本篇博客是几篇微信推送的阅读笔记,内容相对零散一些,可以当作科普了解一下。
1.动态视觉传感器与神经形态视觉
本部分主要参考这篇微信推送。Prophesee联合创始人、匹兹堡大学眼科教授、卡耐基梅隆大学机器人研究所兼职教授、基于事件的视觉技术的开创人之一,Ryad Bensoman认为神经形态视觉(基于事件相机的计算机视觉),将成为计算机视觉的下一个发展方向。
“计算机视觉已经经历了了多次重要革新。”他说,“我至少见证了两次相当于从头开始的重塑。”一次是20世纪90年代从涉及摄影测量的图像处理转向基于几何学的视觉方案,第二次是想机器学习的快速转变。Bensoman认为,在这种图像传感模式打破之前,它实际阻碍了替代技术的创新。GPU等高性能处理器的开发,推迟了寻找替代解决方案的需要,从而延长了这种影响。
1.1 人类感知世界的方式
目前,几乎所有计算机视觉研究的起点都是由可见光相机拍摄的黑白或者彩色影像。这些影像由各类成像传感器拍摄,并且尽可能还原了人眼所看到的一切。但“为什么我们要用图像进行计算机视觉?这是一个非常值得深究的问题。”他说,“我们使用图像,完全是历史原因。”
自公元前五世纪针孔成像技术诞生以来,成像相机就一直伴随着我们。到了16世纪,艺术家们建造了房间大小的装置,用于将设备外的人或风景记录到画布上。经过多年的发展,这些画布逐渐被胶片所取代,以记录图像。随后,数码摄影等技术创新,最终使相机成为现代计算机视觉技术的基础。
然而,Bensoman认为,基于成像相机的计算机视觉技术效率极低。他将其与中世纪城堡的防御系统进行类比:利用城墙周围的守卫监视四面八方接近的敌人。鼓手敲击稳定的节拍,每个守卫会在每个鼓点上,大声喊出他们所看到的情况。在众多守卫的呼喊声中,明辨其中一位发现遥远森林中的敌人并非易事。来到21世纪,鼓声硬件相当于电子时钟信号,而守卫好比每个像素——它们产生了大量数据,并且必须在每个时钟周期捕捉信号,这意味着大量冗余的信息和大量不必要的计算。Bensoman说道:“守卫的监视和汇报相当于城堡的算力。他们需要一直监视没有事情发生的情况,并汇报,相当于一直在搜集大量无用的信息,造成很大的带宽。如果这座城堡还非常庞大且复杂,要捕捉到有用的信息是何其费事且困难。”
1.2 神经形态视觉
神经形态视觉其基本思想受生物系统工作方式的启发,即检测动态场景中的变化,而不是连续分析整个场景。对于刚才的城堡类比,这意味着守卫在没有情况发生时,可以保持静默无需持续汇报,直到他们发现敌人,然后大声喊出他们的位置以发出警报。对于传感器来说,这意味着可以让单个像素决定它们是否看到相关的东西。“像素可以自己决定应该发送什么信息,它们可以选择捕捉有意义的‘特征’信息,而不是捕捉所有信息,这就是区别所在。”他说。与固定频率的系统采集相比,这种基于事件的方法可以节省大量能耗,并减少延迟。他说:“我们需要更具适应性的东西,而这正是基于事件的视觉技术可以提供的,一种自适应的采集频率。当考量振幅变化时,如果某个物体移动得很快,我们就会得到很多样本。如果某个物体没有变化,那么样本量几乎为零。因此,这能够根据场景的动态,调整采集频率。”
这里简单展开一下,在他们看来,相机只要以固定帧率拍摄,就会带来延迟。比如20FPS,每一帧成像时间是50ms,那么每一帧画面相比于拍摄时刻延迟就是50ms。即使FPS为1000,延迟也是1ms。这种观点是挺有意思的。之前并没有从这个角度考虑过问题。
1.3 动态视觉传感器
基于上面提到的观点,所以普诺飞思(Prophesee)公司开发了动态视觉传感器。相比于传统固定帧率的传感器,其最大的特点就是每个像素都是异步且独立的,像素不再由固定的时序源(帧时钟)控制,而是由信号在幅度域的变化来控制,并在检测到变化或运动时进行记录。图像信息不是逐帧发送,而是通过连续的信息流捕获时间运动,并且帧与帧之间没有任何重要信息遗漏。下图展示了普通相机和动态视觉相机的对比。
 下面重点从几个方面来对事件相机进行进一步介绍。
下面重点从几个方面来对事件相机进行进一步介绍。
1.3.1 传统相机的缺点
无论是专业摄影师还是普通人,用过相机的应该都有以下感受:
-
- 传统相机帧率是固定的,以恒定频率采集图像。这样的问题就是,每次成像,相比于真实世界,都会有一定程度的延迟。
-
- 传统相机需要通过一定时间的曝光,使感光器件积累一定的光子,那么在曝光时间之内如果物体在高速运动,则会产生模糊。
-
- 传统相机的动态范围较低,具体表现为在光线极差或者亮度极高时,相机获取的信息有限。
由于相机自身硬件限制,即使高性能相机能够一定程度减小这些问题,但受限于成像原理,终究无法完全避免,而这极大地限制了其应用场景。
1.3.2 事件相机的基本原理
事件相机的基本原理为:当某个像素的亮度变化累计达到一定阈值后,输出一个事件。这里有几个需要注意的地方。首先是亮度变化,而非绝对亮度。换言之,事件相机的输出和变化有关,和绝对亮度无关。无论场景多亮或者多暗,只要没有亮度变化,事件相机都不会有输出。第二是阈值。当亮度变化超过阈值时,才会输出数据,这个阈值时相机固有参数。
此外,在事件相机中,事件有三个要素:时间戳、像素坐标与极性。用一句话来概述就是:在什么时间,哪个像素点,发生了亮度的增加/减小。当场景中由物体运动或光照改变造成大量像素变化时,会产生一系列的事件,这些事件以事件流(Events stream)方式输出。事件流的数据量远小于传统相机传输的数据,且事件流没有最小时间单位,所以不像传统相机定时输出数据,具有低延迟特性。下面的动图揭示了事件相机与传统相机的成像的不同。
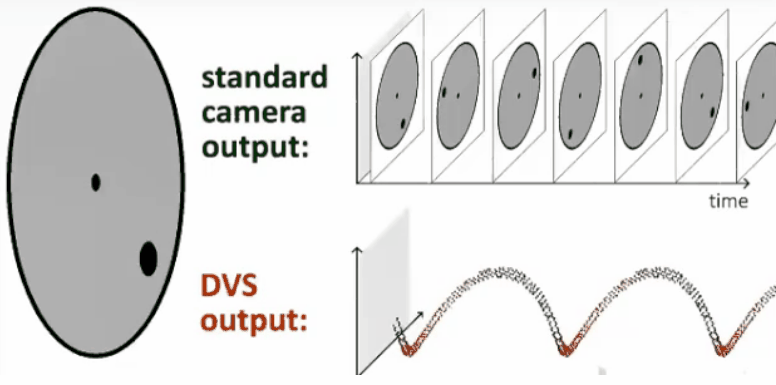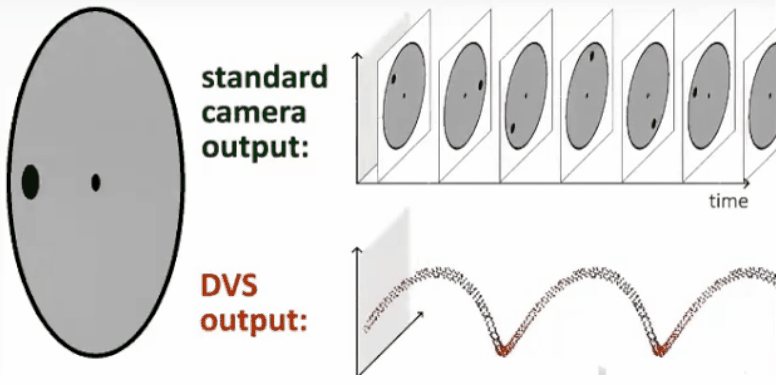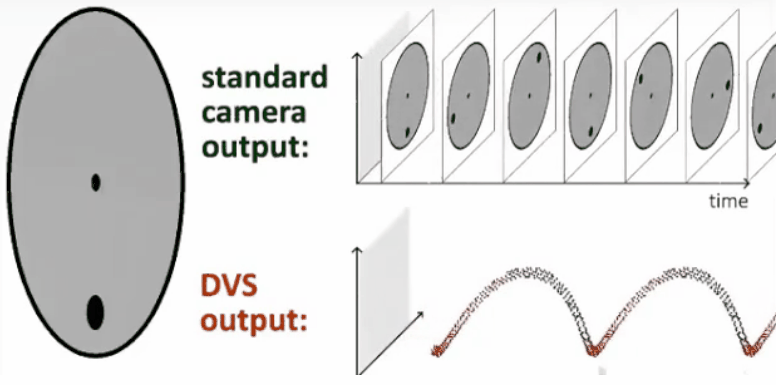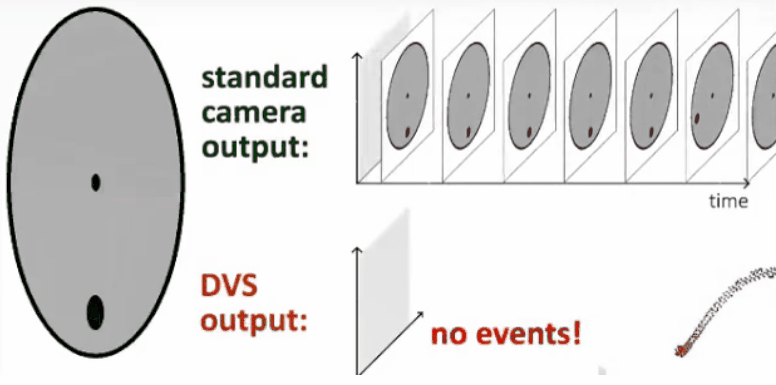 目前,通用神经形态处理器落后于对应的DVS传感器。一些业内最大的厂商(IBM Truenorth、Intel Loihi)仍在努力开发中。Bensoman说,合适的处理器加上正确的传感器,将成为无与伦比的组合。
目前,通用神经形态处理器落后于对应的DVS传感器。一些业内最大的厂商(IBM Truenorth、Intel Loihi)仍在努力开发中。Bensoman说,合适的处理器加上正确的传感器,将成为无与伦比的组合。
1.3.3 个人理解
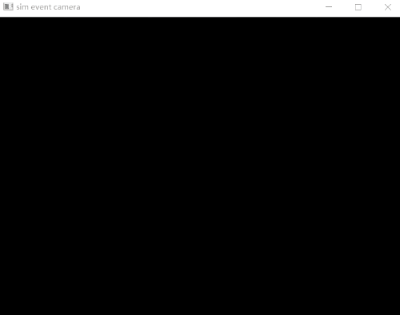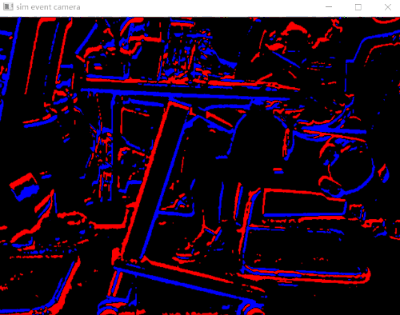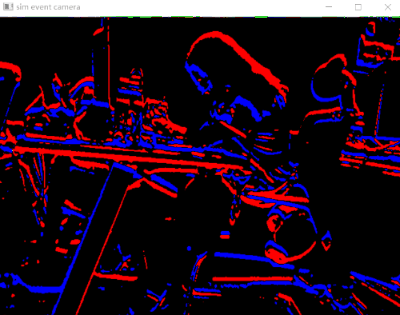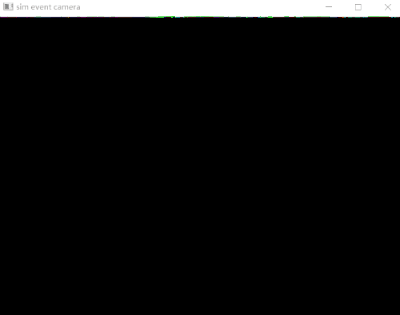
由于事件相机更关注变化信息,所以一些没有变化的地方即使有着丰富的内容也看不到。导致的结果就是拍出来的照片几乎没有什么纹理和可识别的视觉信息。在他们看来运动或者有变化的地方才是值得关注的。所以,如果想在事件相机里不断出现,就需要“一直运动”才可以。如果简单理解,可以把事件相机看作是一种用硬件实现的帧差法。甚至我们可以利用代码简单模拟事件相机的效果,如下。代码主要基于之前这篇博客修改而来。
# coding=utf-8
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
event_th = 20 # 事件相机的判断阈值
flag = False
while 1:
ret, cur_frame = cap.read()
cur_frame = cv2.cvtColor(cur_frame, cv2.COLOR_BGR2GRAY)
if cur_frame is None:
break
else:
if not flag:
last_frame = cur_frame
flag = True
else:
diff_frame = cur_frame.astype(float) - last_frame.astype(float)
event_frame_pos = np.where(diff_frame >= 0, diff_frame, 0)
event_frame_pos = np.where(event_frame_pos >= event_th, 255, 0).astype(np.uint8)
event_frame_pos = cv2.medianBlur(event_frame_pos, 3)
event_frame_neg = np.where(diff_frame < 0, diff_frame, 0)
event_frame_neg = np.where(event_frame_neg <= -event_th, 255, 0).astype(np.uint8)
event_frame_neg = cv2.medianBlur(event_frame_neg, 3)
blank_frame = np.zeros_like(event_frame_pos)
final_frame = cv2.merge((event_frame_pos, blank_frame, event_frame_neg))
cv2.imshow("sim event camera", final_frame)
cv2.waitKey(1)
last_frame = cur_frame
cap.release()
亮度增加用蓝色表示,亮度减少用红色表示。代码中为了过滤一些噪声,用中值滤波进行了一些处理,当然也可以不用。展示的效果如下所示。
2.量子成像高灵敏度图像传感器
本部分主要参考这篇微信推送,该推送参考了潘卫军的《基于量子成像的下一代甚高灵敏度图像传感器技术》论文。在这篇论文中,作者详细分析了成像过程中各个步骤可能引入的噪声,感兴趣可以参考。
高灵敏度探测成像是空间遥感应用中的一个重要技术领域,如全天时对地观测、空间暗弱目标跟踪识别等应用,对于甚高灵敏度图像传感器的需求日益强烈。随着固态图像传感器技术水平的不断提高,尤其背照式及埋沟道等工艺的突破,使得固态图像传感器的灵敏度有了极大提升。尽管科学级CMOS图像传感器可以实现低照度高灵敏成像,但还远未达到单光子探测的辐射分辨能力。量子CMOS图像传感器的出现,对于拓宽空间遥感高灵敏成像应用领域、提升相应的应用水平具有十分重要的意义。
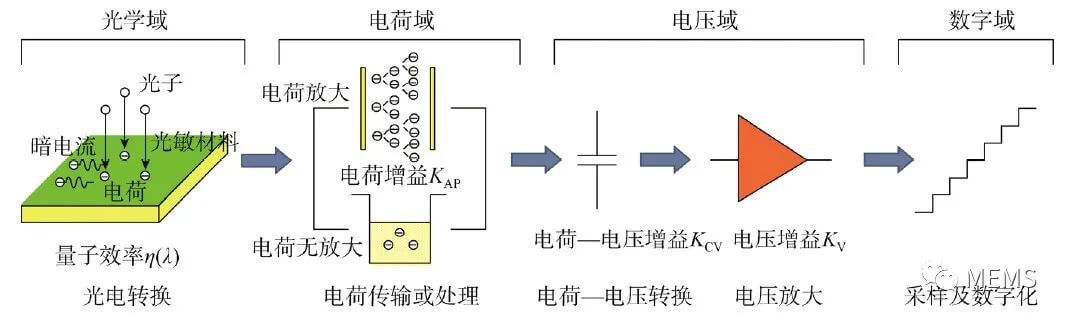
要达到单光子探测的甚高灵敏度要求,对等效输入读出噪声的大小有严格要求。甚高灵敏度图像传感器类似用于观测辐射强度的“显微镜”,其本身的噪声只有达到深亚电子水平才能实现单个光子的分辨能力,所以,甚高灵敏度就意味着甚低噪声。减小噪声的技术途径主要包括:(1)增大信号增益;(2)减小各级噪声;(3)实现足够小的暗电流,由于暗电流引入的散粒噪声是无法通过增大信号增益来抑制的,只能通过工艺上的优化来降低暗电流,从而减弱暗电流散粒噪声的影响。另外,根据增大信号增益的不同方法,形成了目前两种不同的甚高灵敏图像传感器主流技术,一种是以EMCCD和SPAD为代表的通过电荷域内的电荷数放大实现信号高增益放大的技术,另一种则是以科学级CMOS和量子CMOS图像传感器为代表的通过增大电荷-电压转换增益或者跨导积分增益实现高增益放大的技术。
在固态图像传感器领域,CMOS图像传感器技术的发展大致经历了三次技术飞跃:第一次为无源像素到有源像素的发展;第二次为科学级CMOS图像传感器的发展;第三次是量子CMOS图像传感器的发展。量子CMOS图像传感器的关键技术主要有深亚飞法低浮置扩散(FD)电容技术、跨导变积分放大技术以及列级相关多采样(CMS)技术等。目前具有单光子探测能力的主流甚高灵敏度图像传感器包括单光子雪崩二极管(SPAD)、EMCCD、科学级CMOS以及量子CMOS图像传感器,对这些器件从分辨率、像元尺寸、量子效率、响应速度、暗电流以及读出噪声六个维度进行了性能比较,如下。
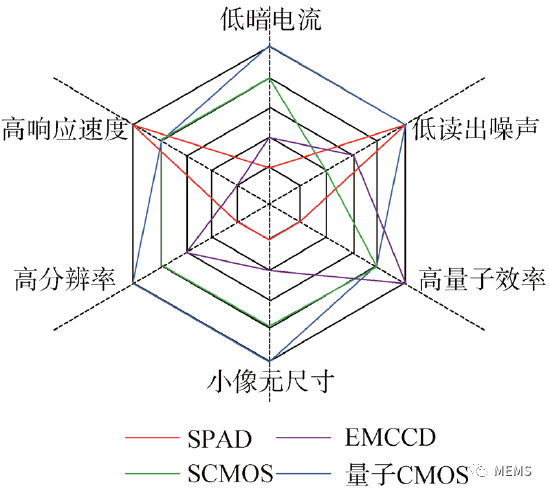 量子CMOS图像传感器的未来发展趋势将向更低噪声继续推进,更灵活的智能化成像模式。最后,展示了常规的sCMOS和量子CMOS的使用范围,如下所示。
量子CMOS图像传感器的未来发展趋势将向更低噪声继续推进,更灵活的智能化成像模式。最后,展示了常规的sCMOS和量子CMOS的使用范围,如下所示。

3.光场相机与光场成像
本部分主要参考这篇微信推送以及一些相关网页,内容比较丰富,感兴趣可阅读参考资料7-13。
3.1 什么是光场
光场可以理解为是光的某个物理量在空间内的分布,其在1939年由A. Gershun提出。后来被E. H. Adelson和J. R. Bergen在上世纪末的一篇论文中完善,并给出了全光函数(Plenoptic Function)的形式。简单来说,光场描述空间中任意一点向任意方向的光线的强度。完整描述光场的全光函数是个7维函数,包括:任意一点的位置(x,y,z)、任意方向(极坐标的θ,φ,类似于经纬度,如下图所示)、波长λ(其实表示的就是颜色,不同波长的光颜色不同)、时间t。
 这样,任意一点的全光函数示意如下。
这样,任意一点的全光函数示意如下。
 而再加上位置之后,完整的全光函数示意如下。
而再加上位置之后,完整的全光函数示意如下。
 可以看到,每一个位置,都可以有一个独一无二的全光函数。在实际应用中,波长和时间是以不同通道(如RGB)和不同帧来表示的。如果除去这两个因素不看,那就只剩位置、方向,一共5个变量了。而目前,大部分成像系统中光线都在有限的光路里传播,所以一种更简单的、利用两个平面来表示光场的方法应运而生,如下。
可以看到,每一个位置,都可以有一个独一无二的全光函数。在实际应用中,波长和时间是以不同通道(如RGB)和不同帧来表示的。如果除去这两个因素不看,那就只剩位置、方向,一共5个变量了。而目前,大部分成像系统中光线都在有限的光路里传播,所以一种更简单的、利用两个平面来表示光场的方法应运而生,如下。
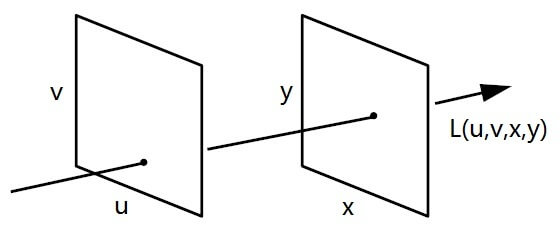 如上图所示,在左右两个平面中,如果我们分别在两个平面上选取两个点,这两个点构成一条光线,你会发现,这条光线的位置和方向就都被确定了。但我们只需要知道这条光线在两个平面中的坐标,也就是上图中的u、v、x、y。
如上图所示,在左右两个平面中,如果我们分别在两个平面上选取两个点,这两个点构成一条光线,你会发现,这条光线的位置和方向就都被确定了。但我们只需要知道这条光线在两个平面中的坐标,也就是上图中的u、v、x、y。
3.2 光场的测量
上面说到,我们可以用两个平面中的四个坐标值来表示光场,那么如何测量呢?经典的办法就是相机阵列,如下图所示,为Stanford Multi-Camera Array。
 还是先从原理说起。如下图所示,为经典小孔成像模型、凸透镜成像模型的示意。
还是先从原理说起。如下图所示,为经典小孔成像模型、凸透镜成像模型的示意。
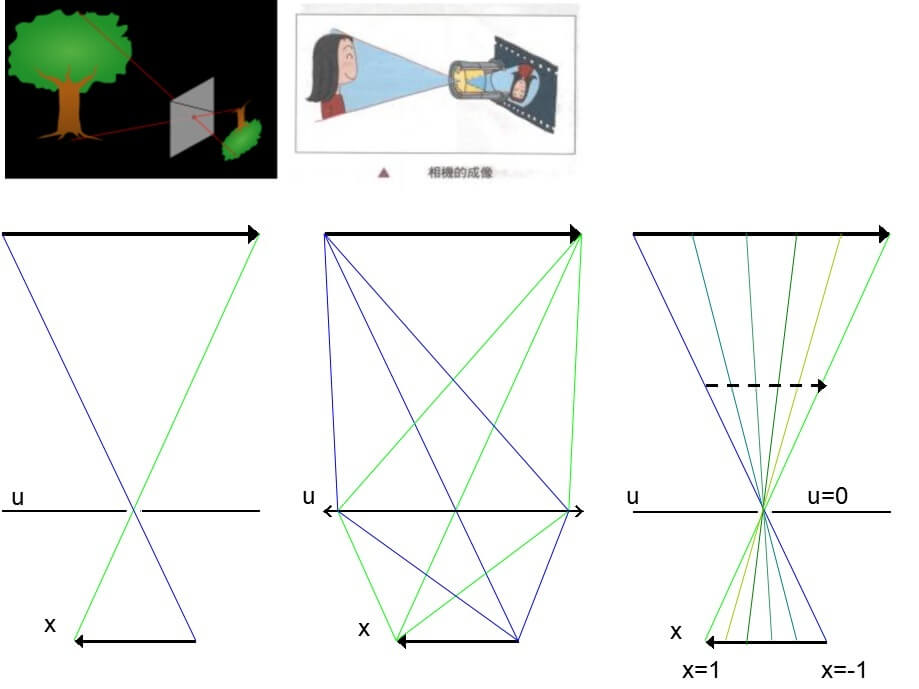 首先看最左边,是经典的小孔成像模型,没有什么特别好说的。但在实际中,小孔成像模型有没有什么问题呢,答案是肯定的。小孔成像的分辨率受限于小孔的大小。如果你初中做过小孔成像相关实验应该会发现,孔的直径越大,成像越不清晰。但如果孔太小的话,进光量又太少,导致成像暗淡。所以进光量和小孔大小天生是一个矛盾的关系。有没有解决办法呢?答案也是肯定的。还是初中物理。还记得以前学过的凸透镜、凹透镜吗?一个基本的原理就是:凸透镜具有聚光性。我们正好可以利用这个性质,将小孔换成凸透镜,就可以解决这个问题,如上图中间所示。在凸透镜成像系统中,无论实际构造如何复杂,核心原理还是一样的。空间中某个点发出的光线,经过凸透镜,最终又重新汇聚于一点。上面我们简单介绍了小孔成像模型和凸透镜成像模型。那么用它们如何测量光场呢?回顾上面我们提到的利用两平面的四个坐标表示光场的方法。如果我们将镜头所在的平面作为uv平面,镜头中心为(0,0),焦平面或者说像平面为xy平面,某束光线的对应位置为(x,y)。那么这样,普通成像系统中拍摄的一幅映像就可以看成是uv平面上(0,0)位置发出的光线在像平面上的采样,我们就可以很好地表示出这个光场了。如果这样做的话你会发现,我们得到的是uv平面上(0,0)这一个点与xy平面上点的关系。但要获得真正两个平面之间的光场,仅靠uv平面上的一个点是不够的,所以我们需要在uv平面上采样多个点。而这采样的多个点,其实就是上面提到的相机阵列。当然了,除了相机阵列,我们还可以利用微透镜阵列,下面进一步介绍。
首先看最左边,是经典的小孔成像模型,没有什么特别好说的。但在实际中,小孔成像模型有没有什么问题呢,答案是肯定的。小孔成像的分辨率受限于小孔的大小。如果你初中做过小孔成像相关实验应该会发现,孔的直径越大,成像越不清晰。但如果孔太小的话,进光量又太少,导致成像暗淡。所以进光量和小孔大小天生是一个矛盾的关系。有没有解决办法呢?答案也是肯定的。还是初中物理。还记得以前学过的凸透镜、凹透镜吗?一个基本的原理就是:凸透镜具有聚光性。我们正好可以利用这个性质,将小孔换成凸透镜,就可以解决这个问题,如上图中间所示。在凸透镜成像系统中,无论实际构造如何复杂,核心原理还是一样的。空间中某个点发出的光线,经过凸透镜,最终又重新汇聚于一点。上面我们简单介绍了小孔成像模型和凸透镜成像模型。那么用它们如何测量光场呢?回顾上面我们提到的利用两平面的四个坐标表示光场的方法。如果我们将镜头所在的平面作为uv平面,镜头中心为(0,0),焦平面或者说像平面为xy平面,某束光线的对应位置为(x,y)。那么这样,普通成像系统中拍摄的一幅映像就可以看成是uv平面上(0,0)位置发出的光线在像平面上的采样,我们就可以很好地表示出这个光场了。如果这样做的话你会发现,我们得到的是uv平面上(0,0)这一个点与xy平面上点的关系。但要获得真正两个平面之间的光场,仅靠uv平面上的一个点是不够的,所以我们需要在uv平面上采样多个点。而这采样的多个点,其实就是上面提到的相机阵列。当然了,除了相机阵列,我们还可以利用微透镜阵列,下面进一步介绍。
3.3 光场相机的特点
本部分主要参考这个网页。如下图所示,为光场相机的基本构成。
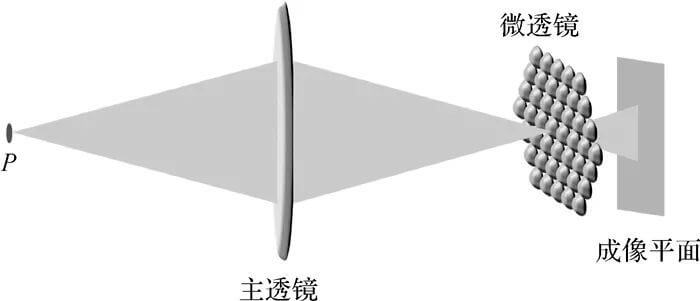 光场相机主要由主透镜、微透镜阵列和成像传感器构成。和上面由多个相机构成的相机阵列,他的体积可以小很多,简单对比示意图如下。
光场相机主要由主透镜、微透镜阵列和成像传感器构成。和上面由多个相机构成的相机阵列,他的体积可以小很多,简单对比示意图如下。
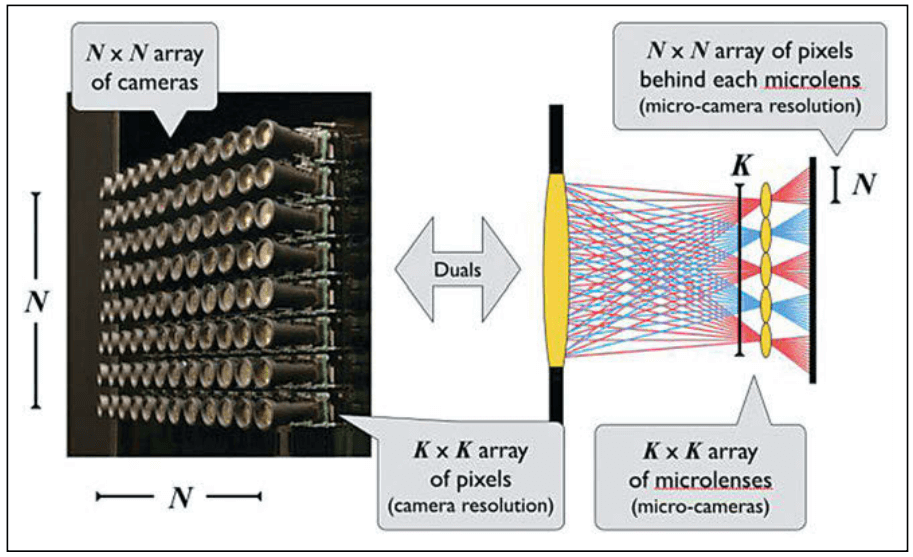 可以看到,通过微透镜阵列,可以实现相同的效果。光场相机和传统相机相比,它的主要问题如下:
可以看到,通过微透镜阵列,可以实现相同的效果。光场相机和传统相机相比,它的主要问题如下:
-
空间分辨率低。光场相机为了采集不同视角的信息,在感光器材前面放置了微透镜阵列。单个视角下光场图像的大小可以看作是微透镜阵列中微透镜的个数。对于一个微透镜数量在100-200之间的阵列,光场图像大小可能只有几万像素。这个分辨率对于消费级摄影器材而言是无法接受的。这也就是为什么代表性的Lytro公司在2011年成立、2018年倒闭的原因。此外,目前比较有代表性的公司有德国的Raytrix、国内的上海奕目科技。
-
基线过短。对于光场相机,每个微透镜都记录这入射点光源的一部分信息,此时,如果把每个微透镜都当做一个小相机,那么由于有多个微透镜,也就有多个小相机。这些相机之间的基线长度呢?答案是,所有被点亮的透镜中,最远的两个之间的距离。可以看到,基线长度随着光源离焦平面的距离而变化。离焦平面近的时候,一般只有少数微透镜被点亮,因此基线距离较小;而离焦平面远时,可能全部微透镜都被点亮,那么基线距离就为微透镜阵列的直径。但即使是最大的基线,其长度也不会超过感光芯片尺寸本身。过短的基线会给深度测量等应用带来困难。
-
相机的动态范围被压缩。上面第二点中也提到,当点光源靠近焦平面时,只有少数微透镜被点亮,也就是说光的能量集中到了少数感光区域上,这意味着传感器上很小的面积上接收了大量能量,为了不过曝,感光元件得降低感光度;另一方面,当点光源远离焦平面时,多个微透镜被点亮,点光源的能量被透镜分散,感光元件上感知到的光线能量被显著分散了,为了不过暗,感光元件得提升感光度。因此,为了不让影像过曝或过暗,被摄物体只能在一个相对较小的动态范围内,使得物体离焦近时不至于过曝,离焦远时不至于过暗。
当然,光场相机也有其优点。它快速、灵活、多变。简单列举如下。
-
密集的多视角。由于微透镜阵列的存在,光场相机在视角的密集程度上具有明显优势。这为重聚焦、深度估计提供了可能性。
-
结构的紧凑性。前面提到了,可以使用相机阵列或者微透镜阵列实现光场相机。在一些光学观察窗口首先的情况下,光场相机会具有一定优势。
-
快速的宽视场体成像。得益于记录的光场信息,光场相机仅需单次拍摄,就可以快速地完成对被摄物体的3D图像采集。
3.4 光场相机的应用
由于记录了完整的场景光场信息,所以基于这些丰富的信息,可以做很多事情。光场相机最多的应用场景,目前主要集中在3D成像领域,特别是深度估计、3D光强场的逆向重构两大方面。此外,基于记录的完整光场信息还可以实现不同景深的多次对焦。感兴趣的话,可以参考这个网页,里面有一些光场相机的实际应用案例展示。
4.相机成像的物理基础
在前面的很多篇博客中,比如这篇和这篇,我们介绍了相机成像的过程与小孔成像模型,这里再简单回顾一下。本节部分参考这篇微信推送。另外说一句,当然了,日常生活中也有一些比较独特的相机,如鱼眼相机,其标定和数据处理也会和常规相机有一些不同,感兴趣可以参考这篇微信推送。
4.1 小孔成像
如下图所示,为小孔成像的基本示意。
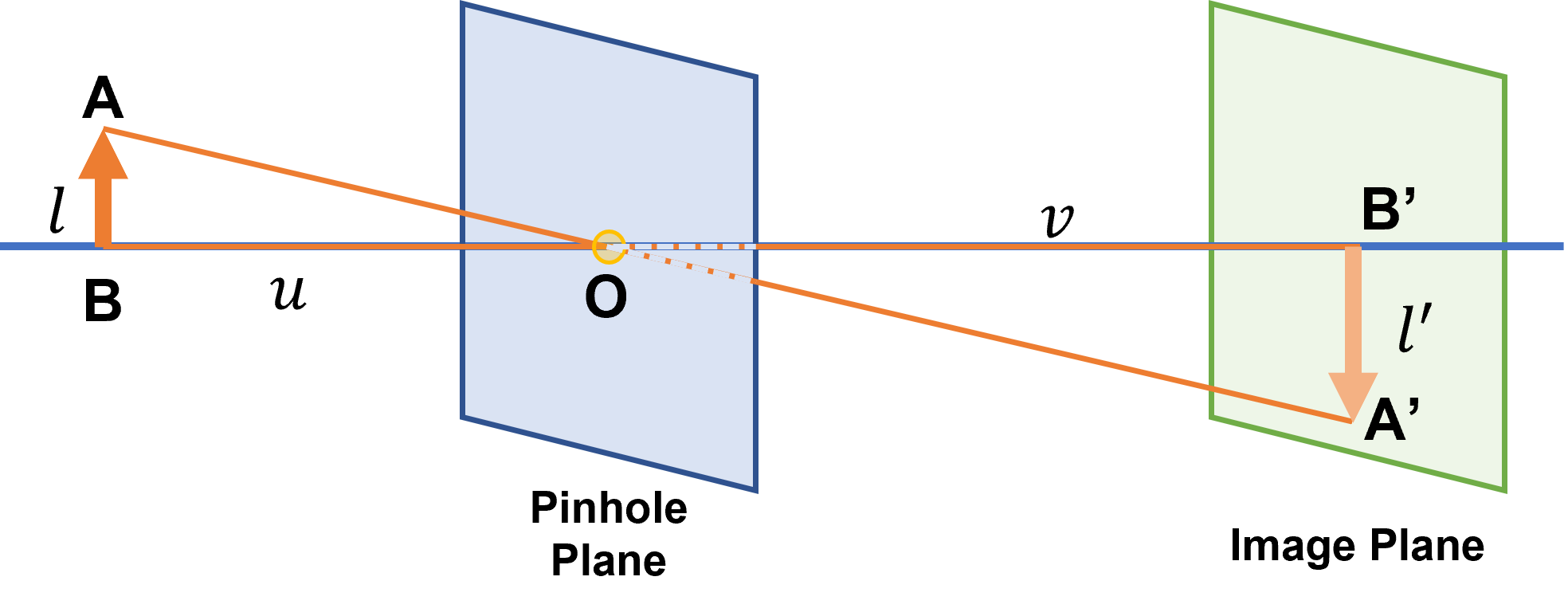 在现实世界中有一个物体AB,大小为l,经过一个小孔O,在像平面上成像A’B’,大小为l’。物体AB到小孔O的距离(物距)为u,成像A’B’到小孔O的距离(像距)为v。显然,根据光沿直线传播的原理,△ABO和△A’B’O相似。所以,我们可以得到下式:
在现实世界中有一个物体AB,大小为l,经过一个小孔O,在像平面上成像A’B’,大小为l’。物体AB到小孔O的距离(物距)为u,成像A’B’到小孔O的距离(像距)为v。显然,根据光沿直线传播的原理,△ABO和△A’B’O相似。所以,我们可以得到下式:
基于上式,我们可以很容易得到成像大小l’与其它变量之间的关系,如下:
\[l'=\frac{lv}{u}\]可以看到,在其余变量不变的情况下,增大像距可以增大成像大小;减小物距也可以增大成像大小。这便是小孔成像的基本理论了。这里需要注意的是,对于小孔成像而言,不管如何移动,成像都是清晰的。换句话说,在小孔成像中,成像清晰度与否并不随着物距或者像距的改变而改变。成像清晰度由小孔的大小决定。小孔越小,其成像越清晰,但由于小孔变小,进光量减少,所以成像变暗。反之,小孔变大,成像变模糊,但由于进光量增加,成像变量。最后需要注意的是,在小孔成像中,其实是不存在“焦距”这个概念的。因为焦距是用来描述透镜的,是光学系统中衡量光的聚集或发散的度量方式,指平行光入射时从透镜光心到光聚集之焦点的距离。在小孔成像中,光线没有发生折射,自然也不会汇聚,所以不存在交点。只是说在针孔相机模型中,为了描述方便,会把小孔到成像平面的距离叫做焦距。
4.2 凸透镜成像
小孔成像模型(或者说针孔相机模型)是非常简化的模型。在实际应用中,为了增加进光量和改善成像光学性质,一般都不会是小孔,而是单片镜头或者多片镜头构成的镜头组。那么此时面对的就是凸透镜成像系统。在透镜成像系统中,平行入射的光经过折射,会最终汇聚于一点,这一点就是焦点,将其与透镜的中心相连,得到的就是焦距,如下所示。
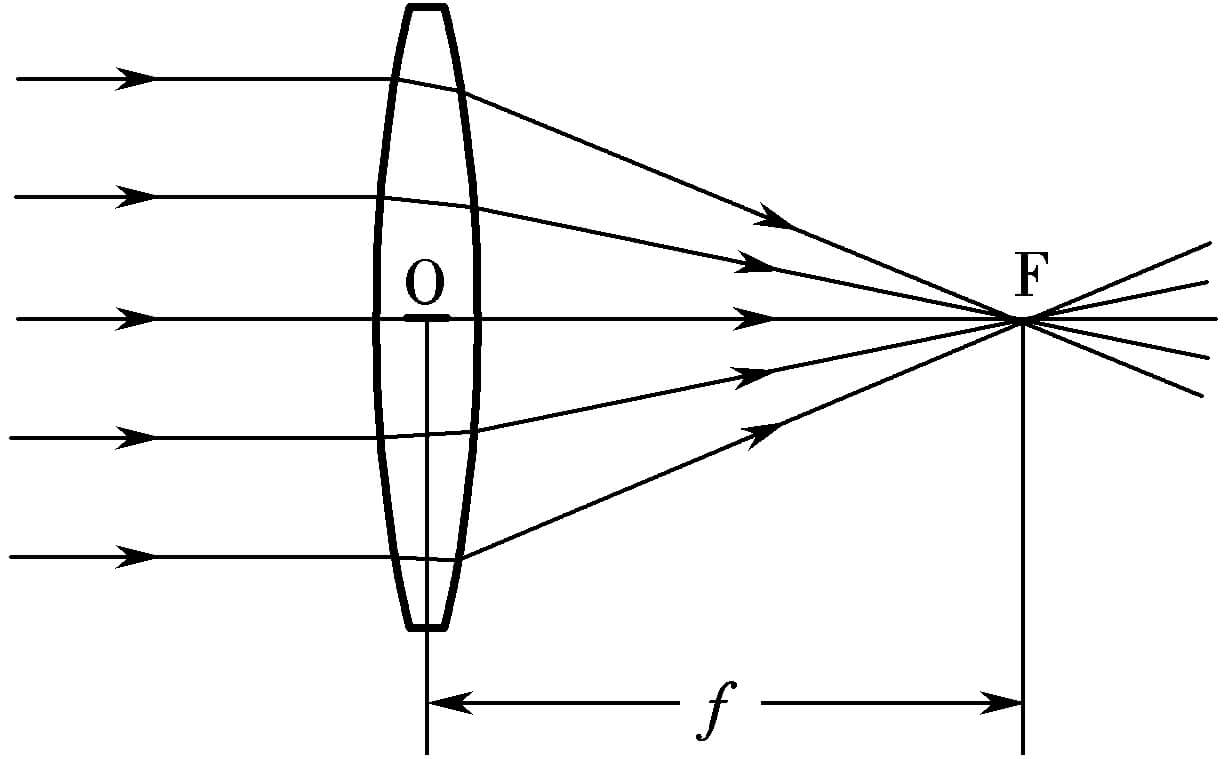 所以一个凸透镜成像系统的成像示意图如下。
所以一个凸透镜成像系统的成像示意图如下。
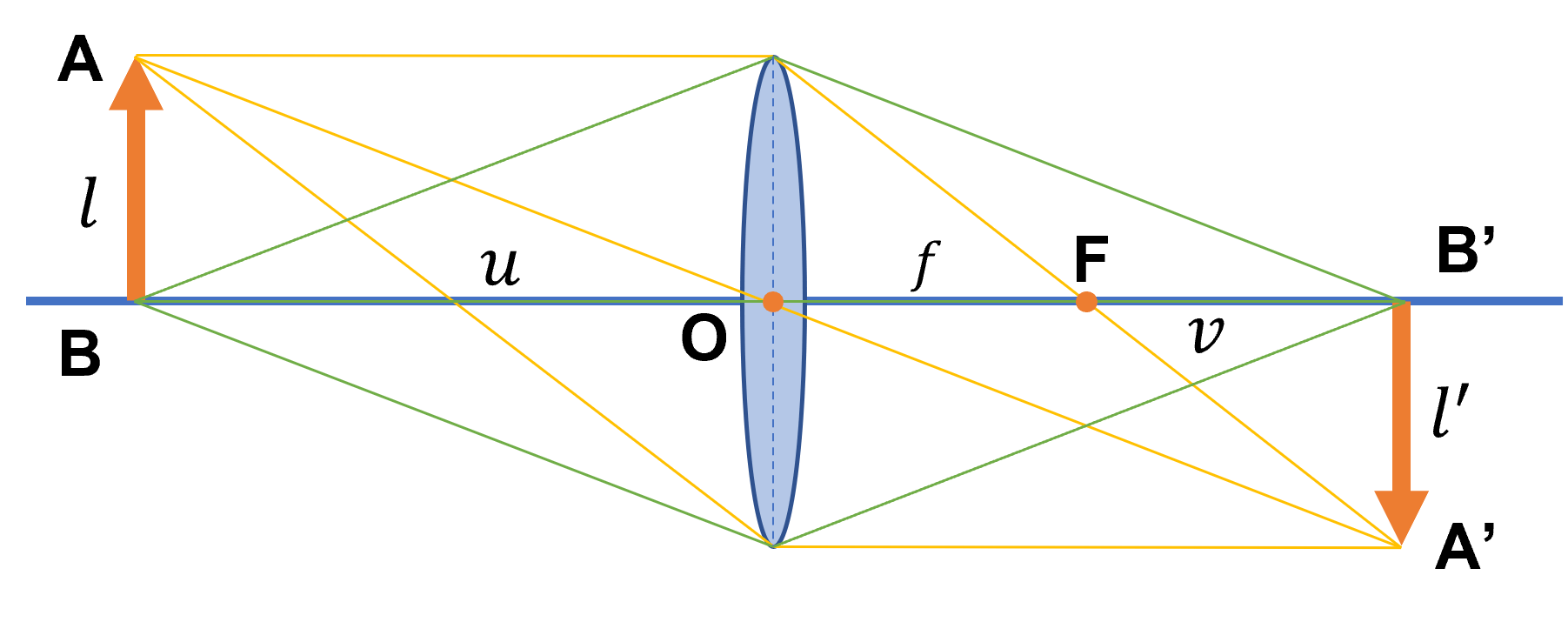 我们有一个长度为l的物体AB,经过透镜后成像为A’B’,长度为l’。物体距离镜头中心的距离(物距)还是为u,成像距离镜头中心的距离(像距)还是为v。而根据焦点的定义,是指平行于主光轴的光线经过折射以后与主光轴的焦点。所以,在图中,焦距f也就是焦点F到镜头中心O的距离。所以可以看到,对于凸透镜成像系统而言,像距不等于焦距。这是需要特别注意的,和我们在针孔相机模型中,认为像平面到小孔的距离(像距)就是焦距是不同的。基于几何信息,我们可以推导出凸透镜成像的公式。我们把上图简化一下,只保留一个点,如下:
我们有一个长度为l的物体AB,经过透镜后成像为A’B’,长度为l’。物体距离镜头中心的距离(物距)还是为u,成像距离镜头中心的距离(像距)还是为v。而根据焦点的定义,是指平行于主光轴的光线经过折射以后与主光轴的焦点。所以,在图中,焦距f也就是焦点F到镜头中心O的距离。所以可以看到,对于凸透镜成像系统而言,像距不等于焦距。这是需要特别注意的,和我们在针孔相机模型中,认为像平面到小孔的距离(像距)就是焦距是不同的。基于几何信息,我们可以推导出凸透镜成像的公式。我们把上图简化一下,只保留一个点,如下:
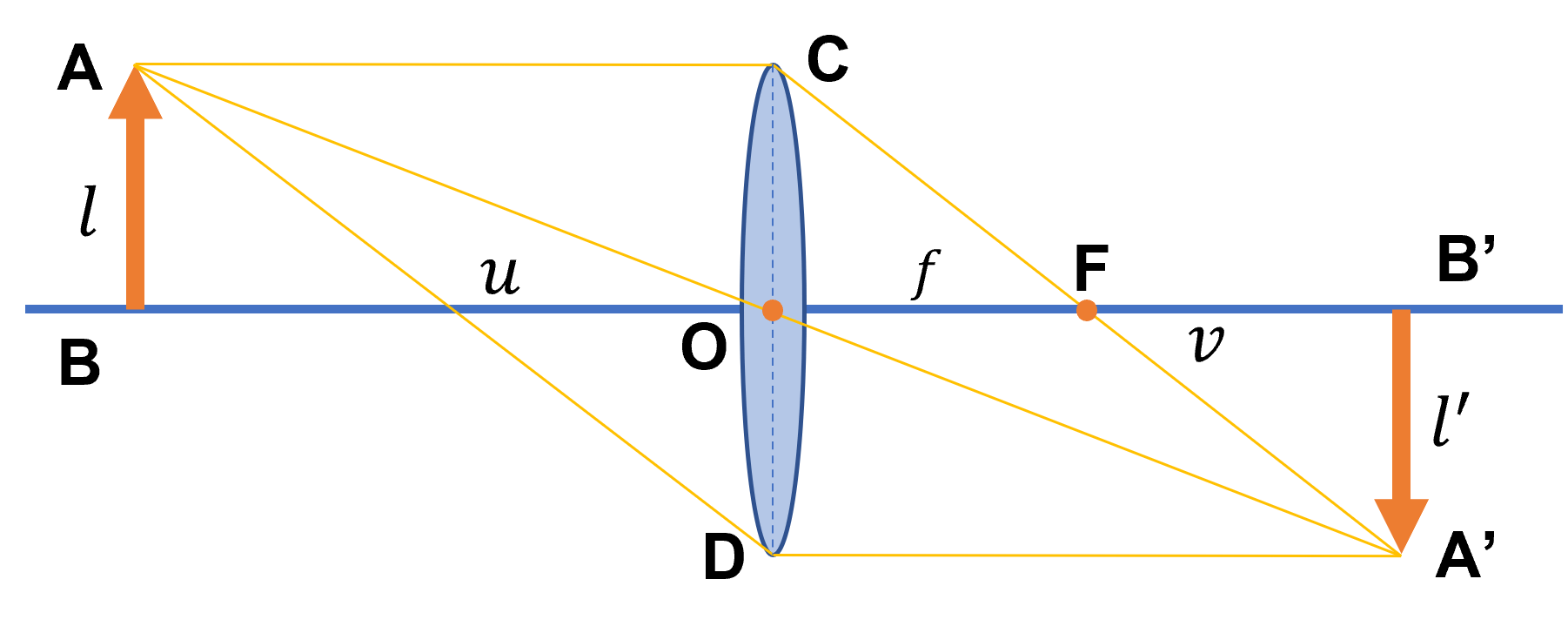 首先我们看△COB和△FB’A’,他们是相似的。所以有l:l’=f:(v-f)。同理,△ABO和△A’B’O相似,所以有l:l’=u:v。所以自然的,l:l’=f:(v-f)=u:v。整理一下有uv-uf=fv。等式两边都乘以1/fuv,就可以得到1/f-1/v=1/u。最终,就可以得到凸透镜成像公式:
首先我们看△COB和△FB’A’,他们是相似的。所以有l:l’=f:(v-f)。同理,△ABO和△A’B’O相似,所以有l:l’=u:v。所以自然的,l:l’=f:(v-f)=u:v。整理一下有uv-uf=fv。等式两边都乘以1/fuv,就可以得到1/f-1/v=1/u。最终,就可以得到凸透镜成像公式:
关于凸透镜成像的一些更多细节,可以参考初中物理光学的知识,这里就不再赘述。
4.3 关于景深
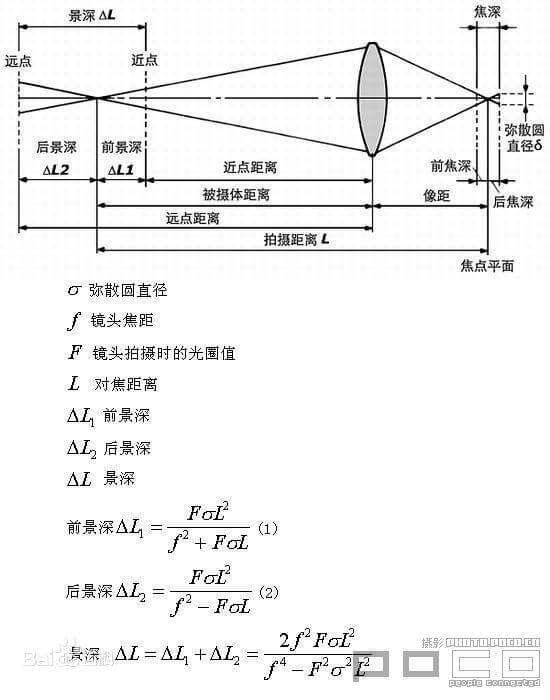
如果接触过摄影一定听说过景深这个概念。而且根据上面我们对凸透镜成像系统的分析。对于某个成像系统,其焦距和像距是固定的。那么如果要严格满足成像方程,其实是可以解算出唯一一个物距的(fv/(v+f))。只有在这个距离上的物体,在成像平面上才会清晰。但现实中,我们拍照不可能只有一个深度,但是我们拍出的不同距离的物体依然是清晰的。这就是镜头景深的相关知识。景深的定义是摄影机镜头能够取得清晰成像所测定的被摄物体前后距离范围。光圈、镜头、及焦平面到拍摄物的距离是影响景深的重要因素。换句话说,在镜头前方(焦点的前、后)有一段一定长度的空间,当被摄物体位于这段空间内时,其在底片上的成像位于同一个弥散圆之间。被摄体所在的这段空间的长度,就叫景深。换言之,在这段空间内的被摄体,其呈现在底片面的模糊度,都在容许弥散圆的限定范围内,这段空间的长度就是景深。如下图所示。
4.4 数字成像系统
在之前的这篇博客中,我们就介绍过了完整的数字成像的流程。这里,结合这篇微信推送,再简单介绍一下。
如下图所示,展示了数字成像系统的组成。图片来自上面的这篇微信推送,虽然画的有点丑,但基本意思表达清楚了。
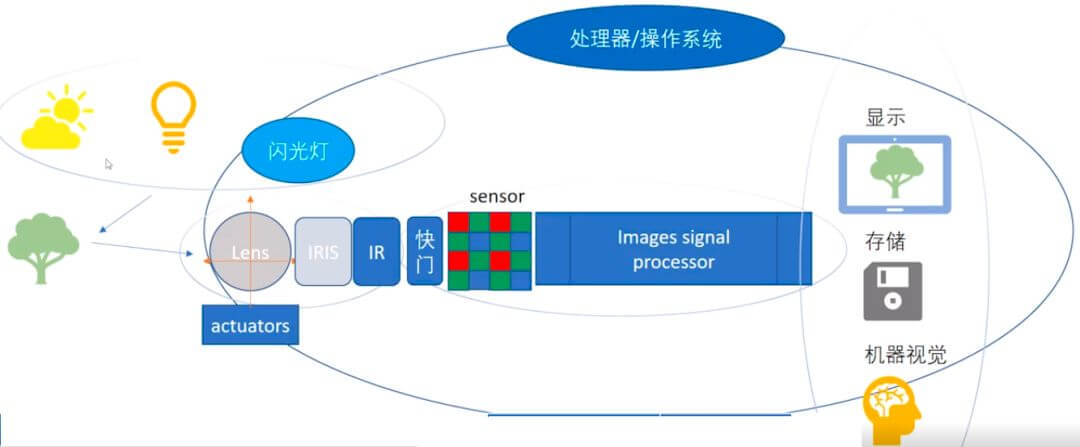 整个系统包含光源、被摄物体、传感器(镜头+感光元件)、显示器。
整个系统包含光源、被摄物体、传感器(镜头+感光元件)、显示器。
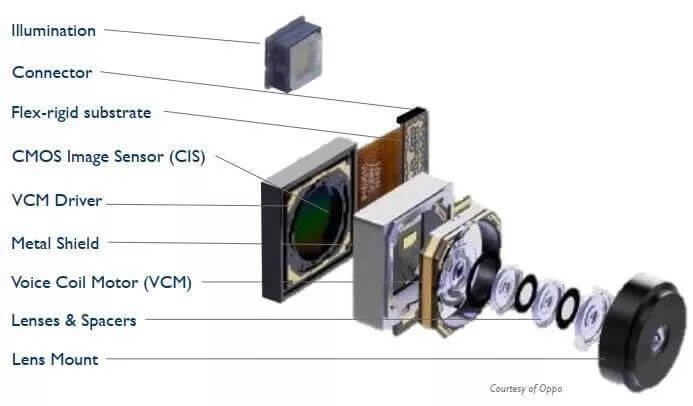
摄像头部分主要包含镜头、对焦马达、CMOS传感器等主要部分,如下图所示。
ISP是Image Signal Processor的缩写,全称是影像处理器。在相机成像的整个环节中,它负责接收感光元件(Sensor)的原始信号数据,并进行初级处理,包括线性纠正、噪点去除、坏点修补、颜色插值、白平衡校正、曝光校正等。ISP芯片能够在很大程度上决定手机相机最终的成像质量,通常它对图像质量的改善空间可达10%-15%。一个常规的ISP算法流程如下。
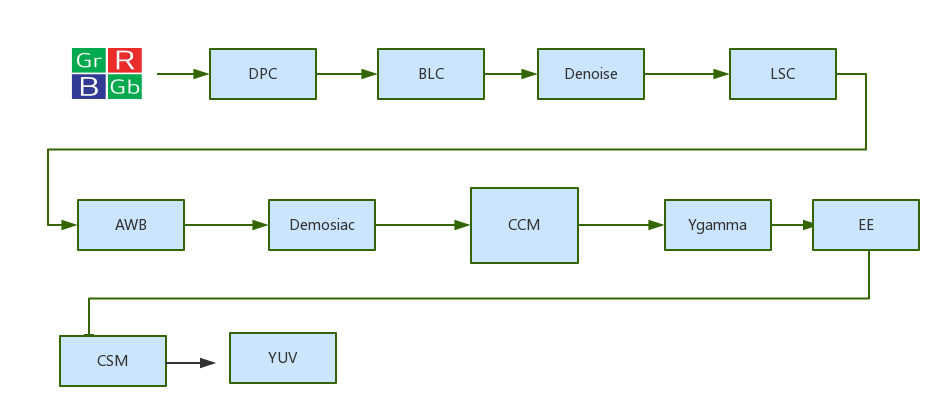 ISP Pipeline最关键的是“3A”算法,也就是AE(Auto Exposure)、AF(Auto Focus)和AWB(Auto White balance)。关于ISP处理的更详细内容可百度或Google,有很多进一步介绍。
ISP Pipeline最关键的是“3A”算法,也就是AE(Auto Exposure)、AF(Auto Focus)和AWB(Auto White balance)。关于ISP处理的更详细内容可百度或Google,有很多进一步介绍。
5.相机的对焦
在之前的这篇博客中我们提到了一个概念叫做“对焦”。简单来说就是手动调整对焦圈,使得画面最清晰。并且我们也明确了“对焦”和“变焦”是两个不同的概念。如果不清楚,看上面的这篇博客,就会明白了。在实际使用相机/手机的过程中,绝大部分情况下我们都不会手动对焦的——而是让设备自动对焦。目前我们SLAM里面用的绝大部分的相机传感器都是不支持自动对焦的(还是那句话,注意区分对焦和调焦),比如以前提到过的USB摄像头、D435i、树莓派相机、工业相机等(顺带补充一句,一般而言,普通的USB摄像头模块可以通过旋转镜头小孔周围齿轮状的旋钮改变焦距)。严格来说,带有自动调焦功能的设备有点超出单纯的摄像头范畴了。但一个完整的感知系统应该包含镜头+感光元件,而我们往往只关注感光元件的各种参数,而忽略了镜头。镜头也是影响最终成像质量非常重要的因素。要实现自动对焦,需要镜头+调焦马达+感光元件的多重配合,但设计起来相对复杂、成本也更高。所以从摄像头传感器的角度来说,其主要任务就是记录影像而已,并不会管记录影像的焦有没有对上。说了这么多,那么自动对焦是如何实现的呢?这一部分主要从自动对焦的原理以及硬件两个方面进行介绍。
5.1 自动对焦的核心思想
本部分主要参考这个网页。什么是对焦呢?从相机的成像过程来看,就是移动镜头改变镜头与图像传感器之间的距离(像距v)使其能满足前面提到的凸透镜成像公式的过程。满足成像公式并停留在这个状态就是对焦成功,这时传感器获取的图像就是最清晰的。如果像距v不满足成像公式,不管过大还是过小都会让传感器获取到模糊图像,差异越大图像越模糊。同时,由于有镜头有景深概念的存在,所以可以获取到不同深度的物体的清晰的图像。
所以到这里,其实自动对焦的核心思想就说完了,就是通过调整像距来获得拍摄物体最清晰的影像。清晰度是判断对焦是否成功的最重要指标。那么下面的问题就是,我怎么知道图像是最清晰的呢?
根据上面的描述,并结合凸透镜成像公式,可以看到,对于某个镜头,其焦距是固定的。如果说我们可以测得被摄物体距离我们的真实距离,也就是物距u已知,又已知焦距f,就可以根据成像公式直接求得像距v,然后我们再通过马达,将镜头调整到指定的距离即可。这是一种思路。另一种思路是,我没法测得物距u,其未知但固定。在这种情况下,我们可以尝试在一定范围内搜索像距,使得成像方程成立,可以求解得到最优的像距v。上面描述的这两种思路,其实分别就对应了自动对焦的两套方案:主动式对焦和被动式对焦。当然了,在一些高端或者专业设备上,这两种方案会同时使用的。
5.1.1 主动式对焦
主动式自动对焦方式的代表是激光对焦(TOF,Time of Flight)。主要原理是通过发射人眼不可见的红外光线到物体表面然后接收其反射回来的信号来测量对焦物体与手机的距离,然后控制马达推动镜头到对应的位置上完成对焦。这种技术还可以细分为I-TOF(间接TOF)和D-TOF(直接TOF)两种,核心区别在于深度测量的方式不同。D-TOF直接测量发射脉冲和接收脉冲之间的时间间隔,进而计算飞行时间,得到距离。而I-TOF大部分则是测量相位偏移,进而间接获得飞行时间。关于这两种方式的更详细对比,可参考这个网页,这里不多赘述。这种主动对焦方式主要运用在各类厂商的旗舰机型上,增加了TOF硬件模组会增加额外成本。优势是对焦速度快,缺点是容易受强光干扰。
5.1.2 被动式对焦
相比于主动式对焦直接测距求解像距v,被动式对焦则需要不断调整,找到 最清晰的图像所对应的像距。针对如何寻找最清晰的图像,现阶段主要有PDAF和CAF两种技术方案,PDAF对焦速度比CAF快一倍以上。
相位探测自动对焦PDAF
PDAF是目前手机上的主流对焦方法。全称是相位探测自动对焦(Phase Detection Auto Focus)。在图像传感器上不同区域规律分布有探测相位用的左右像素对(PD Pixel Pair),左PD像素和右PD像素的相位之差可以衡量对应区域场景的图像清晰度。当相位差为0时物体图像是清晰的,相位差不为0时图像是模糊的。在实际自动对焦时,PDAF软件模块会读取对焦区域内的PD像素对信息计算相位差,然后加上事先在模组厂校准的信息就可以计算出当前相位差要变为0需要设置的马达控制值(Defocus value),然后控制马达一步到位推动镜头到它认为清晰的位置上。
说到这里,你可能会想到佳能相机的一个宣传卖点“全像素双核对焦”,如下。
 他的核心原理也就是上面提到的相位探测,如下。
他的核心原理也就是上面提到的相位探测,如下。
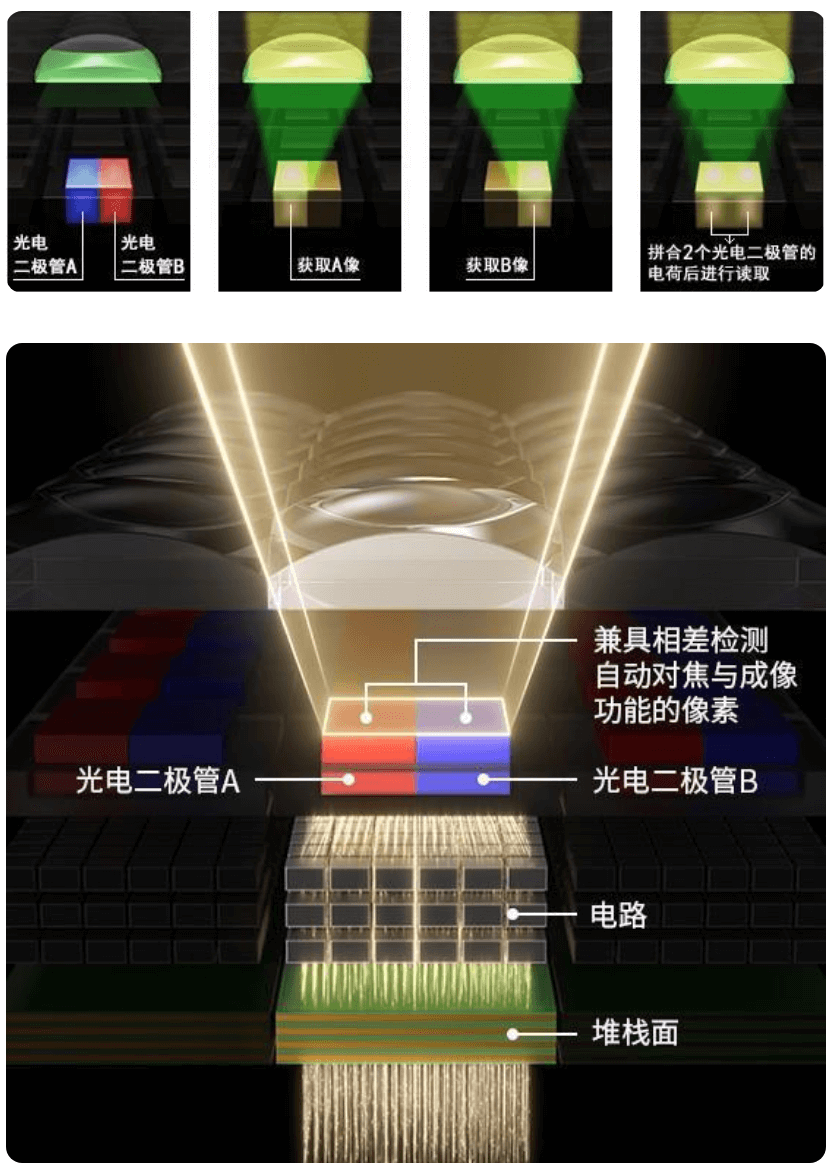 而他所谓的“全像素”则是指传感器上的每个像素都具备相位探测对焦能力,可以覆盖画面100%的区域。这一点对于佳能相机而言是一个重要卖点,官网甚至还专门开了个专题页进行介绍,感兴趣可以查看。
而他所谓的“全像素”则是指传感器上的每个像素都具备相位探测对焦能力,可以覆盖画面100%的区域。这一点对于佳能相机而言是一个重要卖点,官网甚至还专门开了个专题页进行介绍,感兴趣可以查看。
反差式自动对焦CAF
最基础的自动对焦方法之一就是反差式自动对焦(Constract AF,简称CAF),使用爬山算法。之所以叫反差式自动对焦,是因为这个方法是通过计算图像对焦框区域的反差或者对比度(Contrast)来衡量图像清晰度的。反差越大表示图像越清晰。爬山算法是指该算法寻找图像最清晰的镜头位置的方式类似爬山,所以这样命名。算法控制马达移动镜头朝一个方向移动时,图像对比度会出现逐渐增大然后变小的过程,类似爬山,这样才能确定山顶(对比度最高的点)的位置。其示意图如下:
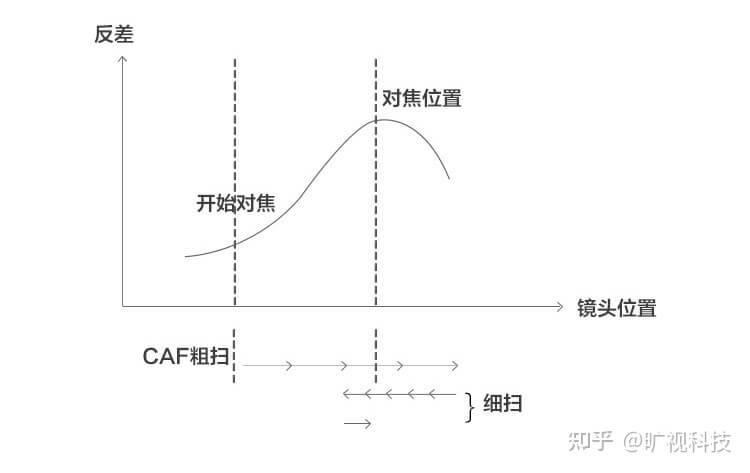 爬山算法包含两个过程,第一阶段叫粗扫(Coarse Search),第二阶段叫细扫(Fine Search)。粗扫的目的是完成爬山过程找到最高点(反差值最大的点)。这个阶段AF算法会让马达每次移动的跨度大一些,精细度不够高,只能大致知道最高点的范围。细扫的目的是准确找到最清晰的点,会在粗扫时发现的最高点附近以比较小的跨度或者步伐来搜索实际最清晰的点。
爬山算法包含两个过程,第一阶段叫粗扫(Coarse Search),第二阶段叫细扫(Fine Search)。粗扫的目的是完成爬山过程找到最高点(反差值最大的点)。这个阶段AF算法会让马达每次移动的跨度大一些,精细度不够高,只能大致知道最高点的范围。细扫的目的是准确找到最清晰的点,会在粗扫时发现的最高点附近以比较小的跨度或者步伐来搜索实际最清晰的点。
5.2 自动对焦的硬件
通过上面的描述,我们简单了解了自动对焦的基本原理。下面还有一个问题,当我算出来一个最佳像距以后,怎么来调整呢?答案就是本部分的内容,主要参考这个微信推送。如果简单来说,核心就是马达。通过马达的旋转,改变镜头的位置。当然,不同的技术路线诞生了不同种类的马达。
5.2.1 步进马达
自实时取景/视频拍摄变得普及后,STM(Stepping motor)步进马达就得到了非常广泛的应用。与传统的直流马达相比,STM步进马达具有响应速度快、控制精度高、架构简单易于小型化等优点。如下是佳能步进马达的示意图。
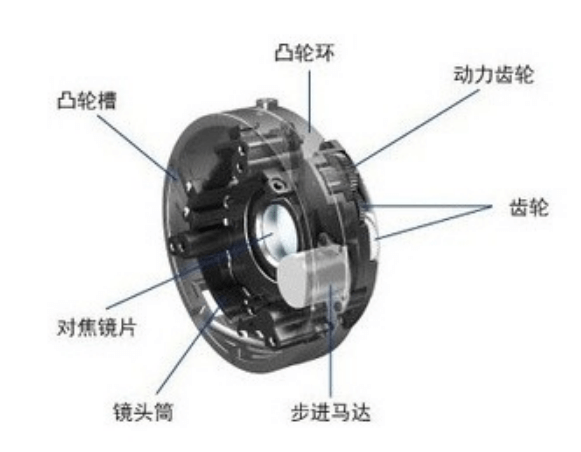
5.2.2 超声波马达
环形超声波马达(USM)是自单反时代传承下来的高性能马达,具有扭力大、噪音低等优点。需要注意的是,因为环形超声波马达的扭力大,所以与之搭配的通常也是重量级对焦镜组。所以使用环形超声波马达的镜头,并不一定比使用普通马达但对焦镜组轻的镜头对焦快。如下是超声波马达的示意。
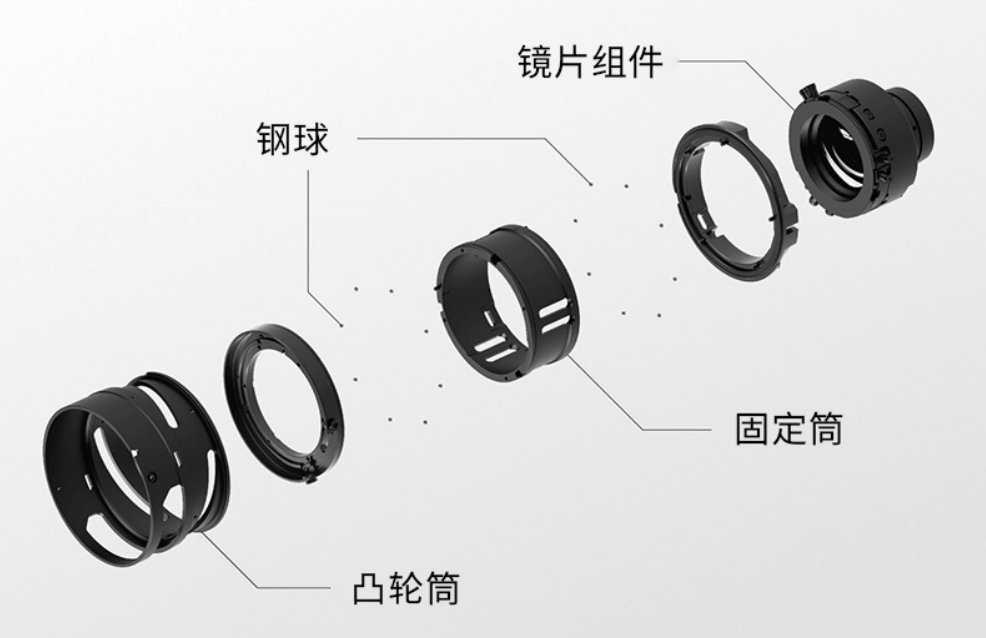 在微单时代,出于轻量、节能的使用需求,与光学设计上的优化(对焦镜组更小更轻),环形超声波马达的使用也随之减少。索尼、尼康、腾龙都在用新的高性能线性对焦马达来替代传统的环形超声波马达。
在微单时代,出于轻量、节能的使用需求,与光学设计上的优化(对焦镜组更小更轻),环形超声波马达的使用也随之减少。索尼、尼康、腾龙都在用新的高性能线性对焦马达来替代传统的环形超声波马达。
5.2.3 线性马达
线性马达应该是微单镜头的发展方向。和传统马达相比,它的效率更高、重量更轻,工作时也更平滑安静。线性马达是指将电能直接转换成直线运动机械能,中间无需转换机构的马达。如下是佳能线性马达的示意图。
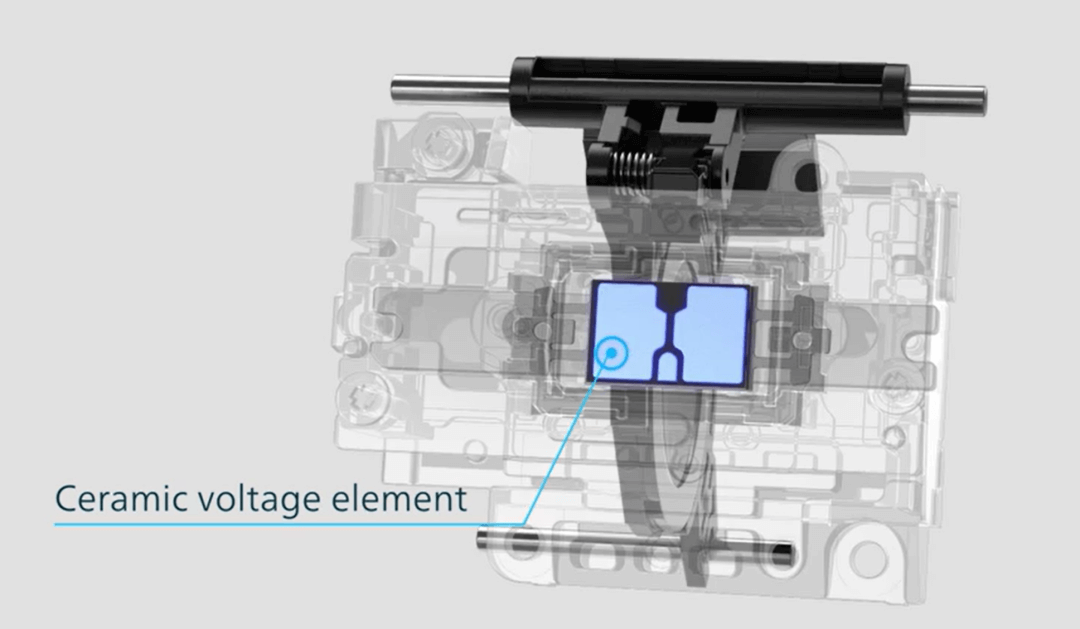
6.参考资料
- [1] https://mp.weixin.qq.com/s/Y-Y2x9vX7F_Jjcx15xdj7w
- [2] https://baijiahao.baidu.com/s?id=1715498655372954402
- [3] https://zhuanlan.zhihu.com/p/108509283
- [4] https://mp.weixin.qq.com/s/S1U84gMn5ZQ0UPNGK2jNSA
- [5] https://mp.weixin.qq.com/s/5K8mW6dvlGwXVh3AMZPm8w
- [6] https://zhuanlan.zhihu.com/p/44419544
- [7] https://zhuanlan.zhihu.com/p/24982662
- [8] https://zhuanlan.zhihu.com/p/24983091
- [9] https://www.zhihu.com/question/480932183/answer/2077451681
- [10] https://zhuanlan.zhihu.com/p/415774172
- [11] https://zhuanlan.zhihu.com/p/438455686
- [12] https://zhuanlan.zhihu.com/p/44419544
- [13] https://zhuanlan.zhihu.com/p/150925126
- [14] http://www.vommatec.com/list/57.html
- [15] https://www.zhihu.com/question/23636965
- [16] https://mp.weixin.qq.com/s/RNlyBoFdqbOlENto1udcNw
- [17] https://zhuanlan.zhihu.com/p/195055006
- [18] https://mp.weixin.qq.com/s/mjEqPdrkamKEIjdoLm4DCg
- [19] https://mp.weixin.qq.com/s/XdRweLBaX5Rkpfv2l8GnTg
本文作者原创,未经许可不得转载,谢谢配合
