本篇博客最初来源于之前参加的Megvii计算摄影训练营最后的作业。我们在NBNet的基础上,修改了模型的一些输入输出,在自己的数据上进行训练,并实现了影像的降噪。NBNet论文见这里,代码见这里。所以这里主要介绍NBNet训练与使用流程相关的内容,不涉及论文与原理,只讨论代码层面的内容。最终目标是实现利用NBNet在自己的数据上进行训练并且测试,形成一套比较方便、通用的流程,这样之后就可以轻松地扩展到其它应用。
为了方便使用,我们也将代码公开到了Github上,感兴趣可以查看,欢迎Star或Fork。
1.模型训练
对于NBNet的模型训练,我们划分成了三个阶段,如下所示。
 分别是训练数据的准备(涉及将影像分块等操作)、验证数据的转换(涉及将影像块转换成
分别是训练数据的准备(涉及将影像分块等操作)、验证数据的转换(涉及将影像块转换成mat文件等操作)以及最后的模型训练。下面会对每一步进行进一步介绍。
为了方便使用,我们把训练过程中需要用到的参数都写到了参数文件里,方便快速修改,如下图所示。
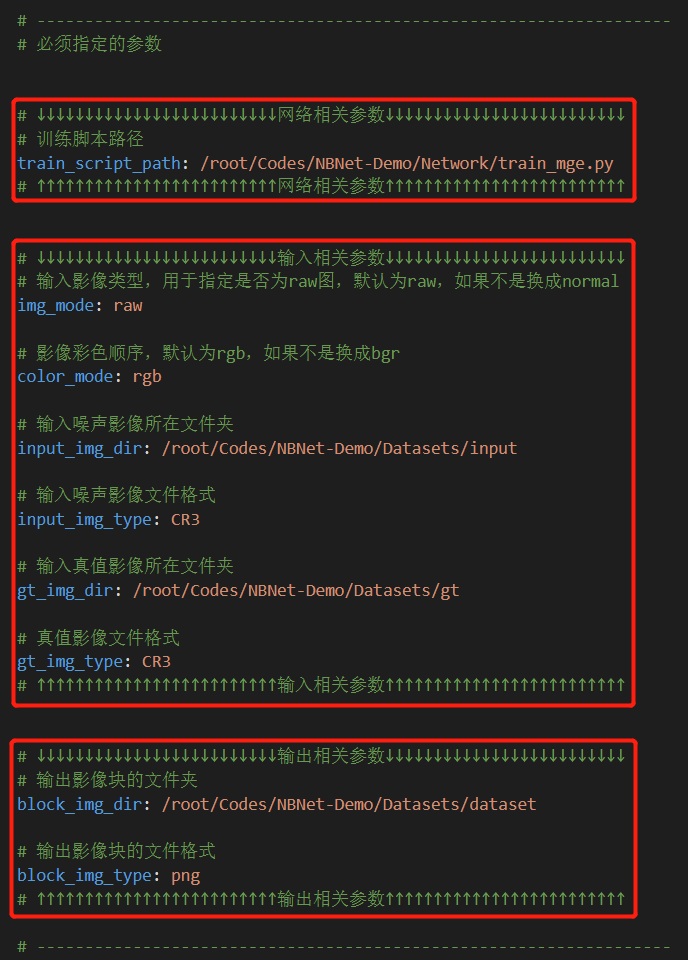 在必须指定的参数中,主要包含训练脚本相关参数(训练脚本路径
在必须指定的参数中,主要包含训练脚本相关参数(训练脚本路径train_script_path)、训练输入相关参数(噪声影像文件夹input_img_dir、噪声影像文件类型input_img_type、真值影像文件夹gt_img_dir、真值影像文件类型gt_img_type、输入影像格式img_mode和输入影像彩色顺序color_mode)、训练输出相关参数(分割后影像块的输出文件夹block_img_dir、影像块的文件格式block_img_type)。更完整、详细参数见Github项目的training.yml。
步骤1:训练数据准备
对应Github项目中step1_training_gen_blocks.py脚本,它的目的就是将多张大的(如6000×4000)影像(可以是raw数据也可以是普通jpg)拆分成指定大小的影像块并输出,形成训练数据。进一步,在这一步中,我们会进行如下操作:
- (1) 在指定文件夹中寻找符合条件的所有影像
- (2) 遍历影像,每张都进行裁块、增强和输出
- a. 读取影像与真值
- b. 随机采样
- c. 样本增强
- d. 输出样本(训练数据+验证数据+索引文件)
- e. 输出随机采样块的覆盖范围
这里有一点需要说的是,对于每张影像,我们并非按照传统方法打格网然后进行裁块,而是采用随机采样的方法,核心思想如下图所示。
 简单来说就是对于每张影像,我们随机选取某一个位置,并按照指定大小读取影像内容,以此作为一个影像块。这样的好处是,对于一张影像,我们可以随机采样任意多数量的影像块,可以在一定程度上增加样本数量。同时,为了进一步增加样本数量,我们也采用了翻转的增强手段,具体包括水平翻转、竖直翻转、水平+竖直翻转。如下图所示,我们对一张6000×4000影像以256×256的大小进行裁块,一共裁1500张,增强之后就是6000张。
简单来说就是对于每张影像,我们随机选取某一个位置,并按照指定大小读取影像内容,以此作为一个影像块。这样的好处是,对于一张影像,我们可以随机采样任意多数量的影像块,可以在一定程度上增加样本数量。同时,为了进一步增加样本数量,我们也采用了翻转的增强手段,具体包括水平翻转、竖直翻转、水平+竖直翻转。如下图所示,我们对一张6000×4000影像以256×256的大小进行裁块,一共裁1500张,增强之后就是6000张。
 上图中绿色框框表示训练数据,橙色框框表示验证数据。
上图中绿色框框表示训练数据,橙色框框表示验证数据。
步骤2:验证数据转换
对应Github项目中step2_training_gen_vali_mat.py,作用是将上一步裁剪得到的验证影像块数据转换成Matlab的mat格式文件。之所以这样做的原因是因为在SIDD中验证数据就是mat格式,所以NBNet的数据加载模块也是读取mat类型的数据。为了尽可能和他们一致,我们就也把我们自己的数据转换成mat了。但其实从真正实际应用角度来说,这一步是完全没有必要的。我们完全可以自己写一个Dataloder就可以了。
对于Matlab的mat文件的读写主要是通过scipy.io模块中的loadmat()、savemat()函数实现。在读写的时候都是以Python的dict进行传输的,如下是写好的工具函数。
def cvtMat2Imgs(mat_path, img_key_name):
imgs = []
img_mat = loadmat(mat_path)
img_data = img_mat[img_key_name]
for i in range(img_data.shape[0]):
imgs.append(img_data[i, :, :, :])
return imgs
def cvtMat2ImgsAndSave(mat_path, img_key_name, img_out_dir, img_type):
imgs = []
img_mat = loadmat(mat_path)
print(img_mat.keys())
img_data = img_mat[img_key_name]
for i in range(img_data.shape[0]):
imgs.append(img_data[i, :, :, :])
for i in range(len(imgs)):
cv2.imwrite(img_out_dir + "/" + str(i).zfill(5) + "." + img_type, imgs[i])
return imgs
完整版见Github项目的utilities.py脚本。
步骤3:开始训练
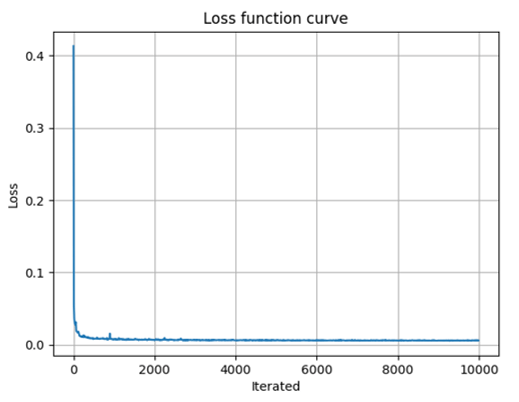
对应Github项目中的step3_training_start.py脚本,利用做好的数据集进行训练。模型训练好以后,会将模型参数以pkl格式保存,也会打印对应的log文件方便查看。需要注意的是整个网络使用的是旷视的天元MegEngine框架,所以如果要本地训练的话,记得先安装好对应环境。而且经过实际测试发现,在Windows下训练似乎会卡住、有问题,所以建议在Ubuntu下进行。如下图所示是我们训练的Loss曲线。
训练所有步骤
当然,为了使用方便,我们也专门编写了steps_training.py脚本,把上面三个步骤合并起来了,用户只需要修改training.yml中的对应参数,即可很方便地进行训练。
2.模型推理
模型训练结束以后,自然是要用这个模型进行推理,对于模型推理和测试,我们分为五个部分,如下图所示。
 主要包括测试数据的准备(影像分块)、数据类型转换(转换成
主要包括测试数据的准备(影像分块)、数据类型转换(转换成mat类型文件)、输入网络进行推理、结果合并、精度评价(如果有真值的话)。下面分别进行介绍。
类似的,为了方便,我们也将testing阶段用到的参数写在了参数文件里,如下图所示。
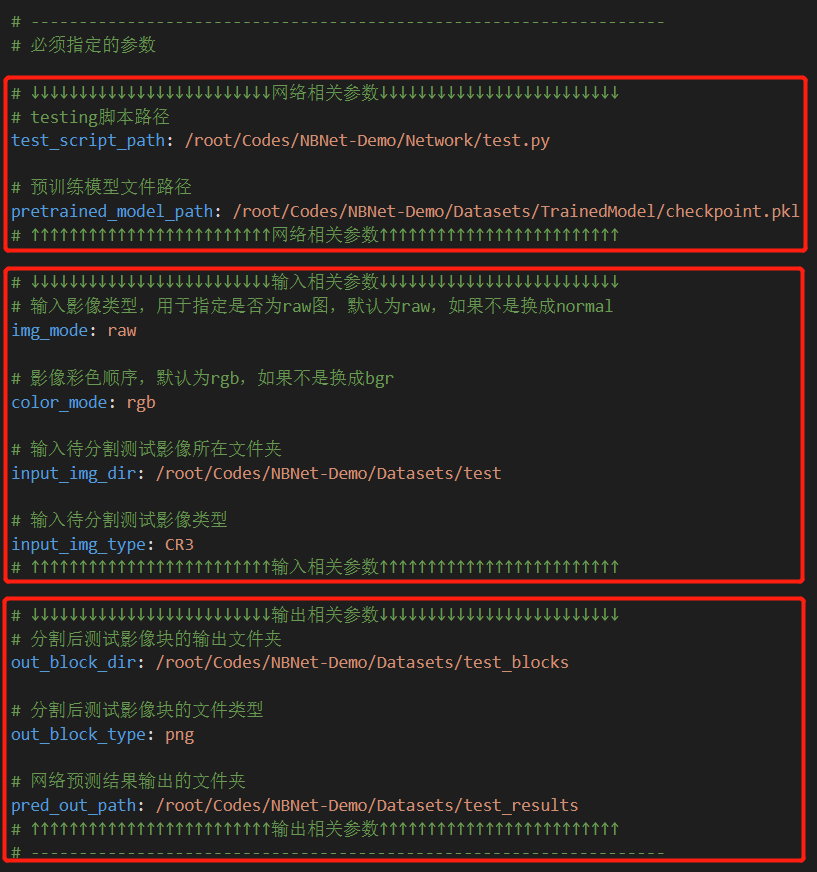 类似的,必须指定的参数也包含三个方面:模型相关参数(测试脚本路径
类似的,必须指定的参数也包含三个方面:模型相关参数(测试脚本路径test_script_path、训练好的模型参数pretrained_model_path)、网络输入相关参数(待测试影像所在文件夹input_img_type、待测试影像文件类型input_img_type、输入影像格式img_mode和输入影像彩色顺序color_mode)、网络输出相关参数(分割后影像块的输出文件夹out_block_dir、影像块文件类型out_block_type、网络处理结果输出文件夹pred_out_path)。完整参数可见Github项目中的testing.yml。
步骤1:测试数据准备
对应于Github项目的step4_testing_gen_blocks.py脚本,用于将待测试影像划分成多个影像块。与训练数据准备类似的,对于测试数据,我们同样需要把它划分成小块。这里值得一提的是我们的划分策略,我们也没有使用常规的打格网。我们允许影像块和块之间存在一定的重叠区域(我们把它叫做overlapping),如下图所示。
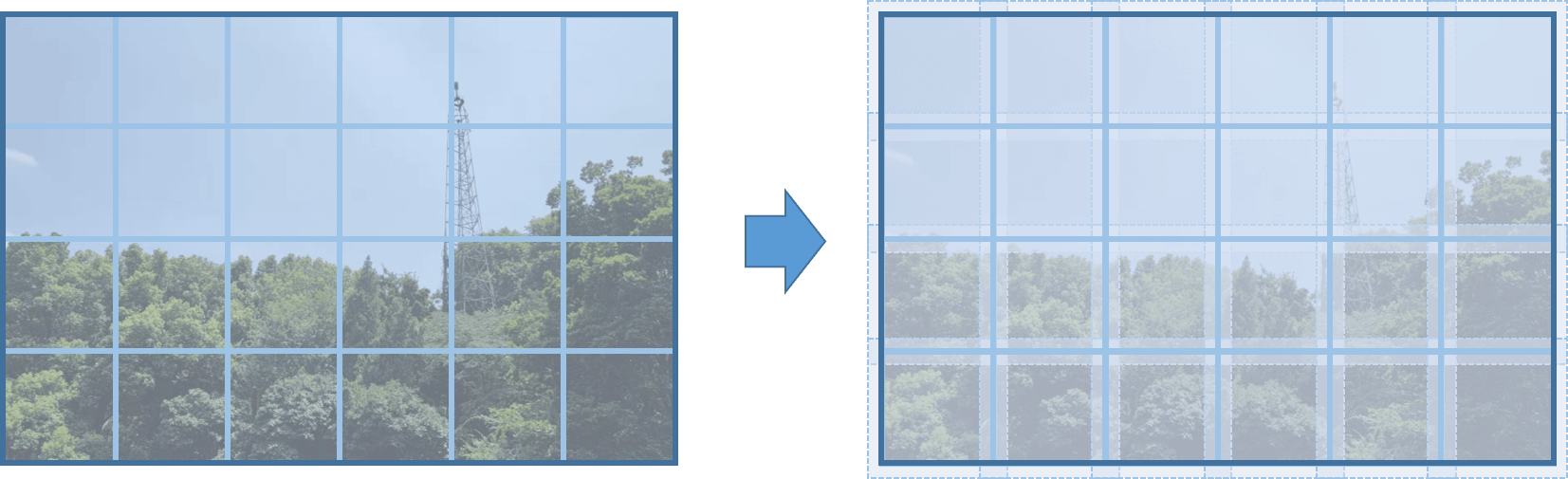 这样做的目的在于在一定程度上消除边界效应。简单来说就是如果影像块和块之间没有重叠,那么当某张影像块输入网络的时候,这个影像块的边缘部分由于缺乏周围布局的信息,最终估计的结果会受到影响。既然这样的话,我们就认为的将影像块边界外扩,这样原本是边界的部分也有了局部信息,在估计的时候就会好很多。最后,我们在合并影像块的时候,再把多出来的边界裁掉,就可以得到一个比较令人满意的效果了。可以比较有效的解决模型预测结果中影像块边缘部分因为缺乏局部信息而导致的差异/拼接缝问题。
这样做的目的在于在一定程度上消除边界效应。简单来说就是如果影像块和块之间没有重叠,那么当某张影像块输入网络的时候,这个影像块的边缘部分由于缺乏周围布局的信息,最终估计的结果会受到影响。既然这样的话,我们就认为的将影像块边界外扩,这样原本是边界的部分也有了局部信息,在估计的时候就会好很多。最后,我们在合并影像块的时候,再把多出来的边界裁掉,就可以得到一个比较令人满意的效果了。可以比较有效的解决模型预测结果中影像块边缘部分因为缺乏局部信息而导致的差异/拼接缝问题。
步骤2:测试数据类型转换
对应于Github项目的step5_testing_gen_mat.py,用于将生成好的影像块文件转换成Matlab的mat格式。原因和上面是类似的,只是为了保持一致才有的这一步,我们可以完全自己写一个DataLoader来把这一步消除掉。
步骤3:开始推理
对应于Github项目的step6_testing_start.py,将构造好的待测试数据输入网络进行推理,并输出预测结果。由于NBNet原本并没有输出影像的功能,所以我们在其基础上增加了一些代码,如下所示。
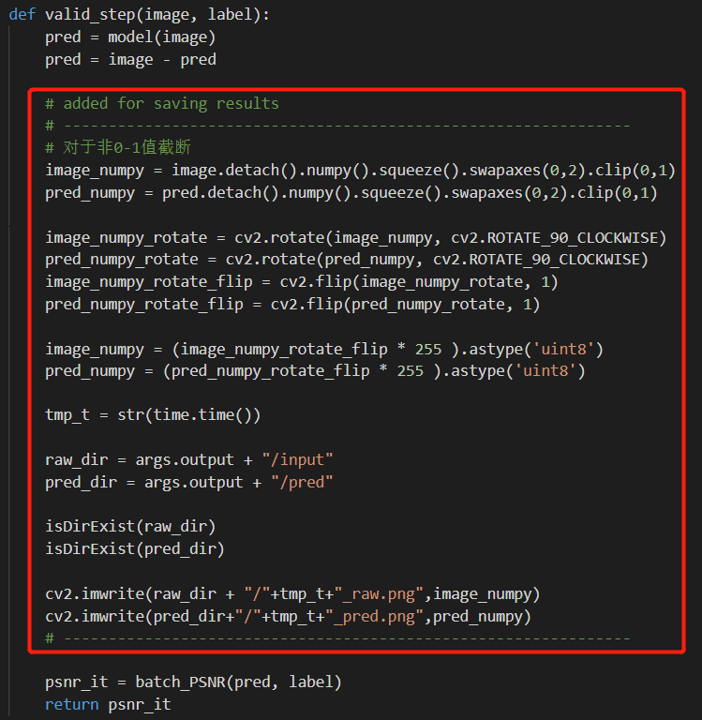
步骤4:结果合并
对应于Github项目的step7_testing_merge_blocks.py,主要目的是将影像块合并成一张大图。这里面没有什么特别复杂的内容,但是坐标的计算可能会绕一些,需要稍微推算一下,如下所示。
def mergeBlocksWithOverlapping(img_blocks, block_indices, block_param):
overlapping_img_height = block_param[16]
overlapping_img_width = block_param[17]
overlapping_img = np.zeros([overlapping_img_height, overlapping_img_width, 3], np.uint8)
padding_img_height = block_param[2]
padding_img_width = block_param[3]
padding_img = np.zeros([padding_img_height, padding_img_width, 3], np.uint8)
padding_top = block_param[8]
padding_bottom = block_param[9]
padding_left = block_param[10]
padding_right = block_param[11]
overlapping = block_param[18]
for i in range(len(img_blocks)):
start_x_overlap = block_indices[i][3]
start_y_overlap = block_indices[i][4]
end_x_overlap = block_indices[i][5]
end_y_overlap = block_indices[i][6]
start_x_padding = block_indices[i][7]
start_y_padding = block_indices[i][8]
end_x_padding = block_indices[i][9]
end_y_padding = block_indices[i][10]
block_overlap = img_blocks[i]
block_padding = img_blocks[i][overlapping:block_overlap.shape[0] - overlapping,
overlapping:block_overlap.shape[1] - overlapping, :]
# 对于重叠影像,直接贴过来(会有拼接缝,如果有更好的融合方法可以尝试)
overlapping_img[start_y_overlap:end_y_overlap, start_x_overlap:end_x_overlap, :] = block_overlap
# 对于非重叠影像,裁剪影像块之后再贴过来(无拼接缝)
padding_img[start_y_padding:end_y_padding, start_x_padding:end_x_padding, :] = block_padding
# 对于原始影像,直接在padding影像上裁剪即可
original_img = padding_img[padding_top:padding_img.shape[0] - padding_bottom,
padding_left:padding_img.shape[1] - padding_right, :]
return overlapping_img, padding_img, original_img
完整版见Github项目的utilities.py脚本。
步骤5:精度评价
对应Github项目中的step8_testing_evaluate.py脚本,用于计算预测结果与真值的差异。这一步是可选的。因为并不是每一个测试数据都有真值以供测试,如果没有真值的话,这一步就不用做了。如果有真值的话,分别输入真值影像、噪声影像以及预测结果就可以进行定量评价,选取的评价指标是MSE和PSNR。它们的详细介绍和计算方式可以参考这篇博客。
推理所有步骤
类似的,为了使用方便,我们也专门编写了steps_testing.py脚本,把上面五个步骤合并起来了,用户只需要修改testing.yml中的对应参数,即可很方便地进行测试。
3.总体测试与总结
当然,为了更加“偷懒”,我们也编写了steps_all.py,将steps_training.py脚本和steps_testing.py脚本进行了整合。用户只需要提前设置好training.yml和testing.yml中的参数,再执行steps_all.py,即可一行命令实现模型的训练和测试,十分方便。而且有了这样一套比较顺畅的批处理流程之后,就可以十分方便地验证其它一些想法。比如NBNet是针对去噪问题提出的,那么我们能不能用NBNet进行暗光增强呢?能不能同时既去噪又暗光增强呢?有了上面的批处理流程,这些问题其实都可以非常方便地回答,我们唯一要做的就是将训练和测试的数据内容更换一下即可,其它什么都不用修改,十分方便。
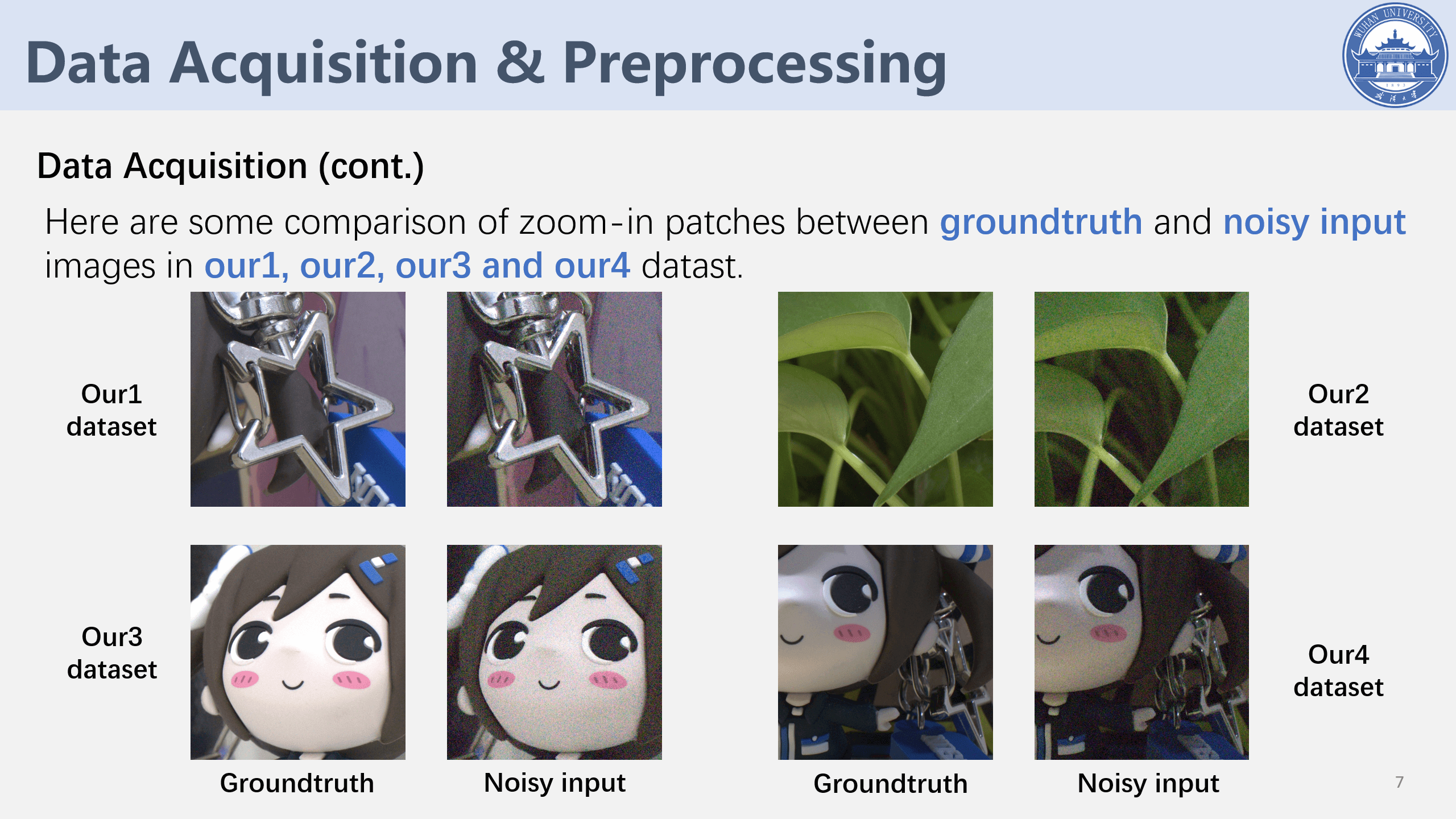
最后,这里也简单贴一些当时课程作业答辩PPT里的一些实验效果。





本文作者原创,未经许可不得转载,谢谢配合
