在用TF实现更为复杂的卷积神经网络之前,有必要先对相关的概念和原理再学习一遍,这样之后实现时会更加顺畅。 本篇博客笔记参考黄文坚《TensorFlow实战》第五章以及网络上各种博客,在此就不一一列举了。
一、卷积神经网络简介
相比于传统人工设计的特征算子,如SIFT、HOG等,卷积神经网络提取的特征可以达到更好的效果。 同时它不需要将特征提取和分类训练两个过程分开,它在训练时就自动提取了最有效的特征(可以理解为我们在一开始初始化卷积核的时候那些特征提取算子确实是随机没有意义的,但随着训练的进行,卷积核的参数渐渐就能表达某一类特征了。这个过程是自动进行的,没有人工的参与。)。
CNN最大特点在于卷积的权值共享结构,可以大幅减少神经网络的参数量,防止过拟合的同时又降低了神经网络模型的复杂度。 卷积神经网络可以利用空间结构关系减少需要学习的参数量,从而提高反向传播算法的训练效率。 在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一个卷积操作只处理一小块图像,进行卷积变化后再传到后面的网络,每一层卷积(也可以说是滤波器)都会提取数据中最有效的特征。 这种方法可以提取到图像中最基础的特征,如不同方向的边或拐角,而后再进行组合和抽象形成更高阶的特征。 因此CNN可以应对各种情况,理论上具有对图像缩放、平移和旋转的不变性。
一般卷积神经网络由多个卷积层构成,每个卷积层中通常会进行如下几个操作。
- 1.图像通过多个不同的卷积核的滤波,并加偏置(bias),提出局部特征,每个卷积核会映射出一个新的2D图像。
- 2.对前面卷积核的滤波输出结果进行非线性的激活函数处理。这也就是前面博客中已经介绍过了。目前最常见的是用ReLU函数,以前Sigmoid用的比较多。
- 3.对激活函数的结果再进行池化操作(及降采样,如将2×2的图像降为1×1的图像),目前一般使用最大池化。这样便于保留最显著的特征,并提升模型的畸变容忍能力。
以上这三步就构成了最常见的卷积层,当然还可以加上一个LRN(Local Response Normalization,局部响应归一化)层。 LRN由Alex提出,他在论文中指出LRN层模仿了生物神经系统的“侧抑制”机制,对局部神经元的活动创建竞争环境,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。 LRN对ReLU这种没有上限边界的激活函数会比较有用,因为它会从附近的多个卷积核的响应(Response)中挑选出比较大的反馈,但不适合Sigmoid这种有固定边界并能抑制过大值的激活函数。 此外还有Batch Normalization等。
需要注意的是,一个卷积层中可以由多个不同的卷积核。可以理解为每一个卷积核都只能提取一种特定的图像特征。所以一般卷积层中会有很多卷积核对输入图像同时进行卷积,以此实现同时提取很多特征的需求。 例如之前MNIST例子中的第一层卷积层中就有32个卷积核。每一个卷积核都对应一个滤波后映射出的新图像,同一个新图像中的每一个像素都来自完全相同的卷积核,这就是卷积核的权值共享。 这样可以降低模型复杂度,减轻过拟合并降低计算量。
一个简单的例子,如果输入图像尺寸是1000×1000像素,且为单通道灰度图像。那么输入就有100万个像素点。如果连接一个相同大小的隐层(100万个隐含节点),那么就将产生一万亿个连接,对应一万亿个权值需要训练。 这显然是十分可怕的。因此必须要减少训练的权值数量,一是降低计算复杂度,二是过多的连接会导致严重的过拟合,减少连接数可提升模型的泛化性。
之所以可以进行“权值共享”是因为图像在空间上是有组织结构的,每个像素点在空间上和周围的像素点实际是有紧密联系的,但和太遥远的像素点就不一定有什么关联了。 这就是卷积概念的前身“视觉感受野”,每个感受野只接受一小块区域的信号。这一小块区域内的像素是互相关联的,每一个神经元不需要接收全部像素点的信息,只需要接收局部的像素点作为输入,而后将所有这些神经元收到的局部信息综合起来就可以得到全局的信息。 这样就可以将之前的全连接的模式修改为局部连接。之前隐层的每个隐含节点都和全部像素连接,现在只需要将每个隐含节点连接到局部的像素点即可。 假设局部感受野大小是10×10,即每个隐含节点只与10×10个像素点相连,那么现在只需要10×10×100万=1亿个连接,比之前小了1万倍。
通过局部连接(Local Connect),将连接数降低了1万倍。但仍然偏多,需要继续降低参数量。现在每个隐含层每个节点都与10×10的像素相连,每个节点有100个参数。 假设局部连接方式是卷积操作,即默认每个隐含节点的参数都完全一样,那么我们的参数就不再是1亿,而是100。 不论图像多大,都是这10×10=100个参数,即卷积核尺寸,这就是卷积对缩小参数量的贡献。 我们不再需要担心有多少节点或图片有多大,参数量只跟卷积核大小有关,这就是所谓的权值共享。 之所以可以共享,基础就是前面说的图像的空间上的相关性。 如果我们只有一个卷积核,就只能提取一种卷积核滤波的结果,即只能提取一种图片特征,这不是我们期望的结果。 好在图像中最基本的特征很少,我们可以增加卷积核的数量来多提取一些特征。 图像中的基本特征无非是点和边,无论多么复杂的图像都是由点和边组合而成的。 因此只要我们提供的卷积核数量足够多,能提取出各种方向的边或各种形态的点,就可以让卷积层抽象出有效而丰富的高阶特征。 每一个卷积核滤波得到的图像就是一类特征的映射,即一个Feature Map。 一般来说,使用100个卷积核放在第一个卷积层就已经很充足了。
因此,依靠卷积,我们可以高效地训练局部连接的神经网络了。卷积的好处是,不管图片尺寸如何,我们需要训练的权值数量只跟卷积核大小、卷积核数量有关。 我们可以用非常少的参数量处理任意大小的图片。每一个卷积层提取的特征,在后面的层中都会抽象组合成更高阶的特征。 而且多层抽象的卷积网络表达能力很强,效率更高,相比只使用一个隐层提取全部高阶特征,反而可以节省大量的参数。 但需要注意的是,虽然训练的参数量下降了,但隐含节点的个数并没有下降,它只与卷积的步长有关。 如果步长为1,那么隐含节点的数量和输入的图像像素数量一致;如果步长为5,那么每5×5的像素才需要一个隐含节点,那么数量就是输入像素数量的1/25。
总结一下就是,卷积神经网络的要点就是局部连接(Local Connection)、权值共享(Weight Sharing)和池化层(Pooling)中的降采样(Down-Sampling)。 其中局部连接和权值共享降低了参数量,使训练复杂度大大下降,并减轻了过拟合。 同时权值共享还赋予了卷积网络对平移的容忍性,而池化层降采样则进一步降低了输出参数量,并赋予模型对轻度形变的容忍性,提高了模型的泛化能力。 卷积神经网络相比传统的机器学习算法,无须手工提取特征,也不需要使用诸如SIFT之类的特征提取算法,可以在训练中自动完成特征的提取和抽象,并同时进行模式分类,大大降低了应用图像识别的难度。 相比于一般的神经网络,CNN在结构上和图片的空间结构更为贴近,都是2D的有联系的结构,并且CNN的卷积连接方式和人的视觉神经处理光信号的方式类似。
二、LeNet5简介
大名鼎鼎的LeNet5诞生于1994年,是最早的深层卷积神经网络之一,并推动了深度学习的发展。它的结构如图所示。
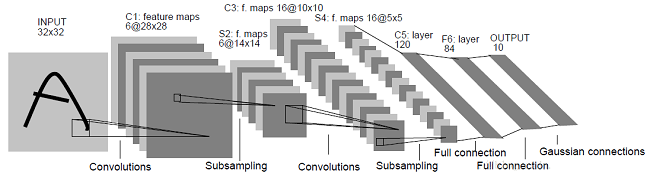 LeNet5的诸多特性现在依然在CNN中使用,可以说LeNet5奠定了现代卷积神经网络的基石。它的输入图像为32×32的灰度值图像,后面有三个卷积层、一个全连接层和一个高斯连接层。
它的第一个卷积层C1中包含6个卷积核,卷积核尺寸为5×5,即共(5×5+1)×6=156个参数。括号中的1代表一个偏置(bias)。
后面是一个2×2的平均池化层S2,用来进行降采样。
再之后是一个Sigmoid激活函数用来进行非线性处理。
而后是第二个卷积层C3,卷积核大小同样为5×5。这里使用了16个卷积核,对应16个Feature Map。
需要注意的是这里的16个Feature Map并不是全部连接到前面的6个Feature Map的输出的,有些只连接了其中的几个Feature Map,这样增加了模型的多样性。
下面的第二个池化层S4和第一个池化层S2一致,都是2×2的降采样。
接下来的第三个卷积层C5有120个卷积核,卷积大小同样为5×5。
因为输入图像大小刚好也是5×5,因此构成了全连接,也可以算作全连接层。
F6层是一个全连接层,拥有84个隐含节点,激活函数为Sigmoid。
LeNet5最后一层由欧式径向基函数(RBF)单元组成,输出最后的分类结果。
更多关于LeNet5的内容可以参考原版论文:Gradient-based learning applied to document recognition
LeNet5的诸多特性现在依然在CNN中使用,可以说LeNet5奠定了现代卷积神经网络的基石。它的输入图像为32×32的灰度值图像,后面有三个卷积层、一个全连接层和一个高斯连接层。
它的第一个卷积层C1中包含6个卷积核,卷积核尺寸为5×5,即共(5×5+1)×6=156个参数。括号中的1代表一个偏置(bias)。
后面是一个2×2的平均池化层S2,用来进行降采样。
再之后是一个Sigmoid激活函数用来进行非线性处理。
而后是第二个卷积层C3,卷积核大小同样为5×5。这里使用了16个卷积核,对应16个Feature Map。
需要注意的是这里的16个Feature Map并不是全部连接到前面的6个Feature Map的输出的,有些只连接了其中的几个Feature Map,这样增加了模型的多样性。
下面的第二个池化层S4和第一个池化层S2一致,都是2×2的降采样。
接下来的第三个卷积层C5有120个卷积核,卷积大小同样为5×5。
因为输入图像大小刚好也是5×5,因此构成了全连接,也可以算作全连接层。
F6层是一个全连接层,拥有84个隐含节点,激活函数为Sigmoid。
LeNet5最后一层由欧式径向基函数(RBF)单元组成,输出最后的分类结果。
更多关于LeNet5的内容可以参考原版论文:Gradient-based learning applied to document recognition
本文作者原创,未经许可不得转载,谢谢配合
