Notes for CUDA on ARM Platform Summer Camp Day3.由于只记录了一些我认为比较重要的东西,笔记内容可能并非非常完整,完整内容可以直接参考课程视频,点击查看百度云,密码2qom。但我尽量保证了笔记内容的逻辑性和整体性,方便其他人阅读。
1.错误检测与事件
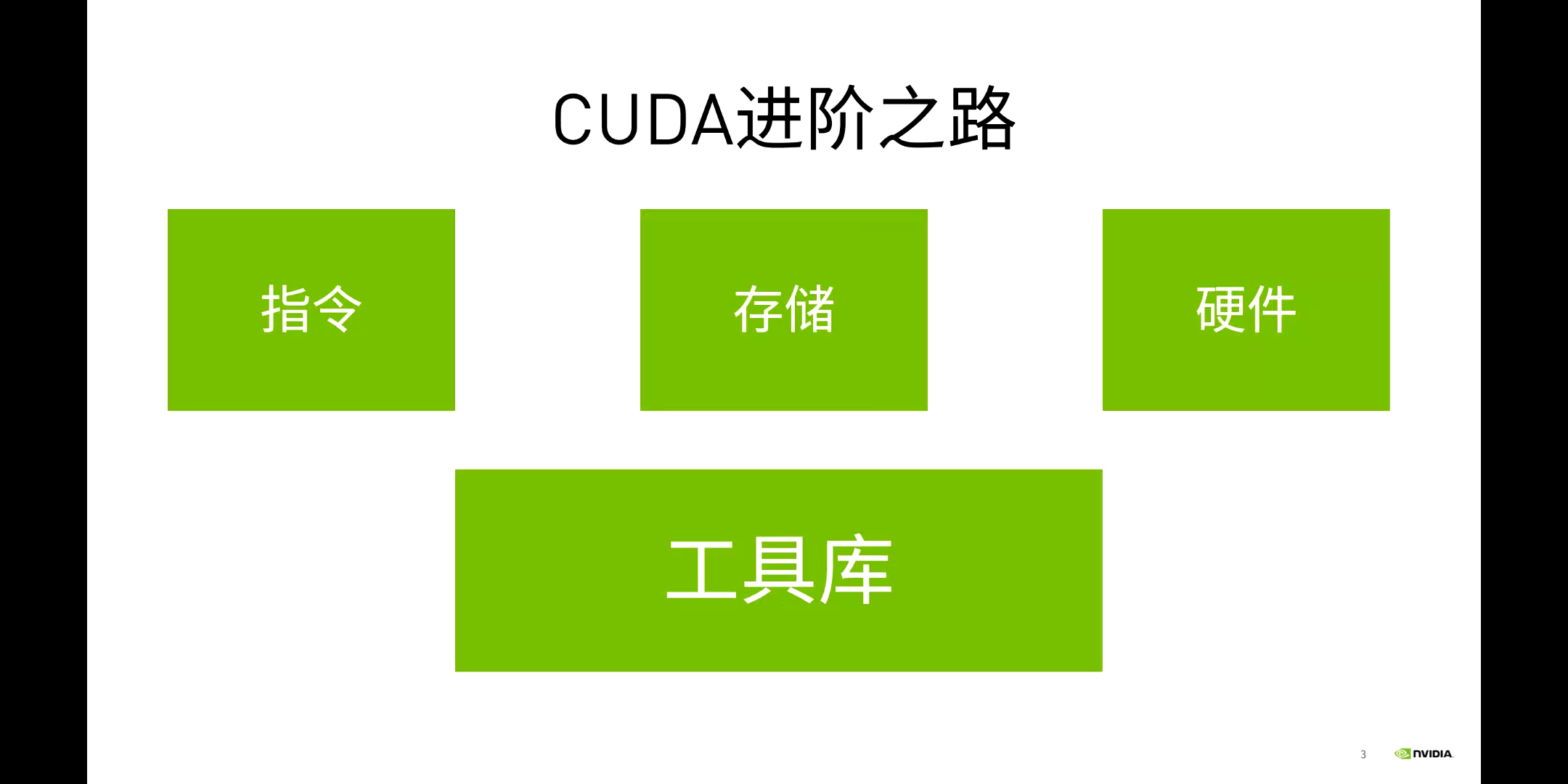
 CUDA进阶之路:指令、存储、硬件、工具库。
CUDA进阶之路:指令、存储、硬件、工具库。
(1)CUDA错误检测函数
在CUDA中有很多很方便的错误检测函数,如下图所示。

 比较常用的是
比较常用的是cudaGetErrorName和cudaGetErrorString,前者用于获取错误类型,后者返回错误描述。如上图所示,申请的Block大小超过了最大数量限制。一个比较方便的检查函数如下所示。

(2)CUDA事件
 GPU Event本质上是一个GPU时间戳,可以用于记录GPU代码的执行时间,避免了使用CPU来计时的一系列问题。Event在使用的时候,有一系列函数可供操作,如下所示。
GPU Event本质上是一个GPU时间戳,可以用于记录GPU代码的执行时间,避免了使用CPU来计时的一系列问题。Event在使用的时候,有一系列函数可供操作,如下所示。

 利用Event记录时间的核心步骤包括:声明、创建、记录。
利用Event记录时间的核心步骤包括:声明、创建、记录。cudaEventRecord()可以用于记录当前时间。
2.多种CUDA存储单元
 GPU常用的存储单元如下:
GPU常用的存储单元如下:
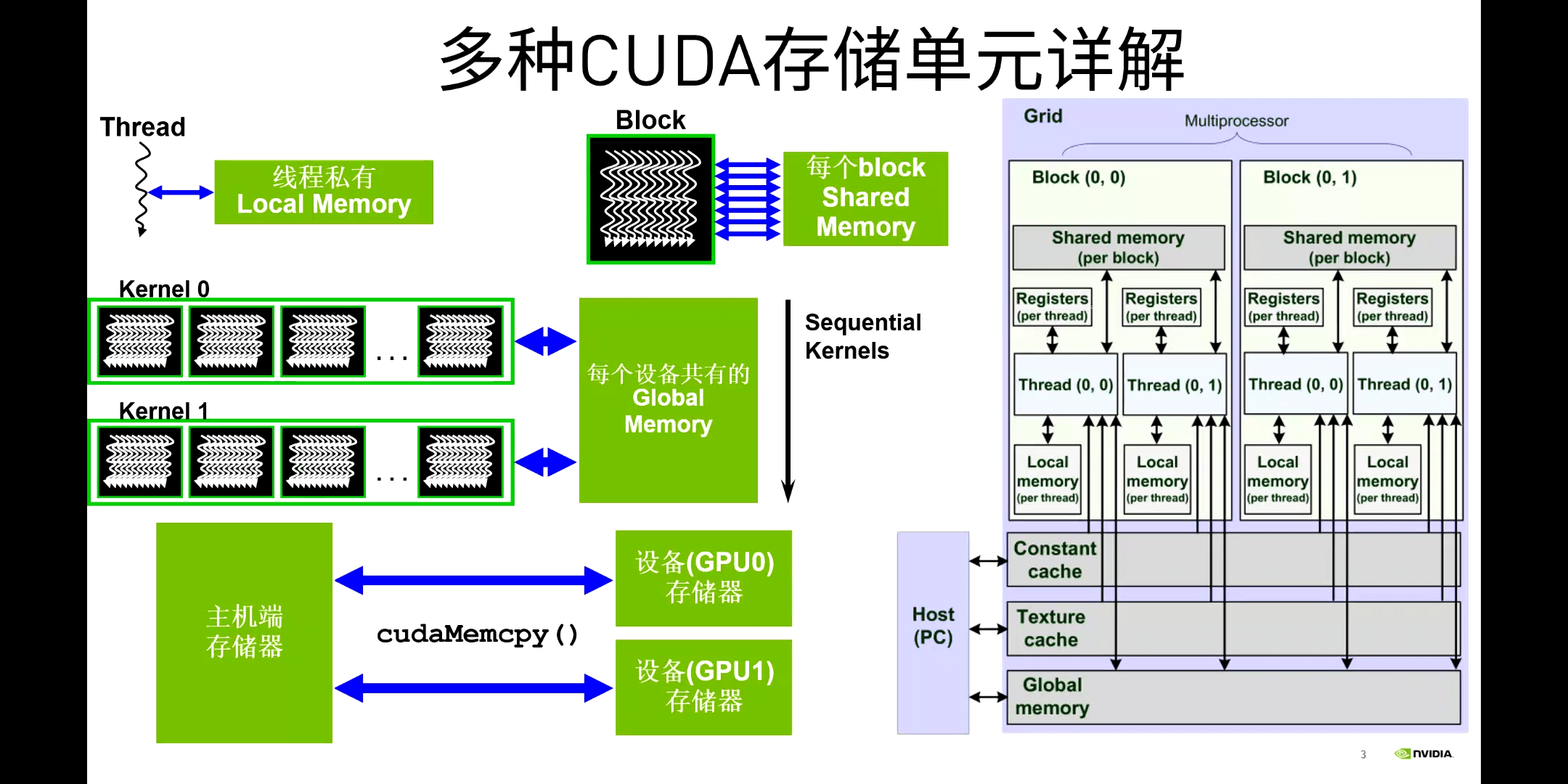
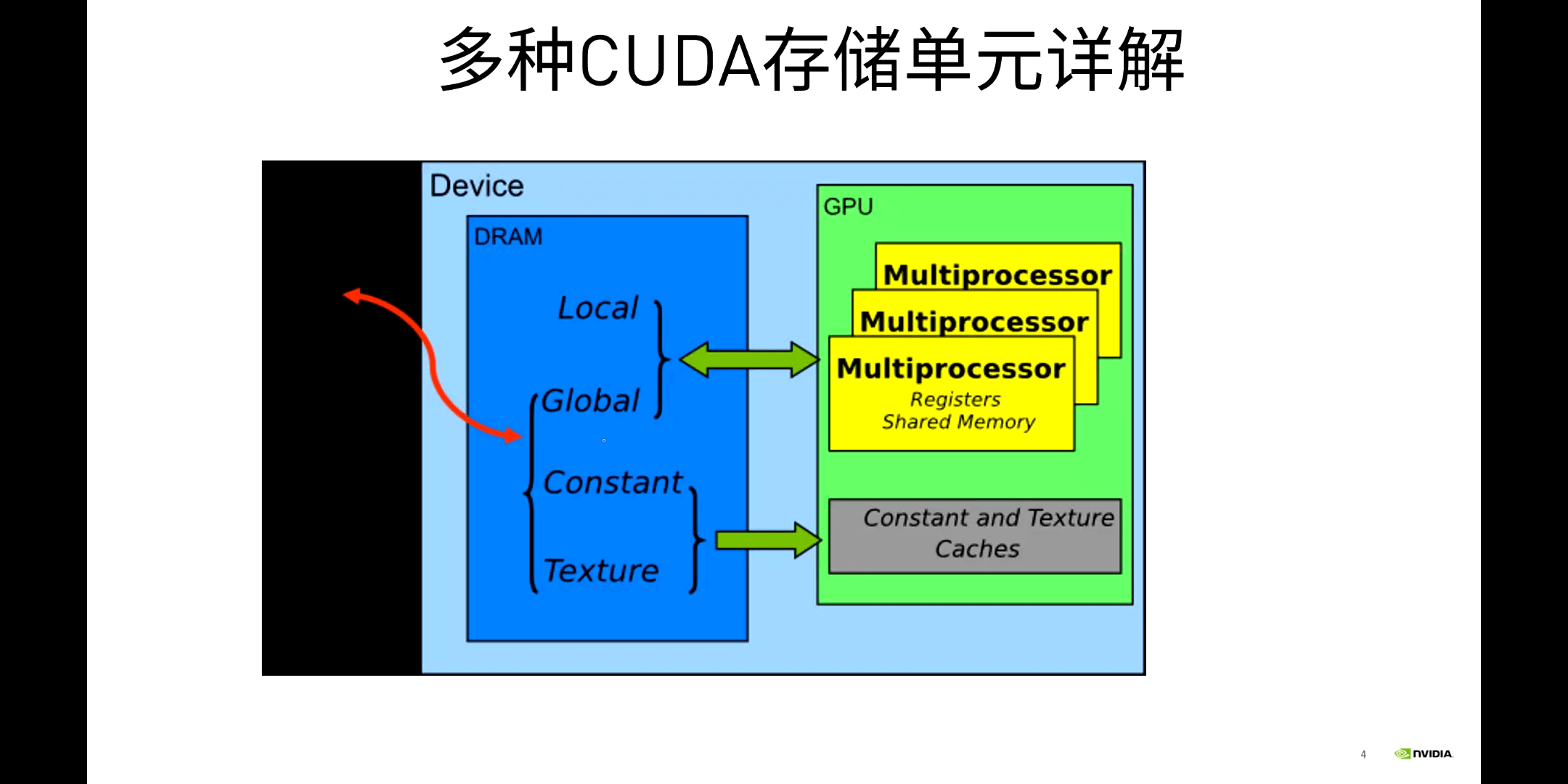 可以看到,Local、Global、Constant、Texture Memory都是在DRAM上的,因此访存的延迟是比较大的。只有Registers和Shared Memory是在GPU内部的,而这其中,只有Shared Memory是我们可以手动操作的。
可以看到,Local、Global、Constant、Texture Memory都是在DRAM上的,因此访存的延迟是比较大的。只有Registers和Shared Memory是在GPU内部的,而这其中,只有Shared Memory是我们可以手动操作的。
(1)Registers
 Registers虽然很快,但是量较小。那为什么不多放一点呢?其原因在于芯片上空间是非常宝贵的,如果放很多的Registers在芯片上,确实会让容量变大。但与之对应的是得要减少一些控制单元的晶体管,可能会导致性能下降。因此,这种设计师一种tradeoff。
Registers虽然很快,但是量较小。那为什么不多放一点呢?其原因在于芯片上空间是非常宝贵的,如果放很多的Registers在芯片上,确实会让容量变大。但与之对应的是得要减少一些控制单元的晶体管,可能会导致性能下降。因此,这种设计师一种tradeoff。
(2)Shared Memory
 我们可以在代码中利用
我们可以在代码中利用__shared__修饰符申请。同一个Block中的线程共享一块Shared Memory,很快,但是相对较小。
(3)Local Memory

(4)Constant Memory
 它的特点是所有Kernel函数都可以访问,且是只读的。常量内存一个使用的场景是光线追踪。
它的特点是所有Kernel函数都可以访问,且是只读的。常量内存一个使用的场景是光线追踪。
(5)Texture Memory
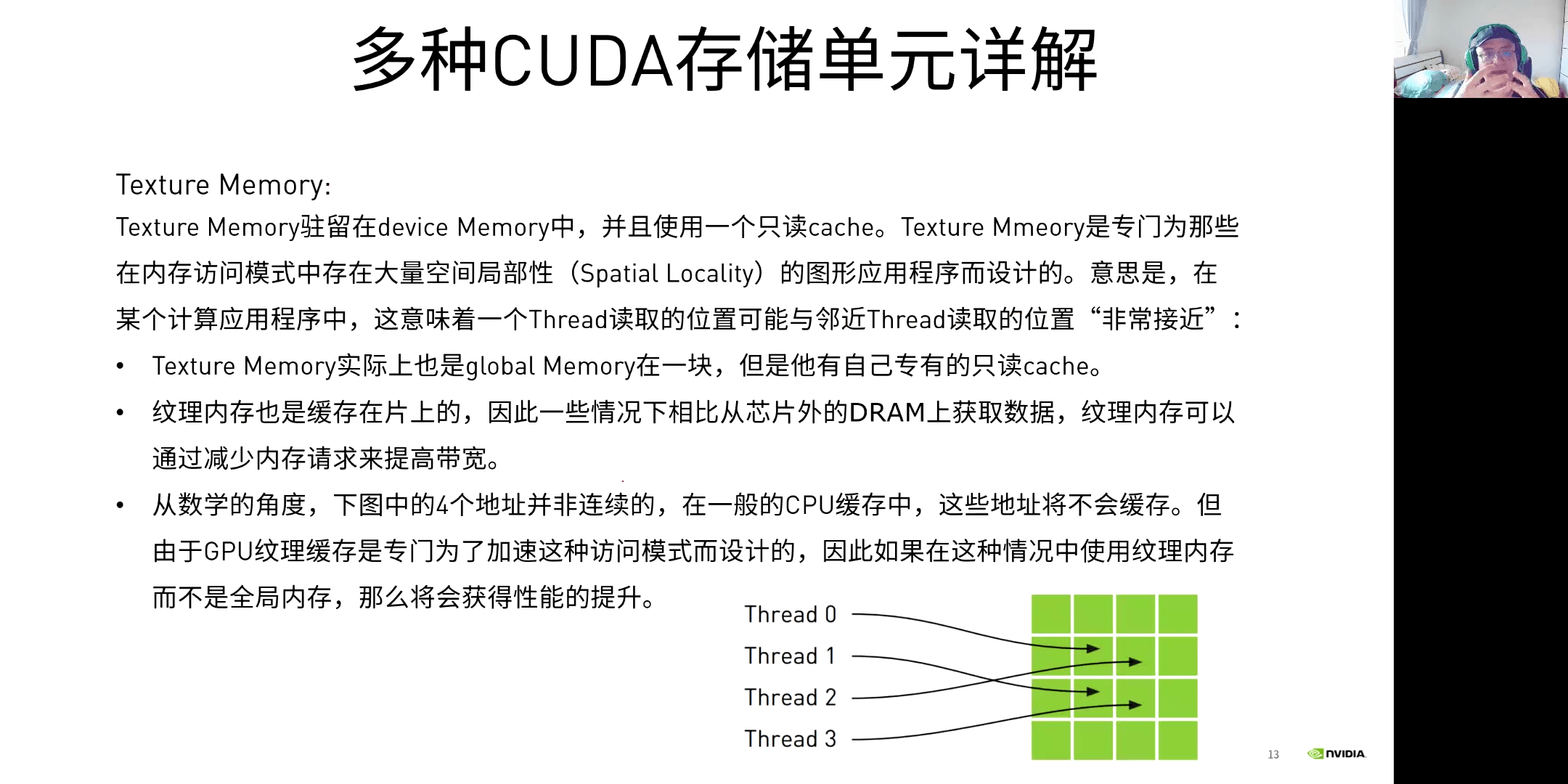 在实际情况中,临近线程访问的数据可能也会临近,那么这个时候Texture Memory就会比较合适。比如计算热传导模型等。
在实际情况中,临近线程访问的数据可能也会临近,那么这个时候Texture Memory就会比较合适。比如计算热传导模型等。
(6)Global Memory
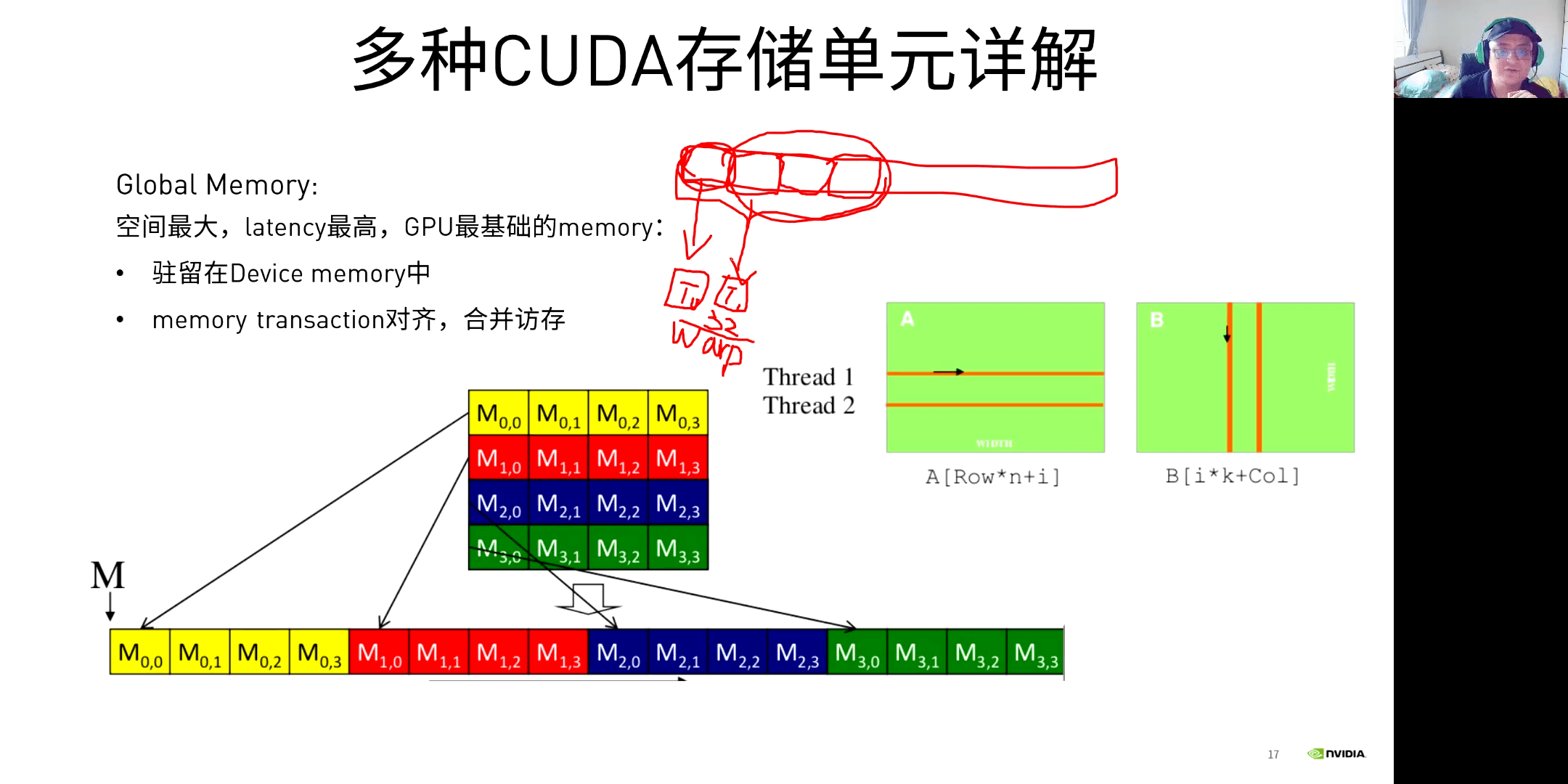
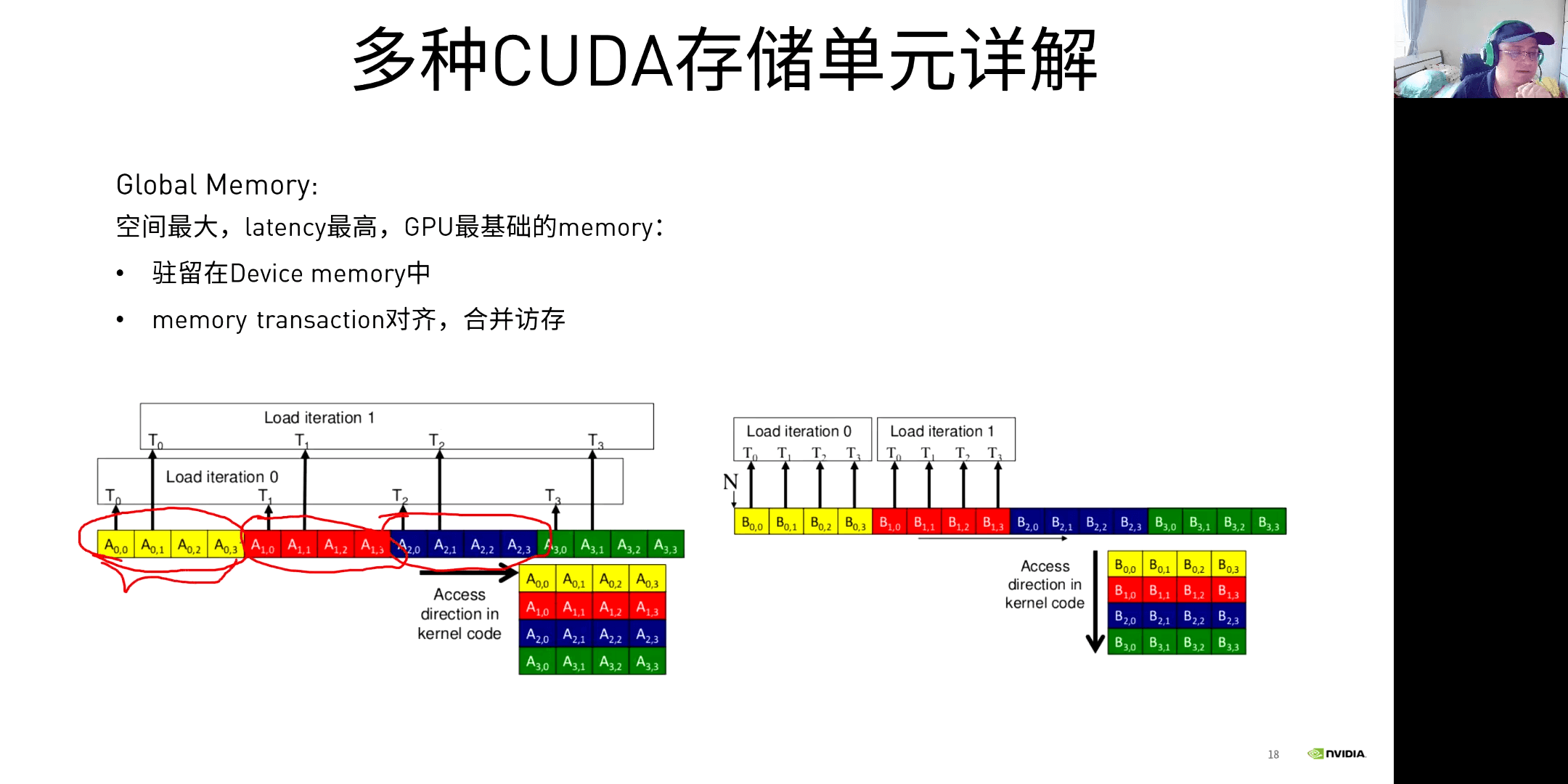 空间最大,延迟最高,是GPU最基础的Memory。
空间最大,延迟最高,是GPU最基础的Memory。
(7)小结
 回想之前矩阵乘法的例子,如果利用Shared Memory,会提升效率。
回想之前矩阵乘法的例子,如果利用Shared Memory,会提升效率。
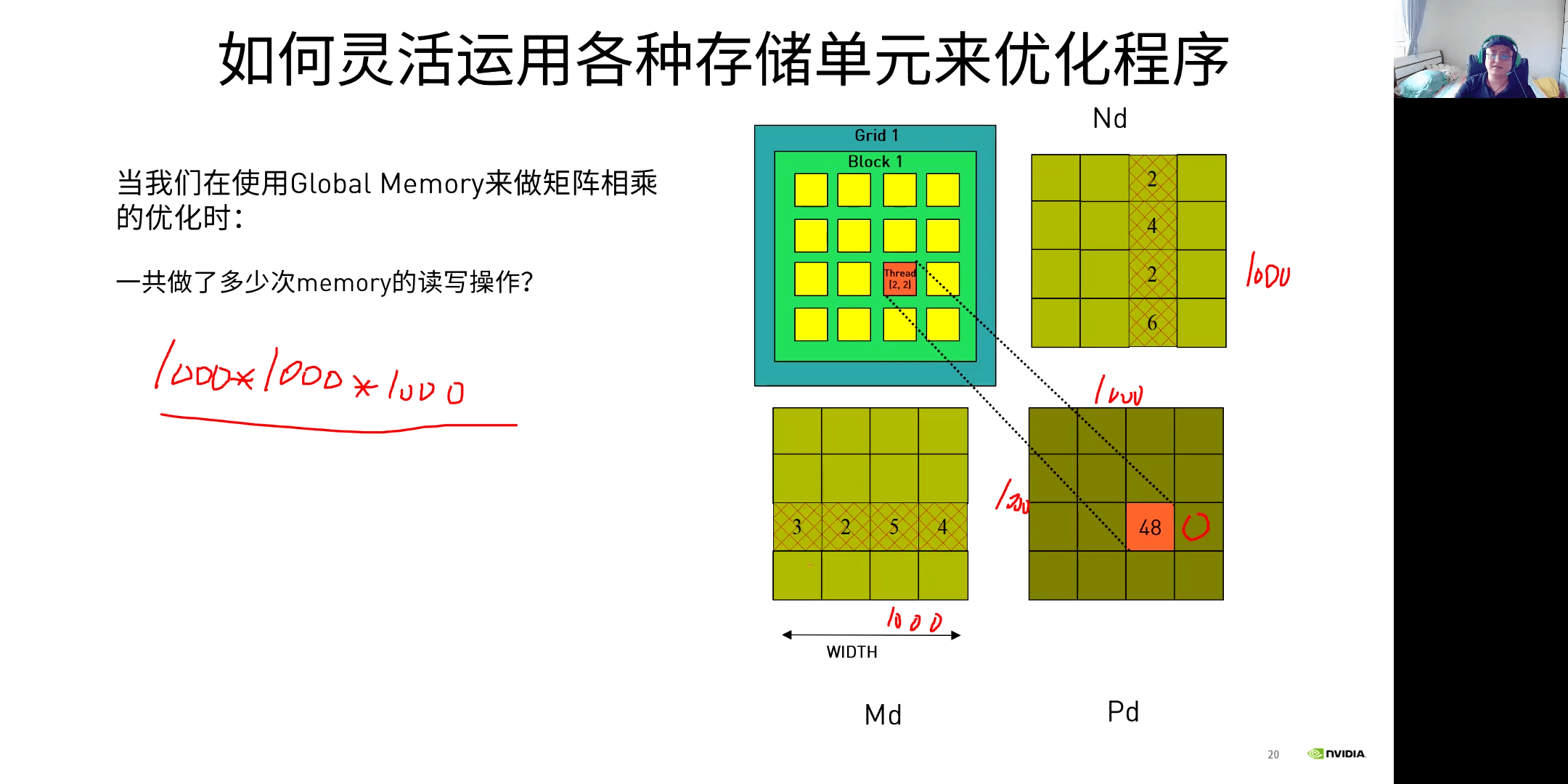
2.利用共享存储单元优化应用
 各个存储单元的读写速度如下所示:
各个存储单元的读写速度如下所示:
 而关于Shared Memory,是目前最快的可以让多个线程沟通的地方。
而关于Shared Memory,是目前最快的可以让多个线程沟通的地方。
 Shared Memory相关特性如下:
Shared Memory相关特性如下:
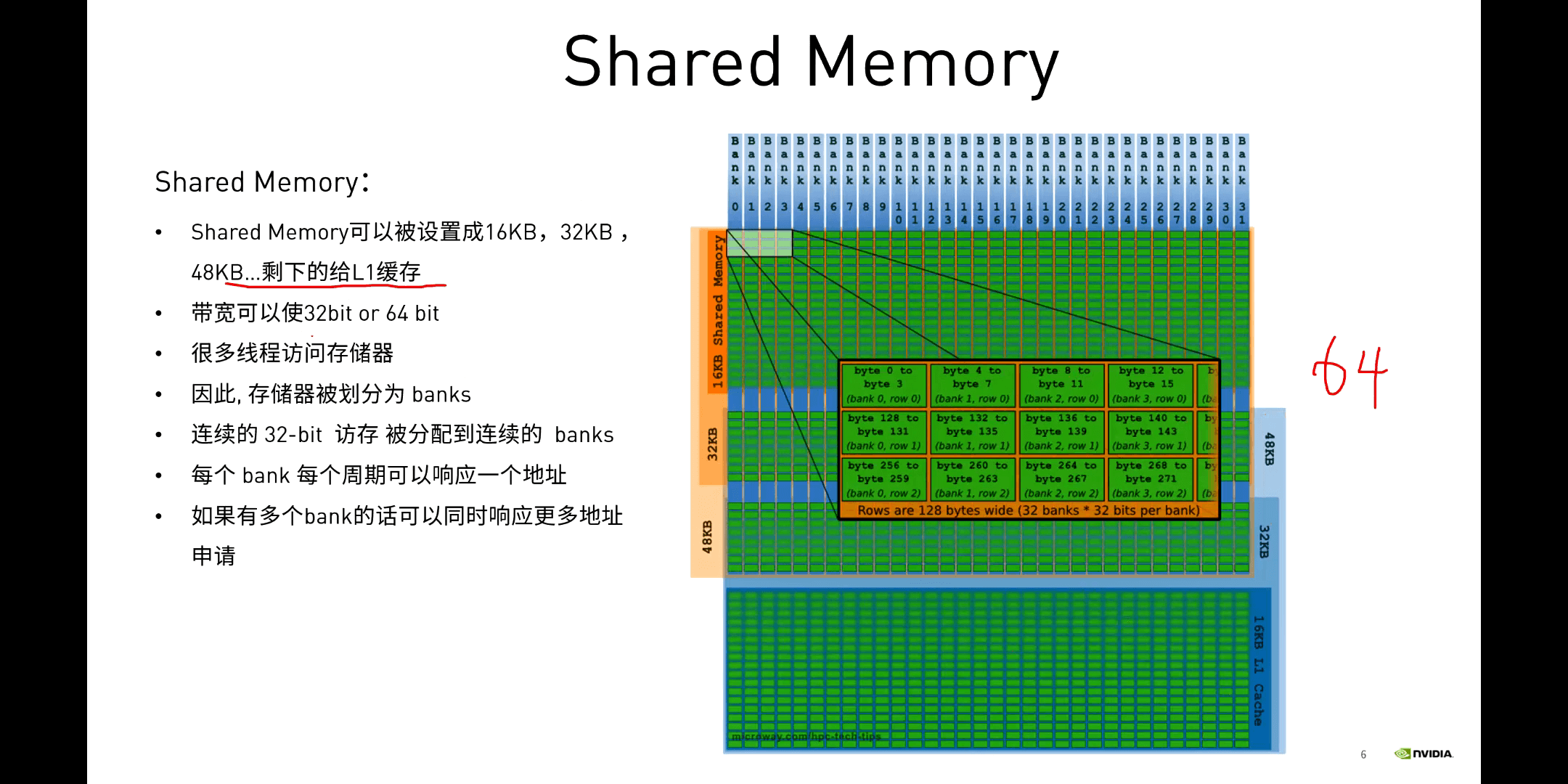
(1)Bank Conflict
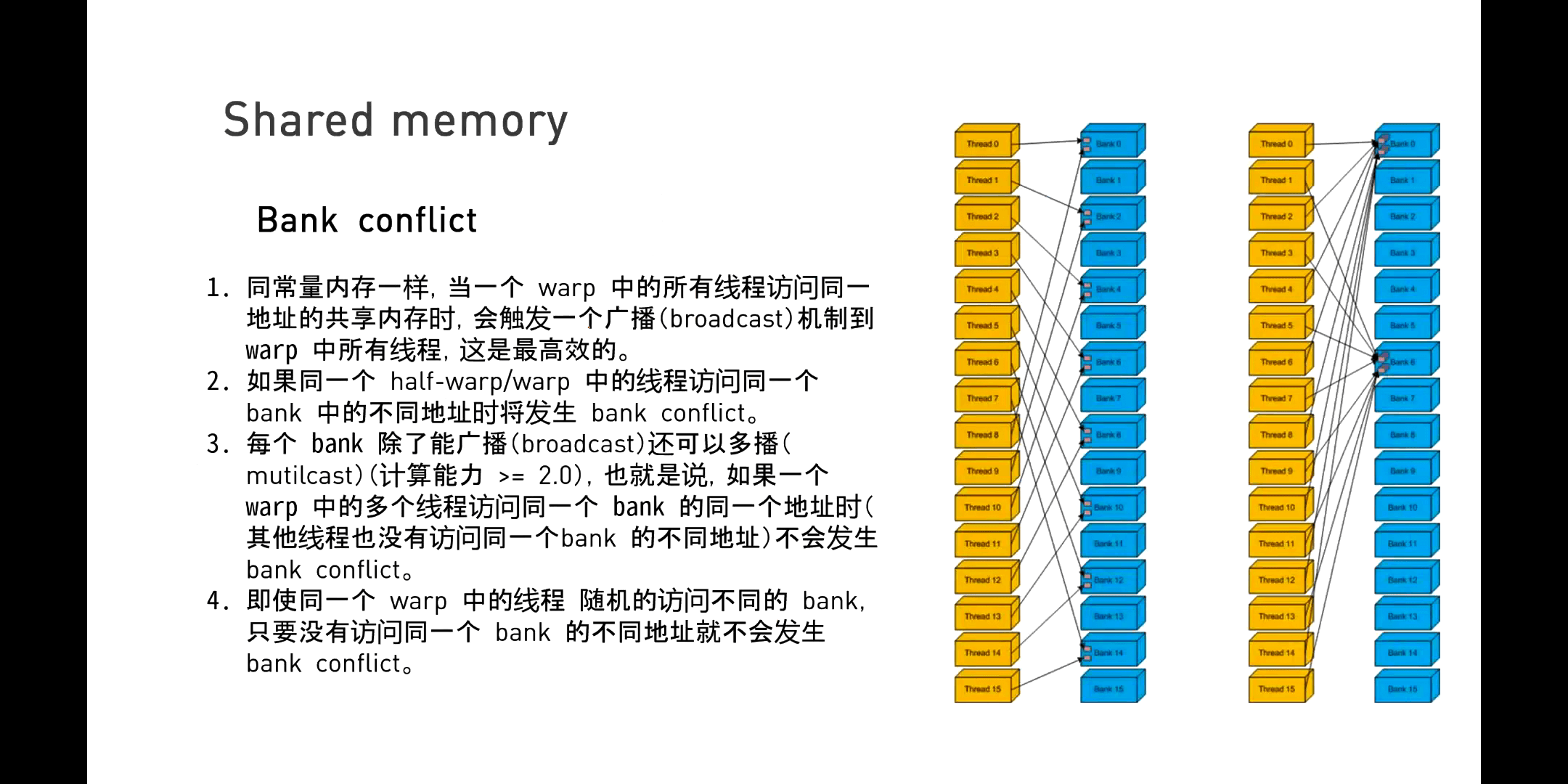
 具体而言是如果同一个Warp中的不同线程访问同一个Bank中的不同地址,就会造成一个访问冲突。如果真的出现了不同线程访问同一个Bank中的不同地址,一个极端的情况是一个Warp中的32个线程访问了Bank中单32个不同地址。系统在这个时候,就会按照访问先后,进行串行响应。但显然这样代价是非常大的。
一个Bank Conflict的实例如下图所示。
具体而言是如果同一个Warp中的不同线程访问同一个Bank中的不同地址,就会造成一个访问冲突。如果真的出现了不同线程访问同一个Bank中的不同地址,一个极端的情况是一个Warp中的32个线程访问了Bank中单32个不同地址。系统在这个时候,就会按照访问先后,进行串行响应。但显然这样代价是非常大的。
一个Bank Conflict的实例如下图所示。

 而为了避免这个问题,我们可以使用Memory Padding的方法,如下图所示。
而为了避免这个问题,我们可以使用Memory Padding的方法,如下图所示。
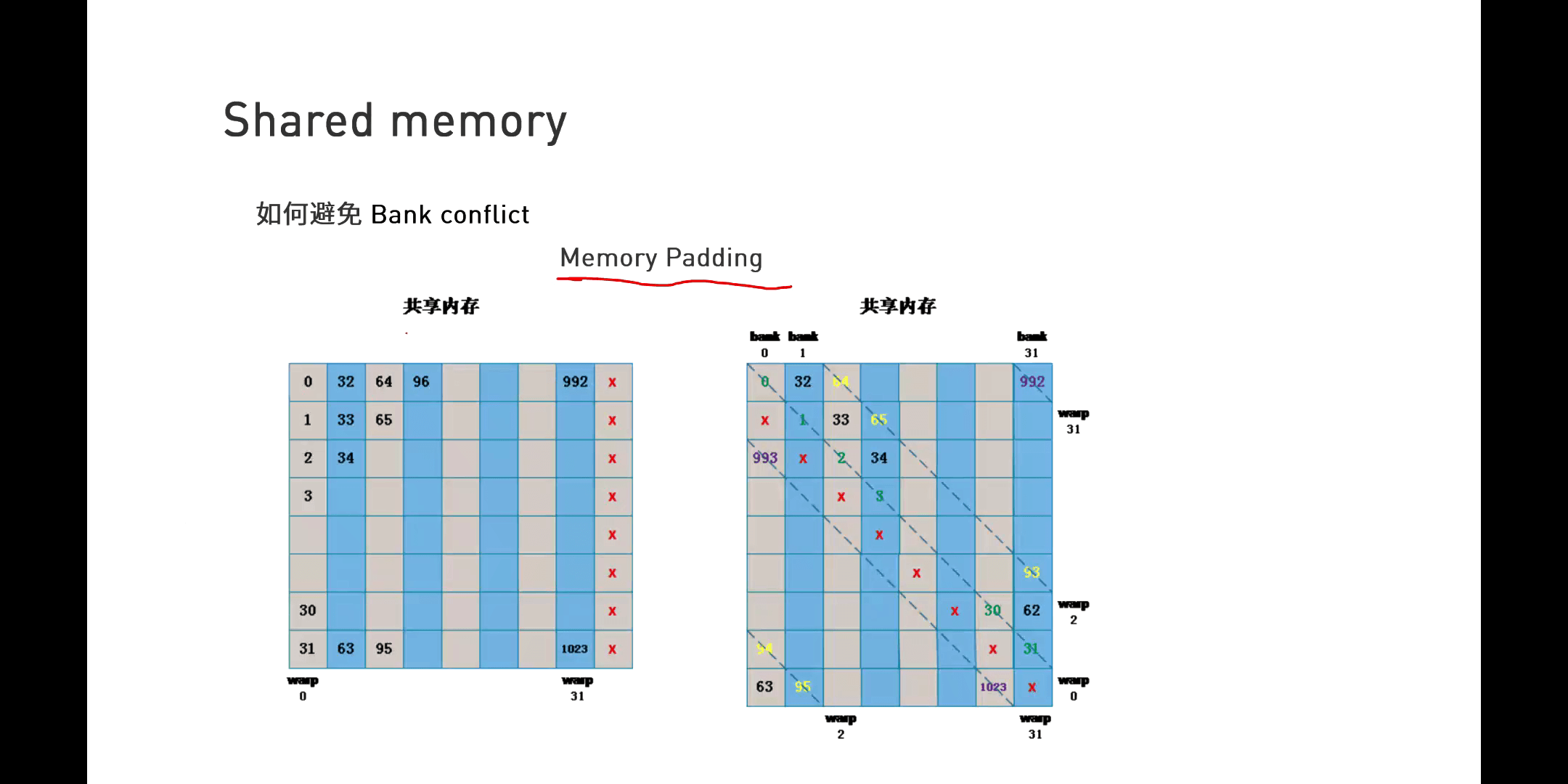
 简单来说就是通过增加一个偏移量,使得访问数据的索引错开。
简单来说就是通过增加一个偏移量,使得访问数据的索引错开。

(2)矩阵乘法
如下图所示,我们可以利用Shared Memory减少重复的矩阵元素读取。
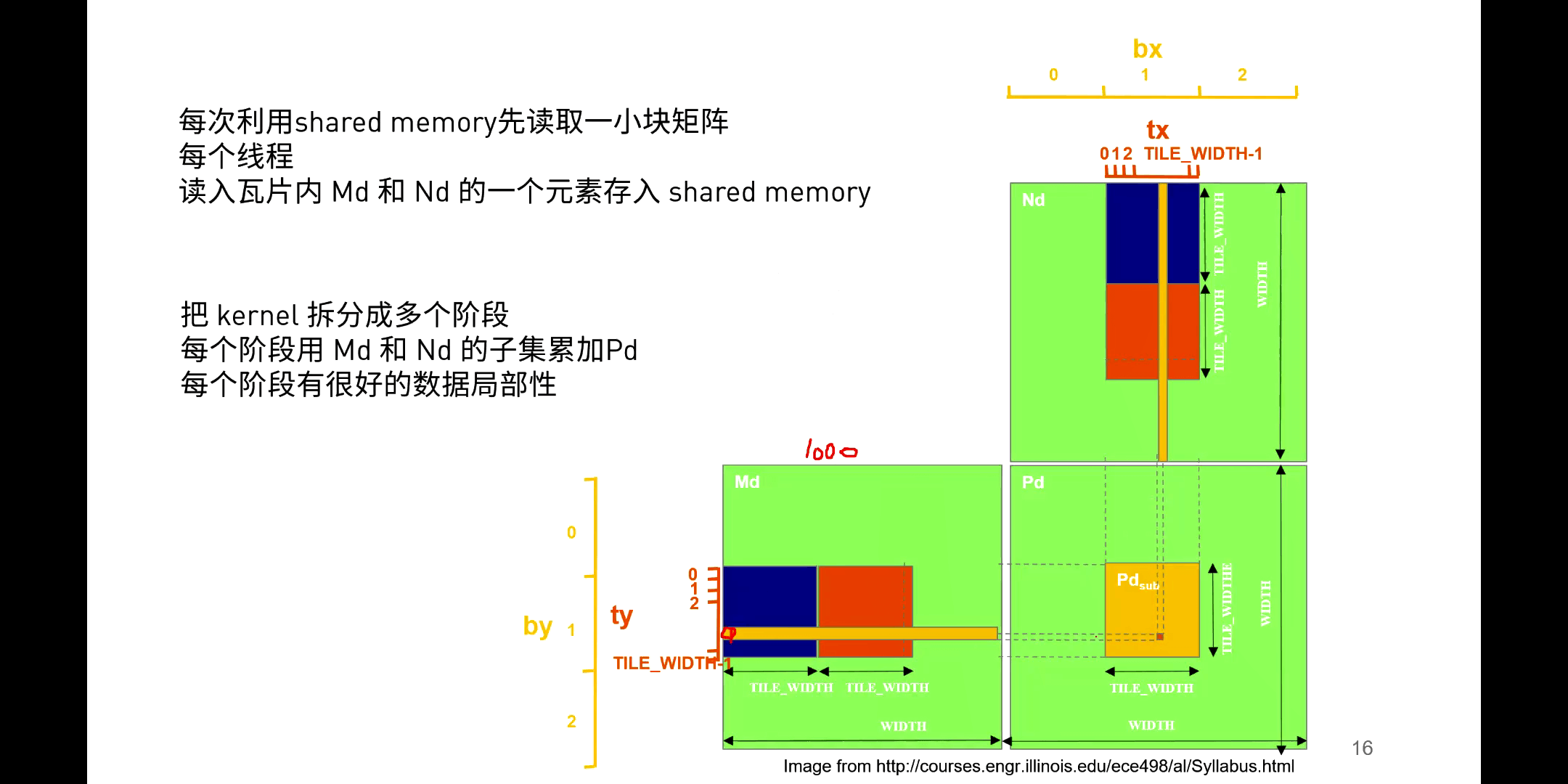 简单来说如果不考虑Shared Memory的大小,我们可以将当前Block所需要的所有数据通通放到Shared Memory中来。但现实的问题是,Shared Memory根本没有这么大的空间,放不下这么多数据。所以我们必须要对要读取的数据分块读取、分块处理,最后再将结果求和,作为这一个Block的结果,如下图所示。
简单来说如果不考虑Shared Memory的大小,我们可以将当前Block所需要的所有数据通通放到Shared Memory中来。但现实的问题是,Shared Memory根本没有这么大的空间,放不下这么多数据。所以我们必须要对要读取的数据分块读取、分块处理,最后再将结果求和,作为这一个Block的结果,如下图所示。
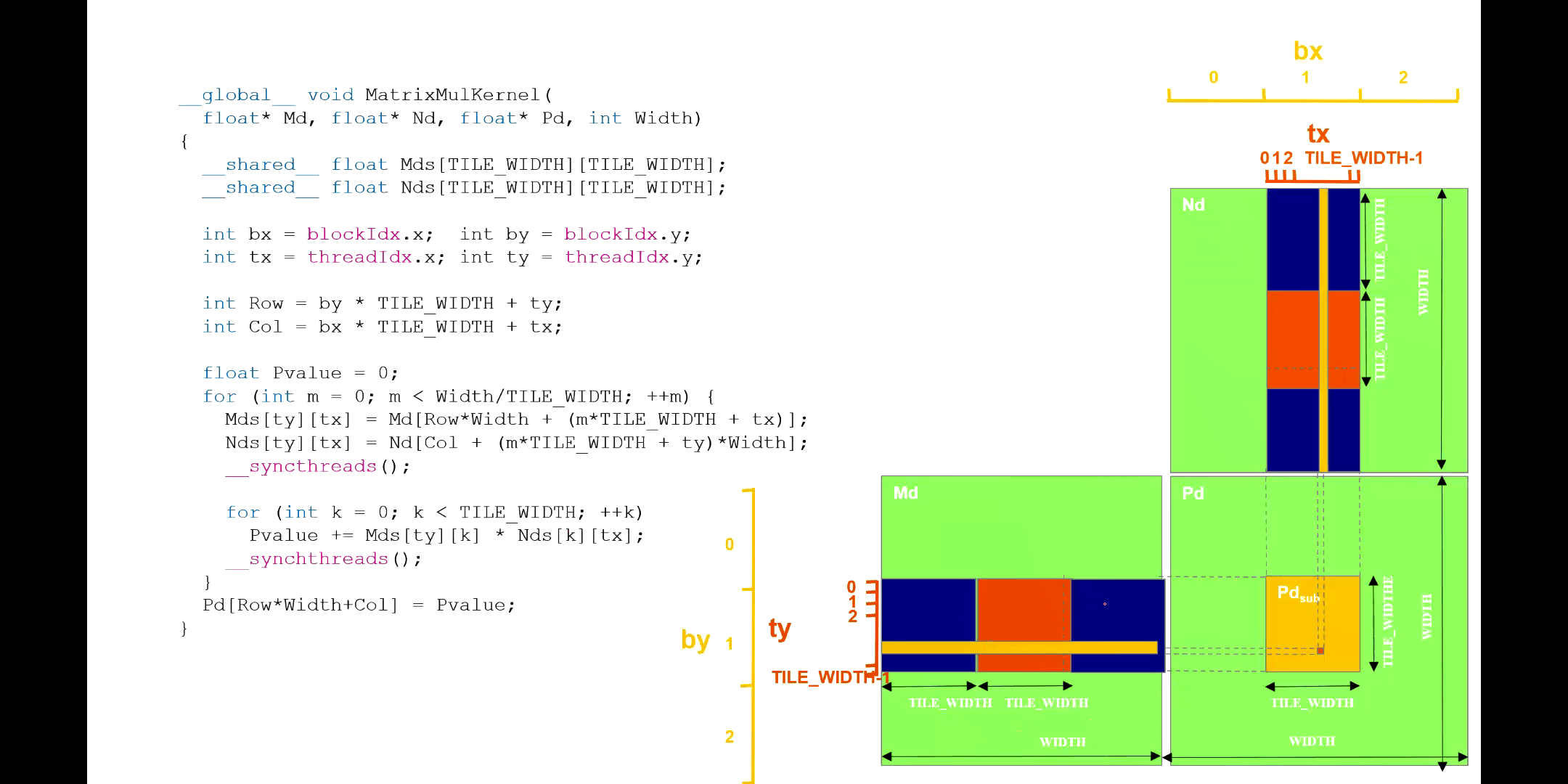
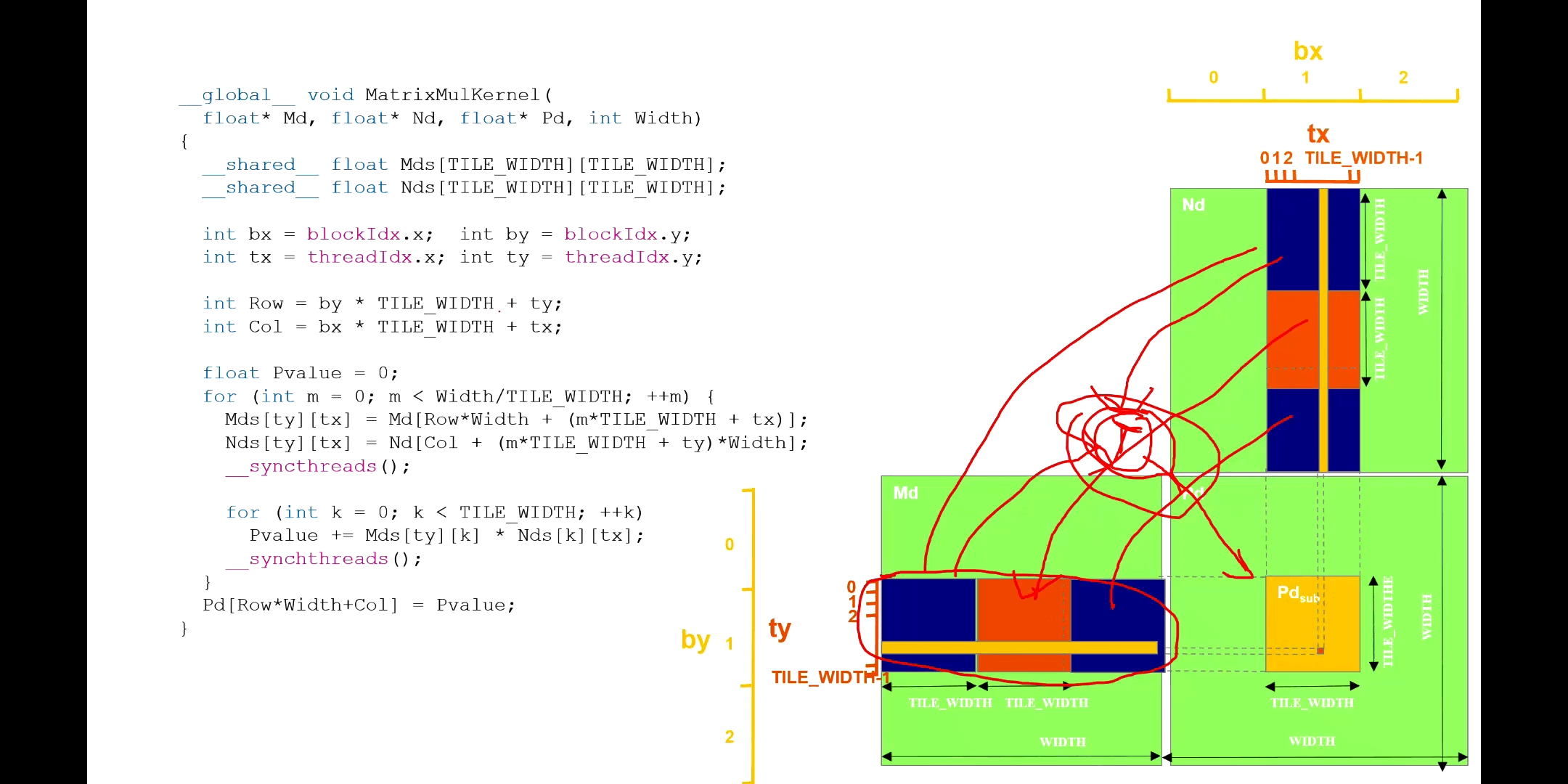
 这里需要注意,核函数里的迭代变量m对应于每一个Tile。当m=0的时候,Block中的线程根据各自的索引,分别可以获得对应的矩阵元素。后面又加了一个同步等待,也就是说Block中所有的线程都赋值完了以后,才会做下面的工作。到这一步也就对应上图中第一个蓝色方块。然后对于这一小块,进行矩阵乘法,得到结果累加变量中。当第二次循环的时候,m=1,也就对应图中橙色方块了。以此类推。一定要注意理解。
这里需要注意,核函数里的迭代变量m对应于每一个Tile。当m=0的时候,Block中的线程根据各自的索引,分别可以获得对应的矩阵元素。后面又加了一个同步等待,也就是说Block中所有的线程都赋值完了以后,才会做下面的工作。到这一步也就对应上图中第一个蓝色方块。然后对于这一小块,进行矩阵乘法,得到结果累加变量中。当第二次循环的时候,m=1,也就对应图中橙色方块了。以此类推。一定要注意理解。
如何选择Shared Memory大小?

本文作者原创,未经许可不得转载,谢谢配合
