0.背景
在之前做SLAM相关实验的时候,有时候不可避免地需要查看对于GPU的使用情况。如果我们只是简单地查看一下,如这篇博客说的,可以直接输入nvidia-smi查看,或者也可以watch nvidia-smi自动刷新。如果你是Nvidia的Jetson平台,除了这个,如这篇博客说的,还可以有专门的jtop命令可用。而如果是普通Linux,类似地可以使用nvtop,新版Ubuntu(19以上)通过apt-get install nvtop安装即可,老版本源码编译。详细安装步骤可以参考这个网页。
但不管是nvidia-smi、jtop、nvtop,都有一个比较麻烦的地方,就是输出的信息无法保存成Log文件。这对于实验过程中需要记录GPU使用变化的情况而言尤其麻烦。因此这篇博客主要就是用来解决这个问题。
1.实现思路
要实现这个目标其实也非常简单,我们只需要通过Python的接口执行nvidia-smi命令,并获取到该命令的返回值,对返回值进行进一步解析,最后将解析的结果保存成文本文件就可以了。
更具体一点,利用Python执行命令并获取返回值,可以使用os模块中的popen()函数,os.system()函数是没有返回值的,这点需要区分一下。对于结果的解析,我们首先可以看一下nvidia-smi的输出内容,如下。
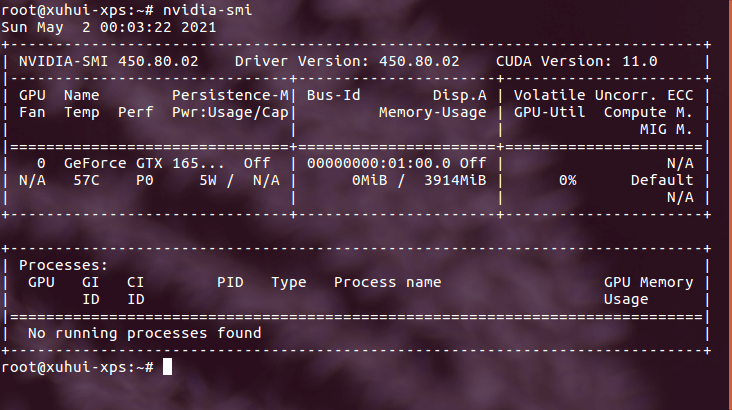 可以看到,其实输出是有固定格式的,基本不会变。因此我们可以利用这一点,大幅度降低处理难度。我们可以初步地按行将结果字符串一行行拆开,然后根据行数先大致确定位置,再在那一行里进行进一步处理。而最后的文本输出,则是再普通不过的
可以看到,其实输出是有固定格式的,基本不会变。因此我们可以利用这一点,大幅度降低处理难度。我们可以初步地按行将结果字符串一行行拆开,然后根据行数先大致确定位置,再在那一行里进行进一步处理。而最后的文本输出,则是再普通不过的open()函数和write()函数了。
2.实现代码
Python的实现代码如下,也传到了Github上,点击查看。
import os
import re
import time
import sys
# 获取显存使用情况
def parseGPUMem(str_content):
lines = str_content.split("\n")
target_line = lines[8]
mem_part = target_line.split("|")[2]
use_mem = mem_part.split("/")[0]
total_mem = mem_part.split("/")[1]
use_mem_int = int(re.sub("\D", "", use_mem))
total_mem_int = int(re.sub("\D", "", total_mem))
return use_mem_int, total_mem_int
# 获取GPU使用情况
def parseGPUUseage(str_content):
lines = str_content.split("\n")
target_line = lines[8]
print(target_line)
useage_part = int(target_line.split("|")[3].split("%")[0])
return useage_part
# 获取监控进程显存使用情况
def parseProcessMem(str_content, process_name):
part = str_content.split("| GPU PID Type Process name Usage |")[1]
lines = part.split("\n")
for i in range(len(lines)):
line = lines[i]
if line.__contains__(process_name):
mem_use = int(line[-10:-5])
return mem_use
if __name__ == '__main__':
if len(sys.argv) == 1:
print("Please input process name to monitor.\nExample: python GPULogger.py target_name")
exit()
str_command = "nvidia-smi" # 需要执行的命令
process_name = sys.argv[1] # 待监控的进程名称
# 如果指定了输出路径和名称,就用输入的,否则自动生成Log文件保存的路径
if len(sys.argv) == 3:
out_path = sys.argv[2]
else:
out_path = "GPU_stat_"+process_name+".txt"
# 监控的时间间隔,如果没有输入,就默认0.5秒记录一次
if len(sys.argv) == 4:
time_interval = float(sys.argv[3])
else:
time_interval = 0.5
fout = open(out_path, "w")
fout.write("Timestamp\tGPU Usage Percentage\tGPU Total Mem Usage\tGPU Total Mem Usage Percentage\tProcess Mem Usage\n")
while True:
out = os.popen(str_command)
text_content = out.read()
out.close()
usage_percentage = parseGPUUseage(text_content)
use_mem, total_mem = parseGPUMem(text_content)
mem_use = parseProcessMem(text_content, process_name)
use_percent = round(use_mem * 100.0 / total_mem, 2)
str_outline = str(time.time()) + "\t" + str(usage_percentage) + "\t" + str(use_mem) + "\t" + str(use_percent) + "\t" + str(mem_use)
fout.write(str_outline + "\n")
print(str_outline + "\t\tPress Ctrl + C to interupt.")
time.sleep(time_interval)
脚本首先需要指定要监测的进程的名称,然后就会输出一个记录的文本文件。其包含时间戳、GPU使用情况、目标进程显存占用情况等。当需要停止的时候,按Ctrl + C 停止即可。
3.实际测试
利用上述脚本,进行实际测试,保存的Log如下。
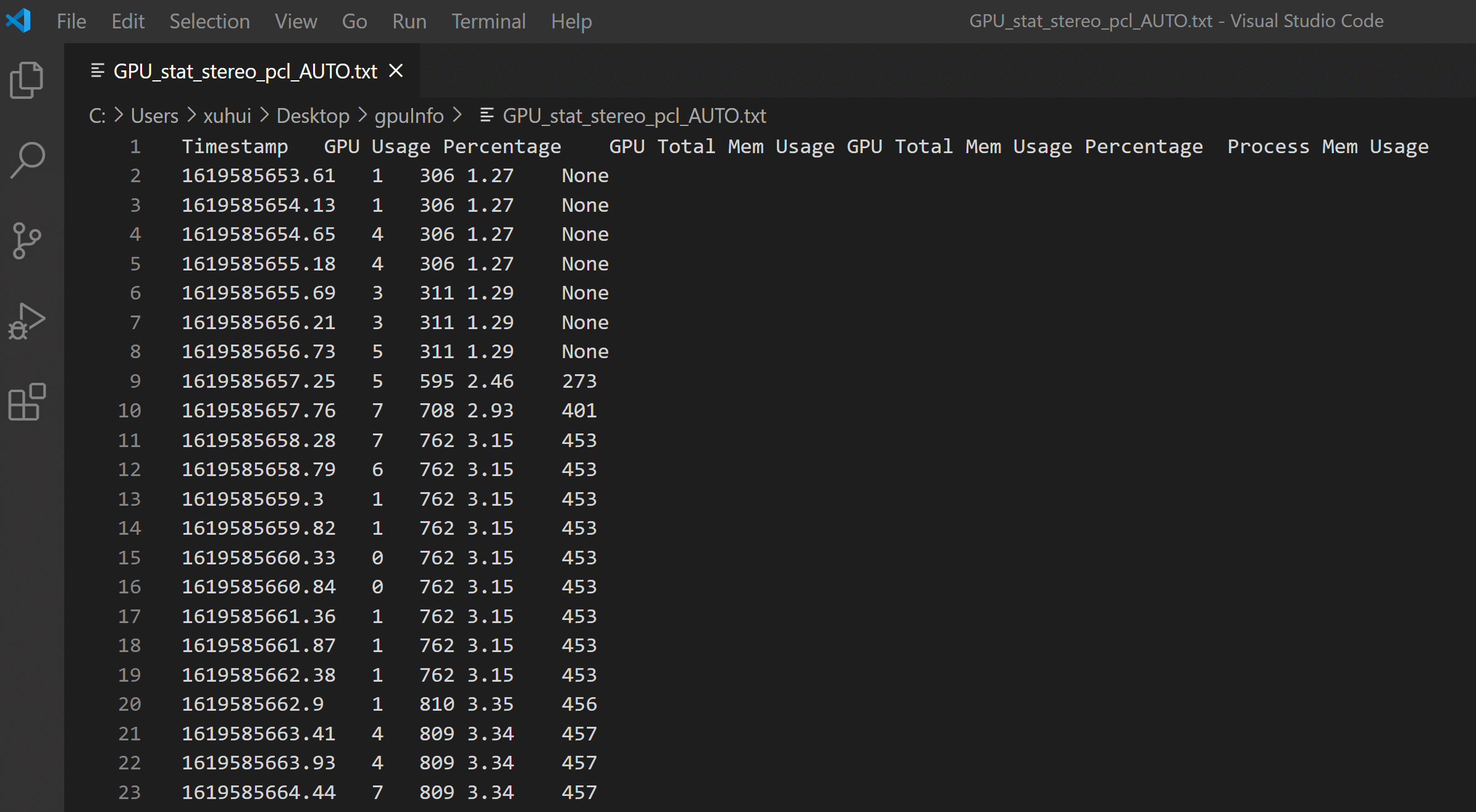 有了这些数据,我们就可以很容易地画图和进一步分析,计算其它指标,如下是GPU使用情况和显存使用情况的变化图。
有了这些数据,我们就可以很容易地画图和进一步分析,计算其它指标,如下是GPU使用情况和显存使用情况的变化图。
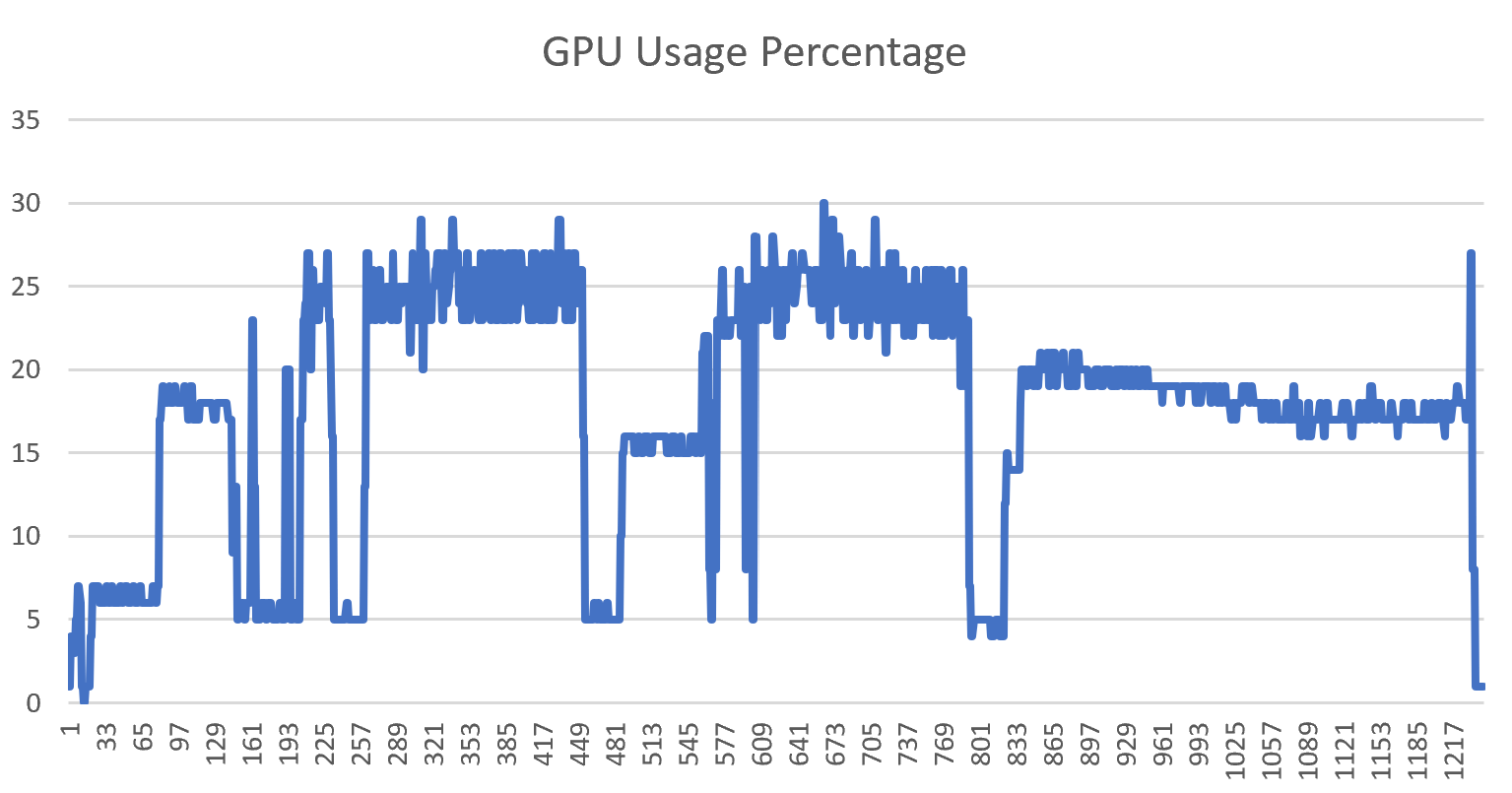
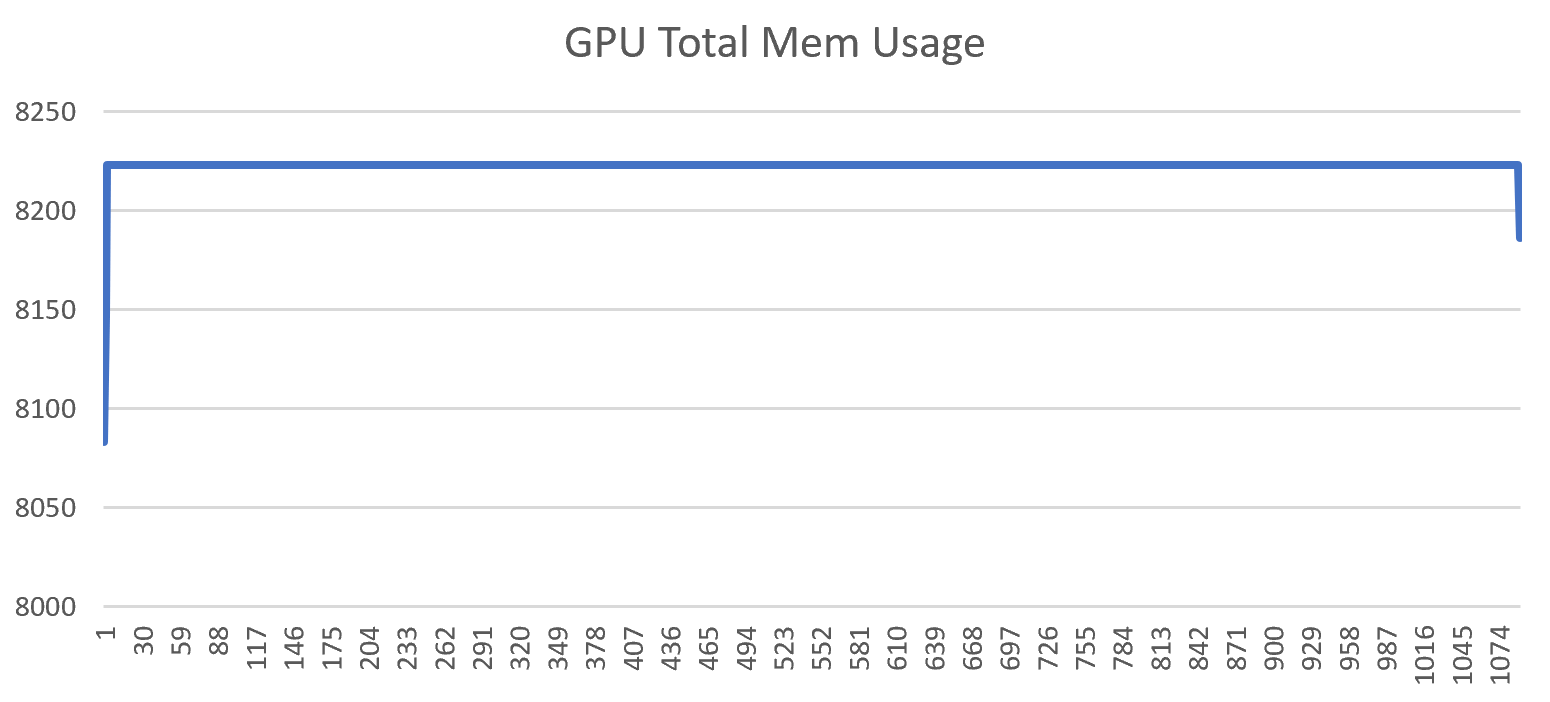 至此,就很好地完成了一开始我们提出的需求。这确实一个很常见、但是又没有被很好解决的问题。当然,如果装好Nvidia CUDA相关开发套件,是会有一些性能分析工具的,但是相比于直接运行一个脚本,还是略显麻烦。
至此,就很好地完成了一开始我们提出的需求。这确实一个很常见、但是又没有被很好解决的问题。当然,如果装好Nvidia CUDA相关开发套件,是会有一些性能分析工具的,但是相比于直接运行一个脚本,还是略显麻烦。
4.参考资料
- [1] https://blog.csdn.net/zong596568821xp/article/details/103712188
本文作者原创,未经许可不得转载,谢谢配合
