Notes for CUDA on ARM Platform Summer Camp Day2.由于只记录了一些我认为比较重要的东西,笔记内容可能并非非常完整,完整内容可以直接参考课程视频,点击查看百度云,密码2qom。但我尽量保证了笔记内容的逻辑性和整体性,方便其他人阅读。
1.线程层次

(1)基础
前面说了,CUDA的核函数在执行的时候都需要指定execution configuration,这其实就是在指定线程的层次。
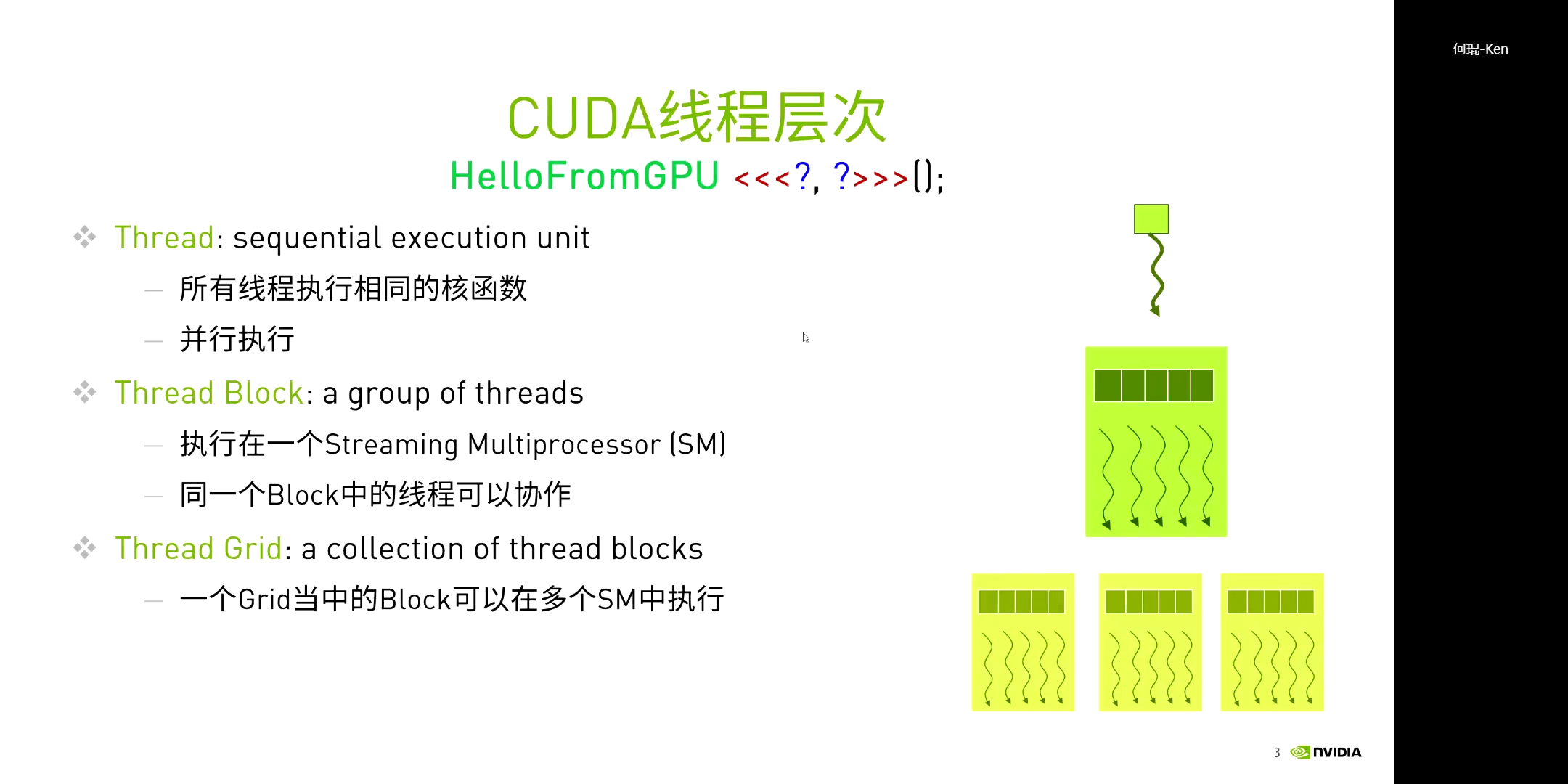 这里需要强调的一个基本概念是,所有线程都会执行相同的核函数,但不一定是相同的指令流(如不同的if判断、迭代次数等)。而函数输出结果的差异从本质上来说,是由于线程所处的位置不同而导致的。因为线程处于不同位置,所以读取到了不同的数据进行处理,进而输出了不同的结果。但所有的执行流程都是相同的。另一点就是,一个线程块中的所有线程都执行在一个SM(Streaming Multiprocessor)中,同一个Block中的线程可以协作。一个SM中不一定只有一个Block(可以有多个),但是一个Block肯定是在一个SM中的。
这里需要强调的一个基本概念是,所有线程都会执行相同的核函数,但不一定是相同的指令流(如不同的if判断、迭代次数等)。而函数输出结果的差异从本质上来说,是由于线程所处的位置不同而导致的。因为线程处于不同位置,所以读取到了不同的数据进行处理,进而输出了不同的结果。但所有的执行流程都是相同的。另一点就是,一个线程块中的所有线程都执行在一个SM(Streaming Multiprocessor)中,同一个Block中的线程可以协作。一个SM中不一定只有一个Block(可以有多个),但是一个Block肯定是在一个SM中的。
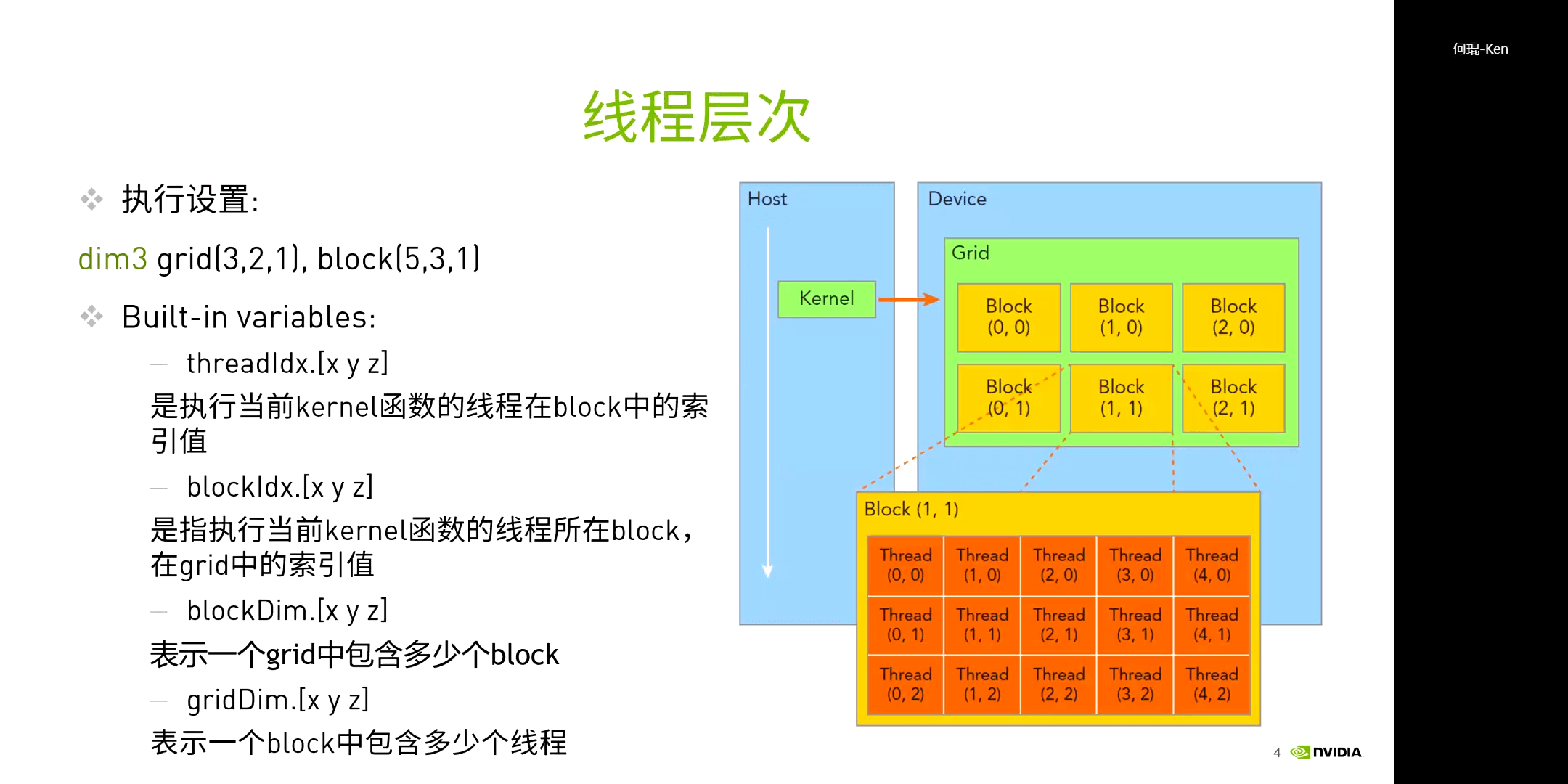 而在执行时,通过指定的执行设置,执行核函数的内容。需要注意的是,
而在执行时,通过指定的执行设置,执行核函数的内容。需要注意的是,threadIdx.[x y z]、blockIdx.[x y z]、blockDim.[x y z]、gridDim.[x y z]都是内置的变量,直接使用即可,无需申明。
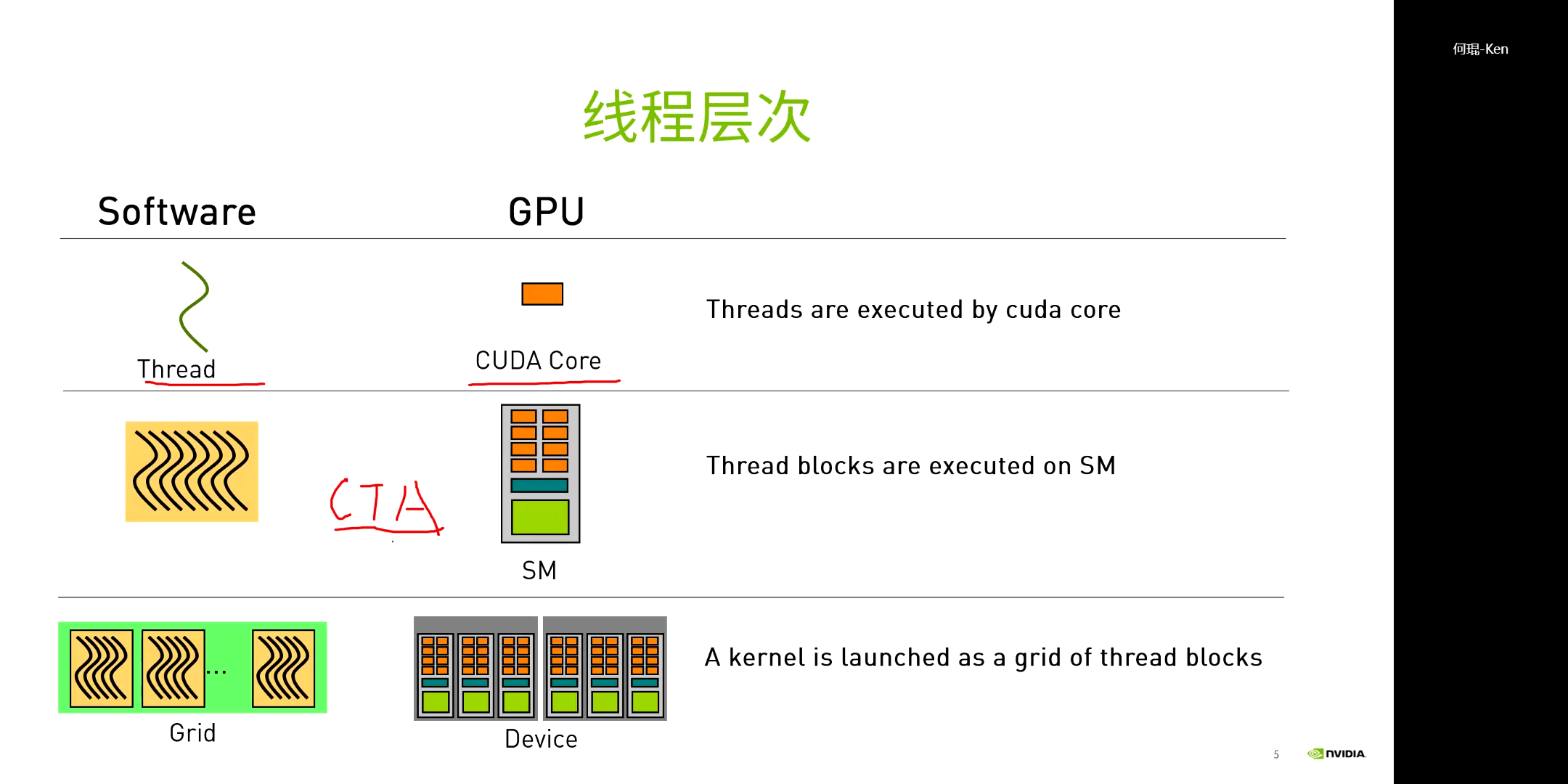
(2)为什么要有Block
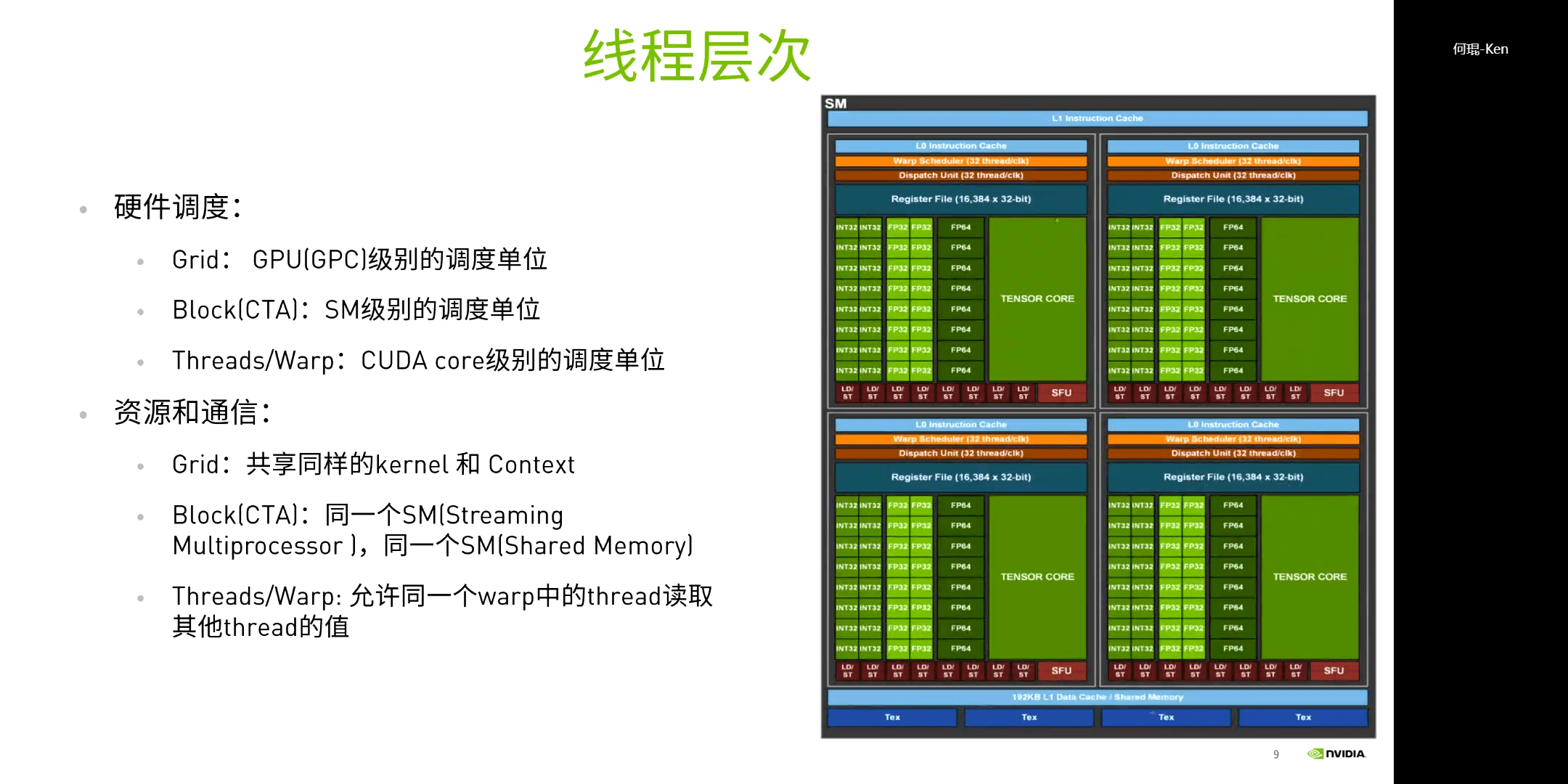
有了Grid和Thread为什么还要有Block?因为这和GPU的硬件是相关的。Grid、Block、Thread分别对应了不同的调度单位,Grid对应GPU级别,Block对应SM级别,Thread对应CUDA Core级别。



 另外,从另一个角度来说,Block给线程提供了多粒度的调度方式。如果没有Block的话,一个Grid里的线程统一调度,但如果只要有一个线程没做完,其它线程全部要等待同步。这显然是非常低效的。而在加了Block层级以后,我们无需等待所有线程都执行完,只要某个Block执行完了就可以继续进行下面的任务。
另外,从另一个角度来说,Block给线程提供了多粒度的调度方式。如果没有Block的话,一个Grid里的线程统一调度,但如果只要有一个线程没做完,其它线程全部要等待同步。这显然是非常低效的。而在加了Block层级以后,我们无需等待所有线程都执行完,只要某个Block执行完了就可以继续进行下面的任务。
(3)线程索引
 线程索引最核心的其实就是二维索引和一维索引的互相转换问题。进一步其可以看做是一个局部坐标转全局坐标的问题,核心其实是非常简单的。另外,正如上个笔记中介绍的,每一个线程执行相同的核函数。而之所以输入会有不同,是因为每个线程有不同的位置,进而对应不同的输入,显然输出也不同了。
线程索引最核心的其实就是二维索引和一维索引的互相转换问题。进一步其可以看做是一个局部坐标转全局坐标的问题,核心其实是非常简单的。另外,正如上个笔记中介绍的,每一个线程执行相同的核函数。而之所以输入会有不同,是因为每个线程有不同的位置,进而对应不同的输入,显然输出也不同了。
(4)一个例子
下图展示了一个利用GPU并行加速的向量加法。
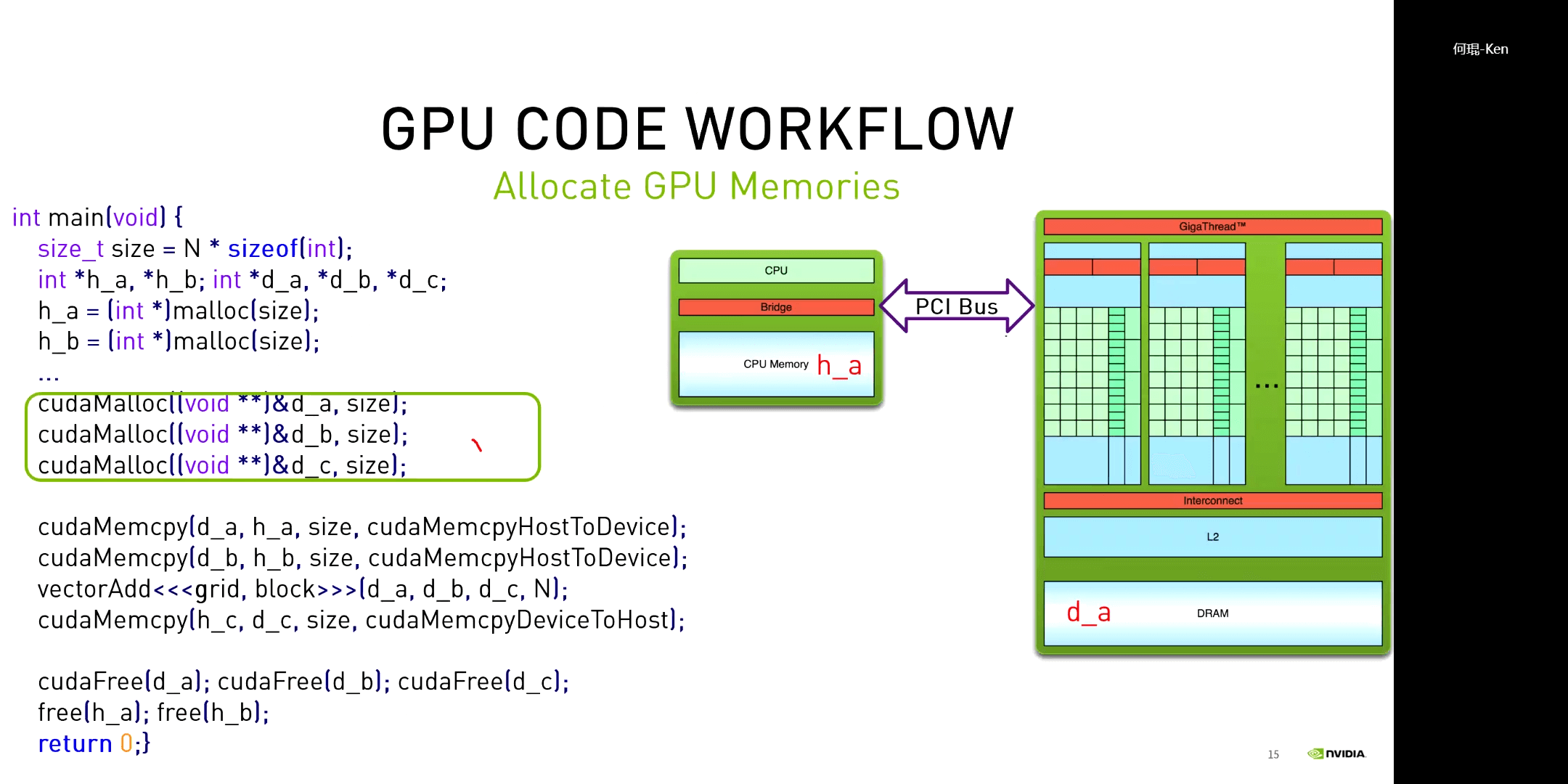
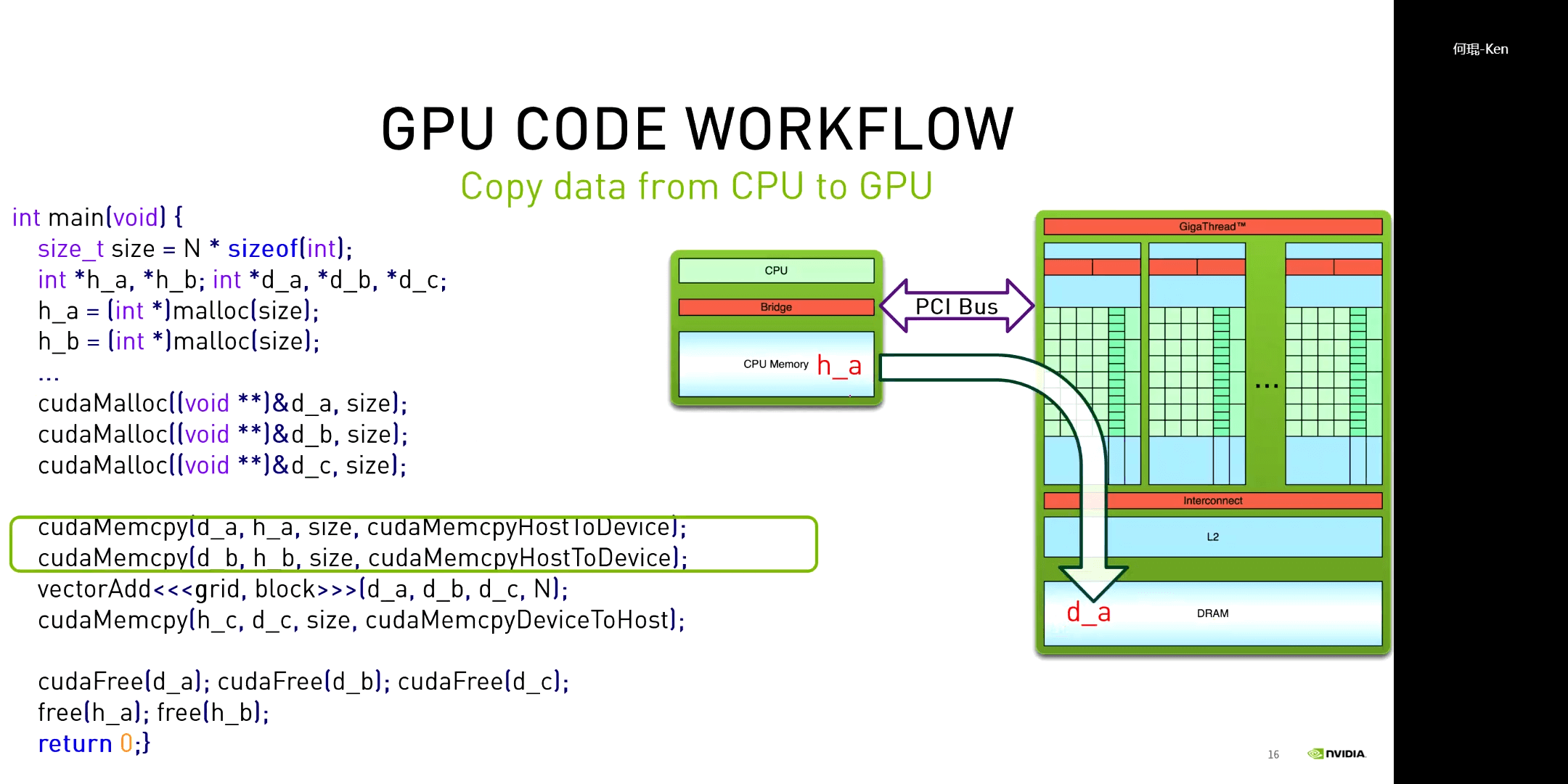
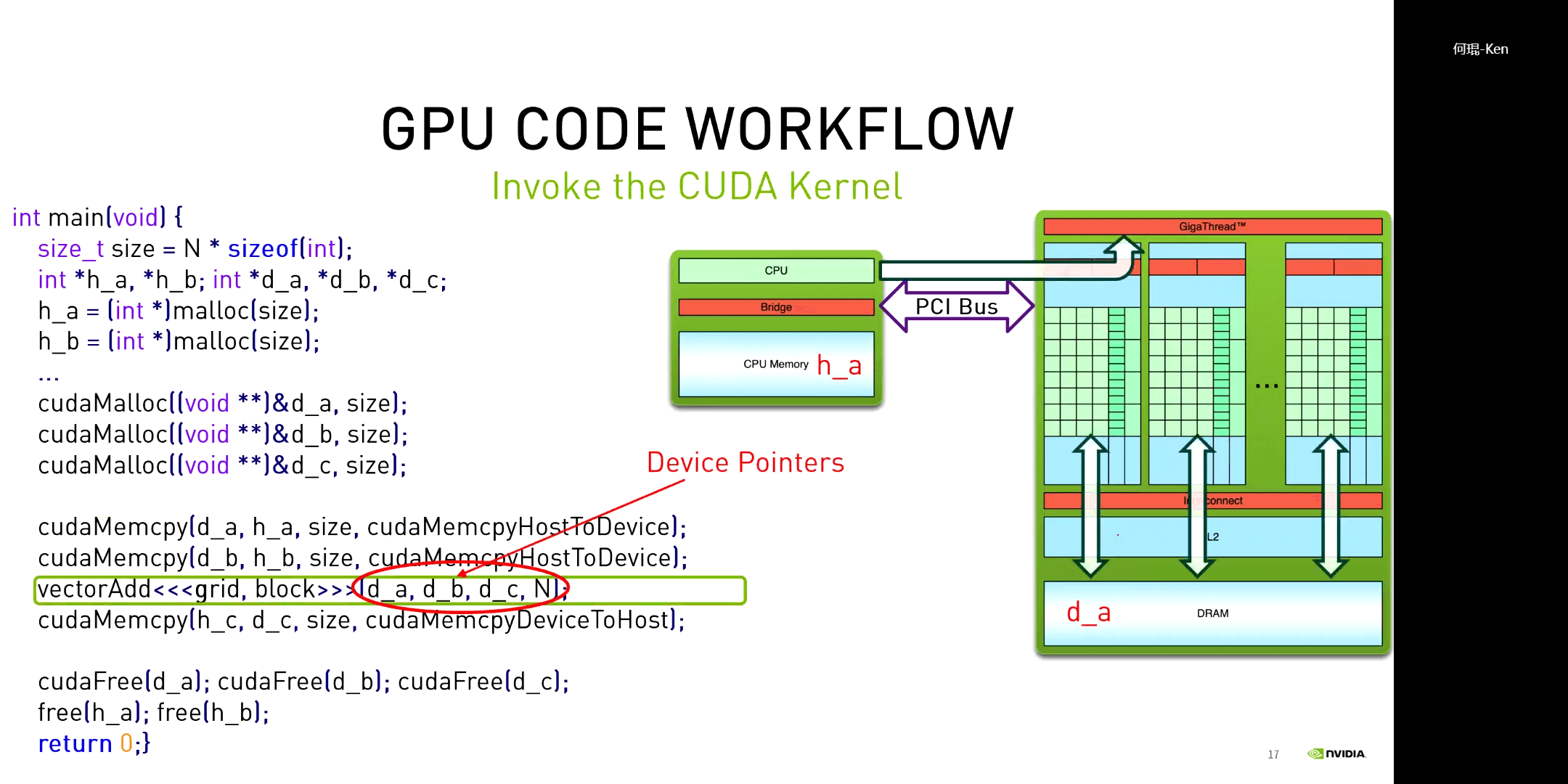

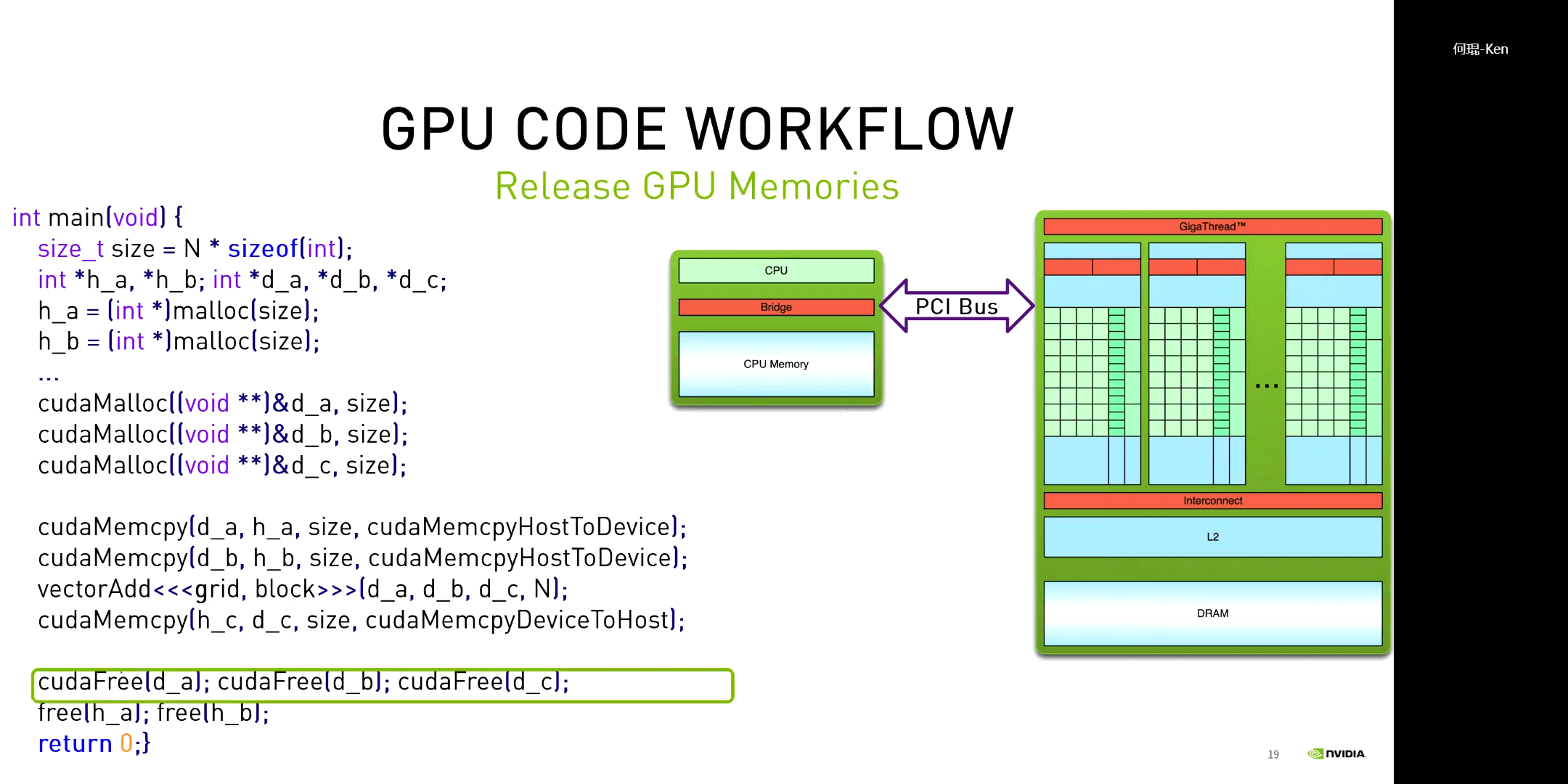 对于一个CUDA程序,其一般都包含以下几个步骤:申请GPU内存、拷贝数据到GPU、执行核函数、拷贝数据到CPU、释放GPU内存。
对于一个CUDA程序,其一般都包含以下几个步骤:申请GPU内存、拷贝数据到GPU、执行核函数、拷贝数据到CPU、释放GPU内存。
(5)Block的大小问题
在给定Block大小的情况下,对于有N个元素的数组,我们就可以很容易地算出Grid的大小,如下图所示。
 但这里又有新的问题,Block可以是多大,任意大吗?答案显然是否定的。
但这里又有新的问题,Block可以是多大,任意大吗?答案显然是否定的。
 如上图所示,展示了某GPU Block所能容纳的最大线程数。这里需要注意的一点是,Block的最大维度是(1024,1024,64)。这并不是说它最大可以有1024×1024×64个线程。而是说每一维,最大只能是这么大。最关键的就是Block中包含的线程总数不能超过1024。进一步来说,这种限制是由硬件带来的。因为每个SM中包含的存储是有限的,所以决定了能包含Block的数量。
如上图所示,展示了某GPU Block所能容纳的最大线程数。这里需要注意的一点是,Block的最大维度是(1024,1024,64)。这并不是说它最大可以有1024×1024×64个线程。而是说每一维,最大只能是这么大。最关键的就是Block中包含的线程总数不能超过1024。进一步来说,这种限制是由硬件带来的。因为每个SM中包含的存储是有限的,所以决定了能包含Block的数量。
但上面所说的这些是最大量,但并不是最优量。我们应该思考,每个Block应该包含多少线程。
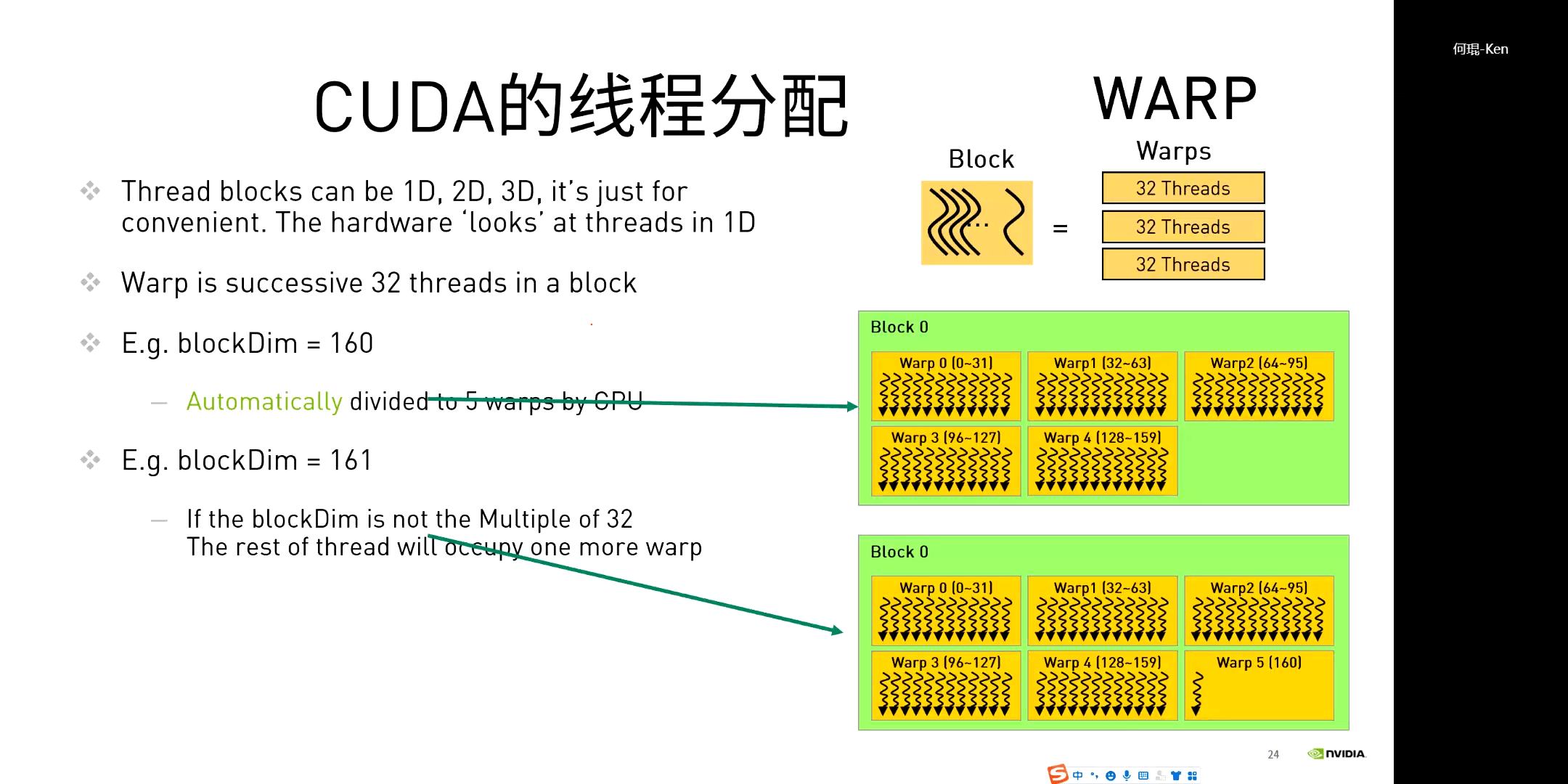 简单一句话总结就是,线程数应该尽量是32的倍数。因为前面说了,一个Warp包含32个线程。GPU在执行的时候会以Warp的形式调度线程。如果Block中的线程个数不是32的整倍数,那么就会出现极个别线程占用一整个Warp的情况,如上图所示。由于硬件资源有限,Warp越多,每个平均分到的资源就越少。所以说应该极力避免出现32的非整倍数个数。当然,如果线程数本身就小于32,那没有什么影响,因为不管是多少,反正小于32,都在同一个Warp里。
简单一句话总结就是,线程数应该尽量是32的倍数。因为前面说了,一个Warp包含32个线程。GPU在执行的时候会以Warp的形式调度线程。如果Block中的线程个数不是32的整倍数,那么就会出现极个别线程占用一整个Warp的情况,如上图所示。由于硬件资源有限,Warp越多,每个平均分到的资源就越少。所以说应该极力避免出现32的非整倍数个数。当然,如果线程数本身就小于32,那没有什么影响,因为不管是多少,反正小于32,都在同一个Warp里。
(6)线程不够的问题
我们需要思考另一个问题。前面说了Block是有最大线程个数限制的,同理其实Grid也是有最大个数限制的。我们可以通过CUDA Samples里的deviceQuery程序进行查询。对于我们实验的Jetson NANO,我们可以cd到/usr/local/cuda/samples/1_Utilities/deviceQuery。如果没有可执行程序的话,make一下就可以了。完成以后,我们就可以./deviceQuery运行,结果如下。
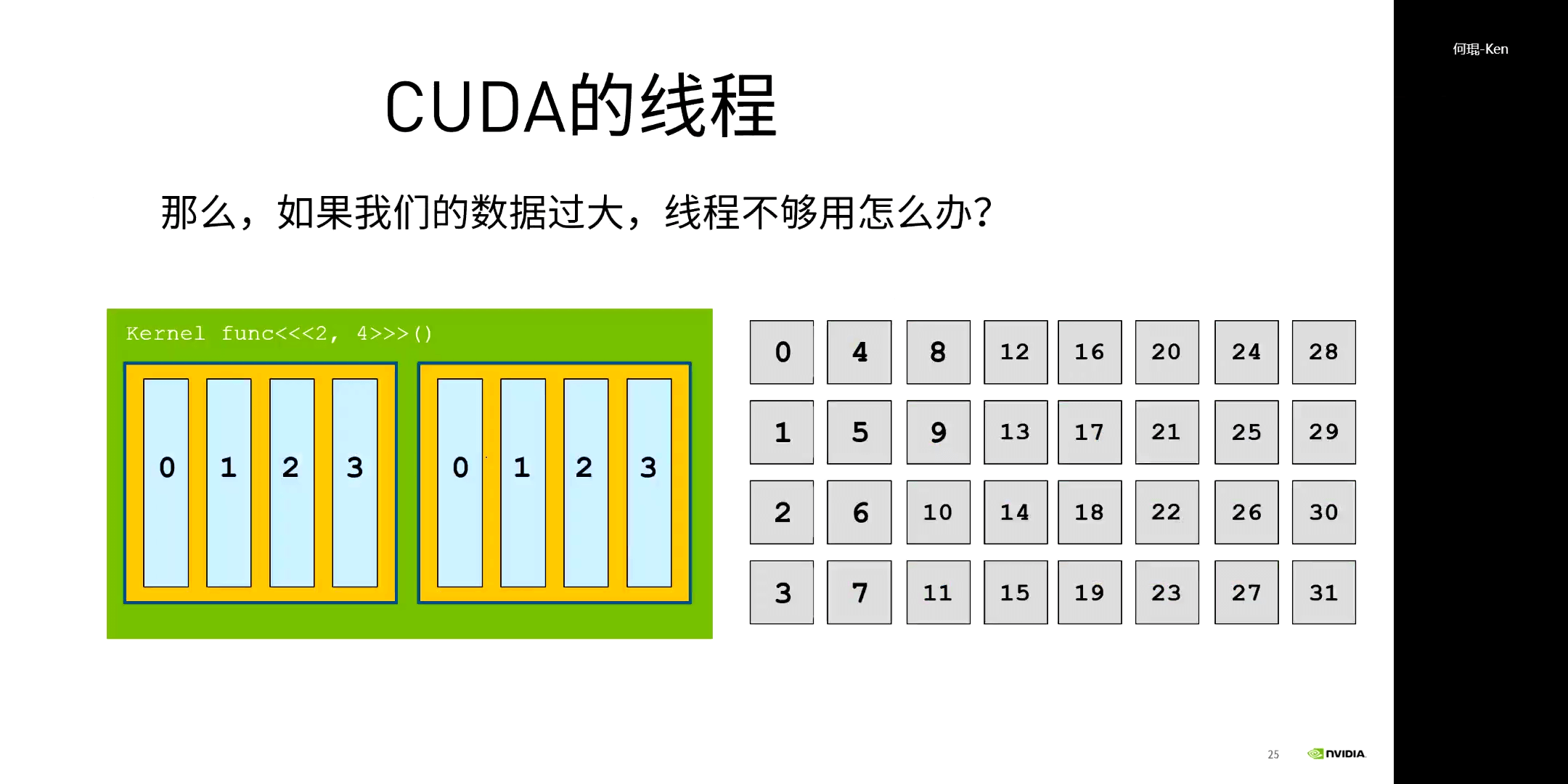
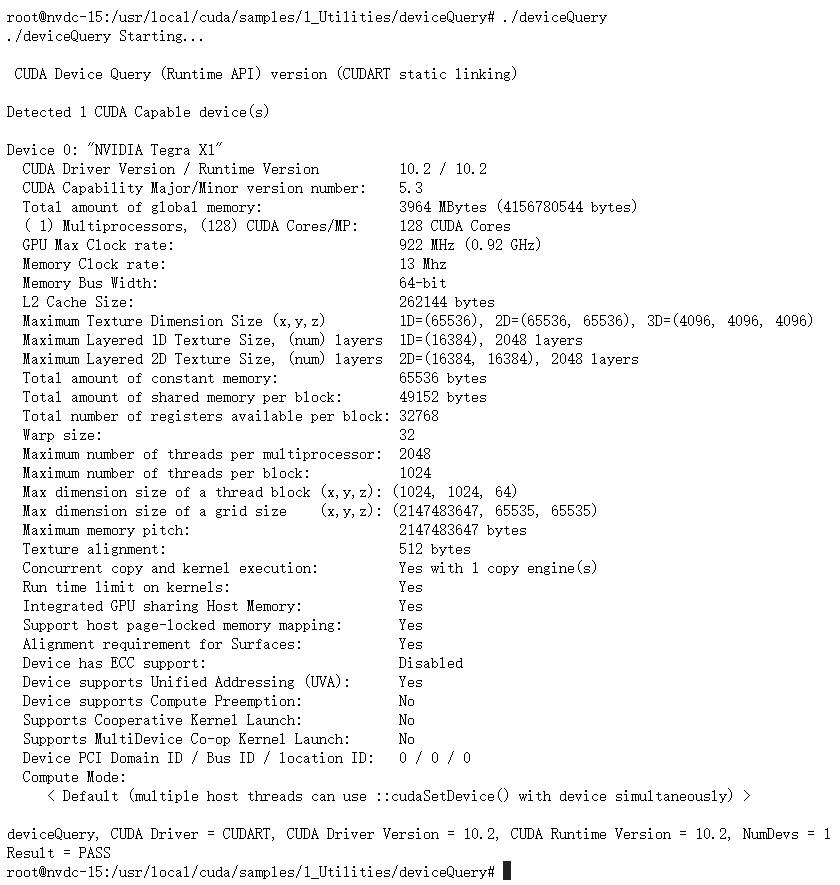 可以看到,我们的GPU型号是Tegra X1,我们每个Block最多包含1024个线程。那么自然会想到一个问题,如果数据量太大了,一个thread对应一个矩阵的元素都还不够,那怎么办呢?
可以看到,我们的GPU型号是Tegra X1,我们每个Block最多包含1024个线程。那么自然会想到一个问题,如果数据量太大了,一个thread对应一个矩阵的元素都还不够,那怎么办呢?
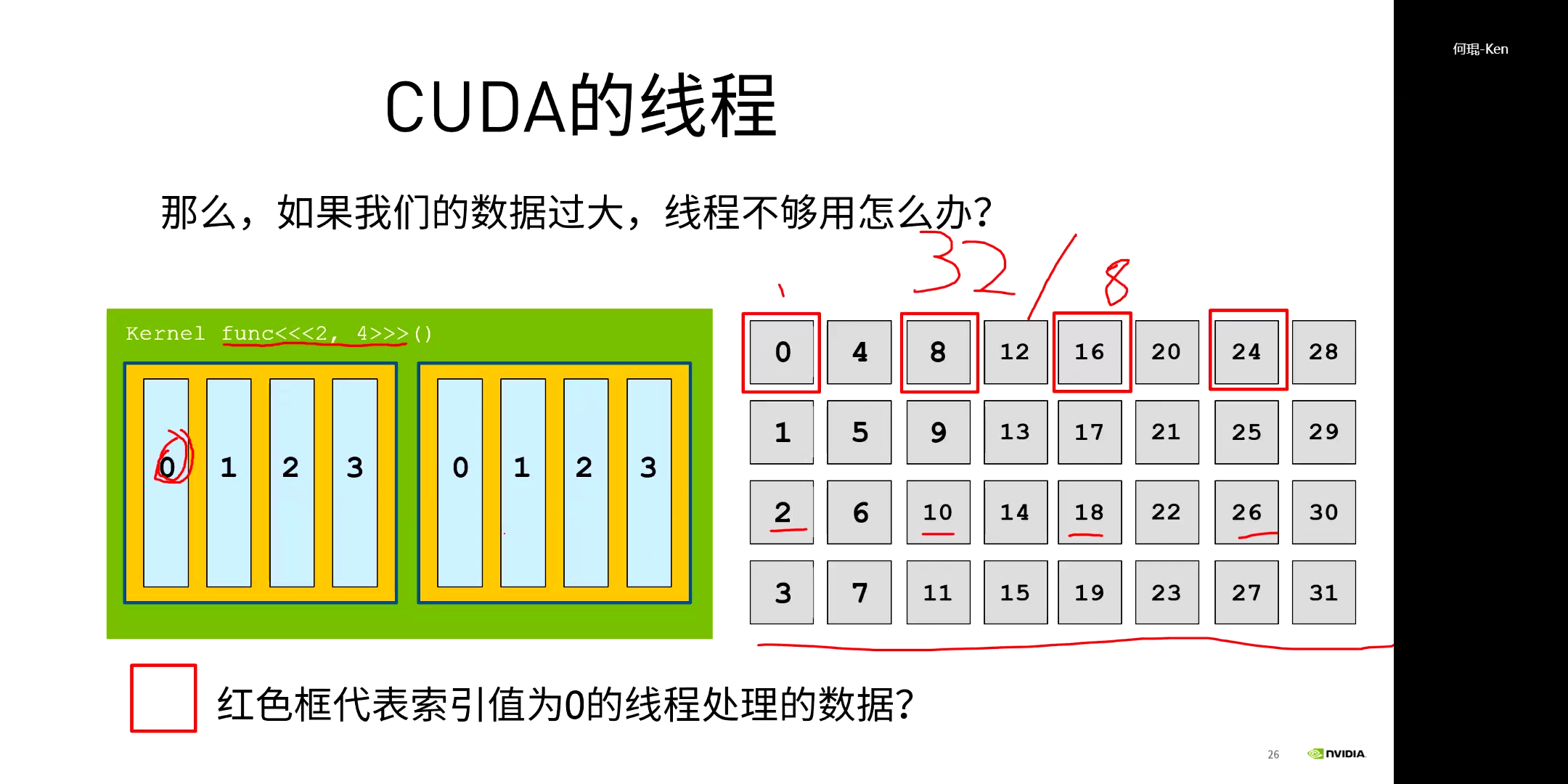 我们可以考虑对大矩阵进行分块然后依次处理,如上图所示。这其实也就是CUDA中的Grid-Stride Loop(网格跨步循环)。感兴趣的话可以参考这个网页。以前,线程数够的时候,我们可以做到一个线程对应一个数据,线程索引和数据索引一一对应。但现在我们线程数不够或者我们人为地设置指定大小的时候,我们就让一个线程处理多个数据,多个数据的间隔就是一个Block的大小。反应在代码中,就是如下的形式。
我们可以考虑对大矩阵进行分块然后依次处理,如上图所示。这其实也就是CUDA中的Grid-Stride Loop(网格跨步循环)。感兴趣的话可以参考这个网页。以前,线程数够的时候,我们可以做到一个线程对应一个数据,线程索引和数据索引一一对应。但现在我们线程数不够或者我们人为地设置指定大小的时候,我们就让一个线程处理多个数据,多个数据的间隔就是一个Block的大小。反应在代码中,就是如下的形式。

2.存储单元与矩阵乘法
(1)GPU内存操作相关函数
GPU的存储单元和彼此之间的关系如下所示。
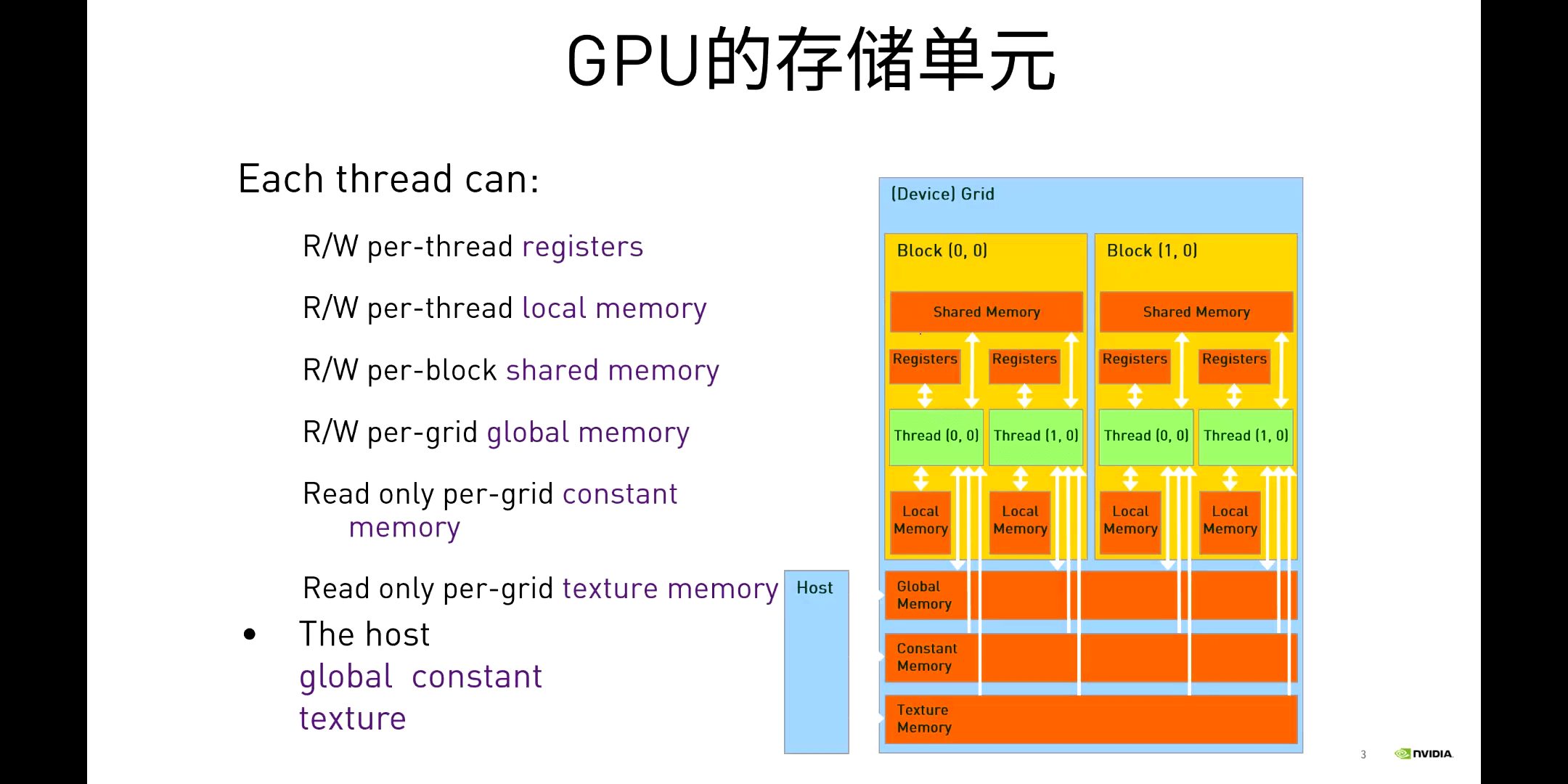 CPU与GPU的内存操作相关函数如下。
CPU与GPU的内存操作相关函数如下。

 需要注意的是,除了指定源地址和目标地址(传输方向),还需要显式指定需要的内存大小。另外需要说明的是,在CUDA编程领域,很多二维的数组都是以一维的方式按照行主序的形式保存的,传输的只是数组的指针,需要我们自己根据索引获取对应元素。这点是和Python或者C++里面有点区别的地方。
需要注意的是,除了指定源地址和目标地址(传输方向),还需要显式指定需要的内存大小。另外需要说明的是,在CUDA编程领域,很多二维的数组都是以一维的方式按照行主序的形式保存的,传输的只是数组的指针,需要我们自己根据索引获取对应元素。这点是和Python或者C++里面有点区别的地方。
(2)矩阵乘法示例
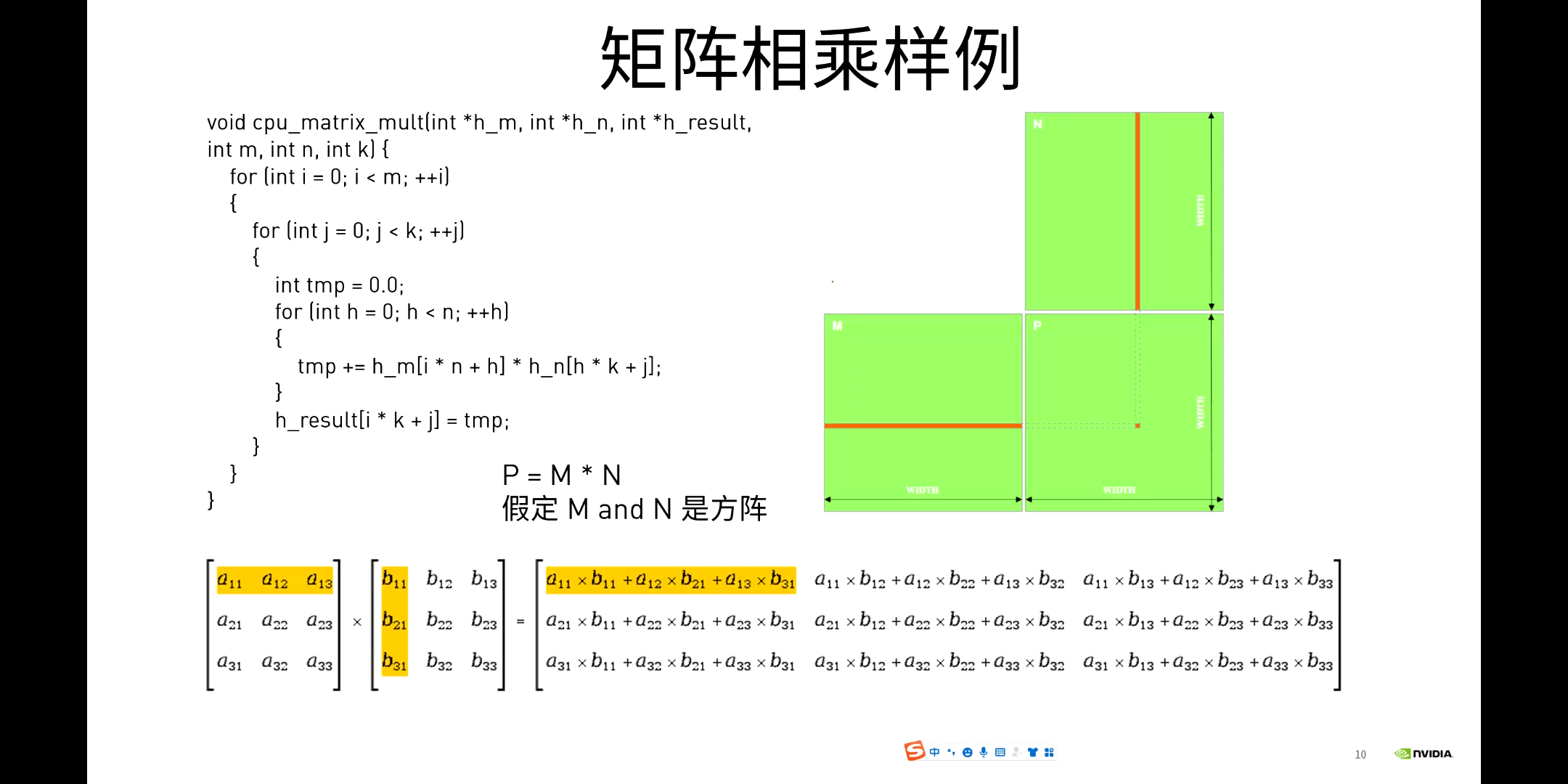
矩阵乘法其实就是某一行的元素乘以某一列的元素再对应求和。在CPU上处理时,其实就是多个循环的嵌套。两层循环控制行列方向上的移动,第三层循环控制指定行或列的元素遍历,如下图所示。
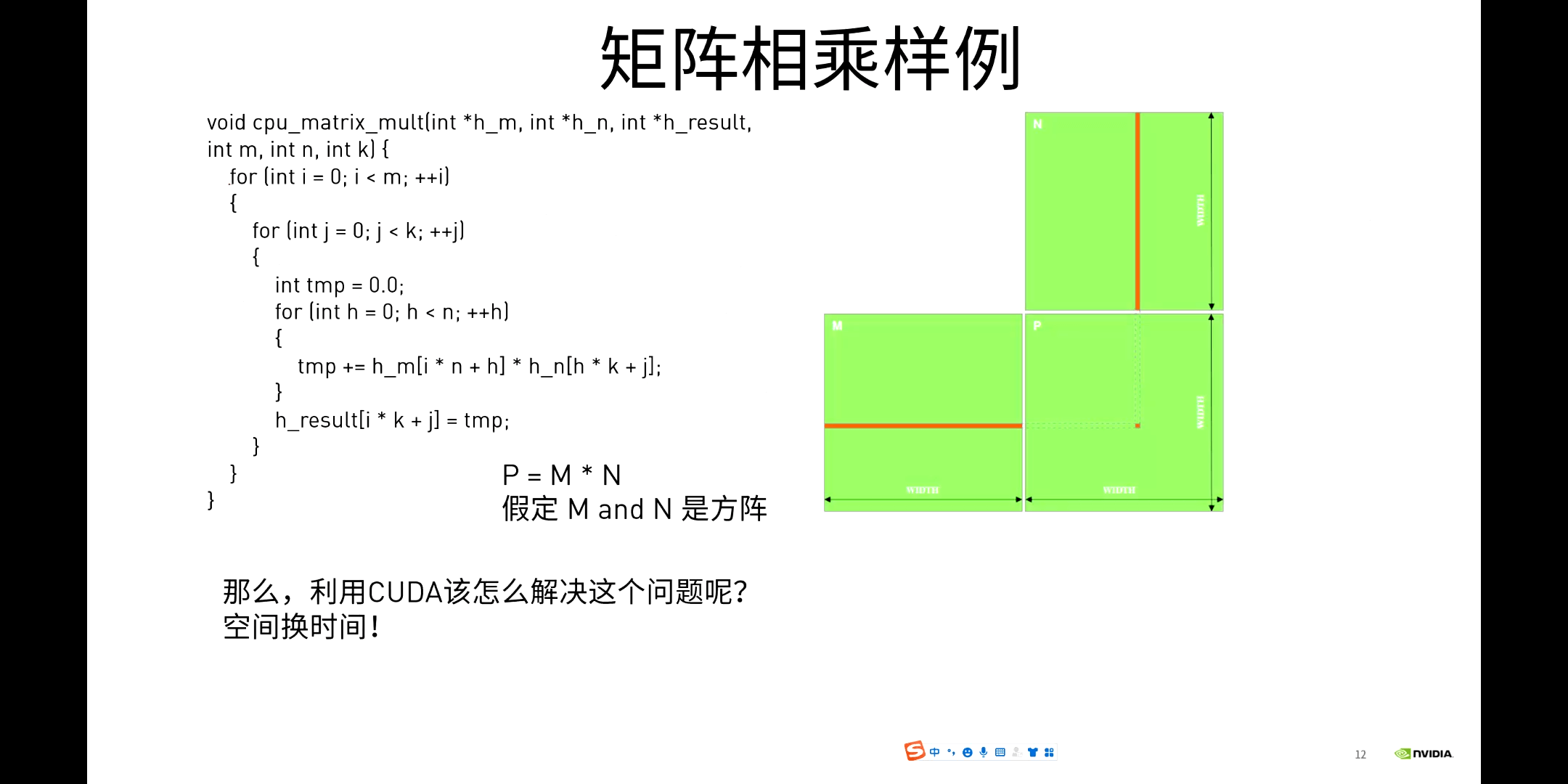
 而对于GPU,可以采用空间换时间的思路,如下图所示。
而对于GPU,可以采用空间换时间的思路,如下图所示。
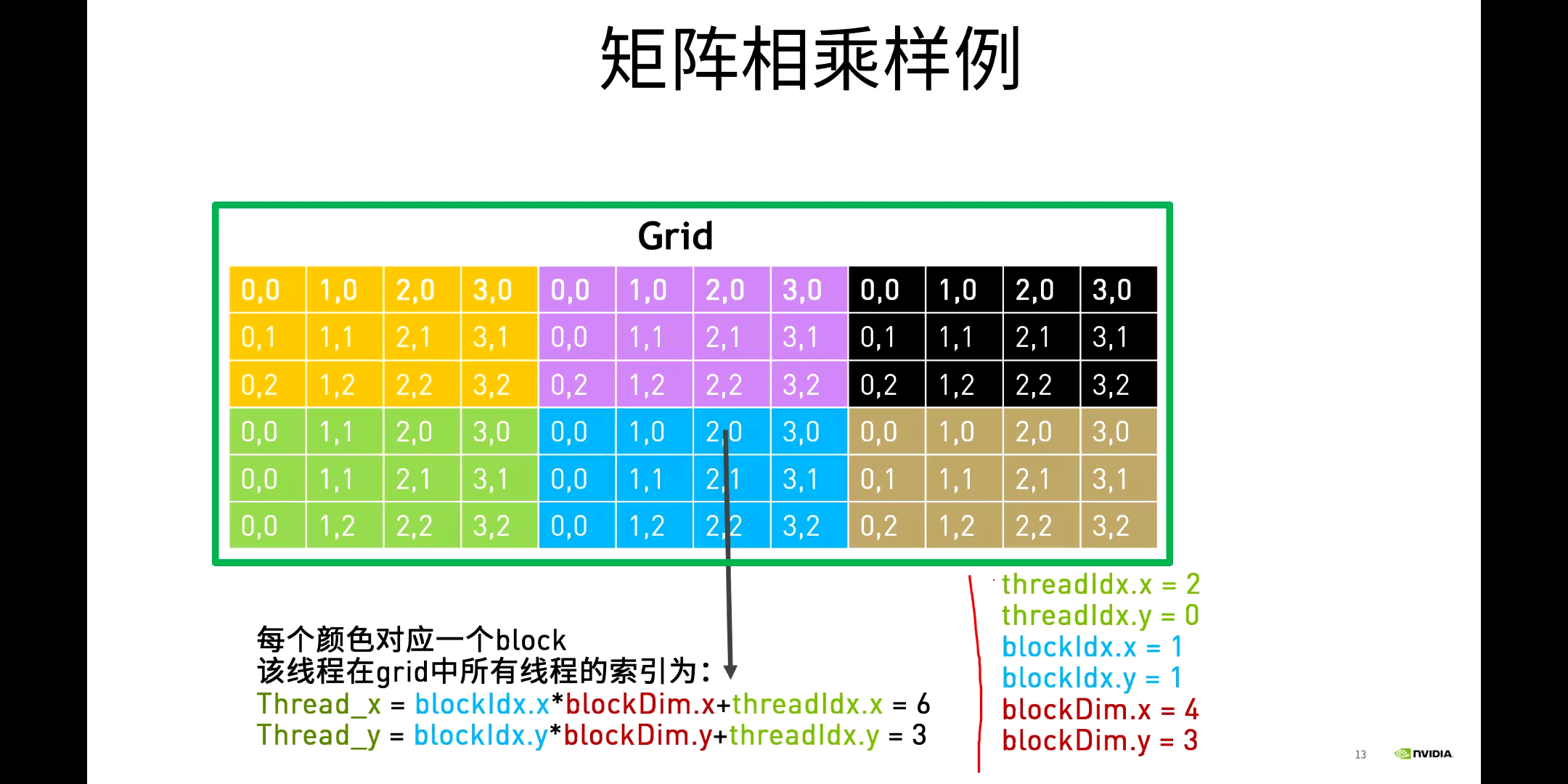

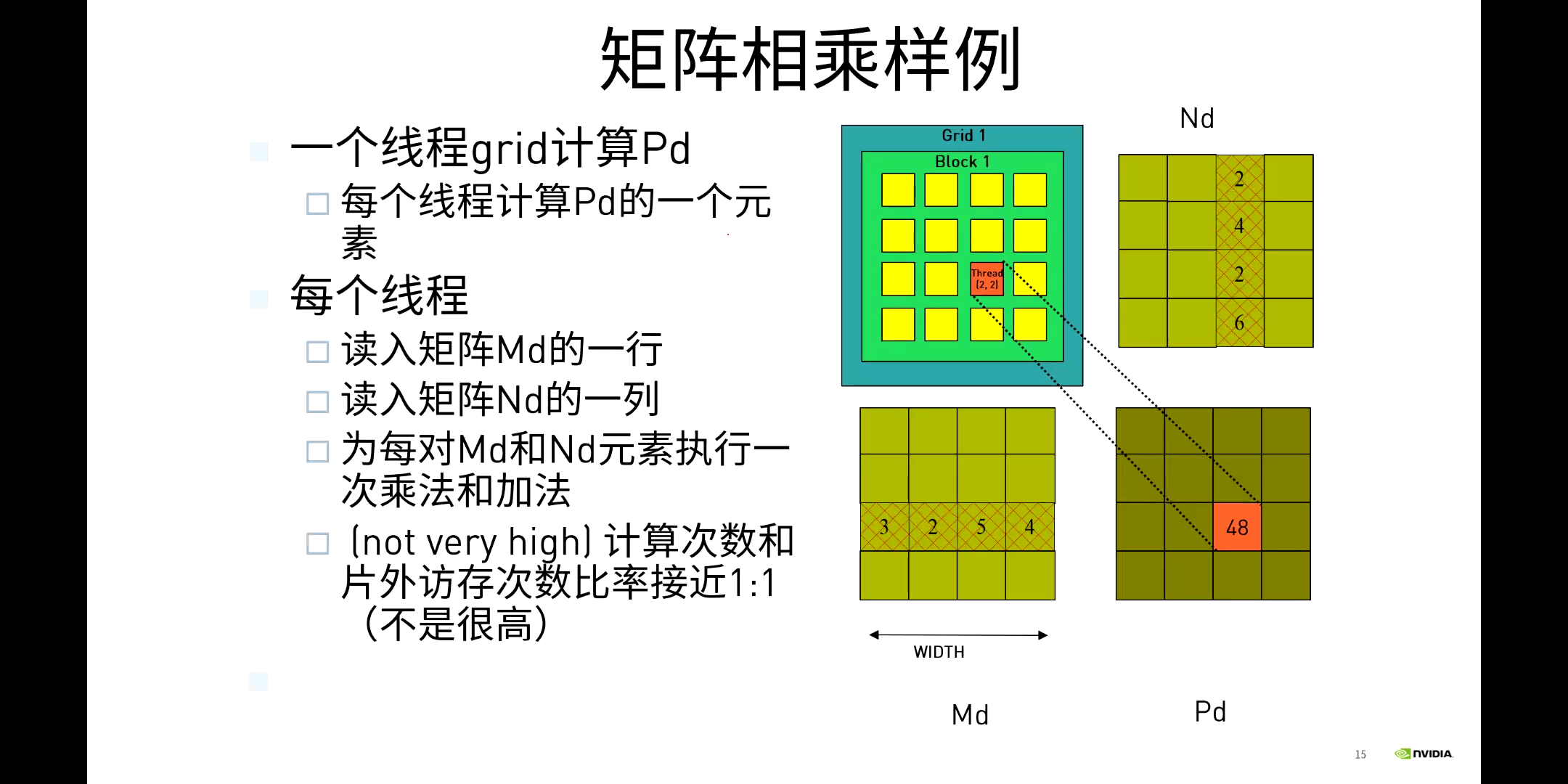 利用多线程的优势,就可以消除外围两个for循环。前面说过了,CUDA中内置了blockIdx和threadIdx等变量,我们可以直接获取到它们,进而计算出当前线程的唯一索引,再拿着这个索引就可以找到矩阵中的对应位置,然后就可以进行计算了。样例代码如下所示。
利用多线程的优势,就可以消除外围两个for循环。前面说过了,CUDA中内置了blockIdx和threadIdx等变量,我们可以直接获取到它们,进而计算出当前线程的唯一索引,再拿着这个索引就可以找到矩阵中的对应位置,然后就可以进行计算了。样例代码如下所示。
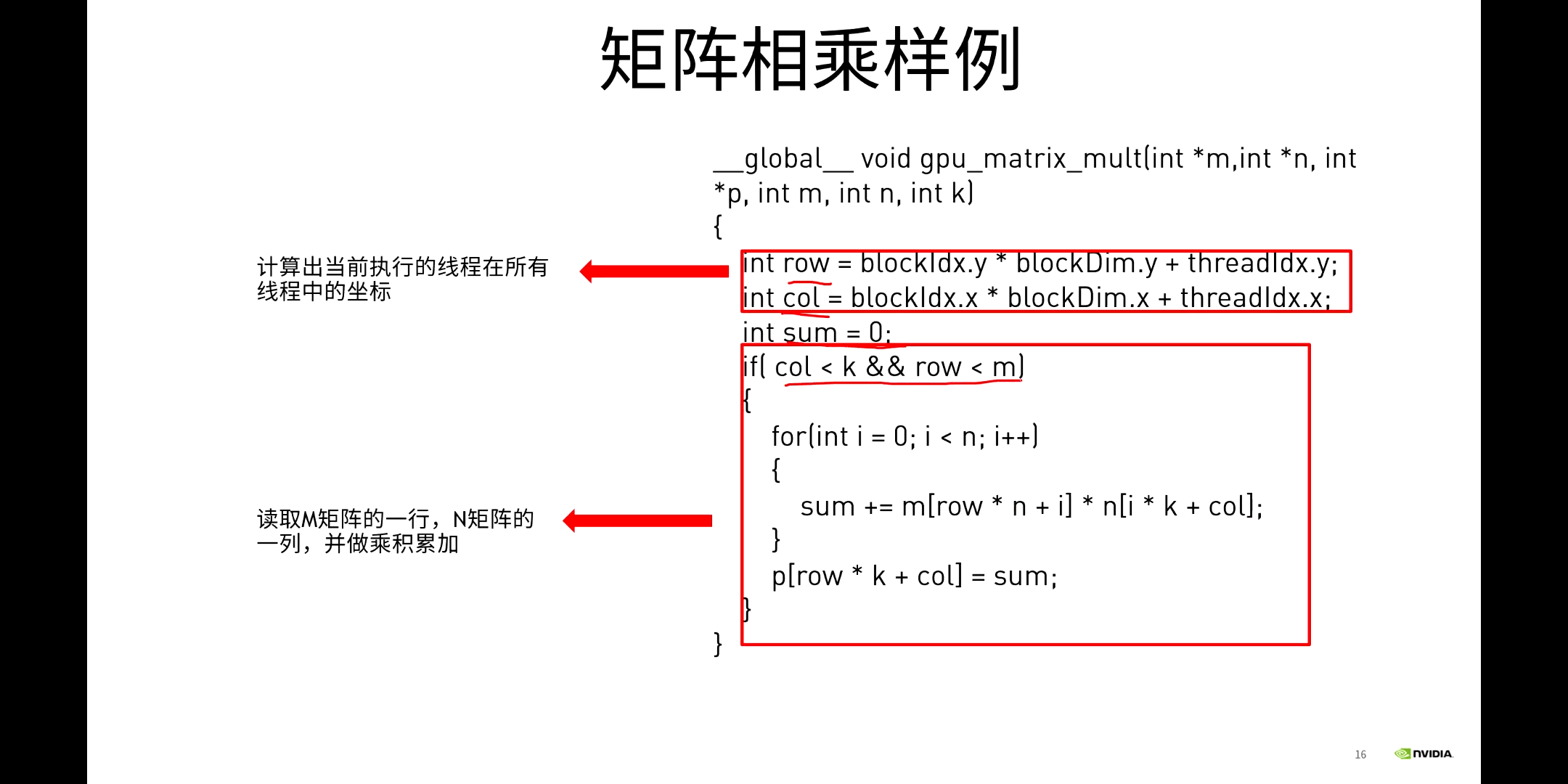
 这样就完成了矩阵相乘。但这里会发现有一个潜在的问题,就是矩阵数据被重复读取了很多次。比如计算同一行的元素时,每计算一次就要读取矩阵中的某一行,下一次还是要读取这一行。这种操作非常重复。显然这是我们可以优化的地方。这是一方面,另一方面是,我们使用的是GPU默认的Global Memory,前面介绍的很多更高效的存储都没有使用,如Shared Memory。所以,我们下一步优化至少可以从这两个方面进行。这是下一节课的内容。
这样就完成了矩阵相乘。但这里会发现有一个潜在的问题,就是矩阵数据被重复读取了很多次。比如计算同一行的元素时,每计算一次就要读取矩阵中的某一行,下一次还是要读取这一行。这种操作非常重复。显然这是我们可以优化的地方。这是一方面,另一方面是,我们使用的是GPU默认的Global Memory,前面介绍的很多更高效的存储都没有使用,如Shared Memory。所以,我们下一步优化至少可以从这两个方面进行。这是下一节课的内容。
另外,需要说明的一点是,对于向量求和(逐像素累加)、数组寻找最值等操作,可以通过CUDA中单归并(Reduction)来实现。
本文作者原创,未经许可不得转载,谢谢配合
