1.什么是GPU
随着GPU并行运算能力的不断提升,其应用范围也渐渐不仅局限于图像领域,
已经由传统的GPU发展到了GPGPU(General Purpose computations on GPU),
也即通用计算图形处理单元。目前GPU在新兴领域如深度学习、AI、大数据分析等领域
应用广泛,而且越来越多的用途被挖掘。
GPU全称是Graphic Processing Unit——图形处理器,
其最大的作用就是进行各种绘制计算机图形所需的运算,
包括顶点设置、光影、像素操作等。
GPU实际上是一组图形函数的集合,而这些函数由硬件实现。
在很久以前,这些工作都是由CPU配合特定软件进行的,
后来随着图像的复杂程度越来越高,
单纯由CPU进行这项工作对于CPU的负荷远远超出了CPU的正常性能范围,
这个时候就需要一个在图形处理过程中担当重任的角色,
GPU也就是从那时起正式诞生了。从GPU的结构示意图上来看,
一块标准的GPU主要包括通用计算单元、控制器和寄存器,
从这些模块上和CPU的内部结构很像。
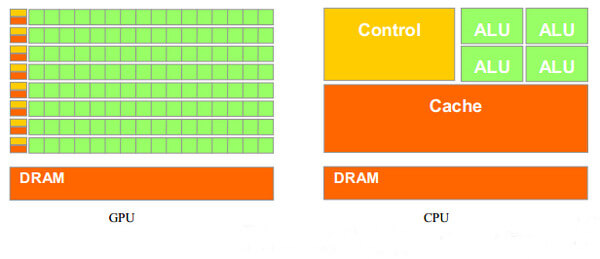 两者的确在内部结构上有许多类似之处,
但由于GPU具有高并行结构(highly parallel structure),
且采用流式并行计算模式,可对每个数据进行独立的并行计算,
所谓“对数据进行独立计算”,即流内任意元素的计算不依赖于其它同类型数据。
而所谓“并行计算”是指“多个数据可以同时被使用,
多个数据并行运算的时间和1个数据单独执行的时间是一样的。
所以GPU在处理图形数据和复杂算法方面拥有比CPU更高的效率。
CPU大部分面积为控制器和寄存器,而GPU拥有更多的ALU(Arithmetic Logic Unit,逻辑运算单元)用于数据处理,
而非数据高速缓存和流控制,这样的结构适合对密集型数据进行并行处理。
CPU执行计算任务时,一个时刻只处理一个数据,不存在真正意义上的并行,
而GPU具有多个处理器核,在一个时刻可以并行处理多个数据。
两者的确在内部结构上有许多类似之处,
但由于GPU具有高并行结构(highly parallel structure),
且采用流式并行计算模式,可对每个数据进行独立的并行计算,
所谓“对数据进行独立计算”,即流内任意元素的计算不依赖于其它同类型数据。
而所谓“并行计算”是指“多个数据可以同时被使用,
多个数据并行运算的时间和1个数据单独执行的时间是一样的。
所以GPU在处理图形数据和复杂算法方面拥有比CPU更高的效率。
CPU大部分面积为控制器和寄存器,而GPU拥有更多的ALU(Arithmetic Logic Unit,逻辑运算单元)用于数据处理,
而非数据高速缓存和流控制,这样的结构适合对密集型数据进行并行处理。
CPU执行计算任务时,一个时刻只处理一个数据,不存在真正意义上的并行,
而GPU具有多个处理器核,在一个时刻可以并行处理多个数据。
2.GPU与CPU的区别
- 设计目的不同
CPU架构是按照兼顾“指令并行执行”和“数据并行运算”的思路而设计, 其大部分晶体管主要用于构建控制电路和Cache。其内部有大约5%是ALU, 但控制电路则更为复杂。GPU的控制电路则相对简单,而且对Cache的需求较小, 所以可以把大部分的晶体管都用于计算单元。GPU的40%都是ALU。 - 延迟不同
CPU的内存延迟是GPU的1/10。 - 内存带宽不同
GPU的内存带宽是CPU的10倍。 - GPU具有更大的执行单元。
- 线程轻重程度不同
CPU线程是软件管理的粗粒度重线程, 当 CPU 线程被中断或者由于等待资源就绪状态就变为等待状态, 操作系统就需要保存当前线程的上下文,并装载另外一个线程的上下文。 这种机制使得CPU切换线程的代价十分高昂,通常需要数百个时钟周期。 而GPU线程是硬件管理的细粒度轻线程,可以实现零开销的线程切换。 当一个线程因为访问片外存储器或者同步指令开始等待以后, 可以立即切换到另外一个处于就绪状态的线程,用计算来隐藏延迟, 并且线程数目越多,隐藏延迟的效果越好。 - CPU属于“多核”,而GPU属于“众核”
CPU 的每个核心具有取指和调度单元构成的完整前端, 因而其核心是多指令流多数据流(Multiple Instruction Multiple Data,MIMD)。 每个CPU核心可以在同一时刻执行自己的指令,与其他的核心完全没有关系。 但这种设计增加了芯片的面积,限制了单块芯片集成的核心数量。 GPU的每个流多处理器才能被看作类似于 CPU 的单个核心, 每个流多处理器以单指令流多线程方式工作,只能执行相同的程序。 尽管 GPU 运行频率低于CPU,但由于其流处理器数目远远多于 CPU 的核心数, 我们称之为“众核”,其单精度浮点处理能力达到了同期CPU的十倍之多。 - 内存与寄存器之间的不同
目前的CPU内存控制器一般基于双通道或者三通道技术, 每个通道位宽64bit。而GPU则有数个存储器控制单元, 这些控制单元具备同时存取数据的能力,从而使得总的存储器位宽达到了512bit。 这个差异导致了GPU全局存储器带宽大约是同期CPU最高内存带宽的5倍。 - 缓存机制不同
CPU拥有多级容量较大的缓存来尽量减小访存延迟和节约带宽, 但缓存在多线程环境下容易产生失效反应,每次线程切换都需要重建缓存上下文, 一次缓存失效的代价是几十到上百个时钟周期。同时,为了实现缓存与内存中数据的一致性, 还需要复杂的逻辑控制,CPU缓存机制导致核心数过多会引起系统性能下降。 在GPU中则没有复杂的缓存体系与一致性机制,GPU缓存的主要目的是随机访问优化和减轻全局存储器的带宽压力。
综上,GPU是以大量线程实现面向吞吐量的数据并行计算, 适合于处理计算密度高、逻辑分支简单的大规模数据并行负载。 而CPU则有复杂的控制逻辑和大容量的缓存减小延迟,擅长复杂逻辑运算。
3.相关概念
(1)SIMT
SIMT中文译为单指令多线程,英文全称为Single Instruction Multiple Threads。 GPU中的SIMT体系结构相对于CPU的SIMD中的概念,SIMT的好处是无需开发者费力把数据凑成合适的矢量长度, 并且SIMT允许每个线程有不同的分支。
线程、线程块、线程格、核函数
Thread:并行运算的基本单位(轻量级的线程)
Block:由相互合作的一组线程组成。一个block中的thread可以彼此同步,快速交换数据,最多可以同时512个线程。
Grid:一组Block,有共享全局内存。
Kernel:在GPU上执行的程序,一个Kernel对应一个Grid。
Block和Thread都有各自的ID,记作blockIdx(x,y,z),threadIdx(x,y,z)。
Block和Thread还有Dim,即blockDim与threadDim,表示维数的大小,为常量。他们都有三个分量x,y,z。
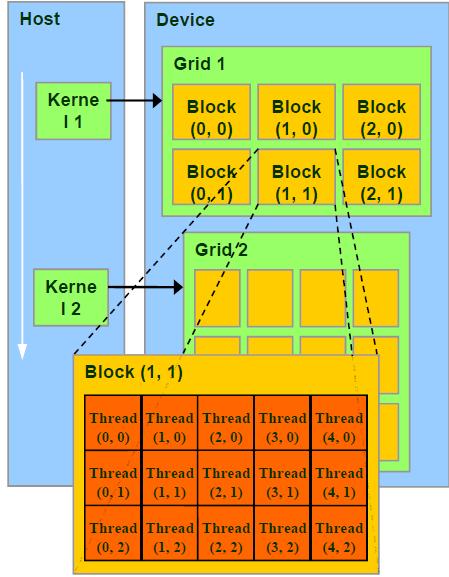 在CUDA中程序执行区域分为两部分,CPU和GPU对应HOST和DEVICE。
任务组织和发送是在CPU里完成的,但并行计算是在GPU里完成。
CUDA执行时让host里面的每个kernel按照线程网格(Grid)的概念在显卡硬件(GPU)上执行,CUDA处理任务的最大单元便是grid。
每一个kernel交给每一个Grid来完成,每个Grid中的任务是一定的。
每一个Grid又把任务分成各个block,block再分线程来完成。我们可以使用
在CUDA中程序执行区域分为两部分,CPU和GPU对应HOST和DEVICE。
任务组织和发送是在CPU里完成的,但并行计算是在GPU里完成。
CUDA执行时让host里面的每个kernel按照线程网格(Grid)的概念在显卡硬件(GPU)上执行,CUDA处理任务的最大单元便是grid。
每一个kernel交给每一个Grid来完成,每个Grid中的任务是一定的。
每一个Grid又把任务分成各个block,block再分线程来完成。我们可以使用__syncthreads()函数同步一个block里的所有线程。
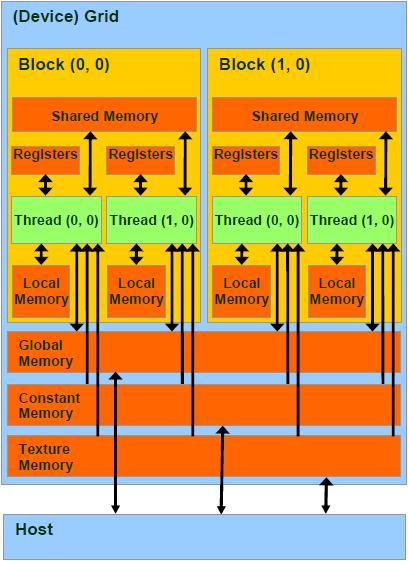
总结来说,每个thread都有自己的一份register和local memory空间。
一组thread构成一个block,这些thread则共享有一份shared memory。
此外,所有thread(包括不同 block 的 thread)都共享一份
global memory、constant memory、和 texture memory。
不同的grid则有各自的global memory、constant memory 和 texture memory。分配内存时使用的cudaMalloc,cudaFree,其分配的是global memory。
(2)变量类型
在编程中,可以在变量名前面加上这些前缀以区分。
__device__:GPU的global memory空间,grid中所有线程可访问。
__constant__:GPU的constant memory空间,grid中所有线程可访问。
__shared__:GPU上的thread block空间,block中所有线程可访问。
local:位于SM内,仅本thread可访问。
(3)数据类型
内建矢量类型
int1,int2,int3,int4,float1,float2, float3,float4 …
纹理类型
texture<Type, Dim, ReadMode> texRef;
内建dim3类型
可以用于定义grid和block的组织方法。例如:
dim3 dimGrid(2, 2);
dim3 dimBlock(4, 2, 2);
kernel<<<dimGrid, dimBlock>>>(argument);
(4)函数定义
__device__:执行于Device,仅能从Device调用。限制,不能用&取地址;不支持递归;不支持static variable;不支持可变长度参数。
__global__:执行于Device,仅能从Host调用。此类函数必须返回void。
__host__:执行于Host,仅能从Host调用,是函数的默认类型。
在执行kernel函数时,必须提供execution configuration,即<<<....>>>部分,例如:
__global__ void KernelFunc(...);
// 5000 thread blocks
dim3 DimGrid(100, 50);
// 256 threads per block
dim3 DimBlock(4, 8, 8);
// 64 bytes of shared memory
size_t SharedMemBytes = 64;
KernelFunc<<< DimGrid, DimBlock, SharedMemBytes >>>(...);
(5)数学函数
CUDA包含一些数学函数,如sin,pow等。每一个函数包含有两个版本, 例如正弦函数sin,一个普通版本sin,另一个不精确但速度极快的__sin版本。
(6)内置变量
gridDim, blockIdx, blockDim, threadIdx, wrapsize这些内置变量不允许赋值的。
4.GPU硬件
GPU一个最小单元称为Streaming Processor(SP),全流水线单事件无序微处理器,
包含两个ALU和一个FPU,多组寄存器文件(register file,很多寄存器的组合),
这个SP没有cache。事实上,现代GPU就是一组SP的array,即SPA。每一个SP执行一个thread。
多个SP组成Streaming Multiprocessor(SM)。每一个SM执行一个block。每个SM包含8个SP。
一个kernel程序执行在一个grid of threads blocks之中。一个threads block是一批相互合作的threads,
可以用过__syncthreads同步。通过shared memory共享变量,不同block的不能同步。
对于一个block可以包含有1到512个并发线程,具有唯一的blockID,可以是1,2,3D。
同一个block中的线程执行同一个程序,不同的操作数,可以同步,每个线程具有唯一的ID。
(1)线程硬件原理
GPU通过Global block scheduler来调度block,根据硬件架构分配block到某一个SM。 每个SM最多分配8个block,每个SM最多可接受768个thread。同一个SM上面的block的尺寸必须相同。每个线程的调度与ID由该SM管理。 SM满负载工作效率最高!考虑某个Block,其尺寸可以为8×8,16×16,32×32:
- 8×8:每个block有64个线程,由于每个SM最多处理768个线程,因此需要768/64=12个block。但是由于SM最多8个block,因此一个SM实际执行的线程为8*64=512个线程。
- 16×16:每个block有256个线程,SM可以同时接受三个block,3*256=768,满负载。
- 32×32:每个block有1024个线程,SM无法处理。
Block是独立执行的,每个Block内的threads是可协同的。 每个线程由SM中的一个SP执行。当然,由于SM中仅有8个SP,768个线程是以warp为单位执行的, 每个warp包含32个线程,这是基于线程指令的流水线特性完成的。Warp是SM基本调度单位,实际上,一个Warp是一个32路SIMD指令。 基本单位是half-warp。如,SM满负载工作有768个线程,则共有768/32=24个warp,每一瞬时,只有一组warp在SM中执行。 Warp全部线程是执行同一个指令,每个指令需要4个clock cycle,通过复杂的机制执行。
(2)一个thread的一生
- Grid在GPU上启动
- block被分配到SM上
- SM把线程组织为warp
- SM调度执行warp
- 执行结束后释放资源
- block继续被分配
(3)线程存储模型
Register and local memory:线程私有,对程序员透明。每个SM中有8192个register,分配给某些block,
block内部的thread只能使用分配的寄存器。线程数多,每个线程使用的寄存器就少了。
shared memory:block内共享,动态分配。如__shared__ float region[N]。shared memory存储器是被划分为16个小单元,
与half-warp长度相同,称为bank,每个bank可以提供自己的地址服务。连续的32位word映射到连续的bank。
对同一bank的同时访问称为bank conflict。尽量减少这种情形。
Global memory:没有缓存。容易称为性能瓶颈,是优化的关键。
一个half-warp里面的16个线程对global memory的访问可以被coalesce成整块内存的访问,如果:
数据长度为4,8或16bytes;地址连续;起始地址对齐;第N个线程访问第N个数据。Coalesce可以大大提升性能。
Coalesced方法:如果所有线程读取同一地址,不妨使用constant memory;如果为不规则读取可以使用texture内存。
如果使用了某种结构体,其大小不是4 8 16的倍数,可以通过__align(X)强制对齐,X=4 8 16 。
(4)其它硬件小知识
显卡内存(显存/DRAM,Dynamic Random Access Memory,即动态随机存取存储器)和内存(RAM)统称memory(记忆体)。
其相当于CPU的RAM (Random access memory, 内存)。
二者共同的特点是通电的时候才能使用,不正常断电数据就丢失。显存又称帧缓冲器(用于场景显示)。
GPU其实相当于是多核的CPU,但是性能相比CPU要弱得多。其实GPU也可以做的像CPU那样强,只是这样成本会高很多。
硬盘速度慢,RAM速度快。原因在于硬盘读取数据的时候,需要指针转到相应的位置,然后读取数据。
而RAM靠的是电子指令,因此RAM要比硬盘快得多。而不多用RAM的原因是因为比较贵。
当我们用randon()函数产生随机数后,是存储在RAM当中的。当我们从文件读入数据,其实是将硬盘中的数据转存到RAM当中。
CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速率却比内存要快得多。同理GPU缓存。
带宽(band width)又叫频宽,是指在固定的的时间可传输的资料数量,亦即在传输管道中可以传递数据的能力。
在数字设备中,频宽通常以bps表示,即每秒可传输之位数。所谓的内存带宽,指的也就是内存总线所能提供的数据传输能力。
本文作者原创,未经许可不得转载,谢谢配合
