最近在做实验的时候由于一些需求,需要统计卫星视频各帧之间的影像重叠度,基于重叠度做进一步的分析。因此需要自己写代码实现重叠度的计算。 一开始没有什么思路,想着通过像素对比来实现,但后来觉得太不靠谱所以放弃了。在网上找了点资料,然后结合实际,想了一种基于影像重采样的方法。
1.算法思路
首先对两张影像进行特征提取,找到对应的同名点对。然后基于同名点对计算两张影像间的变换关系,可以是仿射(Affine)也可以是单应(Homography)。然后基于获得的变换关系对影像进行重采,得到重采后的新影像。统计新影像中纯黑像素(灰度值为0)的像素个数,再除以影像总像素数,即可获得不重叠部分的百分比,再减一下即可。整个流程如下示意图所示。

2.代码实现
整体代码实现流程和之前的视频稳像以及基于单应矩阵的相片纠正几乎差不多,只是在最后加了统计纯黑像素个数以及计算百分比的代码。
# coding=utf-8
import cv2
import numpy as np
import os
def findAllFiles(root_dir, filter):
print("Finding files ends with \'" + filter + "\' ...")
separator = os.path.sep
paths = []
names = []
files = []
# 遍历
for parent, dirname, filenames in os.walk(root_dir):
for filename in filenames:
if filename.endswith(filter):
paths.append(parent + separator)
names.append(filename)
for i in range(paths.__len__()):
files.append(paths[i] + names[i])
print (names.__len__().__str__() + " files have been found.")
paths.sort()
names.sort()
files.sort()
return paths, names, files
def getSURFkps(img):
surf = cv2.xfeatures2d_SURF.create(hessianThreshold=2000)
kp, des = cv2.xfeatures2d_SURF.detectAndCompute(surf, img, None)
return kp, des
def matchSURFkps(kp1, des1, kp2, des2):
good_matches = []
good_kps1 = []
good_kps2 = []
good_out = []
good_out_kp1 = []
good_out_kp2 = []
# FLANN parameters
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50) # or pass empty dictionary
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
# 筛选
for i, (m, n) in enumerate(matches):
if m.distance < 0.5 * n.distance:
good_matches.append(matches[i])
good_kps1.append(kp1[matches[i][0].queryIdx])
good_kps2.append(kp2[matches[i][0].trainIdx])
print("good matches:" + good_matches.__len__().__str__())
for i in range(good_kps1.__len__()):
good_out_kp1.append([good_kps1[i].pt[0], good_kps1[i].pt[1]])
good_out_kp2.append([good_kps2[i].pt[0], good_kps2[i].pt[1]])
good_out.append([good_kps1[i].pt[0], good_kps1[i].pt[1], good_kps2[i].pt[0], good_kps2[i].pt[1]])
return good_out_kp1, good_out_kp2, good_out
if __name__ == '__main__':
_, names, img_files = findAllFiles(".", ".jpg")
img_w = cv2.imread(img_files[0], cv2.IMREAD_GRAYSCALE).shape[1]
img_h = cv2.imread(img_files[0], cv2.IMREAD_GRAYSCALE).shape[0]
total_pixel = img_w * img_h
kp1s = []
kp2s = []
matches = []
nums = []
blank_percents = []
overlay_percents = []
# 新建文本文件用于记录结果
txt_file = open("overlay_records.txt", "a+")
txt_file.write(
"Kp1\tKp2\tMatches\tNums\tTotal\tBlank Percent\tOverlay Percent\n")
txt_file.close()
for i in range(img_files.__len__() - 1):
print i + 2, "/", img_files.__len__()
# 读取影像
img1 = cv2.imread(img_files[i])
img2 = cv2.imread(img_files[i + 1])
# 提取特征点
kp1, des1 = getSURFkps(img1)
kp2, des2 = getSURFkps(img2)
kp1s.append(kp1.__len__())
kp2s.append(kp2.__len__())
print "kp1:", kp1.__len__(), "kp2:", kp2.__len__()
# 特征匹配
g1, g2, match = matchSURFkps(kp1, des1, kp2, des2)
matches.append(match.__len__())
# 计算单应矩阵
h, res = cv2.findHomography(np.array(g2), np.array(g1))
print h
# 基于单应矩阵重采
dst = cv2.warpPerspective(img2, h, (img1.shape[1], img1.shape[0]))
# 统计灰度为0像素个数
num = np.sum(cv2.cvtColor(dst, cv2.COLOR_BGR2GRAY) == 0)
nums.append(num)
# 计算百分比
blank_percent = (num * 1.0 / total_pixel) * 100
over_percent = 100 - (num * 1.0 / total_pixel) * 100
blank_percents.append(blank_percent)
overlay_percents.append(over_percent)
print "blank pixel num:", num
print "total pixel num:", total_pixel
print "blank percent:", blank_percent, "%"
print "overlay percent:", over_percent, "%"
print "-" * 50
# 写入文件
txt_file = open("overlay_records.txt", "a+")
txt_file.write(
kp1s[i].__str__() + "\t" + kp2s[i].__str__() + "\t" +
matches[i].__str__() + "\t" +
nums[i].__str__() + "\t" +
total_pixel.__str__() + "\t" +
blank_percents[i].__str__() + "\t" +
overlay_percents[i].__str__() + "\n")
txt_file.close()
在代码中写成了方便批量处理的形式。完整代码和测试数据放在了Github上,点击查看,欢迎Fork或Star。
3.测试结果
最终在970帧卫星视频数据中运行的结果截图如下。
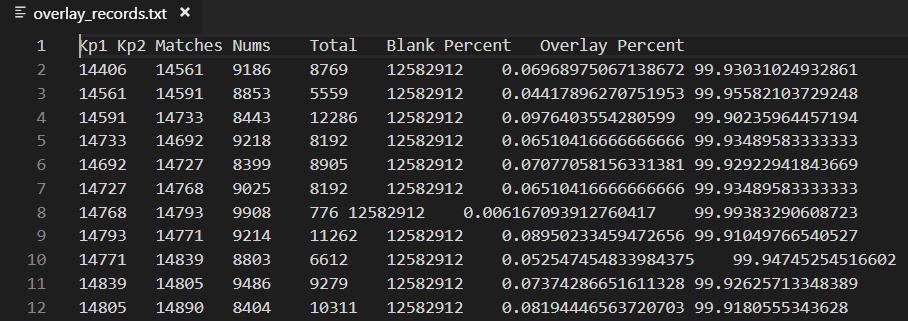 可以看到比较好的统计了想要的结果。
可以看到比较好的统计了想要的结果。
本文作者原创,未经许可不得转载,谢谢配合
