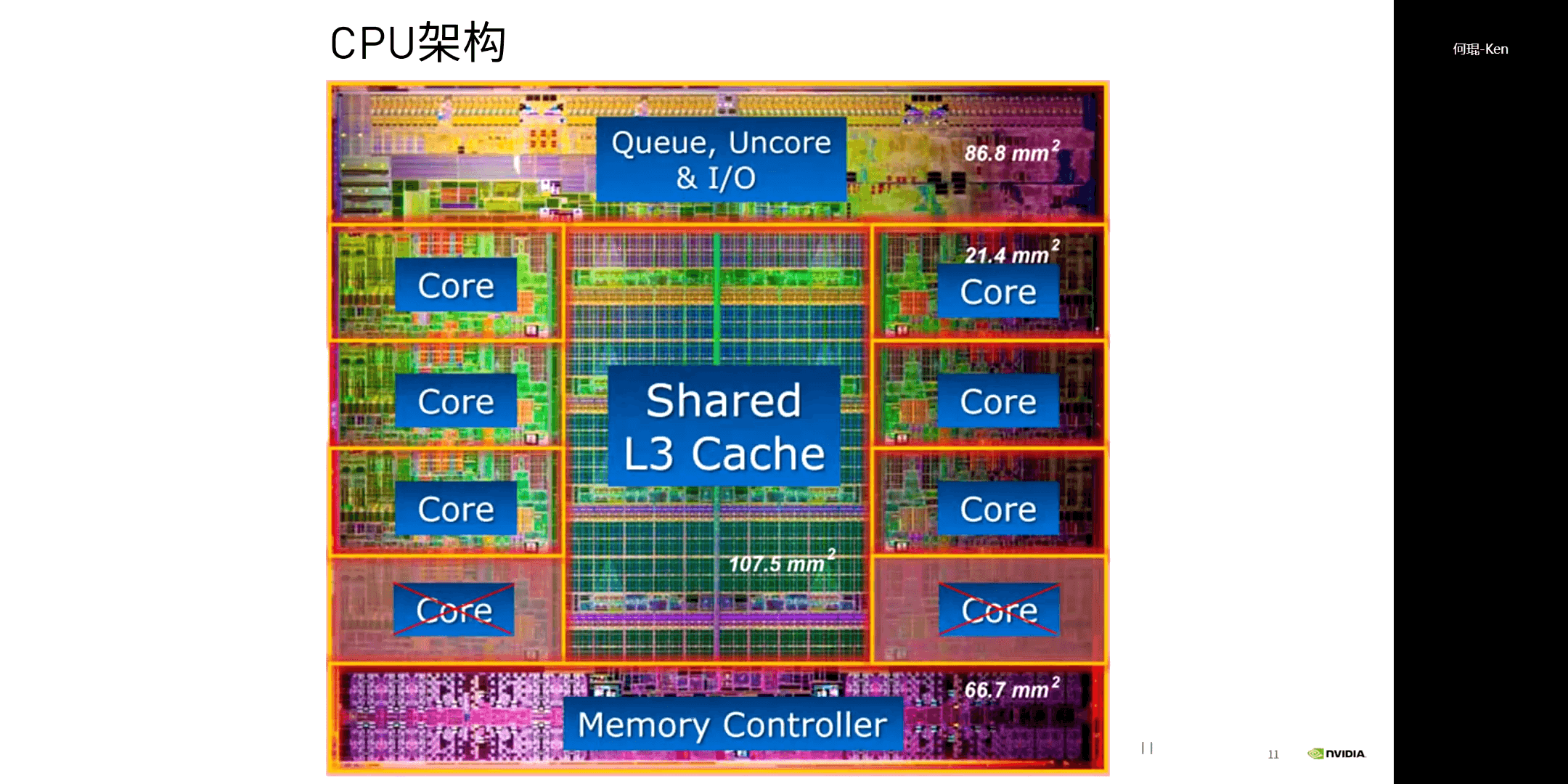
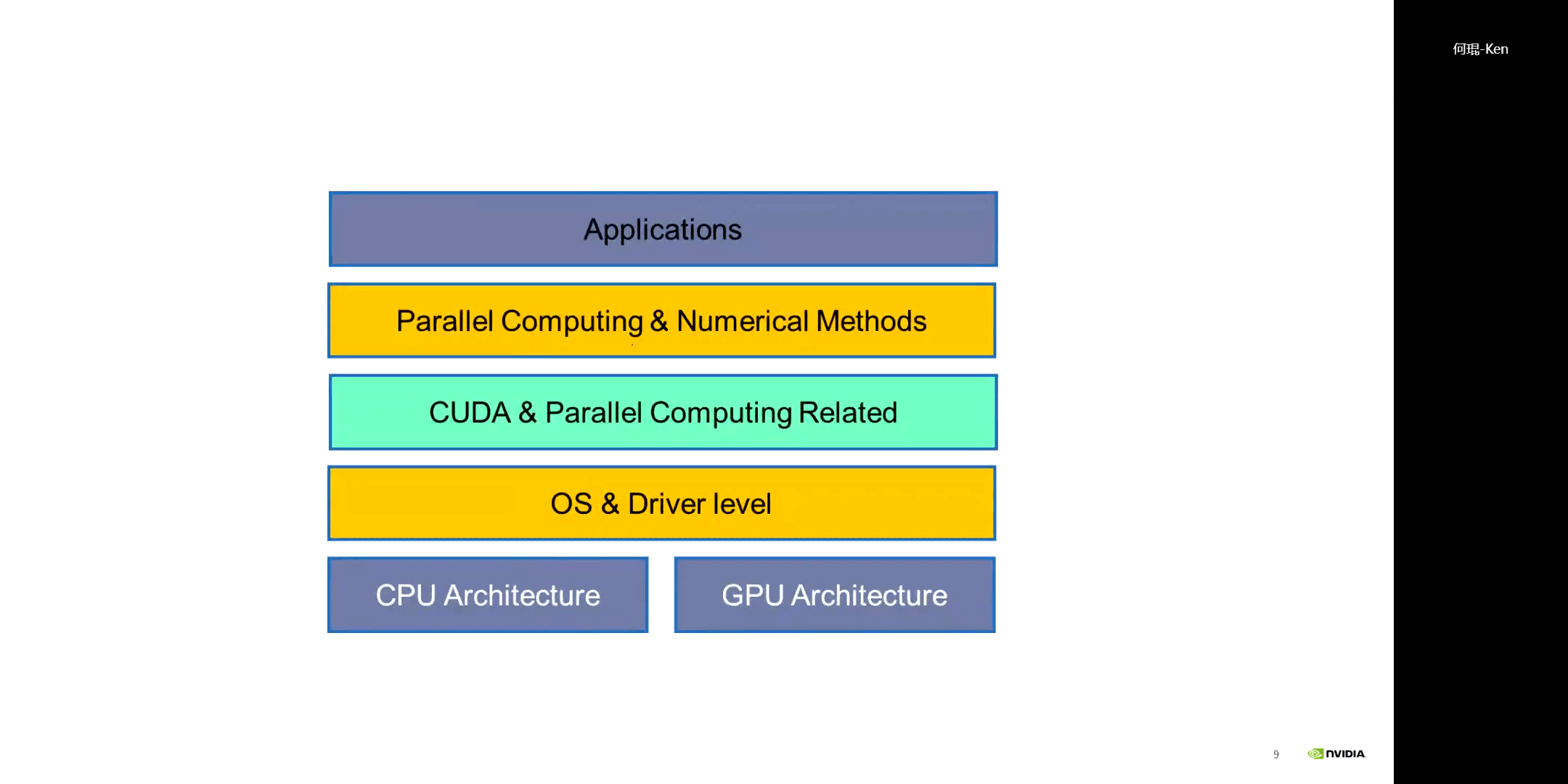 一个典型的CPU架构如下:
一个典型的CPU架构如下:
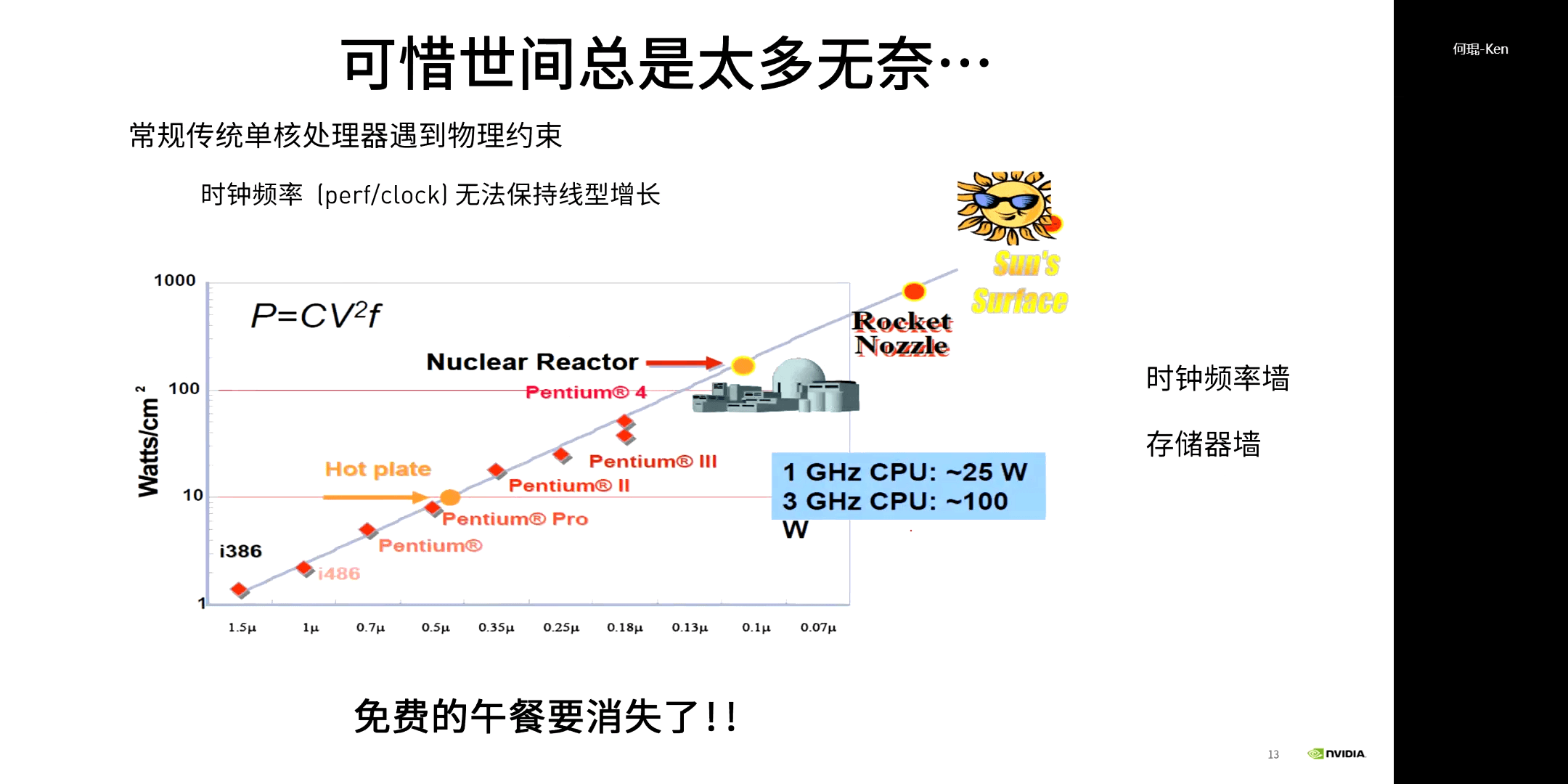
 要想提升性能,就要在单位面积内不断增加晶体管数量。但在实际中,会有物理极限的存在:时钟频率墙和存储器墙。
要想提升性能,就要在单位面积内不断增加晶体管数量。但在实际中,会有物理极限的存在:时钟频率墙和存储器墙。
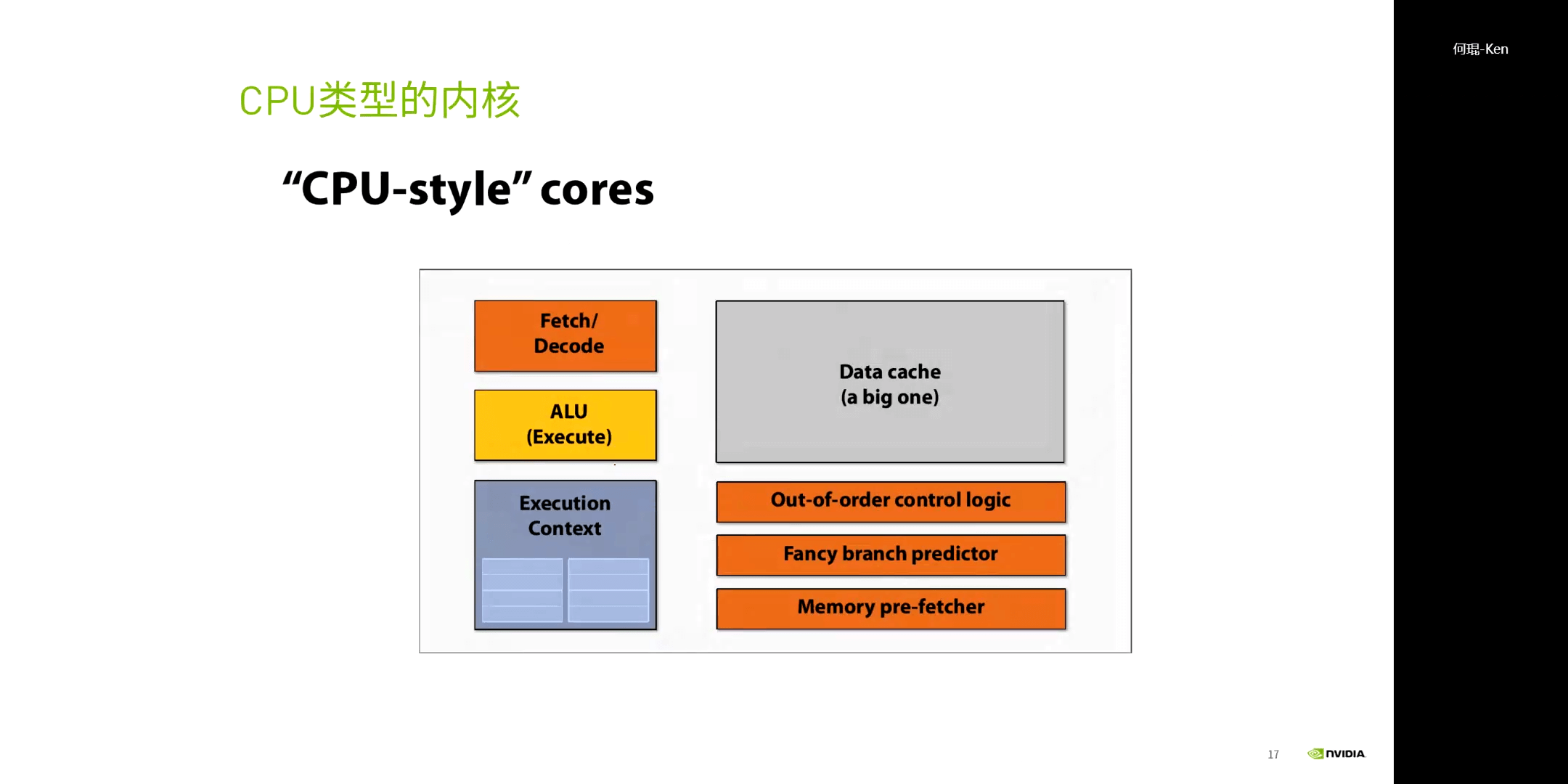
 因此,GPU应运而生。
因此,GPU应运而生。


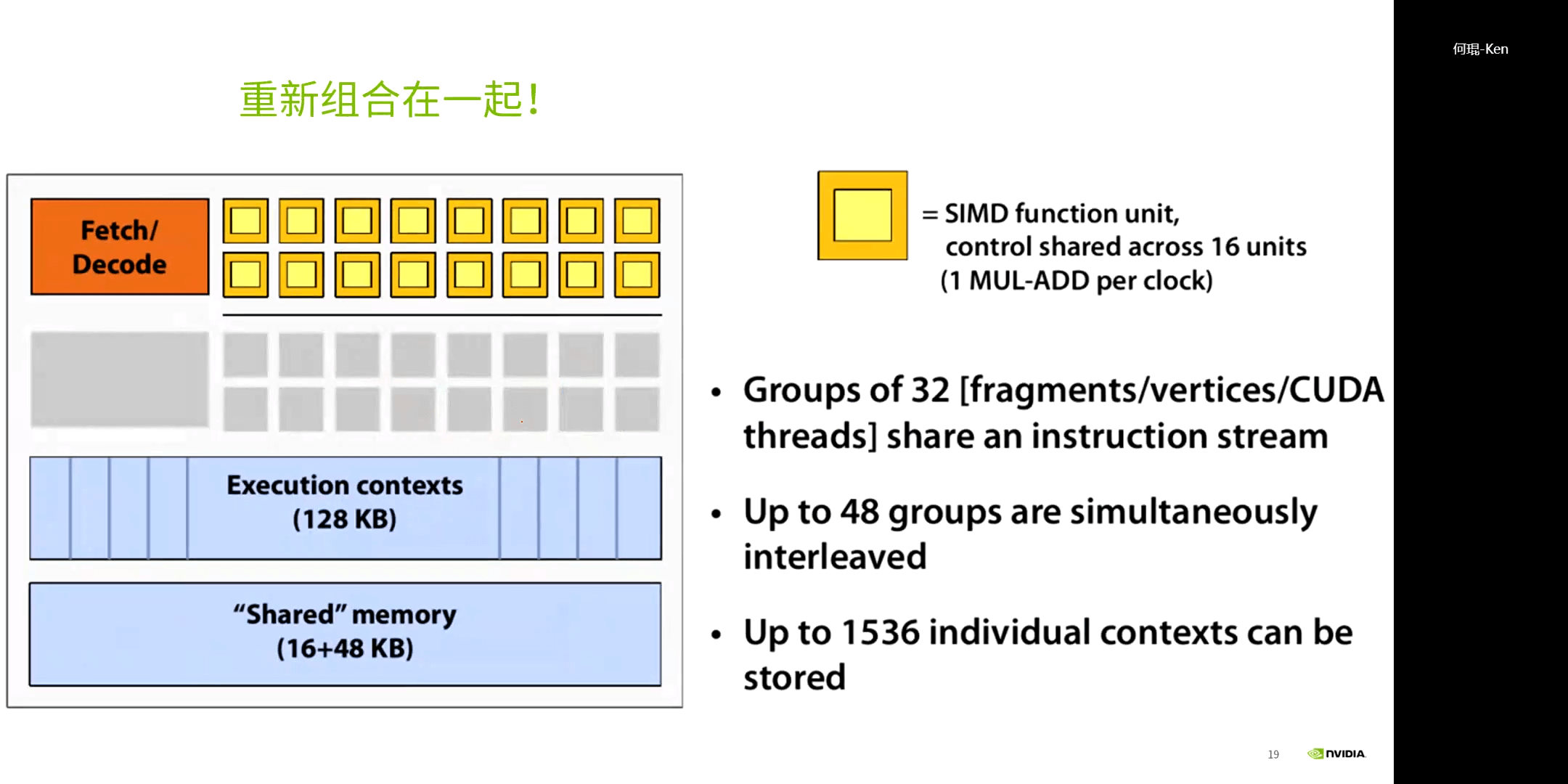
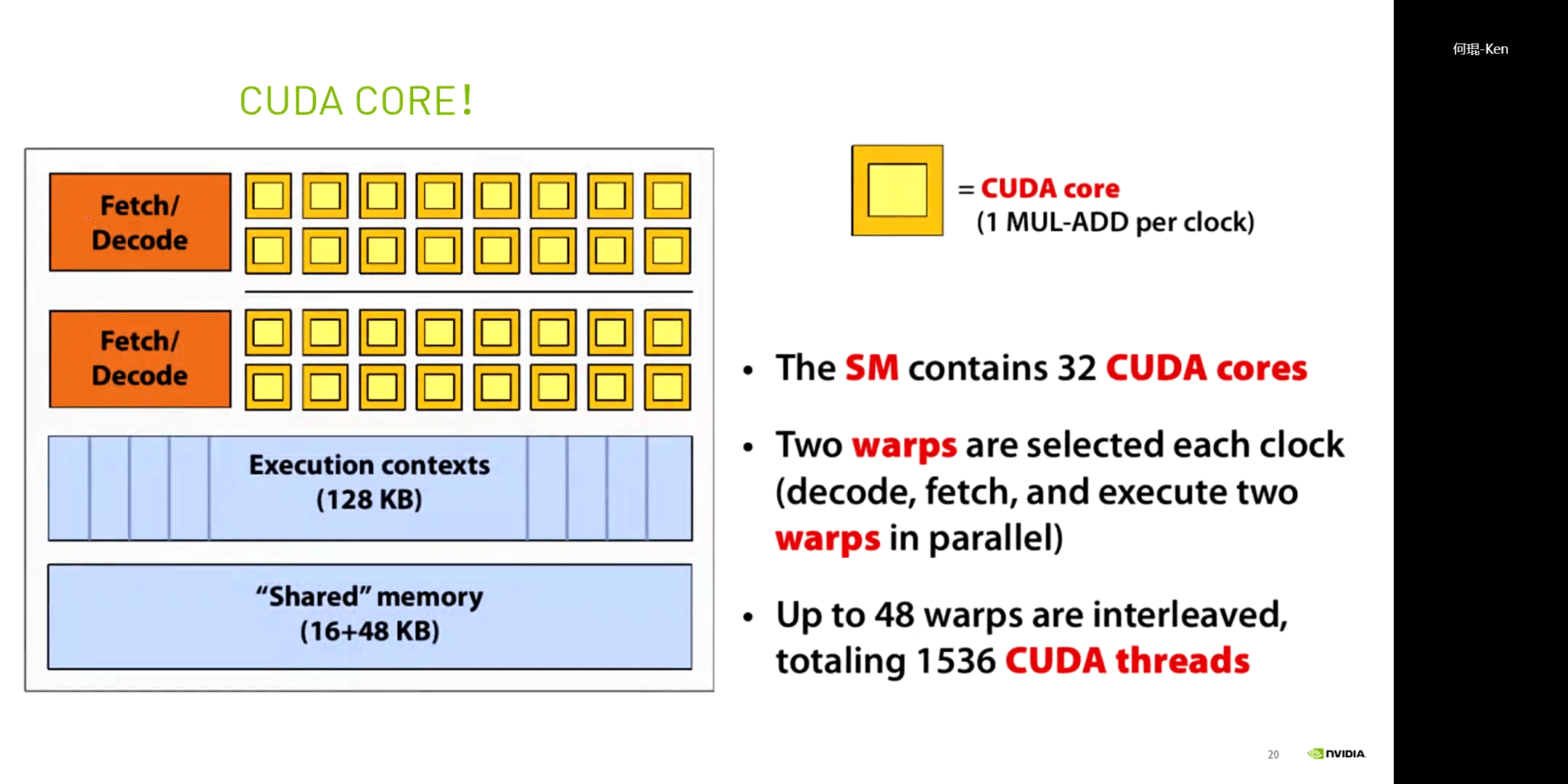 每16个CUDA核共享一个控制器,每32个CUDA核构成一个SM,如上图所示。在物理层面,每32个核心构成一个warp(束)。一个典型的CPU和GPU架构的对比图如下所示。
每16个CUDA核共享一个控制器,每32个CUDA核构成一个SM,如上图所示。在物理层面,每32个核心构成一个warp(束)。一个典型的CPU和GPU架构的对比图如下所示。
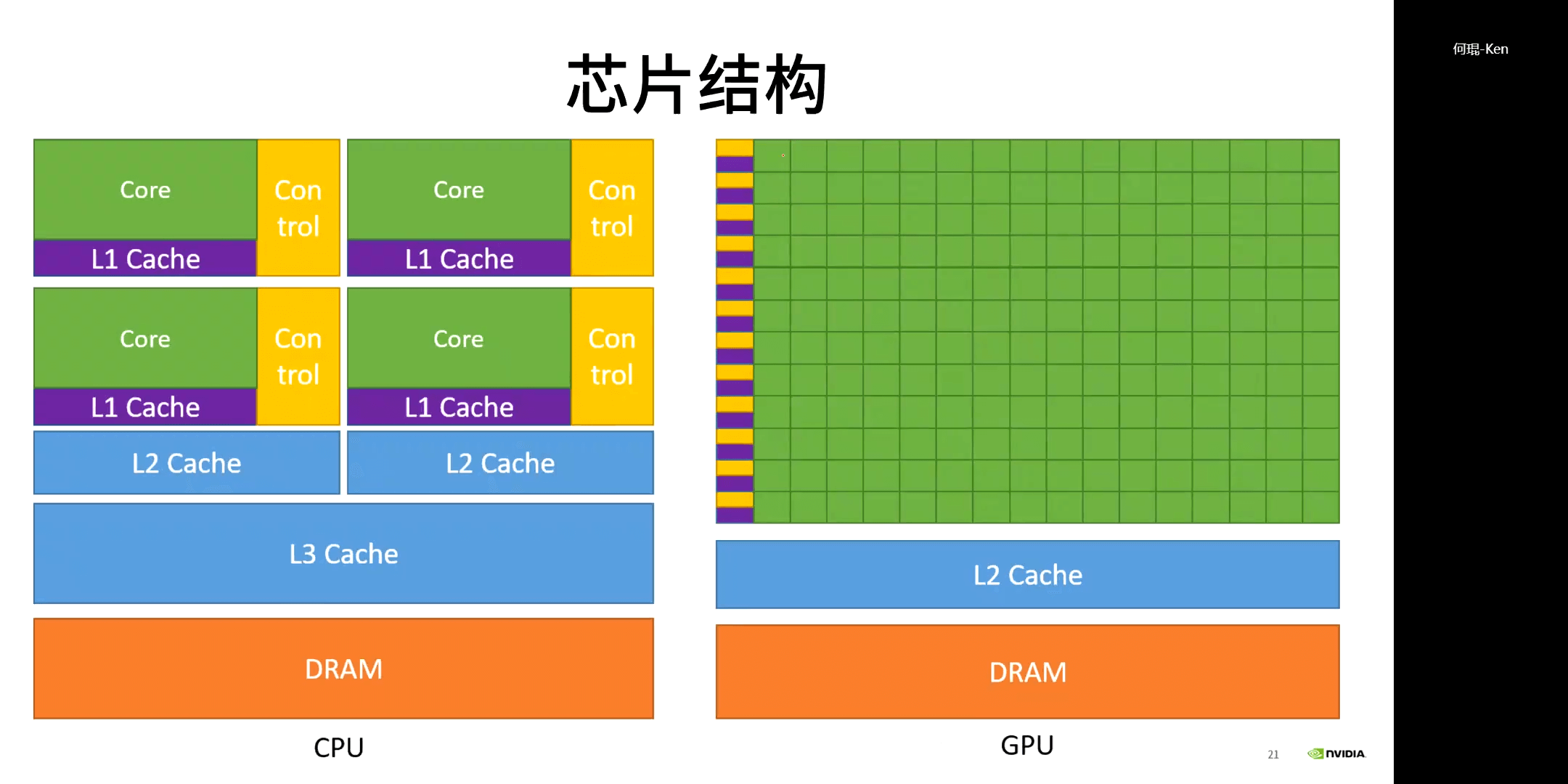 简而言之,CPU适合处理串行任务,GPU适合处理并行任务,如下所示。
简而言之,CPU适合处理串行任务,GPU适合处理并行任务,如下所示。
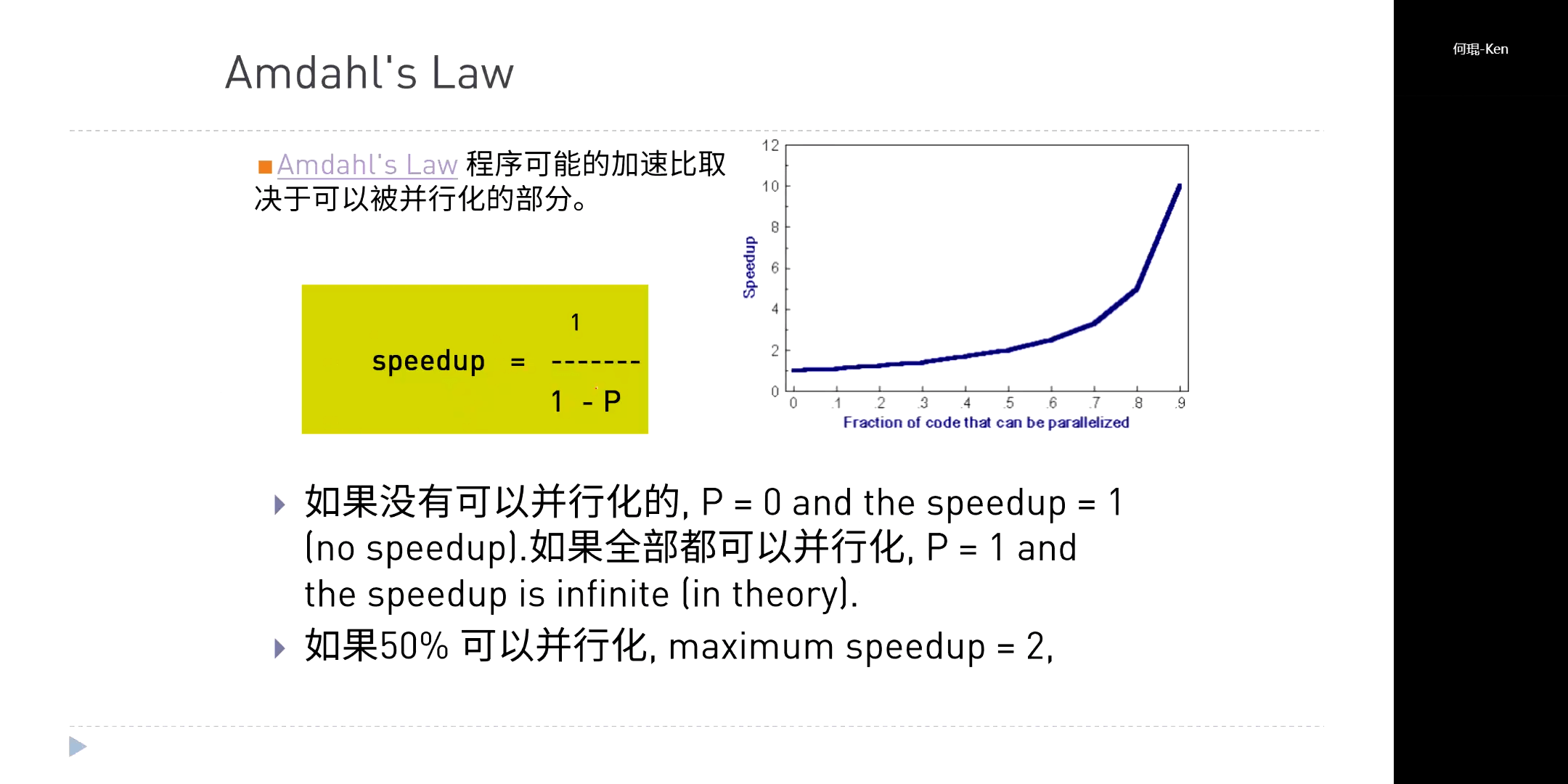
 GPU适合单一指令或少指令的大数据集任务。我们可以用加速比这个概念定量的描述,如下所示。
GPU适合单一指令或少指令的大数据集任务。我们可以用加速比这个概念定量的描述,如下所示。

5.初识CUDA
(1)基础知识
 异构计算。简单来说就是一个程序的代码既有CPU部分又有GPU部分,需要他们合作才能得到结果。
异构计算。简单来说就是一个程序的代码既有CPU部分又有GPU部分,需要他们合作才能得到结果。
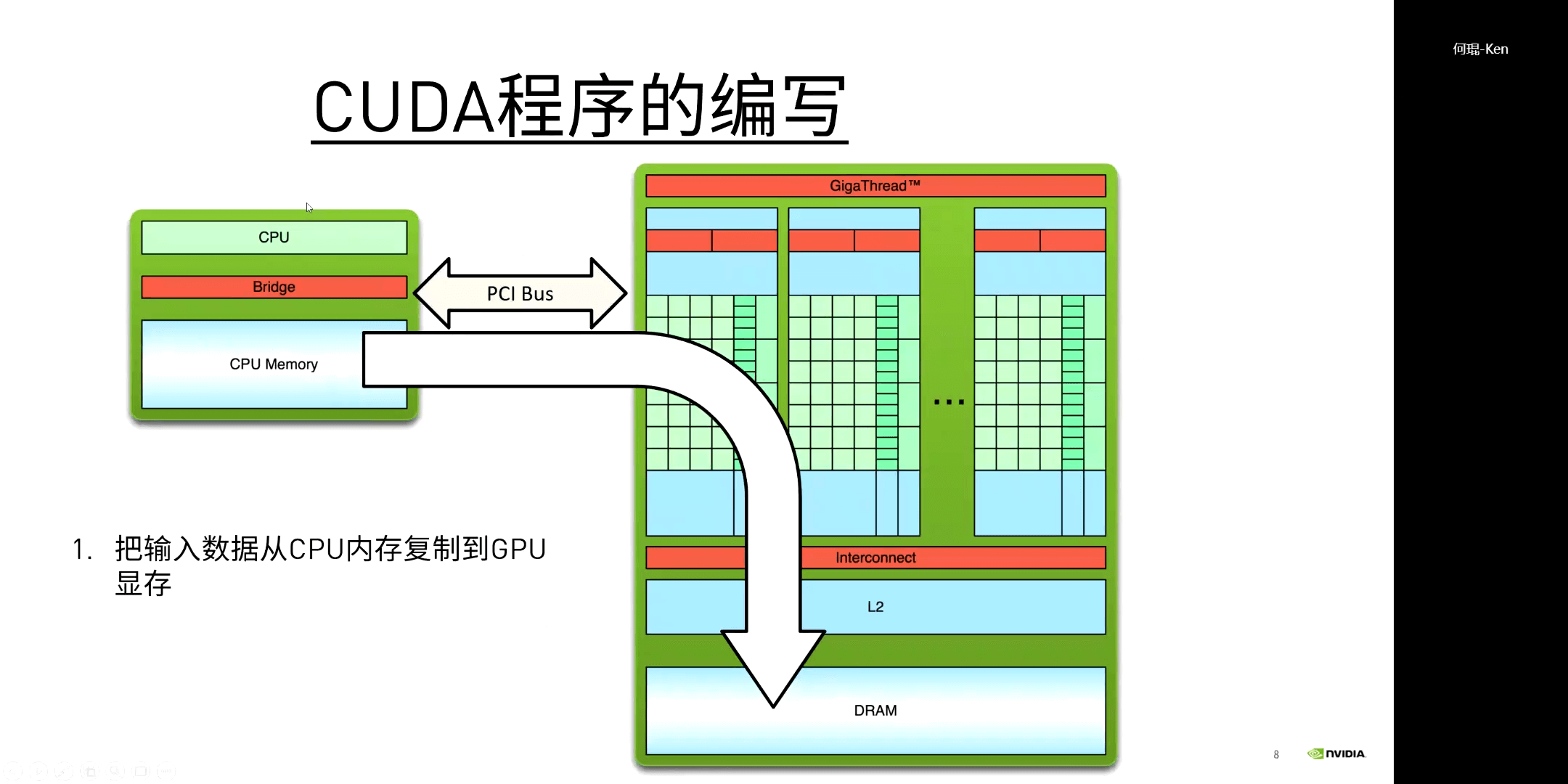
 而对于CUDA程序的执行流程,其实也是很容易理解的,如下图所示。
而对于CUDA程序的执行流程,其实也是很容易理解的,如下图所示。
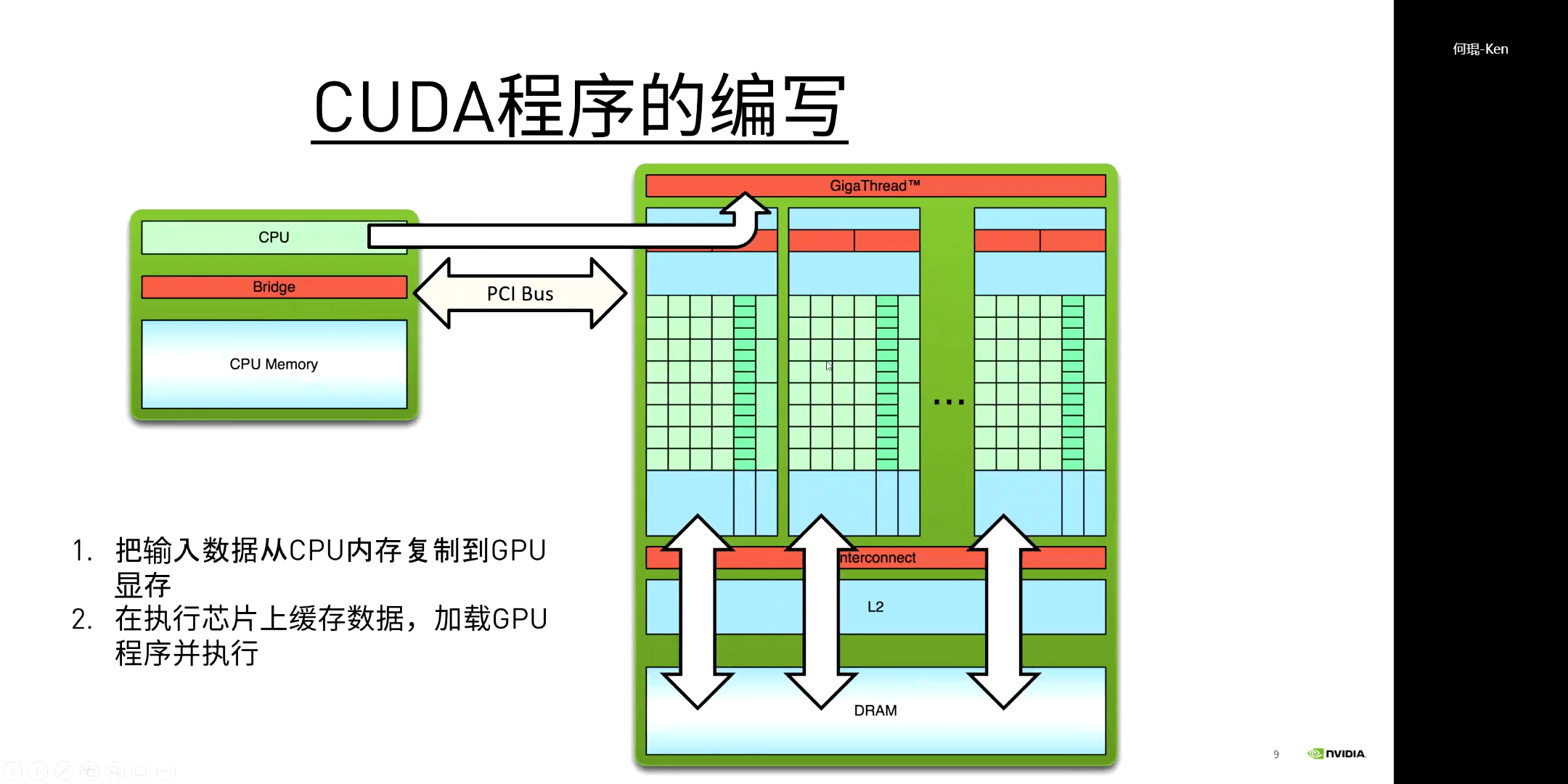
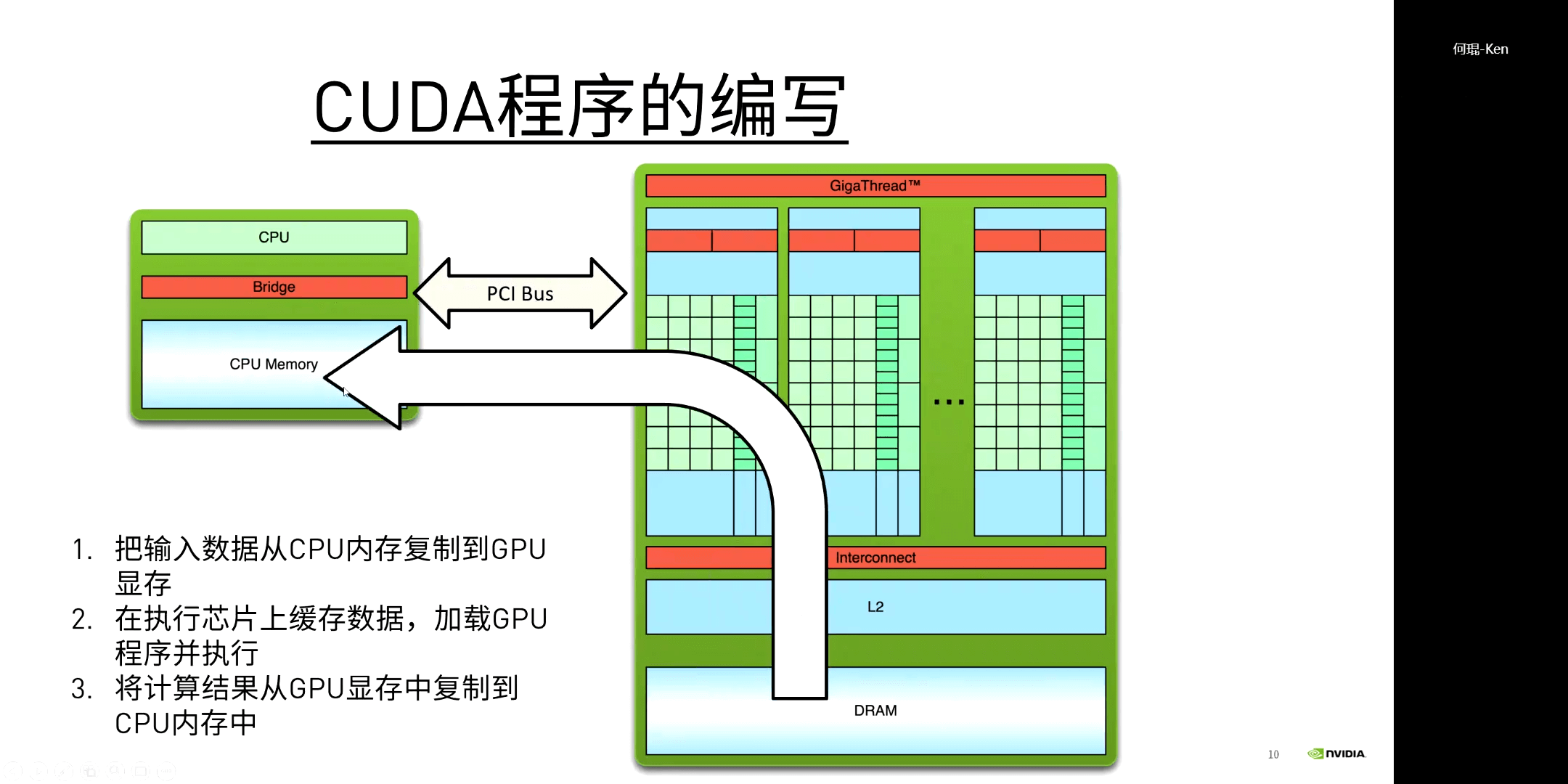
(2)基本语法
CUDA遵循Extended C语法,在实际测试中,使用C/C++的语法都是可以的。
CUDA中的__global__变量/函数可以在Host或者Device端调用,__device__变量/函数只能在Device端调用,__host__变量/函数只能在Host端调用。
 CUDA函数在调用的时候,除了像常规函数一样需要传入参数(如果有的话),还要指定“执行设置”(execution configuration),也就是需要显式地指定需要多少个线程。具体而言,通过三个尖括号指定,如下图所示。
CUDA函数在调用的时候,除了像常规函数一样需要传入参数(如果有的话),还要指定“执行设置”(execution configuration),也就是需要显式地指定需要多少个线程。具体而言,通过三个尖括号指定,如下图所示。

(3)CUDA程序编译
对于CUDA程序的编译,分为离线编译和即时编译两种,如下图所示。
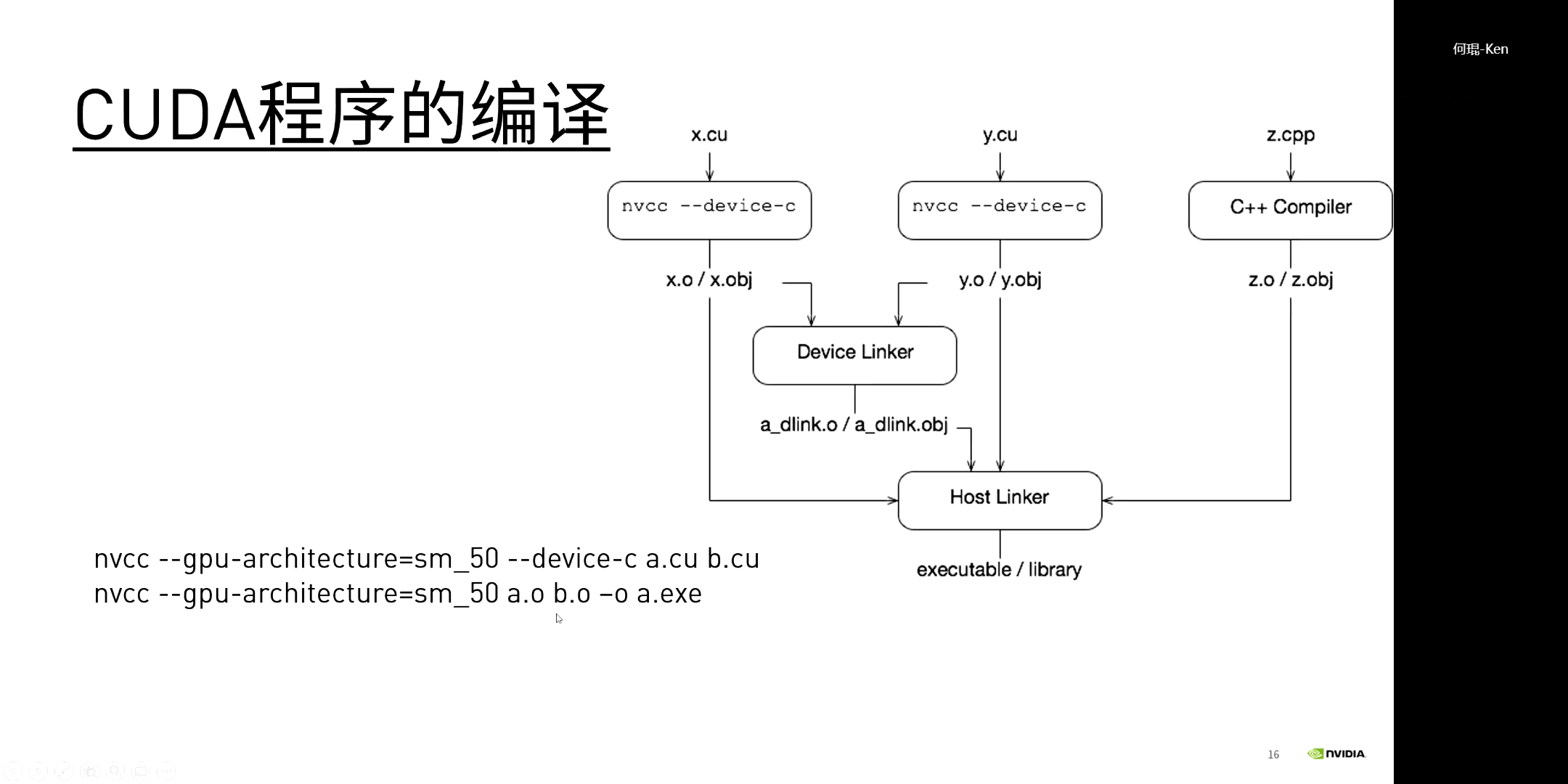
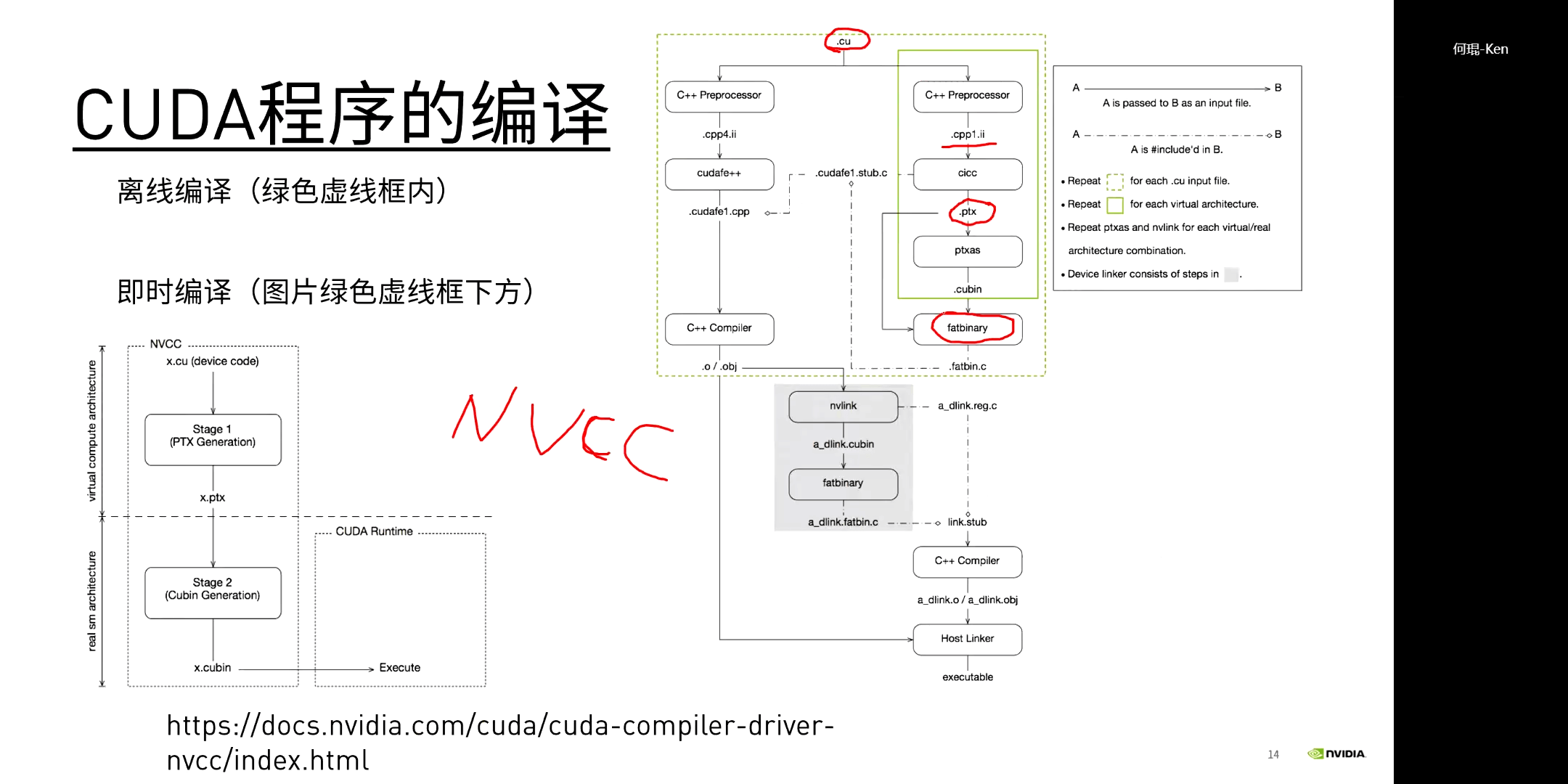 一个简单的CUDA程序编译示意如下。
一个简单的CUDA程序编译示意如下。

(4)NVPROF工具
NVPROF是一个非常方便的用于分析GPU性能的工具。
 我们可以直接输入
我们可以直接输入nvprof target,就可以输出target程序的相关内容,如下所示。
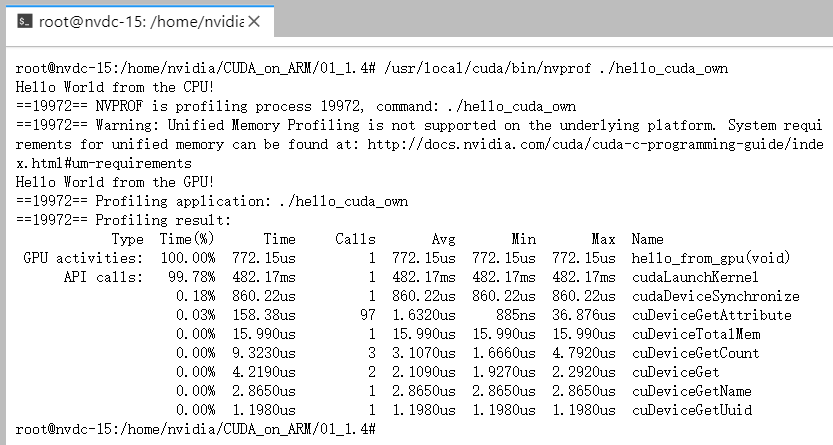 当然,它可以进一步接受不同参数,以输出更多详细的内容。
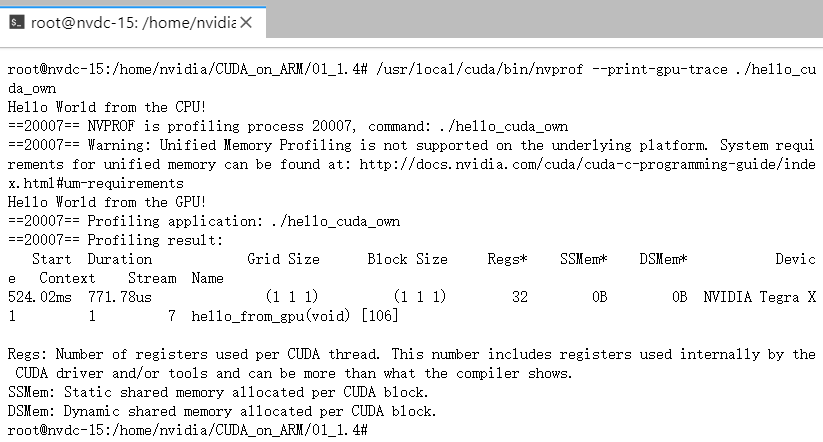
当然,它可以进一步接受不同参数,以输出更多详细的内容。--print-gpu-trace参数可以输出一些数据从Device拷贝到Host耗时、Block大小等详细信息,如下。
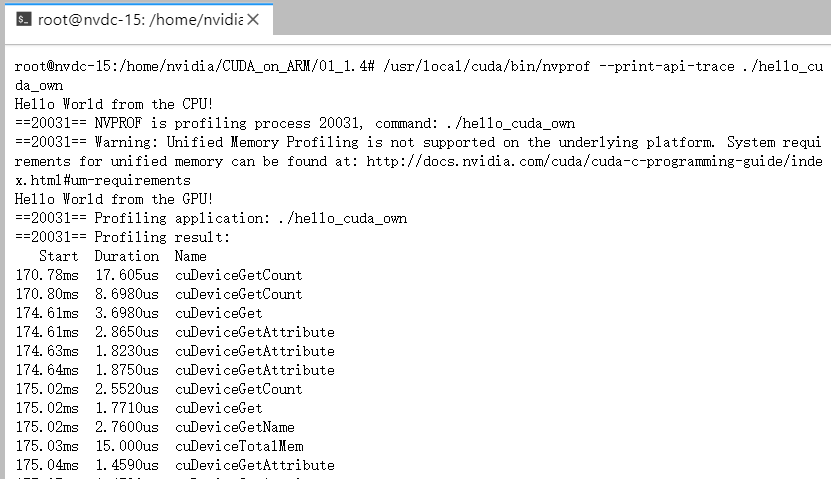
--print-api-trace,可以输出函数间的调用关系,更方便跟踪代码,如下。
本文作者原创,未经许可不得转载,谢谢配合
