本篇博客是旷视CV Master训练营系列《基于神经网络的3D重建》专题的第三课《NeRF在场景重建中的应用》的相关笔记,课程视频可以点此查看。
1.本次课的主要内容


2.场景三维重建
2.1 传统COLMAP
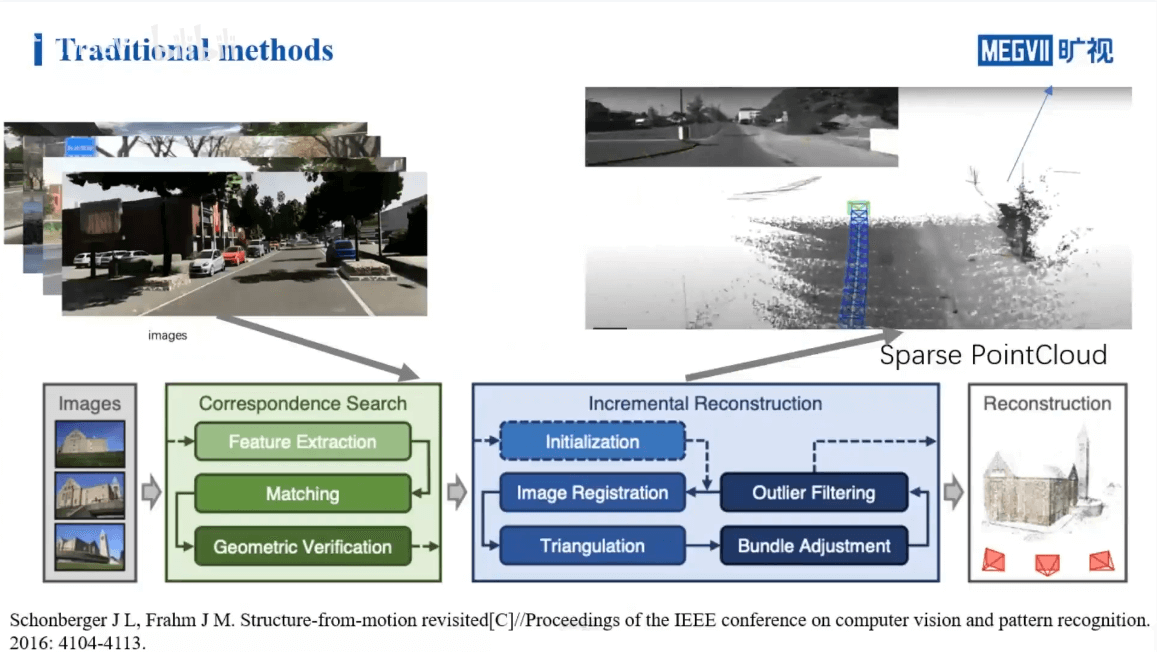 如上图所示,展示了COLMAP进行三维场景重建的步骤。简单来说就是首先对输入的影像进行特征提取与匹配等操作,找到对应关系,得到相机的位姿。然后在此基础上进行增量式重建。当然这个过程不可避免地会引入一些误差,所以会用BA等进行优化。上面提到的是用COLMAP进行三维重建的流程。如果用NeRF进行三维重建,应该有什么样的流程呢?
如上图所示,展示了COLMAP进行三维场景重建的步骤。简单来说就是首先对输入的影像进行特征提取与匹配等操作,找到对应关系,得到相机的位姿。然后在此基础上进行增量式重建。当然这个过程不可避免地会引入一些误差,所以会用BA等进行优化。上面提到的是用COLMAP进行三维重建的流程。如果用NeRF进行三维重建,应该有什么样的流程呢?
2.2 NeRF
如下图所示。
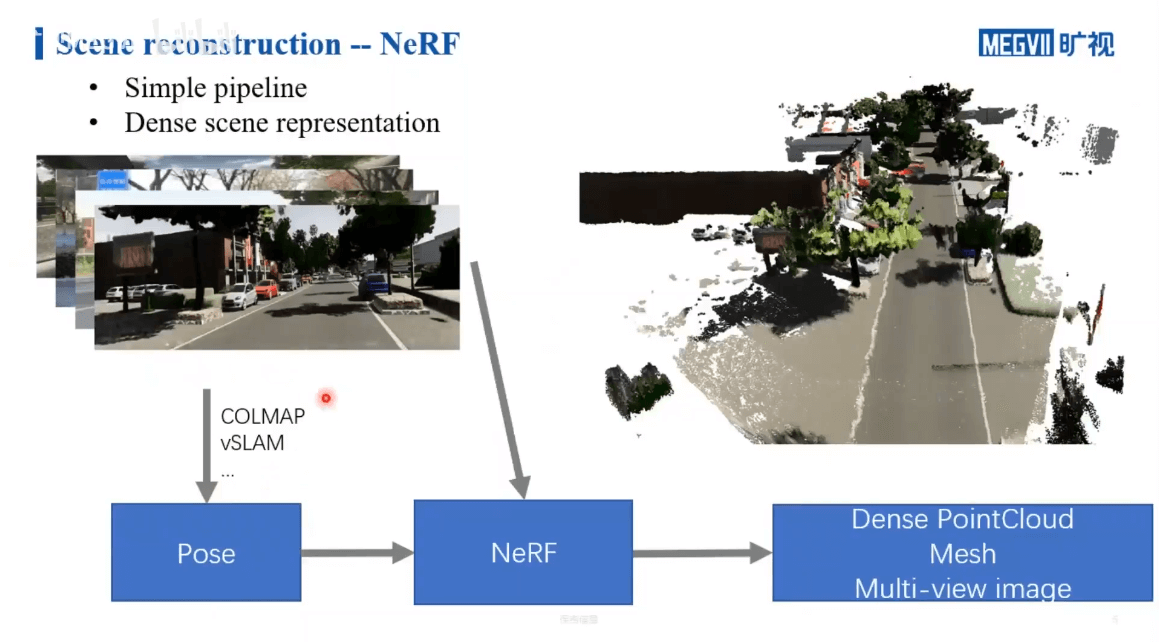 关于NeRF三维重建的pipeline之前笔记中已经介绍了。这里为了结构完整性,再简单介绍一下。利用NeRF进行三维重建,首先要有一堆拍摄的影像。然后我们还要有对应的每一张影像的位姿。这个位姿可以是通过SfM的方法获得,也可以通过SLAM获得,或者说外部直接测量提供都可以。然后将影像+位姿输入NeRF进行训练。训练好以后,给定一个位置和视角,网络就可以给出密度场和颜色场,基于此就可以渲染出合成视角影像。那么相比于传统COLMAP,NeRF有什么优劣呢?主要体现在两个方面:第一,NeRF的重建结果相比于COLMAP而言是更加稠密的;第二,根据上面的介绍也可以看出,NeRF相比于传统方法,流程会更加简单。一句话概括就是:用更简单的流程获得了更稠密的重建。这也就回答了第一篇笔记中的这个问题。
关于NeRF三维重建的pipeline之前笔记中已经介绍了。这里为了结构完整性,再简单介绍一下。利用NeRF进行三维重建,首先要有一堆拍摄的影像。然后我们还要有对应的每一张影像的位姿。这个位姿可以是通过SfM的方法获得,也可以通过SLAM获得,或者说外部直接测量提供都可以。然后将影像+位姿输入NeRF进行训练。训练好以后,给定一个位置和视角,网络就可以给出密度场和颜色场,基于此就可以渲染出合成视角影像。那么相比于传统COLMAP,NeRF有什么优劣呢?主要体现在两个方面:第一,NeRF的重建结果相比于COLMAP而言是更加稠密的;第二,根据上面的介绍也可以看出,NeRF相比于传统方法,流程会更加简单。一句话概括就是:用更简单的流程获得了更稠密的重建。这也就回答了第一篇笔记中的这个问题。
2.3 应用场景


 如上图所示,是Nvidia在GTC 2022上展示的利用NeRF进行场景重建的效果,可以应用在无人驾驶领域。同时,有了场景的三维模型,我们就可以在此基础上合成新的数据,比如模拟下雪场景等。
如上图所示,是Nvidia在GTC 2022上展示的利用NeRF进行场景重建的效果,可以应用在无人驾驶领域。同时,有了场景的三维模型,我们就可以在此基础上合成新的数据,比如模拟下雪场景等。
此外,还可以用在游戏、元宇宙等领域,如下。
 可以看到,相比于利用视觉SLAM或者激光SLAM重建的三维场景,NeRF重建的场景更加真实、细致。因此,我们可以直接拿着相机拍摄很多图片,然后利用NeRF就可以重建出精细的三维模型。这个模型可以直接用于游戏、XR等应用。所以如果从场景重建的角度而言,NeRF对场景的还原与表达是显著由于目前SLAM方法的。当然这跟研究的侧重点也有关系。NeRF本身就是做三维场景的表达与渲染,自然更关注场景本身重建的质量。而SLAM则更多关注于实时以及同时的位姿估计与建图。建图只是SLAM的任务之一。或者说建出来的图更多是为了“辅助”定位或者避障用的,而不是用来可视化的。所以自然看起来会“丑陋”一些。
可以看到,相比于利用视觉SLAM或者激光SLAM重建的三维场景,NeRF重建的场景更加真实、细致。因此,我们可以直接拿着相机拍摄很多图片,然后利用NeRF就可以重建出精细的三维模型。这个模型可以直接用于游戏、XR等应用。所以如果从场景重建的角度而言,NeRF对场景的还原与表达是显著由于目前SLAM方法的。当然这跟研究的侧重点也有关系。NeRF本身就是做三维场景的表达与渲染,自然更关注场景本身重建的质量。而SLAM则更多关注于实时以及同时的位姿估计与建图。建图只是SLAM的任务之一。或者说建出来的图更多是为了“辅助”定位或者避障用的,而不是用来可视化的。所以自然看起来会“丑陋”一些。
3.场景重建中的挑战
 NeRF的技术原理,如下。这里,我们稍微再仔细地分析一下。
NeRF的技术原理,如下。这里,我们稍微再仔细地分析一下。
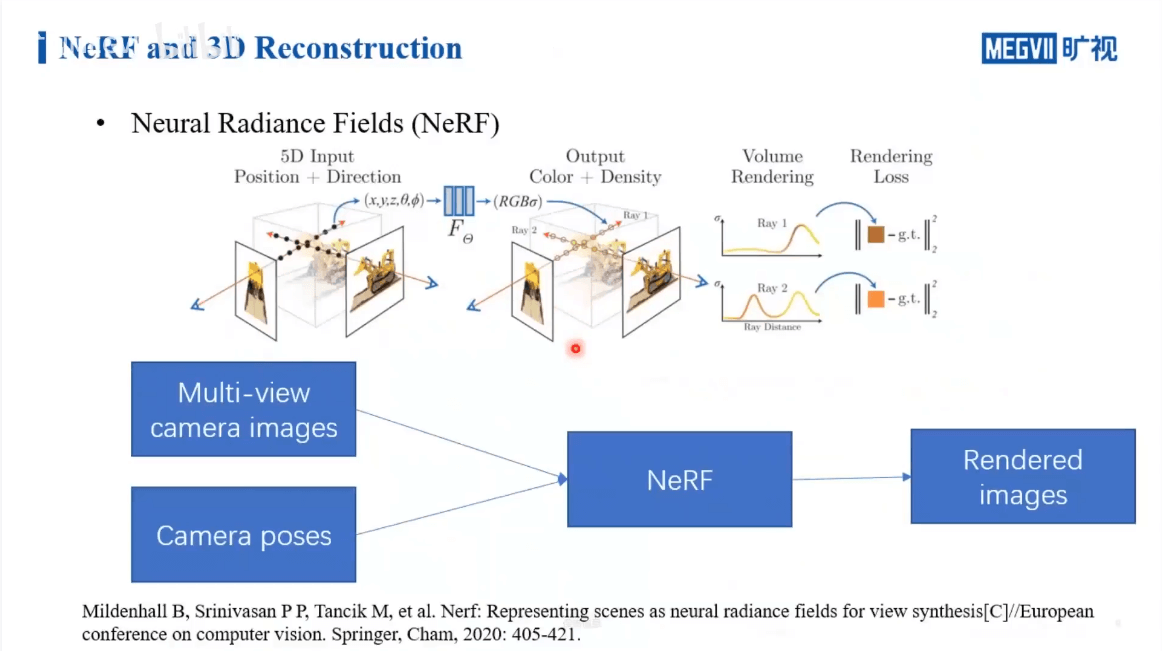 毫无疑问,NeRF跟传统重建技术的区别主要还是在于NeRF可以隐式地学习体素的表示。通过带有位姿的多视影像,NeRF可以学习到场景的表达,最终合成新视角影像。进一步,我们分析各个步骤,如下。
毫无疑问,NeRF跟传统重建技术的区别主要还是在于NeRF可以隐式地学习体素的表示。通过带有位姿的多视影像,NeRF可以学习到场景的表达,最终合成新视角影像。进一步,我们分析各个步骤,如下。
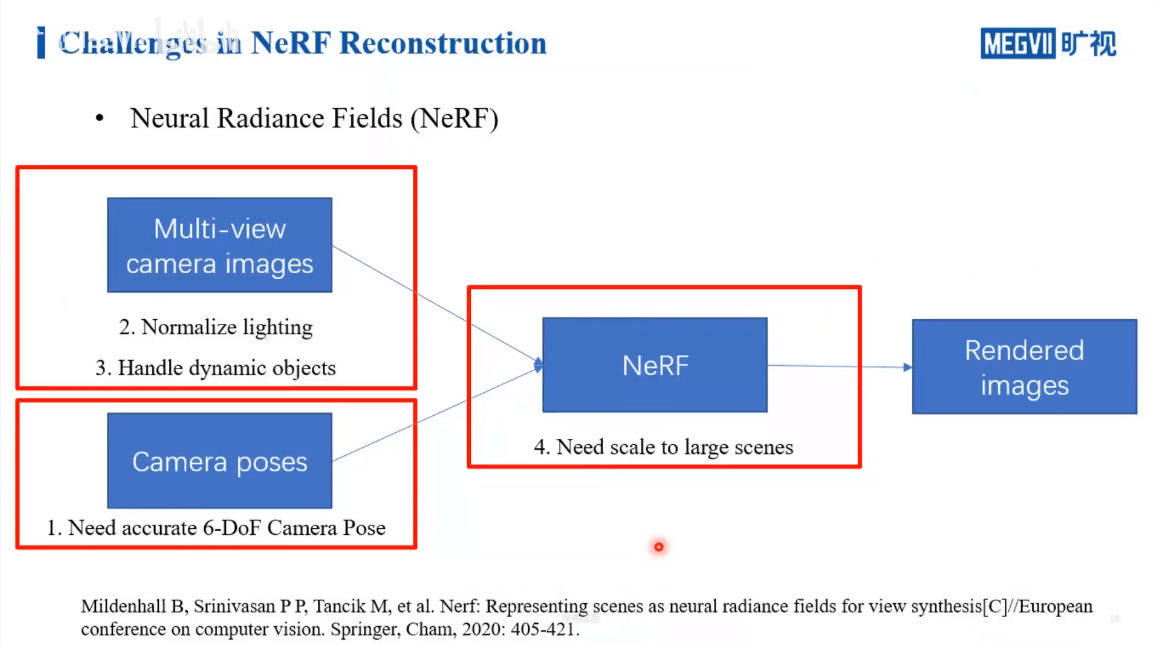 首先,我们的网络在训练阶段对于输入是有一定要求的。首先是相机位姿,我们需要输入的相机位姿是非常准确的,不然训练的网络效果不会很好。另外一个输入是多视影像,我们自然希望是要有稳定、统一的光照。不然就如同RGB-D SLAM一样,建出的图颜色不均匀。第二个是自然希望场景中没有运动物体,不然这种不统一的运动会给位姿估计带来影响。最后,可能出现真实的大场景,如何平衡性能,进行优化也是值得思考的问题。所以之后的内容主要围绕输入影像、输入位姿以及大场景这三个方面介绍。
首先,我们的网络在训练阶段对于输入是有一定要求的。首先是相机位姿,我们需要输入的相机位姿是非常准确的,不然训练的网络效果不会很好。另外一个输入是多视影像,我们自然希望是要有稳定、统一的光照。不然就如同RGB-D SLAM一样,建出的图颜色不均匀。第二个是自然希望场景中没有运动物体,不然这种不统一的运动会给位姿估计带来影响。最后,可能出现真实的大场景,如何平衡性能,进行优化也是值得思考的问题。所以之后的内容主要围绕输入影像、输入位姿以及大场景这三个方面介绍。
4.Neural Approach to Scene Reconstruction

4.1 位姿优化
 前面说了,NeRF的输入之一是相机的位姿。除了物理意义上通过外部测量直接获得位姿真值,我们也可以通过各种手段去算位姿。第一种方法是,我们可以用各种标定板,如Chessboard、AprilTag、ArUco board等,通过特殊的算法,就可以求得相机相对于标定板的位姿。第二种方法是使用各种SLAM方法进行位姿估计。第三种方法是使用SfM方法,如COLMAP等。第四种方法是基于NeRF,比如之前提到的iNeRF工作。通过给定一个影像,得到该影像相对于场景的相对位姿。这四种方法各有千秋。对于基于标定板的方法,显然只适合于小场景。对于室外等大场景就比较无能为力。对于SLAM方法,其本身没有场景大小的限制。但是由于其更关注于实时性,在一定程度上牺牲了一定的精度,导致其估计的位姿相比于SfM方法精度要差一些。对于SfM方法,相比于SLAM方法则是相反,其更关注于精度,但是运行效率会差一些,更加耗时,只能离线处理。因此,我们也就进一步回答了之前笔记里的这个问题。但显然的,除非是非常高精度设备测量的位姿,否则算出来的位姿或多或少都会有点噪声或者说不准确。所以我们就想,能不能让网络有一定的噪声容忍能力。所以BARF就出现了,来自于CMU,如下。
前面说了,NeRF的输入之一是相机的位姿。除了物理意义上通过外部测量直接获得位姿真值,我们也可以通过各种手段去算位姿。第一种方法是,我们可以用各种标定板,如Chessboard、AprilTag、ArUco board等,通过特殊的算法,就可以求得相机相对于标定板的位姿。第二种方法是使用各种SLAM方法进行位姿估计。第三种方法是使用SfM方法,如COLMAP等。第四种方法是基于NeRF,比如之前提到的iNeRF工作。通过给定一个影像,得到该影像相对于场景的相对位姿。这四种方法各有千秋。对于基于标定板的方法,显然只适合于小场景。对于室外等大场景就比较无能为力。对于SLAM方法,其本身没有场景大小的限制。但是由于其更关注于实时性,在一定程度上牺牲了一定的精度,导致其估计的位姿相比于SfM方法精度要差一些。对于SfM方法,相比于SLAM方法则是相反,其更关注于精度,但是运行效率会差一些,更加耗时,只能离线处理。因此,我们也就进一步回答了之前笔记里的这个问题。但显然的,除非是非常高精度设备测量的位姿,否则算出来的位姿或多或少都会有点噪声或者说不准确。所以我们就想,能不能让网络有一定的噪声容忍能力。所以BARF就出现了,来自于CMU,如下。
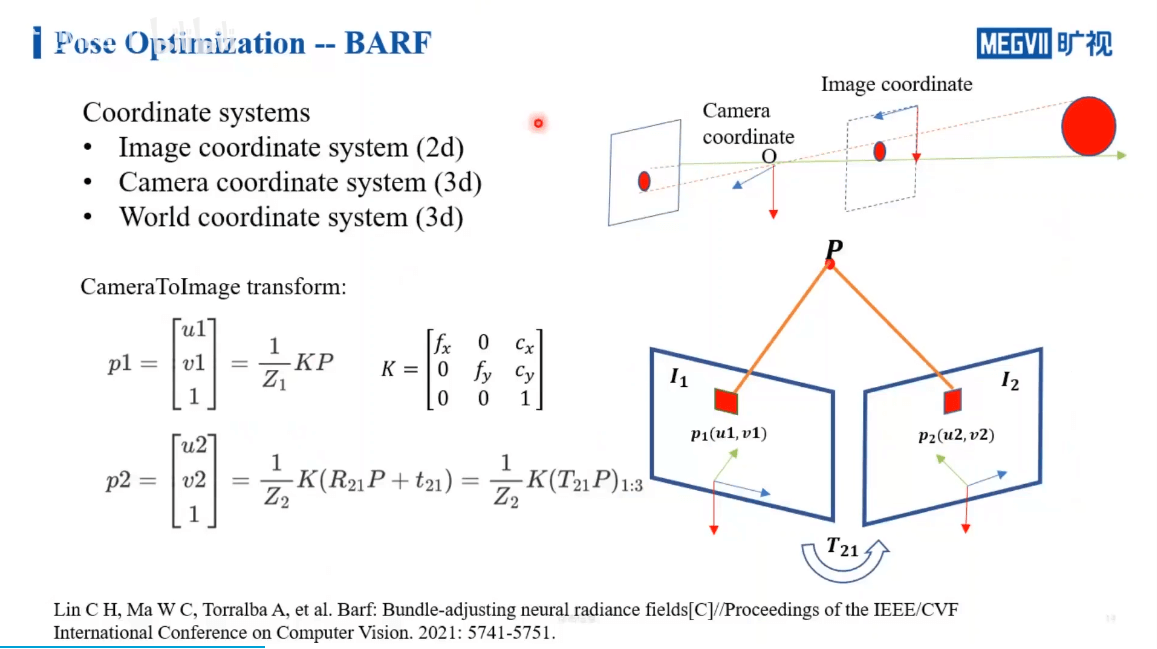
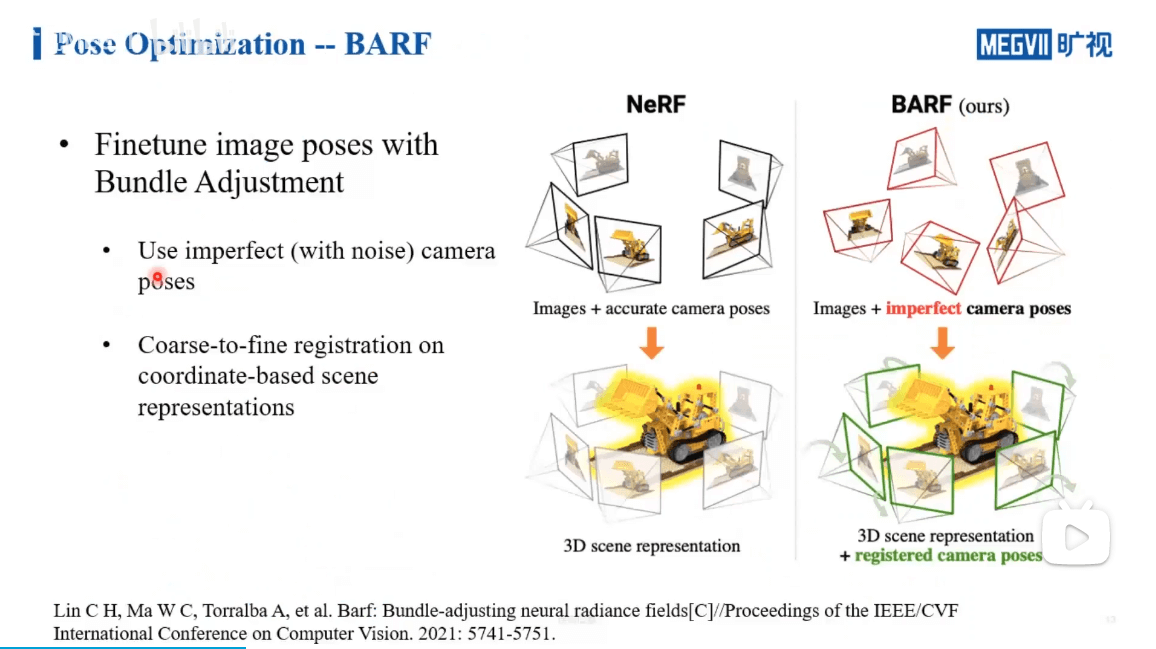 在这个工作中,作者利用传统SLAM中的BA方法优化影像位姿,如上图所示。一般NeRF需要精确的位姿,但是BARF输入的位姿可以是有误差的,通过他们的方法可以调整这种误差,最终得到和NeRF相同的效果。一些基本的三维重建坐标系介绍如下,之前也说过很多,此处不再赘述。
在这个工作中,作者利用传统SLAM中的BA方法优化影像位姿,如上图所示。一般NeRF需要精确的位姿,但是BARF输入的位姿可以是有误差的,通过他们的方法可以调整这种误差,最终得到和NeRF相同的效果。一些基本的三维重建坐标系介绍如下,之前也说过很多,此处不再赘述。
 在BARF中是怎么做呢?如下图所示。
在BARF中是怎么做呢?如下图所示。
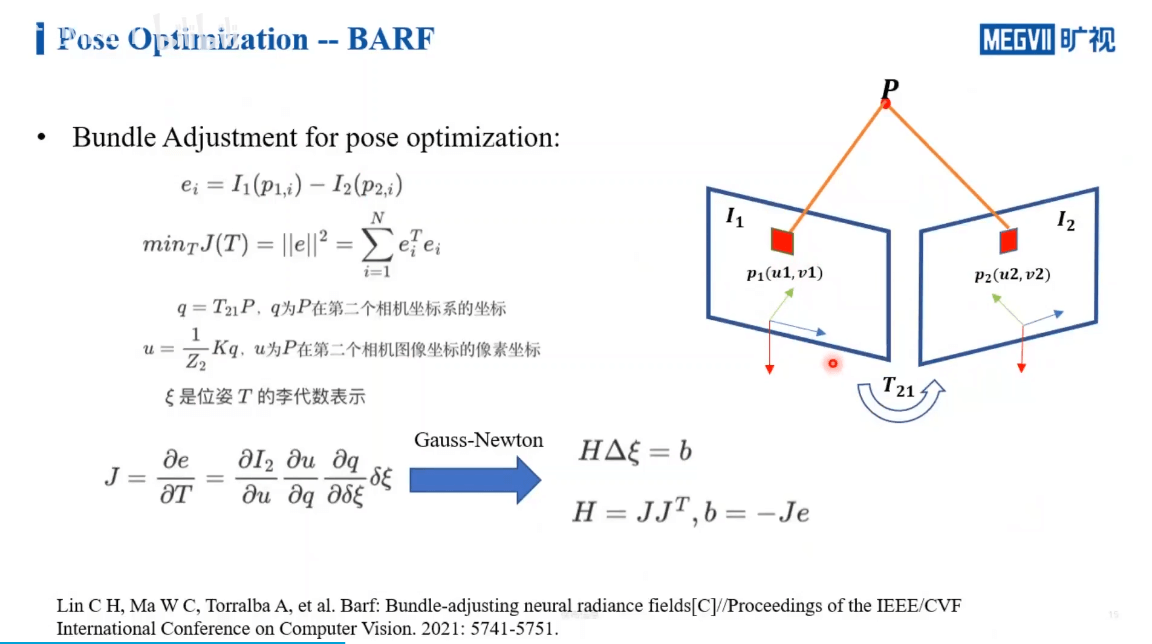 我们做一个帧间BA,使得重投影误差最小。其实也就是之前这篇博客里介绍过的内容。当然学过SLAM的应该知道,这一块理论推导还是挺难的。如果从实际应用的角度,可能会简单一些。因为很多东西已经写好了,我们只需要拿来用就可以了,如下。
我们做一个帧间BA,使得重投影误差最小。其实也就是之前这篇博客里介绍过的内容。当然学过SLAM的应该知道,这一块理论推导还是挺难的。如果从实际应用的角度,可能会简单一些。因为很多东西已经写好了,我们只需要拿来用就可以了,如下。
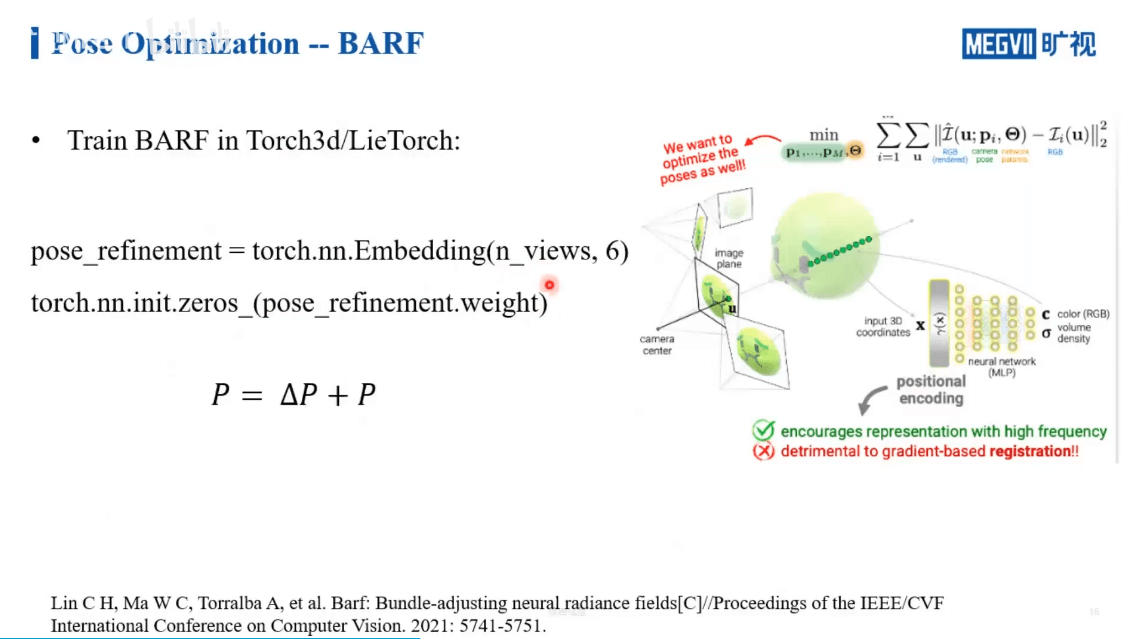 但还有个问题,那就是我们前面提到过的NeRF中的positional encoding。我们利用这种手段使得网络有能力感知到影像中的低频和高频信息,而不是简单的x、y、z坐标。但这确实会给位姿优化带来困难。
但还有个问题,那就是我们前面提到过的NeRF中的positional encoding。我们利用这种手段使得网络有能力感知到影像中的低频和高频信息,而不是简单的x、y、z坐标。但这确实会给位姿优化带来困难。
 我们如果对positional encoding求导,就会得到左下角的式子,可以看到有个比例系数。而且这个系数与层级有关,层级越高,代表频率越高,但是权重越大。这样的结果就是对于高频和低频的信息表达是不均衡的,网络更容易学到一些高频的部分。因此,BARF提供了一种新的机制,如下。
我们如果对positional encoding求导,就会得到左下角的式子,可以看到有个比例系数。而且这个系数与层级有关,层级越高,代表频率越高,但是权重越大。这样的结果就是对于高频和低频的信息表达是不均衡的,网络更容易学到一些高频的部分。因此,BARF提供了一种新的机制,如下。
 可以看到,BARF采用了退火机制。本质上来说就是对positional encoding增加了一个权重。简单来说就是,在网络刚开始训练的时候,只开放了低频的响应,而随着训练次数的增加,逐渐开放高频部分。这也是一种由粗到细的策略,可以保证网络在一开始的时候就不会学到什么奇奇怪怪的东西。下图是BARF的效果展示。
可以看到,BARF采用了退火机制。本质上来说就是对positional encoding增加了一个权重。简单来说就是,在网络刚开始训练的时候,只开放了低频的响应,而随着训练次数的增加,逐渐开放高频部分。这也是一种由粗到细的策略,可以保证网络在一开始的时候就不会学到什么奇奇怪怪的东西。下图是BARF的效果展示。
 可以看到,加了BARF以后,场景的细节恢复地非常好。
可以看到,加了BARF以后,场景的细节恢复地非常好。
然后,另一个工作室iNeRF,如下所示。
 在有了一个训练好的NeRF以后,我们可以实现基于影像的定位。
在有了一个训练好的NeRF以后,我们可以实现基于影像的定位。
4.2 影像优化
在处理完了位姿不准的问题以后,另一个问题就是要对图像进行优化,如上面描述,又主要分为光照变化和动态物体两个方面,下面分别介绍。
4.2.1 光照变化
 这个问题的核心在于,我们输入NeRF的影像自然是希望每张影像光照都比较均匀,变化较小。这在光照条件控制较好的室内或者小场景中还比较容易,但是对于室外等大场景几乎是不可能的。如何对这些不均匀的光照进行优化,是这部分要讨论的问题。
这个问题的核心在于,我们输入NeRF的影像自然是希望每张影像光照都比较均匀,变化较小。这在光照条件控制较好的室内或者小场景中还比较容易,但是对于室外等大场景几乎是不可能的。如何对这些不均匀的光照进行优化,是这部分要讨论的问题。
 一种解决策略是在RGB域建模,通过设置某个可调整的参数,使得网络具备调整影像的能力。另一种是在第一种的基础上更进一步,把ISP处理pipeline中的步骤同样进行建模,让网络学习。最后一种是直接对传感器直出的RAW数据进行训练,得到NeRF。
一种解决策略是在RGB域建模,通过设置某个可调整的参数,使得网络具备调整影像的能力。另一种是在第一种的基础上更进一步,把ISP处理pipeline中的步骤同样进行建模,让网络学习。最后一种是直接对传感器直出的RAW数据进行训练,得到NeRF。
这方面的第一个工作是NeRF in the Wild,如下。
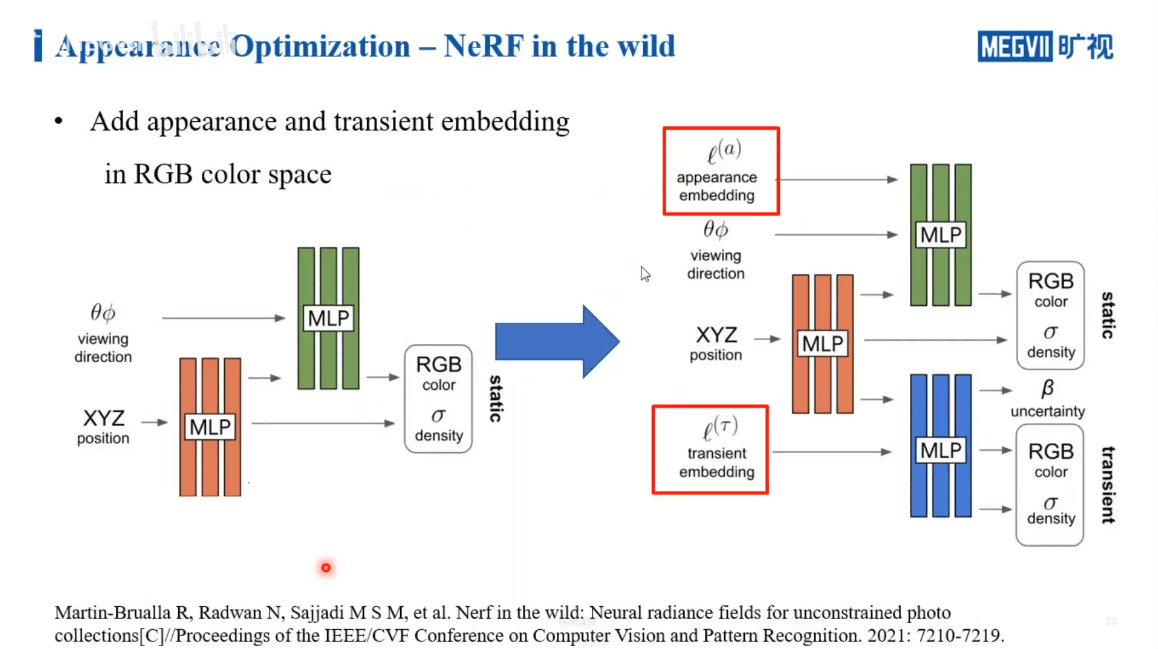 左侧为原始NeRF的流程。右侧作者增加了appearance embedding和transient embedding这两个变量来学习颜色的变化。结果如下。
左侧为原始NeRF的流程。右侧作者增加了appearance embedding和transient embedding这两个变量来学习颜色的变化。结果如下。
 进一步,我们如果考虑ISP处理的一些步骤,也可以对其进行建模。这是ADOP的工作,如下。
进一步,我们如果考虑ISP处理的一些步骤,也可以对其进行建模。这是ADOP的工作,如下。
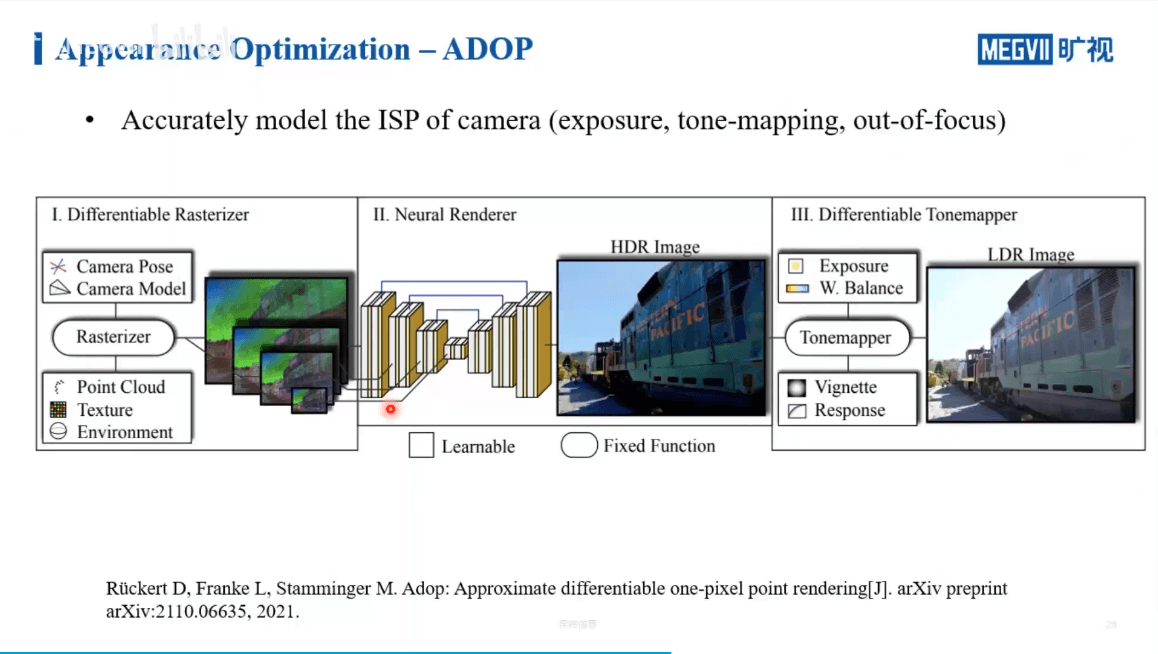 可以看到,网络有能力学习到场景的一些本征的颜色。比如黄色的沙发因为逆光在真实影像中偏暗,但是在合成的影像中,就被恢复的比较好了。
可以看到,网络有能力学习到场景的一些本征的颜色。比如黄色的沙发因为逆光在真实影像中偏暗,但是在合成的影像中,就被恢复的比较好了。
 最后一种思路是在Raw数据上做NeRF,这是NeRF in the dark的工作,如下。
最后一种思路是在Raw数据上做NeRF,这是NeRF in the dark的工作,如下。
 其实想法也比较简单。常规的NeRF拿到的影像是经过ISP处理以后的影像,这种处理引入了各种非线性变换,那么网络去拟合这种变换其实是比较困难的事情。另外,在处理的过程中,也会压缩位宽,导致一些信息损失。所以作者就直接在RAW数据上训练NeRF。
其实想法也比较简单。常规的NeRF拿到的影像是经过ISP处理以后的影像,这种处理引入了各种非线性变换,那么网络去拟合这种变换其实是比较困难的事情。另外,在处理的过程中,也会压缩位宽,导致一些信息损失。所以作者就直接在RAW数据上训练NeRF。
4.2.2 动态物体
在处理了光照不均衡的情况以后,影像相关的另一个挑战就是动态物体。
 解决这个问题一般来说有两种做法,如下。
解决这个问题一般来说有两种做法,如下。
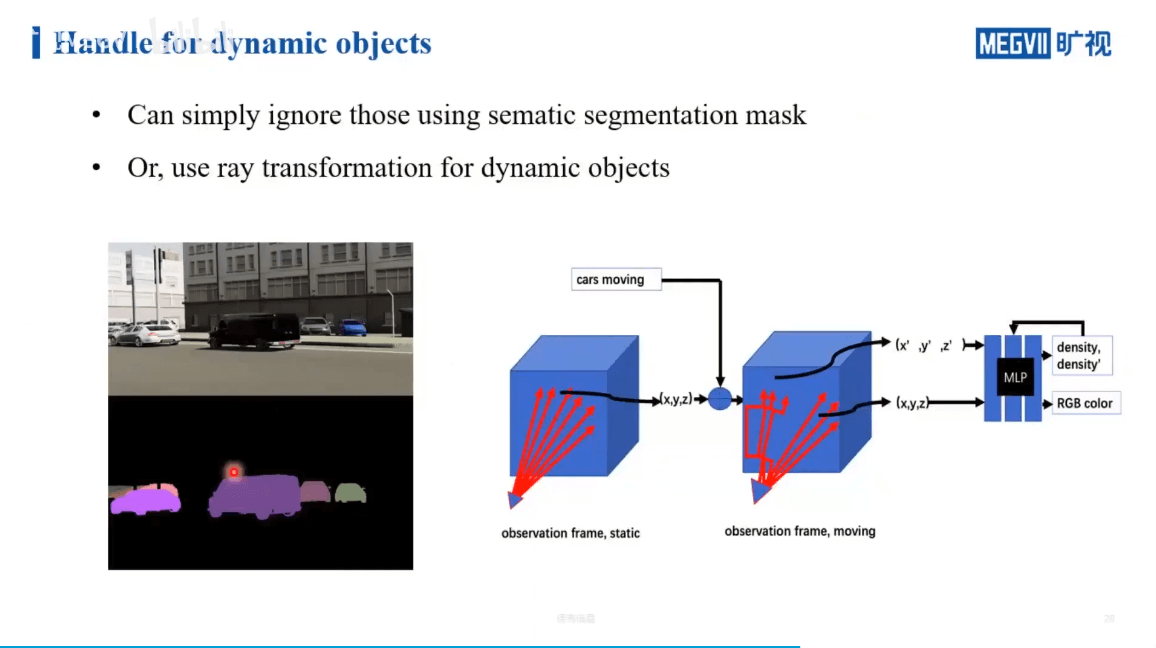 一个简单的想法就是,利用语义信息识别出一些可能运动的物体,然后把它们忽略掉(上图左边)。但这样有个潜在的问题,如果被擦除的物体在其它视角下也没见过,那么就会产生空洞。另一种办法就是,真正的对动态物体的重建完成,具体可以通过光线变换来重建动态物体(上图右边)。
一个简单的想法就是,利用语义信息识别出一些可能运动的物体,然后把它们忽略掉(上图左边)。但这样有个潜在的问题,如果被擦除的物体在其它视角下也没见过,那么就会产生空洞。另一种办法就是,真正的对动态物体的重建完成,具体可以通过光线变换来重建动态物体(上图右边)。
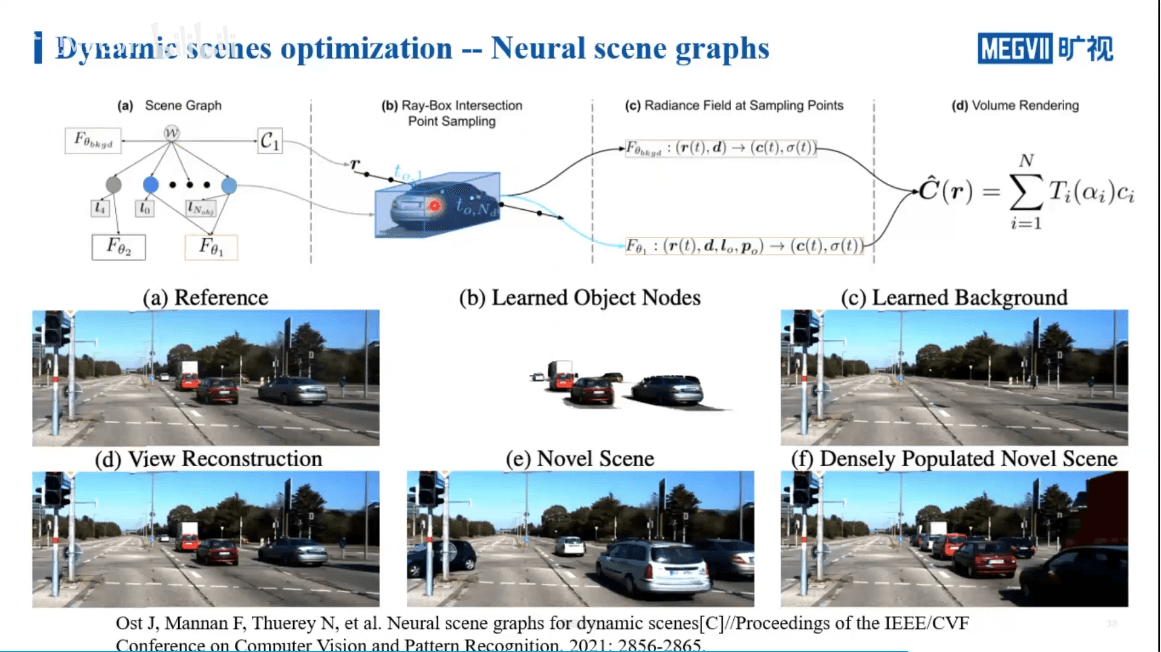
一个工作室Neural Scene Graphs就是这样一个工作,如下图所示。
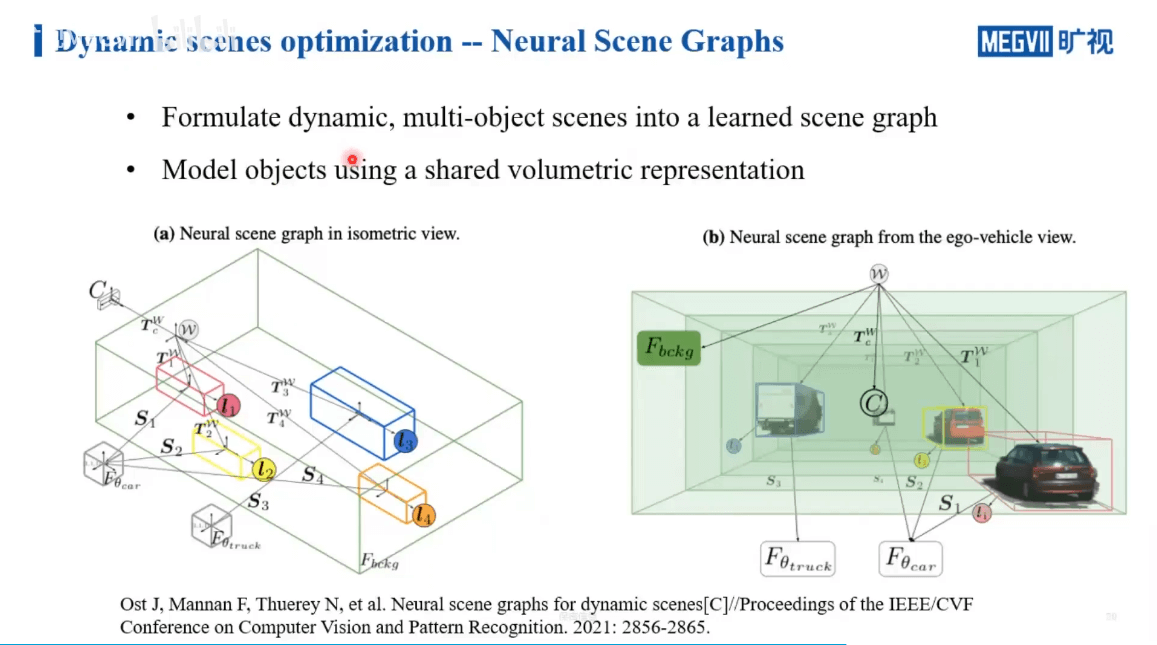 作者通过场景图将场景和运动目标分割开,如上图所示。各个节点之间的关系是通过相对变换得到的。在训练过程中,背景单独用NeRF训练。而对于前景目标,有两种不同的做法,如下图所示。
作者通过场景图将场景和运动目标分割开,如上图所示。各个节点之间的关系是通过相对变换得到的。在训练过程中,背景单独用NeRF训练。而对于前景目标,有两种不同的做法,如下图所示。
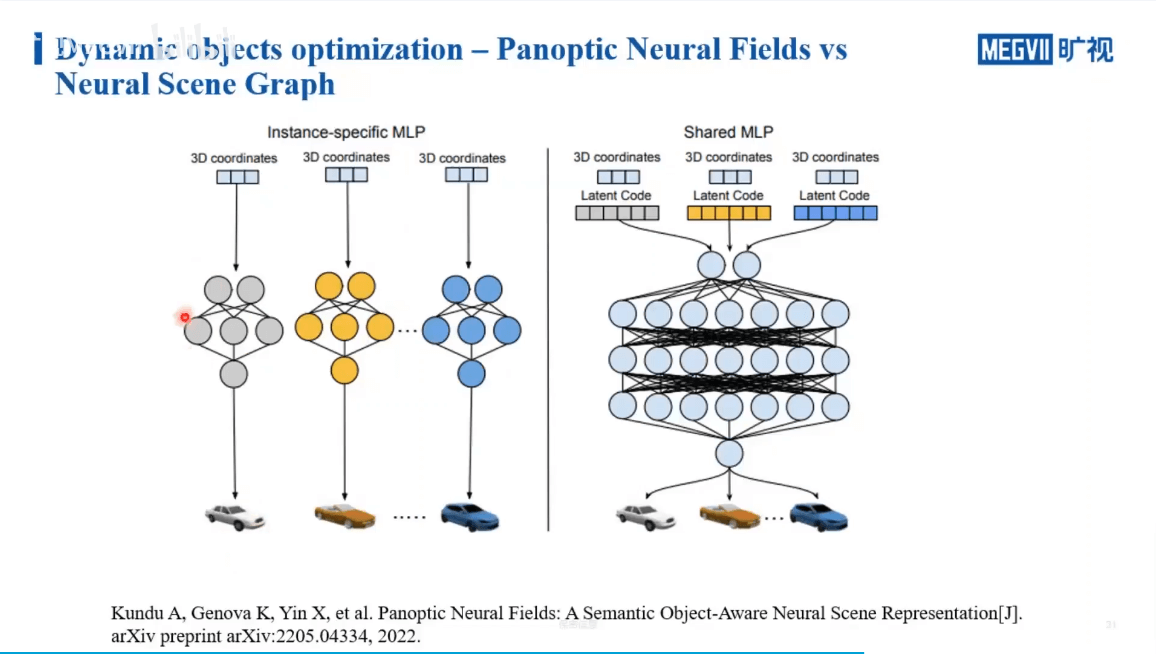 一种方法是,我们可以对每一个运动物体单独用一个很小的NLP来学习,通过多个NLP最终对每个运动目标进行恢复。另一种则是,对于一类物体,共享一个大的NLP,通过学习latent code来区分不同的实例。这两种方式需要根据具体场景决定。当场景中车辆很多的时候,前者的参数量或者学习难度是随着数量而线性增长的,而后者因为共享参数则不会有明显的增长。但如果我们需要对每个车进行精细的建模,那么显然前者更加合适一些。实际渲染过程与结果如下图所示。
一种方法是,我们可以对每一个运动物体单独用一个很小的NLP来学习,通过多个NLP最终对每个运动目标进行恢复。另一种则是,对于一类物体,共享一个大的NLP,通过学习latent code来区分不同的实例。这两种方式需要根据具体场景决定。当场景中车辆很多的时候,前者的参数量或者学习难度是随着数量而线性增长的,而后者因为共享参数则不会有明显的增长。但如果我们需要对每个车进行精细的建模,那么显然前者更加合适一些。实际渲染过程与结果如下图所示。
4.3 大场景挑战
最后一部分是NeRF在大场景中的挑战,如何平衡性能与精度等问题,如下所示。
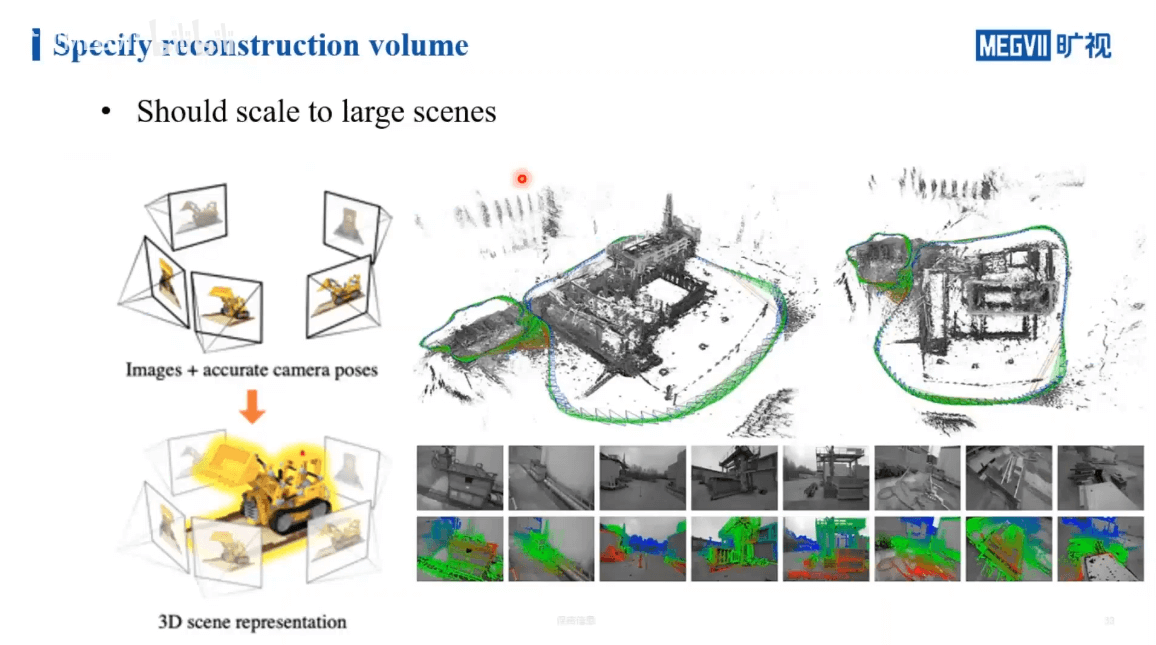 如上图所示,对于一些较小的场景,观测一般都是由外向内进行聚合的。这样我们很容易得到被摄物体的三维包围框。但在室外等大场景中,很难有一个三维的包围框可以把整个场景包含在里面。另外,对于室外的场景,还不可避免的有“天空”问题。在采集过程中,很多视角都会采集到天空的像素,但事实上这些像素是我们重建中不需要考虑(简单的方法是增加mask)。此外还有远处场景的细节优化问题等。对于大场景的建模,还是相对复杂的。
如上图所示,对于一些较小的场景,观测一般都是由外向内进行聚合的。这样我们很容易得到被摄物体的三维包围框。但在室外等大场景中,很难有一个三维的包围框可以把整个场景包含在里面。另外,对于室外的场景,还不可避免的有“天空”问题。在采集过程中,很多视角都会采集到天空的像素,但事实上这些像素是我们重建中不需要考虑(简单的方法是增加mask)。此外还有远处场景的细节优化问题等。对于大场景的建模,还是相对复杂的。
 如上图所示,在最左边的图中,我们给远处分配较大权重,那么近处就会相对模糊。反之,近处权重高以后,远处又会变模糊。所以其实是比较难的问题。在KITTI数据上也是一样,远处的树木可能发生一些偏移。所以总结起来就是,我们没有办法通过有限的资源来掌握场景中的所有细节。尽管很困难,但还是有相关工作,如下。
如上图所示,在最左边的图中,我们给远处分配较大权重,那么近处就会相对模糊。反之,近处权重高以后,远处又会变模糊。所以其实是比较难的问题。在KITTI数据上也是一样,远处的树木可能发生一些偏移。所以总结起来就是,我们没有办法通过有限的资源来掌握场景中的所有细节。尽管很困难,但还是有相关工作,如下。
 Block NeRF主要是针对街景数据的处理,通过对场景进行分块,并保证各个块之间有重叠,实现多个NeRF的联合。Mega NeRF主要是针对无人机数据的处理。它的思路和Instant NGP和KiloNeRF有一定的相似之处。下图展示了Block NeRF更细节的内容。
Block NeRF主要是针对街景数据的处理,通过对场景进行分块,并保证各个块之间有重叠,实现多个NeRF的联合。Mega NeRF主要是针对无人机数据的处理。它的思路和Instant NGP和KiloNeRF有一定的相似之处。下图展示了Block NeRF更细节的内容。
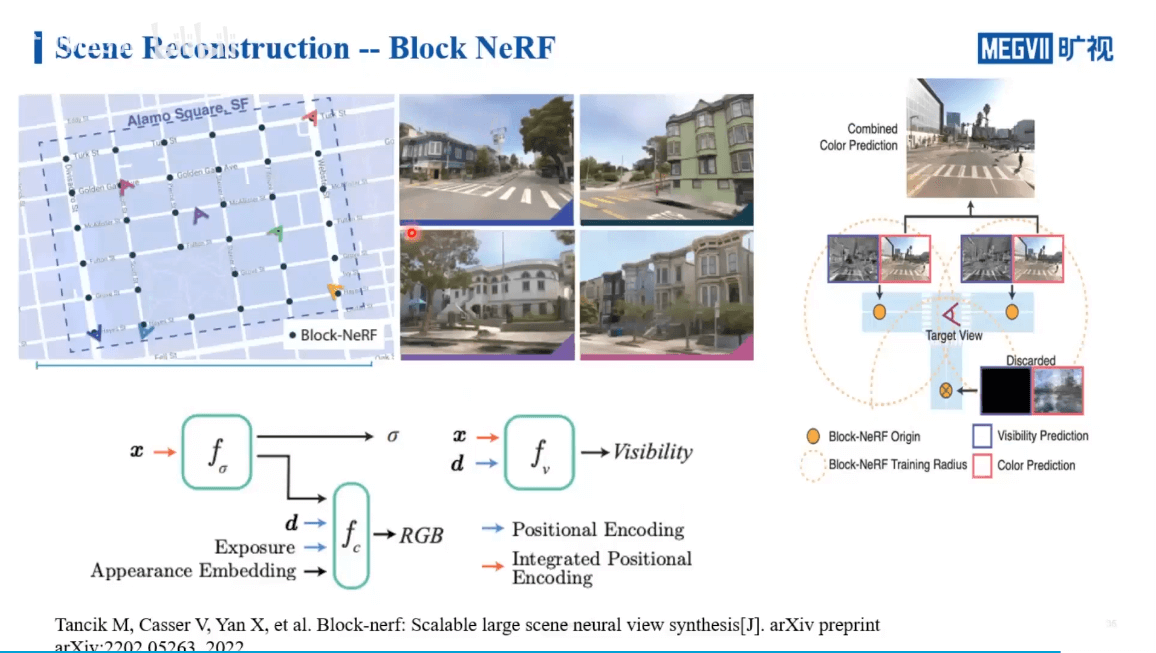 这里还引入了Visibility概念。简单来说就是,如果我们要渲染某个位置的影像,理论上来说我们要查询所有的NeRF网络,找到那些和当前视角相关的进行渲染。但这样每个NeRF网络都查询,显然是非常耗时的。所以作者又训练了一个小网络。这个网络的作用是判断某个位置是否在当前NeRF的场景中。这样只需要查询相关的NeRF网络就可以,而不需要每个都遍历,提升了效率。
这里还引入了Visibility概念。简单来说就是,如果我们要渲染某个位置的影像,理论上来说我们要查询所有的NeRF网络,找到那些和当前视角相关的进行渲染。但这样每个NeRF网络都查询,显然是非常耗时的。所以作者又训练了一个小网络。这个网络的作用是判断某个位置是否在当前NeRF的场景中。这样只需要查询相关的NeRF网络就可以,而不需要每个都遍历,提升了效率。
4.4 小结
至此,我们就介绍了NeRF在真实场景中遇到的一些问题以及解决方案。
 对于位姿不准的问题,可以通过引入BARF在训练NeRF的同时来优化位姿。对于光照变化的问题,可以引入appearance embedding让网络自适应地去学习,实现颜色的调整。对于运动物体问题,要么通过掩膜忽略,要么利用光线变换解决。最后,对于大场景,一般通过分块策略将大场景的计算开销分摊到每个小的NeRF上,最后再合并起来。
对于位姿不准的问题,可以通过引入BARF在训练NeRF的同时来优化位姿。对于光照变化的问题,可以引入appearance embedding让网络自适应地去学习,实现颜色的调整。对于运动物体问题,要么通过掩膜忽略,要么利用光线变换解决。最后,对于大场景,一般通过分块策略将大场景的计算开销分摊到每个小的NeRF上,最后再合并起来。
5.Exercise



本文作者原创,未经许可不得转载,谢谢配合
